
- 1MySQL数据库下载及安装教程(最最新版)
- 2智能助手的巅峰对决:ChatGPT对阵文心一言
- 3常用经典SQL语句大全完整版--详解+实例
- 4selenium使用,qq邮箱登陆_selenium qq邮箱 登录
- 5ansible-playbook debug输出区别与用法_ansible msg
- 6第十二届蓝桥杯python组怎么从零准备?_蓝桥杯python 需要学什么
- 7【数据库】跨库分页的几种常见方案_数据库跨度分页
- 8kubeadm——k8s环境配置_kubeadm init --pod-network-cidr=10.244.0.0/16
- 9xray Web扫描器学习记录_poc-yaml-active-directory-certsrv-detect
- 10(附源码)springboot校园疫情管理系统 毕业设计 021506_校园疫情管理系统er图
技术前沿:传统计算与存内计算的较量,谁将引领未来计算新篇章?_英特尔的研究表明,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pj/bit,占总功耗
赞
踩
在冯诺依曼架构被提出的70余年后,随着处理器算力与存储器储量的提升,架构的局限性逐渐体现,由此,存内计算模式应运而生,针对如今AI时代的新技术的方向,基于存储器运行计算的新型存内计算架构模式,将进一步突破算力瓶颈,引领计算架构发展。
传统计算
(一)传统计算方式/架构
提起计算方式、计算架构,人们都会想到一个熟悉的名字——“冯·诺依曼”,冯诺依曼架构便是当今电子计算器的通用架构,它由数学家冯·诺依曼在20世纪40年代提出,是现代计算机体系结构的基础,被广泛应用于各种计算设备。简单来讲,它将指令和数据存储在同一个存储器(Memory)中,并使用同一套总线进行数据传输,CPU通过抓取指令和数据来执行程序,进行计算。冯诺依曼架构提供了计算机系统的基本组成和工作原理,为计算机的发展奠定了基础,它的简洁性、通用性和可扩展性使得计算机能够执行广泛任务,成为现代科技和信息时代的基石。
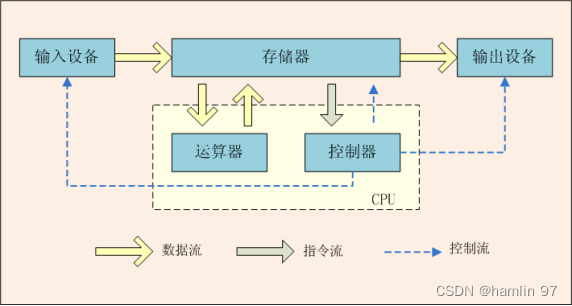
图 1 冯·诺依曼架构示意图
在该架构下,我们可以大致把组件分为:处理器、存储器与输入输出设备。
·处理器:中央处理器(CPU)、图像处理器(GPU)等,负责执行计算机指令与控制计算机的操作,一般由计算单元(ALU)与控制单元(Control Unit)组成;
·存储器:存储指令与数据,存储器种类众多,分为只读存储器(ROM)、随机存储器(RAM)、闪存(Flash)等等;
·输入输出设备:用于与外部环境进行交互,比如键盘、鼠标、显示屏、耳机、打印机等等,他们由处理器中的控制器负责控制;
·总线:除组件之外,图1中的虚线便是连接各组件的数据通路,它包括数据总线、地址总线、控制总线等等,负责不同的数据传输要求。
除冯诺依曼架构外,传统架构还有诸如哈佛架构、CPU混合架构等架构。哈佛架构(Harvard architecture)与冯诺依曼架构类似,它是哈佛大学计算机实验室在20世纪40年代开发的,以哈佛Mark 1计算机为基础并以其命名的架构。其与冯诺依曼架构最大的不同之处在于将指令存储器与数据存储器分开。
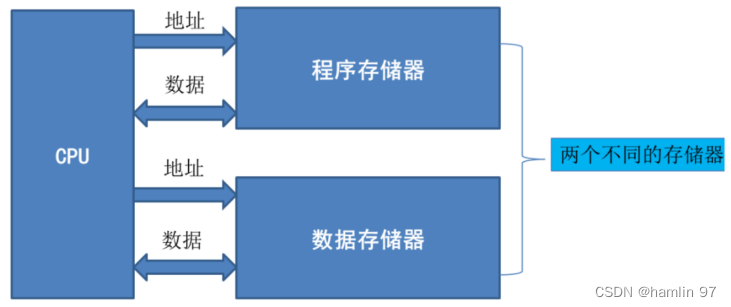
