
- 1中国跨过数据库这座大山了吗?
- 2垂直起降飞行器的设计与控制:固定翼和四旋翼整合自主飞行研究(Matlab代码实现)_vtol matlab
- 3springboot校园便利平台
- 4好程序员:学Java真的找不到工作吗?2023年Java就业情况如何?_java还能找到工作吗
- 5python中tkinter使用text组件添加多行文本并自动换行、添加多行文字、添加按钮、添加图片_tkinter 文本框添加按钮
- 6RocketMQ消息发送常见错误与解决方案_defaultmqproducer send exception
- 7Java使用POI导出Excel_java poi导出excel
- 8在无字体时使用word样式,并设置字体样式_xwpfstyles
- 9苹果iOS设备解锁软件:iToolab UnlockGo_强制解除苹果监管锁的软件
- 107 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书已上线...
HBase(2)——hbase数据模型和命令行使用_hbase(main):022:0> put 'scores:zhangsan','course:m
赞
踩
介绍
列式存储格式(对比mysql)

列存储的优点
1 )减少存储空间占⽤。2 )⽀持好多列
HBase的特点
- 海量存储: 底层基于HDFS存储海量数据
- 列式存储:HBase表的数据是基于列族进⾏存储的,⼀个列族包含若⼲列
- 极易扩展:底层依赖HDFS,当磁盘空间不⾜的时候,只需要动态增加DataNode服务节点就可以
- ⾼并发:⽀持⾼并发的读写请求
- 稀疏:稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占 ⽤存储空间的。
- 数据的多版本:HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插⼊数据的时 间戳
- 数据类型单⼀:所有的数据在HBase中是以字节数组进⾏存储
HBase的应⽤
- 交通⽅⾯:船舶GPS信息,每天有上千万左右的数据存储。
- ⾦融⽅⾯:消费信息、贷款信息、信⽤卡还款信息等
- 电商⽅⾯:电商⽹站的交易信息、物流信息、游览信息等
- 电信⽅⾯:通话信息
总结: HBase 适合海量明细数据的存储,并且后期需要有很好的查询性能(单表超千万、上亿,且并发要求⾼)
HBase数据模型
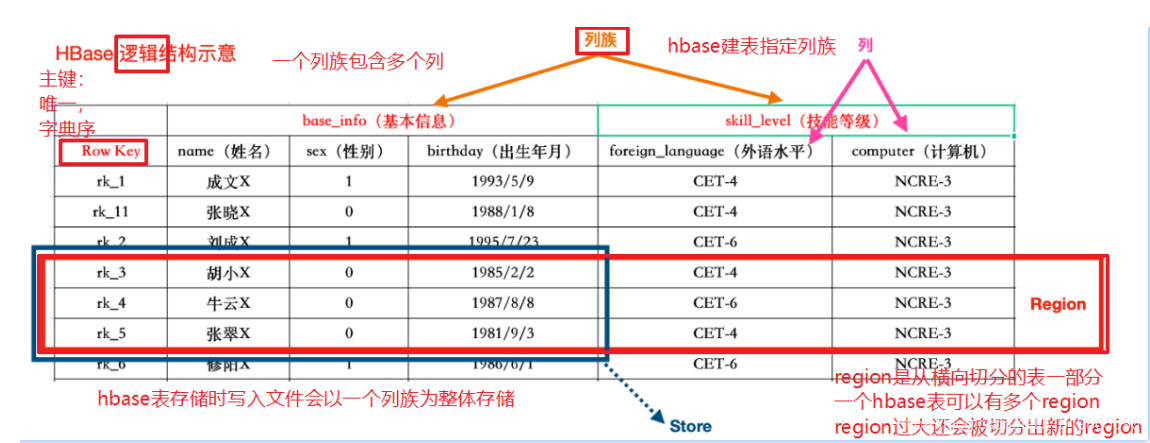

怎么理解HBase所谓的列式存储和Key-Value结构
列式存储
HBase里边也有表、行和列的概念。
- 表没什么好说的,就是一张表
- 一行数据由一个行键和一个或多个相关的列以及它的值所组成
在HBase里边,先有列族后有列,在列族下用列修饰符来标识一列。
简单来说:一个列族下可以任意添加列,不受任何限制

