
- 1python解释器安装_python添加解释器
- 2vue3.0 案例小demo_vue3 demo
- 3C#中File静态类及其常用静态方法实例详解_c# 静态方法和实例方法
- 4分享15个全球顶尖的AIGC图片生成平台_ai生成图片网站
- 5解密AI人工智能的整体分层架构:探索智能科技的未来之路
- 6计算机网络思科考试答案参考--构建和保护小型网络考试_小公司使用协议分析器实用程序捕获网段上的网络流量,公司考虑进行网络升级的目的
- 7自然语言处理: 第十六章RAG的优化技术
- 8【建议收藏】AI论文生成指南|实战教程!ChatGPT在论文写作中9个应用场景!_chatgpt论文生成
- 9简单批处理病毒的制作—bat小程序_杀毒代码编写bat
- 10技术的广度与深度_技术广度和深度
PyTorch 2.2 中文官方教程(十)_pytorch 2.2.0
赞
踩
使用整体追踪分析的追踪差异
原文:
pytorch.org/tutorials/beginner/hta_trace_diff_tutorial.html译者:飞龙
作者: Anupam Bhatnagar
有时,用户需要识别由代码更改导致的 PyTorch 操作符和 CUDA 内核的变化。为了支持这一需求,HTA 提供了一个追踪比较功能。该功能允许用户输入两组追踪文件,第一组可以被视为控制组,第二组可以被视为测试组,类似于 A/B 测试。TraceDiff类提供了比较追踪之间差异的函数以及可视化这些差异的功能。特别是,用户可以找到每个组中添加和删除的操作符和内核,以及每个操作符/内核的频率和操作符/内核所花费的累积时间。
TraceDiff类具有以下方法:
-
compare_traces: 比较两组追踪中 CPU 操作符和 GPU 内核的频率和总持续时间。
-
ops_diff: 获取已被以下操作符和内核删除的操作符和内核:
- 添加到测试追踪中并在控制追踪中不存在
- 从测试追踪中删除并存在于控制追踪中
- 在测试追踪中增加并存在于控制追踪中
- 在测试追踪中减少并存在于控制追踪中
- 在两组追踪中未更改
最后两种方法可用于使用compare_traces方法的输出可视化 CPU 操作符和 GPU 内核的频率和持续时间的各种变化。
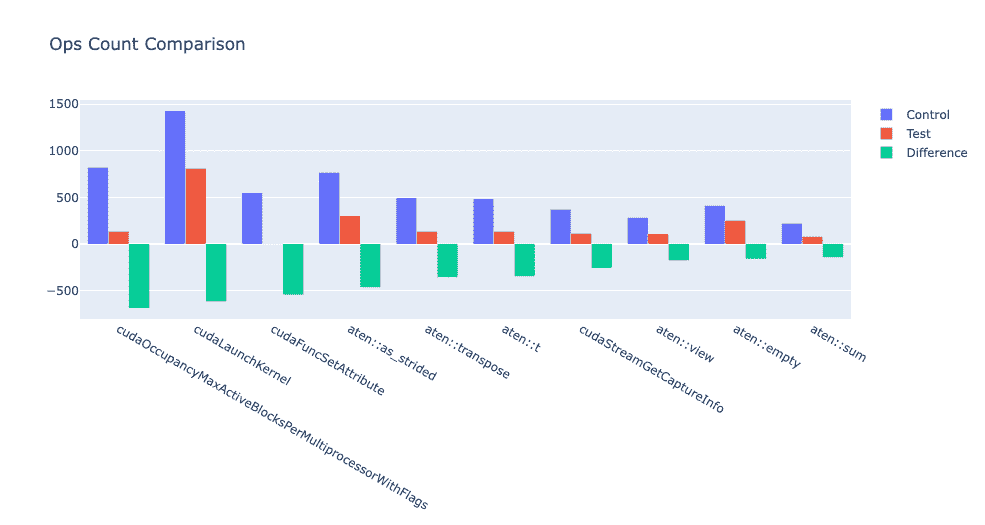
例如,可以计算出频率增加最多的前十个操作符如下:
df = compare_traces_output.sort_values(by="diff_counts", ascending=False).head(10)
TraceDiff.visualize_counts_diff(df)
- 1
- 2
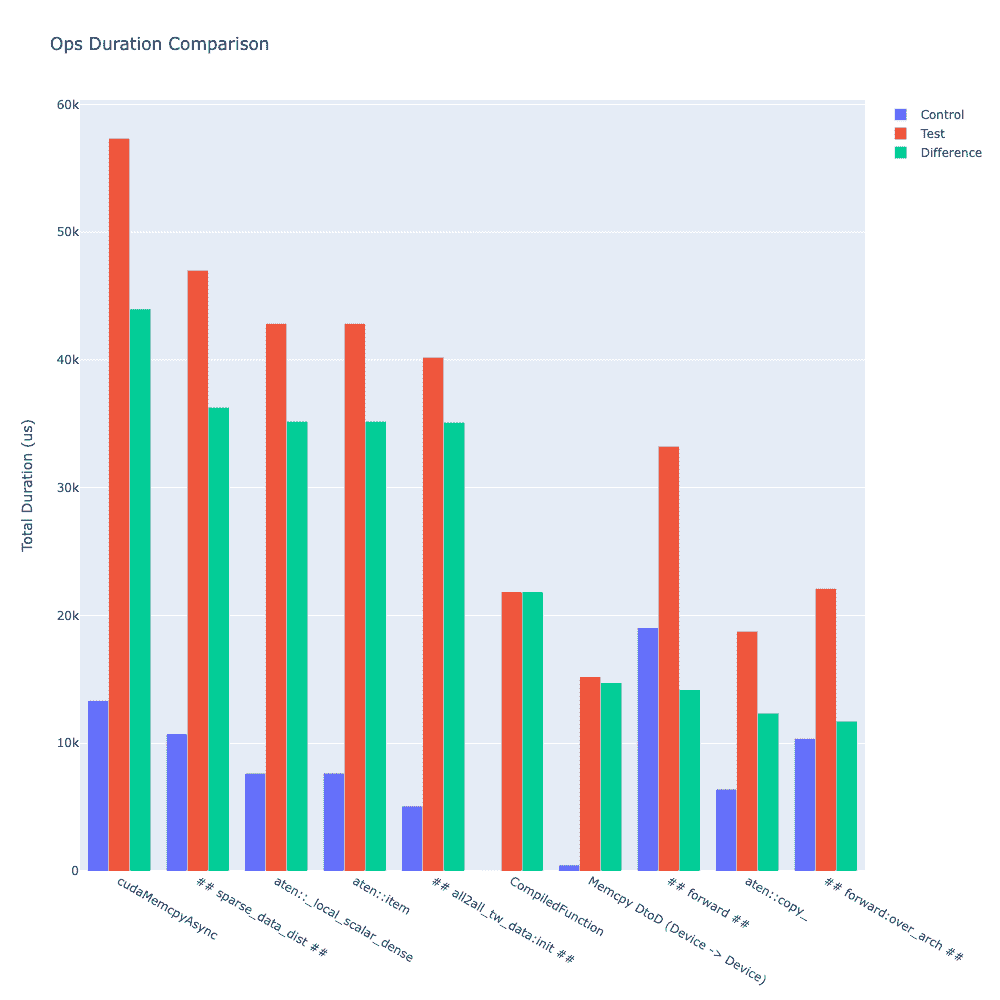
类似地,可以计算出持续时间变化最大的前十个操作符如下:
df = compare_traces_output.sort_values(by="diff_duration", ascending=False)
# The duration differerence can be overshadowed by the "ProfilerStep",
# so we can filter it out to show the trend of other operators.
df = df.loc[~df.index.str.startswith("ProfilerStep")].head(10)
TraceDiff.visualize_duration_diff(df)
- 1
- 2
- 3
- 4
- 5
有关此功能的详细示例,请参阅存储库的示例文件夹中的trace_diff_demo notebook。
代码转换与 FX
(beta)在 FX 中构建一个卷积/批量归一化融合器
原文:
pytorch.org/tutorials/intermediate/fx_conv_bn_fuser.html译者:飞龙
注意
点击这里下载完整示例代码
作者:Horace He
在本教程中,我们将使用 FX,一个用于 PyTorch 可组合函数转换的工具包,执行以下操作:
-
在数据依赖关系中查找卷积/批量归一化的模式。
-
对于在 1)中找到的模式,将批量归一化统计数据折叠到卷积权重中。
请注意,此优化仅适用于处于推理模式的模型(即 mode.eval())
我们将构建存在于此处的融合器:github.com/pytorch/pytorch/blob/orig/release/1.8/torch/fx/experimental/fuser.py
首先,让我们导入一些模块(我们稍后将在代码中使用所有这些)。
from typing import Type, Dict, Any, Tuple, Iterable
import copy
import torch.fx as fx
import torch
import torch.nn as nn
- 1
- 2
- 3
- 4
- 5
对于本教程,我们将创建一个由卷积和批量归一化组成的模型。请注意,这个模型有一些棘手的组件 - 一些卷积/批量归一化模式隐藏在 Sequential 中,一个BatchNorms被包装在另一个模块中。
class WrappedBatchNorm(nn.Module): def __init__(self): super().__init__() self.mod = nn.BatchNorm2d(1) def forward(self, x): return self.mod(x) class M(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(1, 1, 1) self.bn1 = nn.BatchNorm2d(1) self.conv2 = nn.Conv2d(1, 1, 1) self.nested = nn.Sequential( nn.BatchNorm2d(1), nn.Conv2d(1, 1, 1), ) self.wrapped = WrappedBatchNorm() def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.conv2(x) x = self.nested(x) x = self.wrapped(x) return x model = M() model.eval()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