图 2 哈佛架构示意图
(来源:http://681314.com/A/nOhaFxF0E2)
(二)传统架构遇瓶颈,多墙问题逐显现
在摩尔定律的发展的几十年里,处理器、存储器等组件不断发展,处理器算力、存储器存储量都得到了大幅提升。但与之而来的,便是“存储墙”、“带宽墙”、“功耗墙”等问题。
(1)“存储墙”
由于处理器的峰值算力每两年增长3.1倍,而动态存储器的带宽每两年增长1.4倍,存储器的发展速度远落后于处理器,相差1.7倍。CPU时钟速率与片外内存和磁盘驱动器I/O速率之间的差距越来越大。比如,动态随机存储器DRAM(Dynamic Random Access Memory)是芯片领域“最大宗单一产品”,精密工业制造的皇冠之一,被喻为连接中央处理器(CPU)的“数据高速公路”。其功能是暂存正在运行的各种程序和数据,是一种易失性存储器,即断电后数据就丢失。DRAM由于其较差的可扩展性和极高的设计成本敏感性(每比特成本),其发展相对较慢,在10nm技术节点就遭遇了天花板。
存储墙导致访存时延高,效率低,存储器的数据访问速度跟不上处理器的数据处理速度,存算性能失配。为了打破存储墙,已经提出了大量的研究工作来优化DRAM架构,提出了存内计算和近存计算两种技术途径,以便在性能、功率和面积开销之间实现更好的权衡,在后文我们也会详细介绍存内计算这种技术途径。
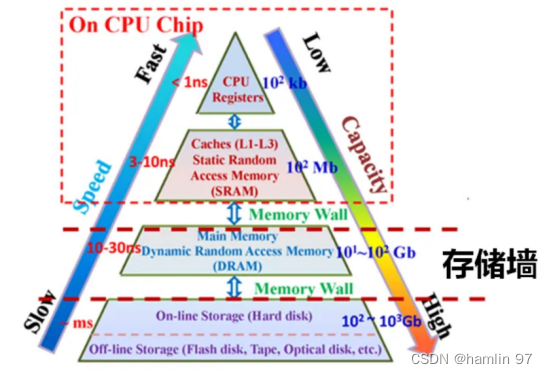
图 3 存储墙示意图
(来源:Bing)
(2)“带宽墙”
事实上,带宽墙与存储墙表述的意义相近,在AI时代,存储带宽制约了计算系统的有效带宽,芯片算力增长步履维艰。从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,也即“带宽墙”。
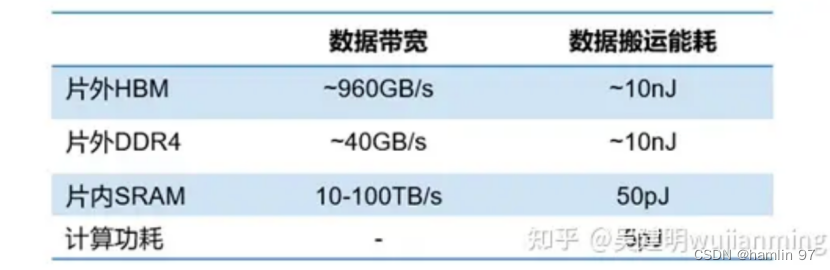
图 4 不同存储器存储带宽对比
(来源:知乎@吴健明whjianming)
(3)“功耗墙”
同样的,数据在计算单元和存储单元之间频繁的移动也会带来不小的功耗,冯·诺依曼架构要求数据在存储器单元和处理单元之间不断地“读写”,这样数据在两者之间来回传输就会消耗很多的传输功耗。根据英特尔的研究表明,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的63.7%。数据传输造成的功耗损失越来越严重,限制了芯片发展的速度和效率,形成了“功耗墙”问题。
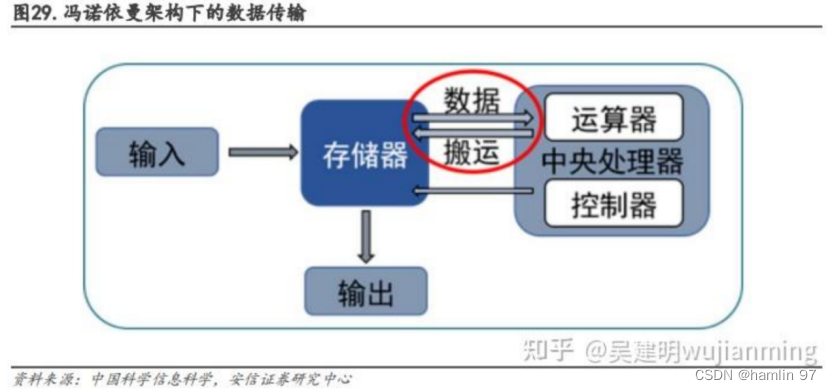
图 5 功耗墙示意图
(来源:知乎@吴健明whjianming)
存内计算
(一)存内计算:继CPU、GPU架构之后的算力架构“第三极”
传统的冯诺依曼架构中,存储单元和计算单元分离,依靠总线获取数据,示意图如下图6(a)所示。
存内计算是一种新型计算架构,直接利用存储器本身进行数据处理,从根本上消除数据搬运,实现存储与计算融合一体化,示意图如图6(b)所示,有望突破冯诺依曼架构存储墙与功耗墙瓶颈,成为AI时代集成电路领域的重点研究方向之一。
存内计算的概念来自于人脑中的神经元。在人脑中,神经元通过突触连接,形成复杂的网络,网络中的每个神经元同时负责数据的接收、处理和存储,意味着数据不需要在存储单元和处理单元之间迁移,效率很高。由于整个运算过程无需再从存储器中反复读取大量模型参数,绕开了冯·诺依曼架构的瓶颈,能效比得到显著提升。