HBase 的Key-Value
HBase本质上其实就是Key-Value的数据库
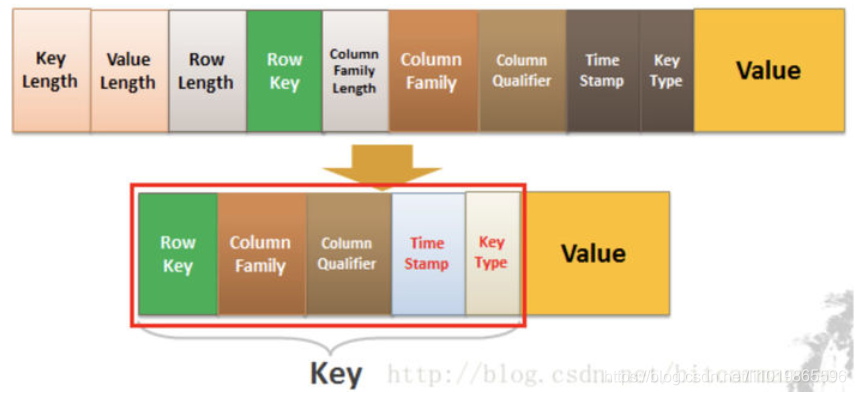
Key由RowKey(行键)+ColumnFamily(列族)+Column Qualifier(列修饰符)+TimeStamp(时间戳--版本)+KeyType(类型)组成,而Value就是实际上的值。
对比上面的例子,其实很好理解,因为我们修改一条数据其实上是在原来的基础上增加一个版本的,那我们要准确定位一条数据,那就得(RowKey+Column+时间戳)。
KeyType是什么?我们上面只说了「修改」的情况,你们有没有想过,如果要删除一条数据怎么做?实际上也是增加一条记录,只不过我们在KeyType里边设置为“Delete”就可以了。
HBase体系结构
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion Server群和HBase Master服务器构成。
HBase Master负责管理所有的HRegion Server,而HBase中的所有RegionServer都是通过ZooKeeper来协调,并处理HBase服务器运行期间可能遇到的错误。
HBase Master Server本身并不存储HBase中的任何数据,HBase逻辑上的表可能会被划分成多个Region,然后存储到HRegion Server群中。HBase Master Server中存储的是从数据到HRegion Server的映射。因此HBase体系结构如下图所示
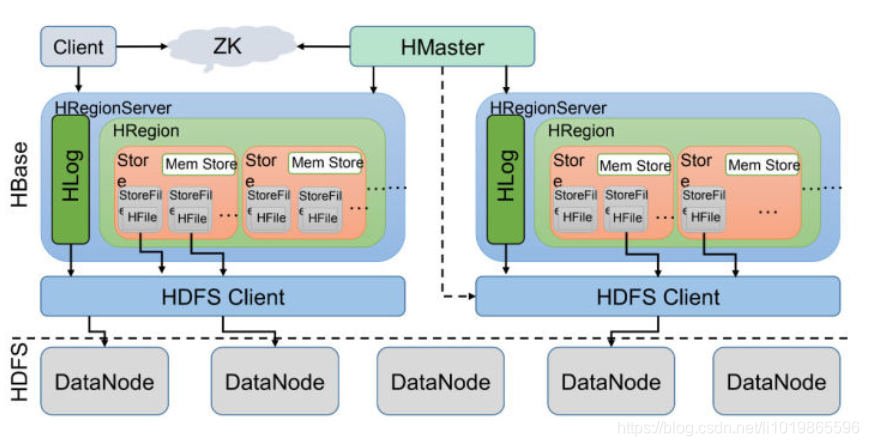
总结大致的流程就是
client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,HRegionServer读写数据后返回给client。
细节讲解
HBase一张表的数据会分到多台机器上的。那HBase是怎么切割一张表的数据的呢?用的就是RowKey来切分,其实就是表的横向切割。
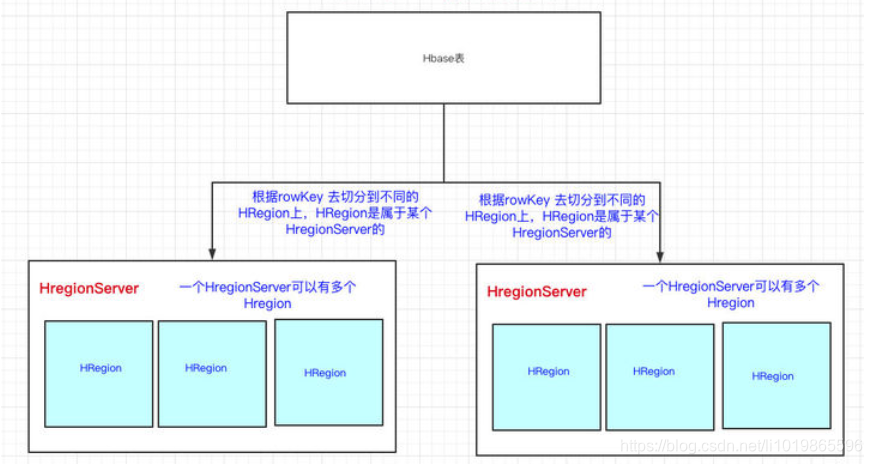
HRegion下面有Store,那Store是什么呢?我们前面也说过,一个HBase表首先要定义列族,然后列是在列族之下的,列可以随意添加。
Store里边有啥?有Mem Store、Store File、HFile,我们再来看看里边都代表啥含义。
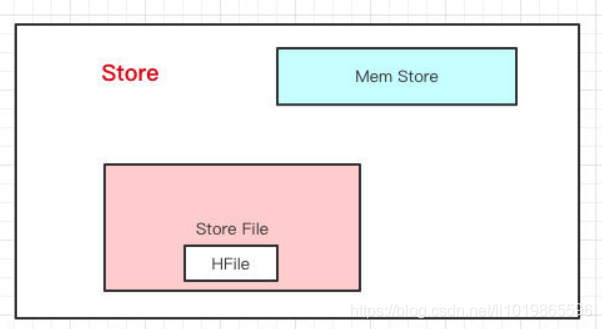
HBase在写数据的时候,会先写到
Mem Store,当MemStore超过一定阈值,就会将内存中的数据刷写到硬盘上,形成StoreFile,而StoreFile底层是以HFile的格式保存,HFile是HBase中KeyValue数据的存储格式。所以说:
Mem Store我们可以理解为内存 buffer,HFile是HBase实际存储的数据格式,而StoreFile只是HBase里的一个名字。
回到HRegionServer上,我们还漏了一块,就是HLog。
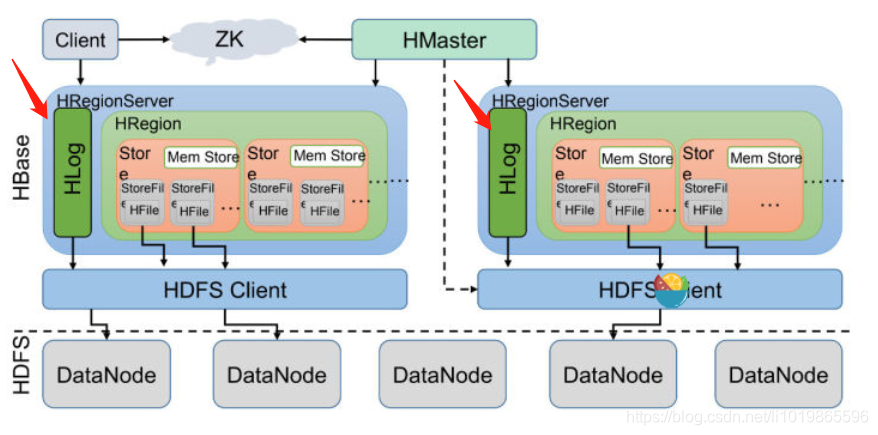
这里其实特别好理解了,我们写数据的时候是先写到内存的,为了防止机器宕机,内存的数据没刷到磁盘中就挂了。我们在写
Mem store的时候还会写一份HLog。这个
HLog是顺序写到磁盘的,所以速度还是挺快的
总结一把:
- HRegionServer是真正干活的机器(用于与hdfs交互),我们HBase表用RowKey来横向切分表
- HRegion里边会有多个Store,每个Store其实就是一个列族的数据(所以我们可以说HBase是基于列族存储的)
- Store里边有Men Store和StoreFile(HFile),其实就是先走一层内存,然后再刷到磁盘的结构
被遗忘的HMaster
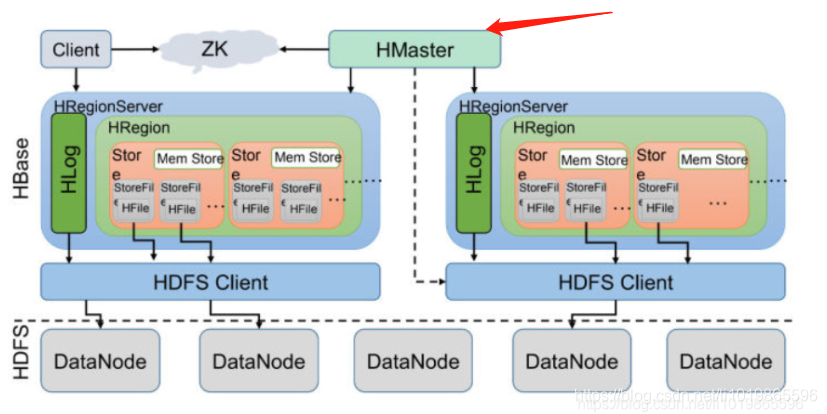
HMaster会处理 HRegion 的分配或转移。如果我们HRegion的数据量太大的话,HMaster会对拆分后的Region重新分配RegionServer。
(如果发现失效的HRegion,也会将失效的HRegion分配到正常的HRegionServer中)
HMaster会处理元数据的变更和监控RegionServer的状态。
详细架构图-读写过程讲解
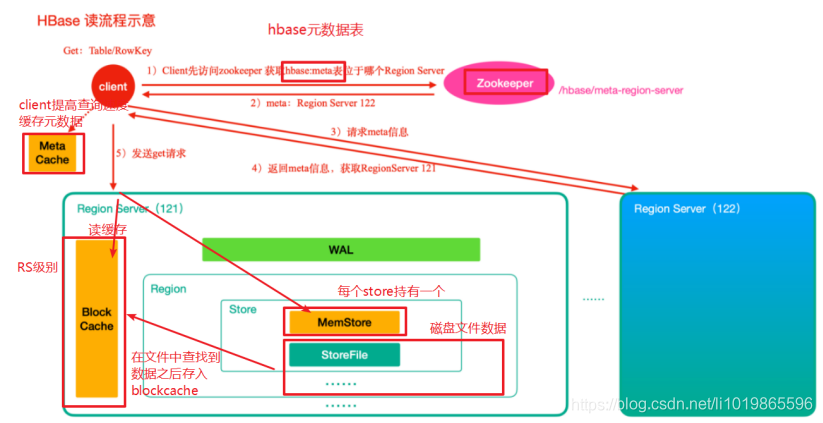
1 )⾸先从 zk 找到 meta 表的 region 位置,然后读取 meta 表中的数据, meta 表中存储了⽤户表的 region 信息2 )根据要查询的 namespace 、表名和 rowkey 信息。找到写⼊数据对应的 region 信息3 )找到这个 region 对应的 regionServer ,然后发送请求4 )查找对应的 region5 )先从 memstore 查找数据,如果没有,再从 BlockCache 上读取HBase 上 Regionserver 的内存分为两个部分⼀部分作为 Memstore ,主要⽤来写;另外⼀部分作为 BlockCache ,主要⽤于读数据;6 )如果 BlockCache 中也没有找到,再到 StoreFile 上进⾏读取从 storeFile 中读取到数据之后,不是直接把结果数据返回给客户端, ⽽是把数据先写⼊到 BlockCache 中,⽬的是为了加快后续的查询;然后在返回结果给客户端。
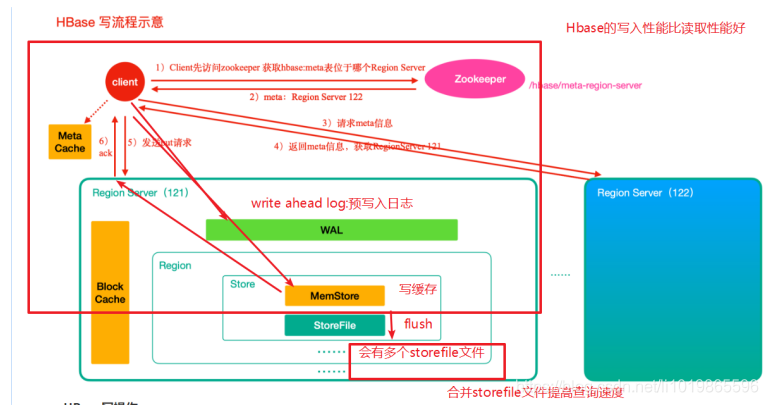
