
- 1将Android手机打造成你的python开发者桌面#华为云·寻找黑马程序员#_termux无法刷流量
- 2干货分享:AI绘图学习心得-Midjourney绘画AI,让你的AI绘画之路少走弯路_ai绘画课程总结
- 3Oracle 数据库中 查询时如何使用日期(时间)作为查询条件_oracle 时间条件
- 4用python实现简易图书管理系统_python图书管理系统代码_图书管理系统python
- 5软件工程电商系统数据库定义_电子商务网站建立系统数据库
- 6程序员不得不收藏的十二个网站_uisources 会员
- 7【Java探索之旅】我与Java的初相识(二):程序结构与运行关系和JDK,JRE,JVM的关系_java编译与运行结构
- 8图解TCP/IP_图解tcpip
- 9【MySQL调优】如何进行MySQL调优?从参数、数据建模、索引、SQL语句等方向,三万字详细解读MySQL的性能优化方案(2024版)_mysql 临时表代替子查询
- 10域名注册后能改吗?
HiveSql常用函数总结_hive sql coalesce
赞
踩
COALESCE()函数
主流数据库系统都支持COALESCE()函数,这个函数主要用来进行空值处理,其参数格式如下: COALESCE ( expression,value1,value2……,valuen) COALESCE()函数的第一个参数expression为待检测的表达式,而其后的参数个数不定。 COALESCE()函数将会返回包括expression在内的所有参数中的第一个非空表达式。
如果expression不为空值则返回expression;否则判断value1是否是空值,
如果value1不为空值则返回value1;否则判断value2是否是空值,
如果value2不为空值则返回value2;……以此类推, 如果所有的表达式都为空值,则返回NULL。
时间转换函数
to_date()函数
select to_date(from_unixtime(unix_timestamp()+28800));--返回当前时间的日期datediff(date1, date2) 函数
Returns the number of days between date1 and date2
返回日期date1和date2之间的日期天数
select datediff(from_unixtime(unix_timestamp()+28800),'2021-01-01');from_unixtime()函数
from_unixtime()函数可以方便地把时间戳转化为时间
from_unixtime(unix_timestamp()+28800) =现在的北京时间
date_format()函数
DATE_FORMAT(date,format)函数用于以不同的格式显示日期/时间数据。 date是日期列,format是格式
STR_TO_DATE(str,format) 将字符串转成日期
- select date_format(日期字段,'%Y-%m-%d') as '日期' from test
- mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00', '%W %M %Y');
- -> 'Saturday October 1997'
- select date_format('2022-04-12','%W, %M %e, %Y');
- -> 'Tuesday, April 12, 2022'
-
- mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00', '%H:%i:%s');
- -> '22:23:00'
- mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
- '%D %y %a %d %m %b %j');
- -> '4th 97 Sat 04 10 Oct 277'
- mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
- '%H %k %I %r %T %S %w');
- -> '22 22 10 10:23:00 PM 22:23:00 00 6'
- mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');
- -> '1998 52'

开窗函数
①格式:函数名(列) OVER(选项)
②分类:
第一大类:聚合开窗函数 聚合函数(列) OVER (选项),这里的选项可以是PARTITION BY子句,但不可是ORDER BY子句
第二大类:排序开窗函数 排序函数(列) OVER(选项),这里的选项可以是ORDER BY子句,也可以是 OVER(PARTITION BY子句 ORDER BY子句),但不可以是PARTITION BY子句
聚合:
使用数据:

1. sum(…) over( partition by… )
求出各个球队总进球数
- select distinct team_name,sum(goals)over(partition by team_name )as total_goals
- from record_match;

2. sum(…) over( partition by… order by … )
同第1点中的排序求和原理,在组内按照人名首字母顺序依次求出总进球数:
- select team_name,player_name,sum(goals)over(partition by team_name order by player_name)as total_goals
- from record_match;

排序:
1.row_number()over( partition by...order by...)普通的字段值大小排名,无任何约束条件
2.dense_rank() over( partition by... order by... )数据值相同的字段,他们的排名也相同,且排名之间没有间隔(从1-n连续不间断)
3.rank() 数据值相同的字段,他们的排名也相同,且排名之间有间隔
使用数据:

1.班内分数由高到低排序 row_number()over( partition by...order by...)
- select
- s_id,c_id,s_score,row_number() over (partition by c_id order by s_score desc )
- from score

2.分数相同并列排序的,排名无间隔 dense_rank() over( partition by... order by... )
- select
- s_id,c_id,s_score,dense_rank() over (partition by c_id order by s_score desc )
- from score
3.分数相同并列排序的,排名有间隔
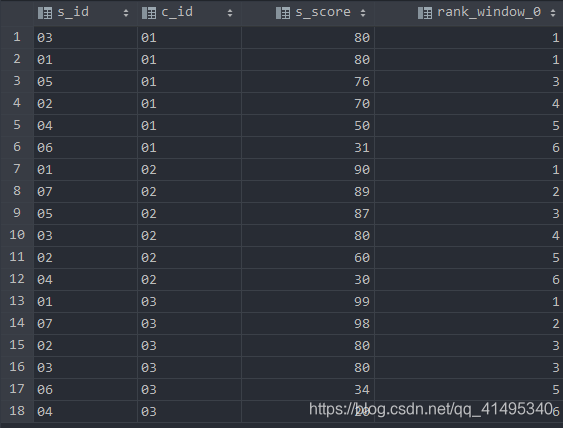
爆炸函数
explode()函数用于打散行的函数(将一行的数据拆分成多行,它的参数必须为map或array)
示范数据:

1.explode()
把student_name这一列中的数据由一行变成多行。这里需要使用split和explode,并结合lateral view实现。代码如下:
- select
- distinct class_id, student_name
- from
- class_info
- lateral view explode(split(student_name,',')) t as student1
2.单列explode()
我们想要给每个学院来一个编号,按姓名首字母的顺序,可以再使用posexplode这个函数,代码如下:
- select
- class_id,student_index + 1 as student_index,student_num
- from
- class_info
- lateral view posexplode(split(student_name,',')) t as student_index,student_num;

3.多列explode
这次我们想基于两列进行explode,同时能够使学院和其成绩能够匹配,即按照班级、姓名、分数对应按列输出,且不能重复,输出结果按分数排序:
- select class_id,
- name,
- student_score
- from class_info
- lateral view posexplode(split(student_name, ',')) sn as student_index_sn, name
- lateral view posexplode(split(score, ',')) sc as student_index_sc, student_score
- where student_index_sn = student_index_sc
- order by student_score;
!切忌列名和字段名不能重复

分析函数 LAG Lead
LAG()接受三个参数:列名或从中获取值的表达式、上面要跳过的行数(偏移量)以及如果从上面的行获取的存储值为空时要返回的默认值。只需要第一个参数。仅当您指定第二个参数偏移量时,才允许使用第三个参数(默认值)。
与其他窗口函数一样,LAG()需要OVER子句。它可以采用可选参数,我们将在后面解释。使用LAG(),您必须ORDER BY在OVER子句中指定一个,并使用列或列列表来对行进行排序。
使用数据:

用lag( ) 函数,返回上一个销售员销售额
- SELECT seller_name, sale_value,
- LAG(sale_value) OVER(ORDER BY sale_value) as previous_sale_value
- FROM sale;

LEAD()类似于LAG(). 而LAG()访问存储在上面一行中LEAD()的值,访问存储在下面一行中的值。
就像 一样LAG(),该LEAD()函数接受三个参数:列或表达式的名称,下面要跳过的偏移量,以及从下面的行中获取的存储值为空时返回的默认值。只需要第一个参数。第三个参数是默认值,只有在指定第二个参数偏移量时才能指定。
就像LAG(),LEAD()是一个窗口函数,需要一个OVER子句。和 一样LAG(),在子句中LEAD()必须带有一个。ORDER BYOVER
- SELECT seller_name, sale_value,
- LEAD(sale_value) OVER(ORDER BY sale_value) as next_sale_value
- FROM sale;

实例:Leetcode 第603题 连续空余座位