这一过程可以用阅览室(存储单元)、图书(数据)、读者和图书馆工作人员(数据搬运)、电梯(带宽)、借阅台(处理单元)的例子来进行理解。我们约定,只有借阅台能办理书籍借阅和归还,归还的书籍会由工作人员放回,以借还业务办理完成为结束。
图书馆只在一层设有多个借阅台,人流量较小时,读者按照图书索引号能很快找到想阅读的书籍,拿到借阅台办理借阅。但当人流量增大后,如果借阅台仍只设在一层,大量读者会花费时间在等电梯上,同时借阅台处可能也会排队,导致图书馆借阅办理效率低下。这就是冯诺依曼计算机的思路及其问题,其计算结构如下图6(a)示意。
如何解决该问题呢?第一个思路,挑出读者常借阅的书,单独组成一个小型快速阅览室,如果读者借阅的是该阅览室中的书籍,就可以快速完成办理,缓解了电梯处的压力。问题是,随着时间的推移,快速阅览室的书籍需要由图书馆工作人员定期维护更新,还回的书也需要图书馆工作人员放回书架,电梯仍面临运输压力。这种方法是在不改变冯诺依曼架构的情况下做出的改进,在电路结构中表现为在处理单元附近设置快速缓存和多级缓存。
第二个思路,在每个阅览室旁、甚至每个书架旁都设置借阅台,可以办理借还业务,提升了借还书的办理效率。这就是存内计算的做法。
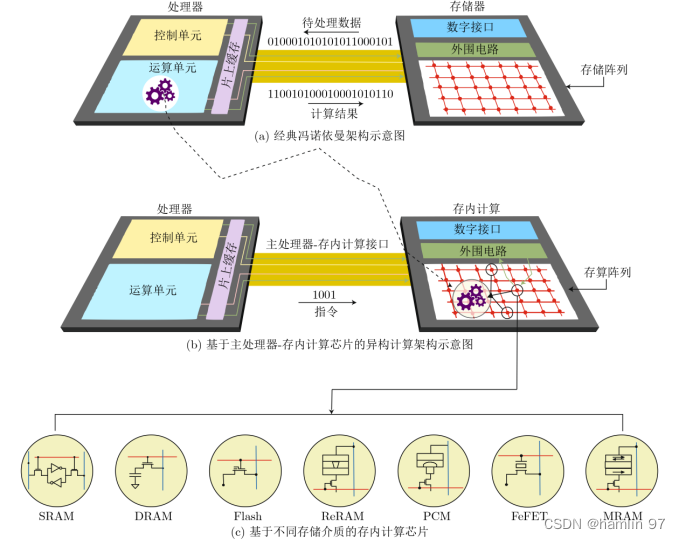
图 6 存内计算结构示意图
(二)计算范式
根据计算范式的而不同,存内计算可以主要分为模拟式和数字式两种。
(1)模拟式存内计算
模拟存内计算是指存储单元内部或阵列周边的信号以模拟信号的方式进行操作,具体来说,主要基于物理定律(欧姆定律和基尔霍夫定律),在存算阵列上实现乘累加运算。
(2)数字式存内计算
数字式存内计算是指在实际运算过程中,存储单元内部或阵列周边的信号以数字信号的方式进行操作,通过在存储阵列内部加入逻辑计算电路,如与门和加法器等,使数字存内计算阵列具备存储及计算能力。
数字存内计算需在存储的基础上增加部分传统逻辑电路来实现,而传统逻辑电路需要晶体管数量多,一定程度上限制了存内计算带来的面积及能效优势。因此,当前业界多采用可兼容先进工艺的SRAM来实现数字存内计算,通过更先进、更成熟的工艺来避免复杂的外部电路设计和更大的面积。
(3)范式比较
数字存算精度高、可靠性高,并且保留了传统数字电路的高抗噪性,对于不同制造工艺、电源电压和温度的变化呈现很强的鲁棒性,因而更适合大规模高计算精度芯片的实现。相较于模拟存算,数字存算更具运算灵活性,可以通过对数字部分的调整适配各种场景,通用性较强,但是功耗更高。
模拟计算可以搭载任意存储单元来实现,但数字存算要求存储单元的内容必须以数字信号形式呈现,而不是经过读写接口电路才能转换为数字信号,因而主要借助于SRAM来实现。相比于数字存算,模拟计算减少了大量乘法器和加法器的面积开销,因而在面积开销上更优。
(三)存储器件和存储方案介绍
存内计算方案根据存储器的不同实现方案也不同,传统存储器包括SRAM、DRAM和Flash等,新型存储器包括ReRAM、PCM、FeFET、MRAM等,电路示意图如上图6(c)所示,其中基于NOR Flash和SRAM研发的存内计算芯片更接近产业化。
根据文献[1]的内容,总结各个不同存储介质的存内计算芯片的性能如下表所示。