融合卷积与批量归一化
尝试在 PyTorch 中自动融合卷积和批量归一化的主要挑战之一是 PyTorch 没有提供一种轻松访问计算图的方法。FX 通过符号跟踪实际调用的操作来解决这个问题,这样我们就可以通过前向调用、嵌套在 Sequential 模块中或包装在用户定义模块中来跟踪计算。
traced_model = torch.fx.symbolic_trace(model)
print(traced_model.graph)
- 1
- 2
这给我们提供了模型的图形表示。请注意,顺序内部的模块以及包装的模块都已内联到图中。这是默认的抽象级别,但可以由通道编写者配置。更多信息请参阅 FX 概述pytorch.org/docs/master/fx.html#module-torch.fx
融合卷积与批量归一化
与其他一些融合不同,卷积与批量归一化的融合不需要任何新的运算符。相反,在推理期间,批量归一化由逐点加法和乘法组成,这些操作可以“烘烤”到前面卷积的权重中。这使我们能够完全从我们的模型中删除批量归一化!阅读nenadmarkus.com/p/fusing-batchnorm-and-conv/获取更多详细信息。这里的代码是从github.com/pytorch/pytorch/blob/orig/release/1.8/torch/nn/utils/fusion.py复制的,以便更清晰。
def fuse_conv_bn_eval(conv, bn): """ Given a conv Module `A` and an batch_norm module `B`, returns a conv module `C` such that C(x) == B(A(x)) in inference mode. """ assert(not (conv.training or bn.training)), "Fusion only for eval!" fused_conv = copy.deepcopy(conv) fused_conv.weight, fused_conv.bias = \ fuse_conv_bn_weights(fused_conv.weight, fused_conv.bias, bn.running_mean, bn.running_var, bn.eps, bn.weight, bn.bias) return fused_conv def fuse_conv_bn_weights(conv_w, conv_b, bn_rm, bn_rv, bn_eps, bn_w, bn_b): if conv_b is None: conv_b = torch.zeros_like(bn_rm) if bn_w is None: bn_w = torch.ones_like(bn_rm) if bn_b is None: bn_b = torch.zeros_like(bn_rm) bn_var_rsqrt = torch.rsqrt(bn_rv + bn_eps) conv_w = conv_w * (bn_w * bn_var_rsqrt).reshape([-1] + [1] * (len(conv_w.shape) - 1)) conv_b = (conv_b - bn_rm) * bn_var_rsqrt * bn_w + bn_b return torch.nn.Parameter(conv_w), torch.nn.Parameter(conv_b)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
FX Fusion Pass
现在我们有了我们的计算图以及融合卷积和批量归一化的方法,剩下的就是迭代 FX 图并应用所需的融合。
def _parent_name(target : str) -> Tuple[str, str]: """ Splits a ``qualname`` into parent path and last atom. For example, `foo.bar.baz` -> (`foo.bar`, `baz`) """ *parent, name = target.rsplit('.', 1) return parent[0] if parent else '', name def replace_node_module(node: fx.Node, modules: Dict[str, Any], new_module: torch.nn.Module): assert(isinstance(node.target, str)) parent_name, name = _parent_name(node.target) setattr(modules[parent_name], name, new_module) def fuse(model: torch.nn.Module) -> torch.nn.Module: model = copy.deepcopy(model) # The first step of most FX passes is to symbolically trace our model to # obtain a `GraphModule`. This is a representation of our original model # that is functionally identical to our original model, except that we now # also have a graph representation of our forward pass. fx_model: fx.GraphModule = fx.symbolic_trace(model) modules = dict(fx_model.named_modules()) # The primary representation for working with FX are the `Graph` and the # `Node`. Each `GraphModule` has