HBase 写操作1 )⾸先从 zk 找到 meta 表的 region 位置,然后读取 meta 表中的数据, meta 表中存储了⽤户表的 region 信息2 )根据 namespace 、表名和 rowkey 信息。找到写⼊数据对应的 region 信息3 )找到这个 region 对应的 regionServer ,然后发送请求4 )把数据分别写到 HLog ( write ahead log )和 memstore 各⼀份5 ) memstore 达到阈值后把数据刷到磁盘,⽣成 storeFile ⽂件6 )删除 HLog 中的历史数据
命令行
- 创建成绩表
-
- create 'scores','grade','course'
-
- 查看结构
- desc'scores'
-
- 插入值
-
- put 'scores','zhangsan01','course:math','99'
- put 'scores','zhangsan01','course:art','90'
- put 'scores','zhangsan01','grade:','101'
- put 'scores','zhangsan02','course:math','66'
- put 'scores','zhangsan02','course:art','60'
- put 'scores','lisi01','course:math','89'
-
- put 'scores','rk2','grade:value','2'
- delete 'scores','rk2','grade:value';
-
- 删除列族
- alter 'scores', 'delete' => 'grade'
-
- 删除scores表数据
- truncate 'scores'
-
- 删除scores表
- hbase(main):036:0> disable 'scores'
- hbase(main):037:0> drop 'scores
- --row查询
- get 'scores','lisi01'
- --范围查询
- scan 'scores', { STARTROW => 'lisi', ENDROW => 'wo'}
- scan 'scores', { STARTROW => 'lisi01'}
- --标识符查询
- scan 'scores', {COLUMNS => 'course'}
- scan 'scores', {COLUMNS => 'course:math'}
- --标识符模糊查询
- scan 'scores', {FILTER => "(QualifierFilter(=,'substring:a'))"}
- --值模糊查询
- scan 'scores', {FILTER => "ValueFilter(=, 'binary:name')"}
-
-

当我们在hbase命令行,输错命令行时,再输入下一条命令,并不执行,而是只换行。
此时,我们可以输入>',退出本次执行,再次输入正确的命令后,可重新执行