表 1 基于不同存储介质的存内计算芯片性能比较
| 标准 | SRAM | DRAM | Flash | ReRAM | PCM | FeFET | MRAM |
| 非易失性 | 否 | 否 | 是 | 是 | 是 | 是 | 是 |
| 多比特存储能力 | 否 | 否 | 是 | 是 | 是 | 是 | 否 |
| 面积效率 | 低 | 一般 | 高 | 高 | 高 | 高 | 高 |
| 功耗效率 | 低 | 低 | 高 | 高 | 高 | 高 | 高 |
| 工艺微缩性 | 好 | 好 | 较差 | 好 | 较好 | 好 | 好 |
| 成本 | 高 | 较高 | 低 | 低 | 较低 | 低 | 低 |
| 技术成熟度 | 测试 | 测试 | 量产 | 测试 | 测试 | 器件 | 测试 |
参考文献
[1] 郭昕婕,王光燿,王绍迪.存内计算芯片研究进展及应用[J].电子与信息学报,2023,45(05):1888-1898.
[2] 清华大学:集成电路学院高滨课题组在支持片上学习的忆阻器存算一体芯片领域取得重要突破
[3] F. Tu et al., "A 28nm 29.2TFLOPS/W BF16 and 36.5TOPS/W INT8 Reconfigurable Digital CIM Processor with Unified FP/INT Pipeline and Bitwise In-Memory Booth Multiplication for Cloud Deep Learning Acceleration," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731762.
[4] 北京大学/集成电路高精尖创新中心研究团队在模拟计算领域取得重要进展
[5] B. Yan et al., "A 1.041-Mb/mm2 27.38-TOPS/W Signed-INT8 Dynamic-Logic-Based ADC-less SRAM Compute-in-Memory Macro in 28nm with Reconfigurable Bitwise Operation for AI and Embedded Applications," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 188-190, doi: 10.1109/ISSCC42614.2022.9731545.
[6] 北航集成电路科学与工程学院在《Nature Communications》期刊发表研究成果
[7] 复旦大学芯片与系统前沿技术研究院存算一体集成芯片成果亮相ISSCC 2022
[8] AI芯天下:趋势丨存算一体芯片迈进开源
[9] D. Niu et al., "184QPS/W 64Mb/mm23D Logic-to-DRAM Hybrid Bonding with Process-Near-Memory Engine for Recommendation System," 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 2022, pp. 1-3, doi: 10.1109/ISSCC42614.2022.9731694.