a `Graph` associated with it - this # `Graph` is also what generates `GraphModule.code`. # The `Graph` itself is represented as a list of `Node` objects. Thus, to # iterate through all of the operations in our graph, we iterate over each # `Node` in our `Graph`. for node in fx_model.graph.nodes: # The FX IR contains several types of nodes, which generally represent # call sites to modules, functions, or methods. The type of node is # determined by `Node.op`. if node.op != 'call_module': # If our current node isn't calling a Module then we can ignore it. continue # For call sites, `Node.target` represents the module/function/method # that's being called. Here, we check `Node.target` to see if it's a # batch norm module, and then check `Node.args[0].target` to see if the # input `Node` is a convolution. if type(modules[node.target]) is nn.BatchNorm2d and type(modules[node.args[0].target]) is nn.Conv2d: if len(node.args[0].users) > 1: # Output of conv is used by other nodes continue conv = modules[node.args[0].target] bn = modules[node.target] fused_conv = fuse_conv_bn_eval(conv, bn) replace_node_module(node.args[0], modules, fused_conv) # As we've folded the batch nor into the conv, we need to replace all uses # of the batch norm with the conv. node.replace_all_uses_with(node.args[0]) # Now that all uses of the batch norm have been replaced, we can # safely remove the batch norm. fx_model.graph.erase_node(node) fx_model.graph.lint() # After we've modified our graph, we need to recompile our graph in order # to keep the generated code in sync. fx_model.recompile() return fx_model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
注意
为了演示目的,我们在这里进行了一些简化,比如只匹配 2D 卷积。查看github.com/pytorch/pytorch/blob/master/torch/fx/experimental/fuser.py以获取更可用的通道。
测试我们的融合通道
现在我们可以在初始的玩具模型上运行这个融合通道,并验证我们的结果是相同的。此外,我们可以打印出我们融合模型的代码,并验证是否还有批量归一化。
fused_model = fuse(model)
print(fused_model.code)
inp = torch.randn(5, 1, 1, 1)
torch.testing.assert_allclose(fused_model(inp), model(inp))
- 1
- 2
- 3
- 4
在 ResNet18 上对我们的融合进行基准测试
我们可以在像 ResNet18 这样的较大模型上测试我们的融合通道,看看这个通道如何提高推理性能。
import torchvision.models as models import time rn18 = models.resnet18() rn18.eval() inp = torch.randn(10, 3, 224, 224) output = rn18(inp) def benchmark(model, iters=20): for _ in range(10): model(inp) begin = time.time() for _ in range(iters): model(inp) return str(time.time()-begin) fused_rn18 = fuse(rn18) print("Unfused time: ", benchmark(rn18)) print("Fused time: ", benchmark(fused_rn18))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
正如我们之前看到的,我们的 FX 转换的输出是(“torchscriptable”)PyTorch 代码,我们可以轻松地jit.script输出,尝试进一步提高性能。通过这种方式,我们的 FX 模型转换与 TorchScript 组合在一起,没有任何问题。
jit_rn18 = torch.jit.script(fused_rn18)
print("jit time: ", benchmark(jit_rn18))