Region 拆分机制
Region中存储的是⼤大量量的rowkey数据 ,当Region中的数据条数过多的时候,直接影响查询效率.当Region过⼤大的时候.HBase会拆分Region
为单个表指定Region拆分策略
- create 'test2', {METADATA => {'SPLIT_POLICY' =>
- 'org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy'}},{NAME => 'cf1'}
HBase表的预分区(region)
为何要预分区?
当⼀个table刚被创建的时候,Hbase默认的分配⼀一个region给table。也就是说这个时候,所有的读写请求都会访问到同⼀一个regionServer的同⼀一个region中,这个时
候就达不不到负载均衡的效果了了,集群中的其他regionServer就可能会处于⽐比较空闲的状态。解决这个问题可以⽤用pre-splitting,在创建table的时候就配置好,⽣生成多个
region。
- 增加数据读写效率
- 负载均衡,防⽌止数据倾斜
- ⽅方便便集群容灾调度region
每一个region维护着startRow与endRowKey,如果加⼊入的数据符合某个region维护的rowKey范围,则该数据交给这个region维
手动指定预分区
create 'person','info1','info2',SPLITS => ['1000','2000','3000']或把分区规则创建于⽂文件中
- vim split.txt
- aaa
- bbb
- ccc
- ddd
-
- 执行
- create 'student','info',SPLITS_FILE => '/root/hbase/split.txt'
Region 合并
Region的合并不不是为了了性能,⽽而是出于维护的目的
- alter 't1',METHOD=>'table_att','Coprocessor'=>'hdfs://linux126:9000/processor/processor.jar|com.lagou.hbase.processor.MyProcessor|1001|'
-
-
- put 't1','rk1','info:name','lisi'
协处理器
alter 'relation',METHOD =>
'table_att','Coprocessor'=>'hdfs://linux126:9000/processor/processor.jar|cn.lagou.DeleteProcessor|1001|'
delete 'relation','uid1','friends:uid2'
注:以上为本人小小总结,如果对您起到了一点点帮助,请给予我一点鼓励,在下方点个小小的赞,谢谢,如有错误之处,望不吝指出,非常感谢!