############
# Conclusion
# ----------
# As we can see, using FX we can easily write static graph transformations on
# PyTorch code.
#
# Since FX is still in beta, we would be happy to hear any
# feedback you have about using it. Please feel free to use the
# PyTorch Forums (https://discuss.pytorch.org/) and the issue tracker
# (https://github.com/pytorch/pytorch/issues) to provide any feedback
# you might have.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
脚本的总运行时间:(0 分钟 0.000 秒)
下载 Python 源代码:fx_conv_bn_fuser.py
下载 Jupyter 笔记本:fx_conv_bn_fuser.ipynb
(beta)使用 FX 构建一个简单的 CPU 性能分析器
原文:
pytorch.org/tutorials/intermediate/fx_profiling_tutorial.html译者:飞龙
注意
点击这里下载完整的示例代码
作者:James Reed
在本教程中,我们将使用 FX 来执行以下操作:
-
以一种我们可以检查和收集关于代码结构和执行的统计信息的方式捕获 PyTorch Python 代码
-
构建一个小类,作为一个简单的性能“分析器”,收集关于模型各部分的运行时统计信息。
在本教程中,我们将使用 torchvision ResNet18 模型进行演示。
import torch
import torch.fx
import torchvision.models as models
rn18 = models.resnet18()
rn18.eval()
- 1
- 2
- 3
- 4
- 5
- 6
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=1000, bias=True) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
现在我们有了我们的模型,我们想要更深入地检查其性能。也就是说,在以下调用中,模型的哪些部分花费时间最长?
input = torch.randn(5, 3, 224, 224)
output = rn18(input)
- 1
- 2
回答这个问题的常见方法是浏览程序源代码,在程序的各个点添加收集时间戳的代码,并比较这些时间戳之间的差异,以查看这些时间戳之间的区域需要多长时间。
这种技术当然适用于 PyTorch 代码,但如果我们不必复制模型代码并进行编辑,尤其是我们没有编写的代码(比如这个 torchvision 模型),那将更好。相反,我们将使用 FX 自动化这个“仪器化”过程,而无需修改任何源代码。
首先,让我们解决一些导入问题(我们稍后将在代码中使用所有这些)。
import statistics, tabulate, time
from typing import Any, Dict, List
from torch.fx import Interpreter
- 1
- 2
- 3
注意
tabulate是一个外部库,不是 PyTorch 的依赖项。我们将使用它来更轻松地可视化性能数据。请确保您已从您喜欢的 Python 软件包源安装了它。
使用符号跟踪捕获模型
接下来,我们将使用 FX 的符号跟踪机制来捕获我们模型的定义,以便我们可以操作和检查它。
traced_rn18 = torch.fx.symbolic_trace(rn18)
print(traced_rn18.graph)
- 1
- 2
graph(): %x : torch.Tensor [num_users=1] = placeholder[target=x] %conv1 : [num_users=1] = call_moduletarget=conv1, kwargs = {}) %bn1 : [num_users=1] = call_moduletarget=bn1, kwargs = {}) %relu : [num_users=1] = call_moduletarget=relu, kwargs = {}) %maxpool : [num_users=2] = call_moduletarget=maxpool, kwargs = {}) %layer1_0_conv1 : [num_users=1] = call_moduletarget=layer1.0.conv1, kwargs = {}) %layer1_0_bn1 : [num_users=1] = call_moduletarget=layer1.0.bn1, kwargs = {}) %layer1_0_relu : [num_users=1] = call_moduletarget=layer1.0.relu, kwargs = {}) %layer1_0_conv2 : [num_users=1] = call_moduletarget=layer1.0.conv2, kwargs = {}) %layer1_0_bn2 : [num_users=1] = call_moduletarget=layer1.0.bn2, kwargs = {}) %add : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer1_0_relu_1 : [num_users=2] = call_moduletarget=layer1.0.relu, kwargs = {}) %layer1_1_conv1 : [num_users=1] = call_moduletarget=layer1.1.conv1, kwargs = {}) %layer1_1_bn1 : [num_users=1] = call_moduletarget=layer1.1.bn1, kwargs = {}) %layer1_1_relu : [num_users=1] = call_moduletarget=layer1.1.relu, kwargs = {}) %layer1_1_conv2 : [num_users=1] = call_moduletarget=layer1.1.conv2, kwargs = {}) %layer1_1_bn2 : [num_users=1] = call_moduletarget=layer1.1.bn2, kwargs = {}) %add_1 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer1_1_relu_1 : [num_users=2] = call_moduletarget=layer1.1.relu, kwargs = {}) %layer2_0_conv1 : [num_users=1] = call_moduletarget=layer2.0.conv1, kwargs = {}) %layer2_0_bn1 : [num_users=1] = call_moduletarget=layer2.0.bn1, kwargs = {}) %layer2_0_relu : [num_users=1] = call_moduletarget=layer2.0.relu, kwargs = {}) %layer2_0_conv2 : [num_users=1] = call_moduletarget=layer2.0.conv2, kwargs = {}) %layer2_0_bn2 : [num_users=1] = call_moduletarget=layer2.0.bn2, kwargs = {}) %layer2_0_downsample_0 : [num_users=1] = call_moduletarget=layer2.0.downsample.0, kwargs = {}) %layer2_0_downsample_1 : [num_users=1] = call_moduletarget=layer2.0.downsample.1, kwargs = {}) %add_2 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer2_0_relu_1 : [num_users=2] = call_moduletarget=layer2.0.relu, kwargs = {}) %layer2_1_conv1 : [num_users=1] = call_moduletarget=layer2.1.conv1, kwargs = {}) %layer2_1_bn1 : [num_users=1] = call_moduletarget=layer2.1.bn1, kwargs = {}) %layer2_1_relu : [num_users=1] = call_moduletarget=layer2.1.relu, kwargs = {}) %layer2_1_conv2 : [num_users=1] = call_moduletarget=layer2.1.conv2, kwargs = {}) %layer2_1_bn2 : [num_users=1] = call_moduletarget=layer2.1.bn2, kwargs = {}) %add_3 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer2_1_relu_1 : [num_users=2] = call_moduletarget=layer2.1.relu, kwargs = {}) %layer3_0_conv1 : [num_users=1] = call_moduletarget=layer3.0.conv1, kwargs = {}) %layer3_0_bn1 : [num_users=1] = call_moduletarget=layer3.0.bn1, kwargs = {}) %layer3_0_relu : [num_users=1] = call_moduletarget=layer3.0.relu, kwargs = {}) %layer3_0_conv2 : [num_users=1] = call_moduletarget=layer3.0.conv2, kwargs = {}) %layer3_0_bn2 : [num_users=1] = call_moduletarget=layer3.0.bn2, kwargs = {}) %layer3_0_downsample_0 : [num_users=1] = call_moduletarget=layer3.0.downsample.0, kwargs = {}) %layer3_0_downsample_1 : [num_users=1] = call_moduletarget=layer3.0.downsample.1, kwargs = {}) %add_4 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer3_0_relu_1 : [num_users=2] = call_moduletarget=layer3.0.relu, kwargs = {}) %layer3_1_conv1 : [num_users=1] = call_moduletarget=layer3.1.conv1, kwargs = {}) %layer3_1_bn1 : [num_users=1] = call_moduletarget=layer3.1.bn1, kwargs = {}) %layer3_1_relu : [num_users=1] = call_moduletarget=layer3.1.relu, kwargs = {}) %layer3_1_conv2 : [num_users=1] = call_moduletarget=layer3.1.conv2, kwargs = {}) %layer3_1_bn2 : [num_users=1] = call_moduletarget=layer3.1.bn2, kwargs = {}) %add_5 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer3_1_relu_1 : [num_users=2] = call_moduletarget=layer3.1.relu, kwargs = {}) %layer4_0_conv1 : [num_users=1] = call_moduletarget=layer4.0.conv1, kwargs = {}) %layer4_0_bn1 : [num_users=1] = call_moduletarget=layer4.0.bn1, kwargs = {}) %layer4_0_relu : [num_users=1] = call_moduletarget=layer4.0.relu, kwargs = {}) %layer4_0_conv2 : [num_users=1] = call_moduletarget=layer4.0.conv2, kwargs = {}) %layer4_0_bn2 : [num_users=1] = call_moduletarget=layer4.0.bn2, kwargs = {}) %layer4_0_downsample_0 : [num_users=1] = call_moduletarget=layer4.0.downsample.0, kwargs = {}) %layer4_0_downsample_1 : [num_users=1] = call_moduletarget=layer4.0.downsample.1, kwargs = {}) %add_6 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer4_0_relu_1 : [num_users=2] = call_moduletarget=layer4.0.relu, kwargs = {}) %layer4_1_conv1 : [num_users=1] = call_moduletarget=layer4.1.conv1, kwargs = {}) %layer4_1_bn1 : [num_users=1] = call_moduletarget=layer4.1.bn1, kwargs = {}) %layer4_1_relu : [num_users=1] = call_moduletarget=layer4.1.relu, kwargs = {}) %layer4_1_conv2 : [num_users=1] = call_moduletarget=layer4.1.conv2, kwargs = {}) %layer4_1_bn2 : [num_users=1] = call_moduletarget=layer4.1.bn2, kwargs = {}) %add_7 : [num_users=1] = call_functiontarget=operator.add, kwargs = {}) %layer4_1_relu_1 : [num_users=1] = call_moduletarget=layer4.1.relu, kwargs = {}) %avgpool : [num_users=1] = call_moduletarget=avgpool, kwargs = {}) %flatten : [num_users=1] = call_functiontarget=torch.flatten, kwargs = {}) %fc : [num_users=1] = call_moduletarget=fc, kwargs = {}) return fc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
这为我们提供了 ResNet18 模型的图形表示。图形由一系列相互连接的节点组成。每个节点代表 Python 代码中的调用点(无论是函数、模块还是方法),边缘(在每个节点上表示为args和kwargs)代表这些调用点之间传递的值。有关图形表示和 FX 的其余 API 的更多信息,请参阅 FX 文档pytorch.org/docs/master/fx.html。
创建一个性能分析解释器
接下来,我们将创建一个从torch.fx.Interpreter继承的类。虽然symbolic_trace生成的GraphModule编译了 Python 代码,当您调用GraphModule时运行,但运行GraphModule的另一种方法是逐个执行Graph中的每个Node。这就是Interpreter提供的功能:它逐个解释图节点。
通过继承Interpreter,我们可以重写各种功能,并安装我们想要的分析行为。目标是有一个对象,我们可以将一个模型传递给它,调用模型 1 次或多次,然后获取关于模型和模型各部分在这些运行中花费多长时间的统计信息。
让我们定义我们的ProfilingInterpreter类:
class ProfilingInterpreter(Interpreter): def __init__(self, mod : torch.nn.Module): # Rather than have the user symbolically trace their model, # we're going to do it in the constructor. As a result, the # user can pass in any ``Module`` without having to worry about # symbolic tracing APIs gm = torch.fx.symbolic_trace(mod) super().__init__(gm) # We are going to store away two things here: # # 1\. A list of total runtimes for ``mod``. In other words, we are # storing away the time ``mod(...)`` took each time this # interpreter is called. self.total_runtime_sec : List[float] = [] # 2\. A map from ``Node`` to a list of times (in seconds) that # node took to run. This can be seen as similar to (1) but # for specific sub-parts of the model. self.runtimes_sec : Dict[torch.fx.Node, List[float]] = {} ###################################################################### # Next, let's override our first method: ``run()``. ``Interpreter``'s ``run`` # method is the top-level entry point for execution of the model. We will # want to intercept this so that we can record the total runtime of the # model. def run(self, *args) -> Any: # Record the time we started running the model t_start = time.time() # Run the model by delegating back into Interpreter.run() return_val = super().run(*args) # Record the time we finished running the model t_end = time.time() # Store the total elapsed time this model execution took in the # ``ProfilingInterpreter`` self.total_runtime_sec.append(t_end - t_start) return return_val ###################################################################### # Now, let's override ``run_node``. ``Interpreter`` calls ``run_node`` each # time it executes a single node. We will intercept this so that we # can measure and record the time taken for each individual call in # the model. def run_node(self, n : torch.fx.Node) -> Any: # Record the time we started running the op t_start = time.time() # Run the op by delegating back into Interpreter.run_node() return_val = super().run_node(n) # Record the time we finished running the op t_end = time.time() # If we don't have an entry for this node in our runtimes_sec # data structure, add one with an empty list value. self.runtimes_sec.setdefault(n, []) # Record the total elapsed time for this single invocation # in the runtimes_sec data structure self.runtimes_sec[n].append(t_end - t_start) return return_val ###################################################################### # Finally, we are going to define a method (one which doesn't override # any ``Interpreter`` method) that provides us a nice, organized view of # the data we have collected. def summary(self, should_sort : bool = False) -> str: # Build up a list of summary information for each node node_summaries : List[List[Any]] = [] # Calculate the mean runtime for the whole network. Because the # network may have been called multiple times during profiling, # we need to summarize the runtimes. We choose to use the # arithmetic mean for this. mean_total_runtime = statistics.mean(self.total_runtime_sec) # For each node, record summary statistics for node, runtimes in self.runtimes_sec.items(): # Similarly, compute the mean runtime for ``node`` mean_runtime = statistics.mean(runtimes) # For easier understanding, we also compute the percentage # time each node took with respect to the whole network. pct_total = mean_runtime / mean_total_runtime * 100 # Record the node's type, name of the node, mean runtime, and # percent runtime. node_summaries.append( [node.op, str(node), mean_runtime, pct_total]) # One of the most important questions to answer when doing performance # profiling is "Which op(s) took the longest?". We can make this easy # to see by providing sorting functionality in our summary view if should_sort: node_summaries.sort(key=lambda s: s[2], reverse=True) # Use the ``tabulate`` library to create a well-formatted table # presenting our summary information headers : List[str] = [ 'Op type', 'Op', 'Average runtime (s)', 'Pct total runtime' ] return tabulate.tabulate(node_summaries, headers=headers)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
注意
我们使用 Python 的time.time函数来获取墙钟时间戳并进行比较。这不是衡量性能的最准确方法,只会给我们一个一阶近似。我们仅仅出于演示目的使用这种简单的技术。
调查 ResNet18 的性能
我们现在可以使用ProfilingInterpreter来检查我们的 ResNet18 模型的性能特征;
interp = ProfilingInterpreter(rn18)
interp.run(input)
print(interp.summary(True))
- 1
- 2
- 3
Op type Op Average runtime (s) Pct total runtime ------------- --------------------- --------------------- ------------------- call_module maxpool 0.0058043 9.43883 call_module conv1 0.00556087 9.04297 call_module layer4_0_conv2 0.00342155 5.56404 call_module layer4_1_conv2 0.00325394 5.29148 call_module layer4_1_conv1 0.00316119 5.14066 call_module layer1_0_conv2 0.00267935 4.3571 call_module layer1_1_conv1 0.00267816 4.35516 call_module layer3_0_conv2 0.00267792 4.35477 call_module layer3_1_conv1 0.00261283 4.24893 call_module layer3_1_conv2 0.00259137 4.21403 call_module layer1_0_conv1 0.00256515 4.17138 call_module layer2_1_conv1 0.00249219 4.05274 call_module layer2_1_conv2 0.0024581 3.9973 call_module layer2_0_conv2 0.00242114 3.93721 call_module layer1_1_conv2 0.00241613 3.92906 call_module layer4_0_conv1 0.00203657 3.31183 call_module layer3_0_conv1 0.00165725 2.69498 call_module layer2_0_conv1 0.00164604 2.67676 call_module bn1 0.00133991 2.17894 call_module layer2_0_downsample_0 0.000616312 1.00223 call_module layer3_0_downsample_0 0.000507832 0.825825 call_module layer4_0_downsample_0 0.000471115 0.766117 call_function add 0.00034976 0.568772 call_module relu 0.000216722 0.352429 call_function add_1 0.000201702 0.328004 call_module fc 0.000183105 0.297762 call_module layer1_0_bn1 0.000178337 0.290008 call_module layer1_0_bn2 0.000164032 0.266745 call_module layer1_1_bn1 0.000163794 0.266358 call_module layer1_1_bn2 0.000160933 0.261705 call_module avgpool 0.000149012 0.242319 call_module layer2_1_bn2 0.000141621 0.2303 call_module layer2_0_downsample_1 0.000141382 0.229913 call_module layer4_0_bn2 0.000140429 0.228362 call_module layer2_0_bn1 0.000137806 0.224097 call_module layer4_1_bn2 0.000136852 0.222546 call_module layer2_1_bn1 0.000136137 0.221383 call_module layer2_0_bn2 0.000132799 0.215955 call_module layer1_1_relu 0.000128984 0.209752 call_function add_2 0.000127316 0.207038 call_module layer3_1_bn1 0.000127316 0.207038 call_module layer3_0_downsample_1 0.0001266 0.205875 call_module layer3_0_bn1 0.000126362 0.205487 call_module layer3_0_bn2 0.000125647 0.204324 call_function add_3 0.000124454 0.202385 call_module layer3_1_bn2 0.000123978 0.20161 call_module layer4_1_bn1 0.000119686 0.194631 call_module layer4_0_downsample_1 0.000118017 0.191917 call_module layer4_0_bn1 0.000117779 0.191529 call_module layer1_0_relu 0.000107288 0.17447 call_module layer1_0_relu_1 9.91821e-05 0.161288 call_module layer1_1_relu_1 9.63211e-05 0.156635 call_module layer4_0_relu 8.51154e-05 0.138413 call_function add_5 8.46386e-05 0.137637 call_module layer4_1_relu 8.44002e-05 0.13725 call_module layer2_1_relu 8.36849e-05 0.136087 call_function add_4 8.24928e-05 0.134148 call_module layer2_0_relu 8.10623e-05 0.131822 call_module layer2_1_relu_1 8.01086e-05 0.130271 call_module layer2_0_relu_1 7.96318e-05 0.129496 call_module layer3_0_relu_1 7.9155e-05 0.12872 call_module layer4_0_relu_1 7.7486e-05 0.126006 call_function add_7 7.7486e-05 0.126006 call_module layer3_1_relu 7.70092e-05 0.125231 call_function add_6 7.67708e-05 0.124843 call_module layer4_1_relu_1 7.67708e-05 0.124843 call_module layer3_0_relu 7.65324e-05 0.124455 call_module layer3_1_relu_1 7.10487e-05 0.115538 call_function flatten 4.3869e-05 0.0713388 placeholder x 2.59876e-05 0.0422605 output output 1.95503e-05 0.0317923
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
这里有两件事情我们应该注意:
-
MaxPool2d占用了最多的时间。这是一个已知问题:github.com/pytorch/pytorch/issues/51393 -
BatchNorm2d 也占用了相当多的时间。我们可以继续这种思路,并在 Conv-BN Fusion with FX 教程中对其进行优化。
结论
正如我们所看到的,使用 FX,我们可以轻松地捕获 PyTorch 程序(甚至是我们没有源代码的程序!)以机器可解释的格式进行分析,比如我们在这里所做的性能分析。FX 为使用 PyTorch 程序开辟了一个充满可能性的世界。
最后,由于 FX 仍处于测试阶段,我们很乐意听取您对其使用的任何反馈意见。请随时使用 PyTorch 论坛(discuss.pytorch.org/)和问题跟踪器(github.com/pytorch/pytorch/issues)提供您可能有的任何反馈意见。
脚本的总运行时间:(0 分钟 0.374 秒)
下载 Python 源代码:fx_profiling_tutorial.py
下载 Jupyter 笔记本:fx_profiling_tutorial.ipynb
前端 APIs
(beta)PyTorch 中的通道最后内存格式
原文:
pytorch.org/tutorials/intermediate/memory_format_tutorial.html译者:飞龙
注意
点击这里下载完整示例代码
什么是通道最后
通道最后的内存格式是在保留维度顺序的同时对 NCHW 张量进行排序的另一种方式。通道最后的张量以通道成为最密集的维度(即按像素存储图像)的方式进行排序。
例如,NCHW 张量的经典(连续)存储(在我们的情况下,是两个具有 3 个颜色通道的 4x4 图像)如下所示:

通道最后内存格式以不同的方式对数据进行排序:

Pytorch 通过利用现有的步幅结构来支持内存格式(并提供与现有模型(包括 eager、JIT 和 TorchScript)的向后兼容性)。例如,通道最后格式中的 10x3x16x16 批次将具有等于(768,1,48,3)的步幅。
通道最后内存格式仅适用于 4D NCHW 张量。
内存格式 API
以下是如何在连续和通道最后的内存格式之间转换张量的方法。
经典的 PyTorch 连续张量
import torch
N, C, H, W = 10, 3, 32, 32
x = torch.empty(N, C, H, W)
print(x.stride()) # Outputs: (3072, 1024, 32, 1)
- 1
- 2
- 3
- 4
- 5
(3072, 1024, 32, 1)
- 1
转换运算符
x = x.to(memory_format=torch.channels_last)
print(x.shape) # Outputs: (10, 3, 32, 32) as dimensions order preserved
print(x.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
- 3
torch.Size([10, 3, 32, 32])
(3072, 1, 96, 3)
- 1
- 2
回到连续
x = x.to(memory_format=torch.contiguous_format)
print(x.stride()) # Outputs: (3072, 1024, 32, 1)
- 1
- 2
(3072, 1024, 32, 1)
- 1
备选选项
x = x.contiguous(memory_format=torch.channels_last)
print(x.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
(3072, 1, 96, 3)
- 1
格式检查
print(x.is_contiguous(memory_format=torch.channels_last)) # Outputs: True
- 1
True
- 1
to和contiguous这两个 API 之间存在一些细微差别。我们建议在明确转换张量的内存格式时坚持使用to。
对于一般情况,这两个 API 的行为是相同的。然而,在特殊情况下,对于大小为NCHW的 4D 张量,当C==1或H==1 && W==1时,只有to会生成适当的步幅以表示通道最后的内存格式。
这是因为在上述两种情况中,张量的内存格式是模糊的,即大小为N1HW的连续张量在内存存储中既是contiguous又是通道最后的。因此,它们已被视为给定内存格式的is_contiguous,因此contiguous调用变为无操作,并且不会更新步幅。相反,to会在尺寸为 1 的维度上重新调整张量的步幅,以正确表示预期的内存格式。
special_x = torch.empty(4, 1, 4, 4)
print(special_x.is_contiguous(memory_format=torch.channels_last)) # Outputs: True
print(special_x.is_contiguous(memory_format=torch.contiguous_format)) # Outputs: True
- 1
- 2
- 3
True
True
- 1
- 2
相同的情况也适用于显式置换 API permute。在可能发生模糊的特殊情况下,permute不能保证生成适当携带预期内存格式的步幅。我们建议使用to并明确指定内存格式,以避免意外行为。
另外需要注意的是,在极端情况下,当三个非批量维度都等于1时(C==1 && H==1 && W==1),当前的实现无法将张量标记为通道最后的内存格式。
创建为通道最后
x = torch.empty(N, C, H, W, memory_format=torch.channels_last)
print(x.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
(3072, 1, 96, 3)
- 1
clone 保留内存格式
y = x.clone()
print(y.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
(3072, 1, 96, 3)
- 1
to,cuda,float … 保留内存格式
if torch.cuda.is_available():
y = x.cuda()
print(y.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
- 3
(3072, 1, 96, 3)
- 1
empty_like,*_like运算符保留内存格式
y = torch.empty_like(x)
print(y.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
(3072, 1, 96, 3)
- 1
逐点运算符保留内存格式
z = x + y
print(z.stride()) # Outputs: (3072, 1, 96, 3)
- 1
- 2
(3072, 1, 96, 3)
- 1
使用cudnn后端的Conv,Batchnorm模块支持通道最后(仅适用于 cuDNN >= 7.6)。卷积模块,与二进制逐点运算符不同,通道最后是主导的内存格式。如果所有输入都在连续的内存格式中,操作符将以连续的内存格式生成输出。否则,输出将以通道最后的内存格式生成。
if torch.backends.cudnn.is_available() and torch.backends.cudnn.version() >= 7603:
model = torch.nn.Conv2d(8, 4, 3).cuda().half()
model = model.to(memory_format=torch.channels_last) # Module parameters need to be channels last
input = torch.randint(1, 10, (2, 8, 4, 4), dtype=torch.float32, requires_grad=True)
input = input.to(device="cuda", memory_format=torch.channels_last, dtype=torch.float16)
out = model(input)
print(out.is_contiguous(memory_format=torch.channels_last)) # Outputs: True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
True
- 1
当输入张量到达不支持通道最后的操作符时,内核应自动应用置换以恢复输入张量上的连续性。这会引入开销并停止通道最后的内存格式传播。尽管如此,它保证了正确的输出。
性能收益
Channels last 内存格式优化在 GPU 和 CPU 上都可用。在 GPU 上,观察到 NVIDIA 硬件上具有 Tensor Cores 支持的运行在降低精度(torch.float16)时,性能增益最显著。我们能够在使用‘AMP(自动混合精度)’训练脚本时,通过 Channels last 实现超过 22%的性能增益,同时利用了由 NVIDIA 提供的 AMP github.com/NVIDIA/apex。
python main_amp.py -a resnet50 --b 200 --workers 16 --opt-level O2 ./data
# opt_level = O2 # keep_batchnorm_fp32 = None <class 'NoneType'> # loss_scale = None <class 'NoneType'> # CUDNN VERSION: 7603 # => creating model 'resnet50' # Selected optimization level O2: FP16 training with FP32 batchnorm and FP32 master weights. # Defaults for this optimization level are: # enabled : True # opt_level : O2 # cast_model_type : torch.float16 # patch_torch_functions : False # keep_batchnorm_fp32 : True # master_weights : True # loss_scale : dynamic # Processing user overrides (additional kwargs that are not None)... # After processing overrides, optimization options are: # enabled : True # opt_level : O2 # cast_model_type : torch.float16 # patch_torch_functions : False # keep_batchnorm_fp32 : True # master_weights : True # loss_scale : dynamic # Epoch: [0][10/125] Time 0.866 (0.866) Speed 230.949 (230.949) Loss 0.6735125184 (0.6735) Prec@1 61.000 (61.000) Prec@5 100.000 (100.000) # Epoch: [0][20/125] Time 0.259 (0.562) Speed 773.481 (355.693) Loss 0.6968704462 (0.6852) Prec@1 55.000 (58.000) Prec@5 100.000 (100.000) # Epoch: [0][30/125] Time 0.258 (0.461) Speed 775.089 (433.965) Loss 0.7877287269 (0.7194) Prec@1 51.500 (55.833) Prec@5 100.000 (100.000) # Epoch: [0][40/125] Time 0.259 (0.410) Speed 771.710 (487.281) Loss 0.8285319805 (0.7467) Prec@1 48.500 (54.000) Prec@5 100.000 (100.000) # Epoch: [0][50/125] Time 0.260 (0.380) Speed 770.090 (525.908) Loss 0.7370464802 (0.7447) Prec@1 56.500 (54.500) Prec@5 100.000 (100.000) # Epoch: [0][60/125] Time 0.258 (0.360) Speed 775.623 (555.728) Loss 0.7592862844 (0.7472) Prec@1 51.000 (53.917) Prec@5 100.000 (100.000) # Epoch: [0][70/125] Time 0.258 (0.345) Speed 774.746 (579.115) Loss 1.9698858261 (0.9218) Prec@1 49.500 (53.286) Prec@5 100.000 (100.000) # Epoch: [0][80/125] Time 0.260 (0.335) Speed 770.324 (597.659) Loss 2.2505953312 (1.0879) Prec@1 50.500 (52.938) Prec@5 100.000 (100.000)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
通过传递--channels-last true允许在 Channels last 格式中运行模型,观察到 22%的性能增益。
python main_amp.py -a resnet50 --b 200 --workers 16 --opt-level O2 --channels-last true ./data
# opt_level = O2 # keep_batchnorm_fp32 = None <class 'NoneType'> # loss_scale = None <class 'NoneType'> # # CUDNN VERSION: 7603 # # => creating model 'resnet50' # Selected optimization level O2: FP16 training with FP32 batchnorm and FP32 master weights. # # Defaults for this optimization level are: # enabled : True # opt_level : O2 # cast_model_type : torch.float16 # patch_torch_functions : False # keep_batchnorm_fp32 : True # master_weights : True # loss_scale : dynamic # Processing user overrides (additional kwargs that are not None)... # After processing overrides, optimization options are: # enabled : True # opt_level : O2 # cast_model_type : torch.float16 # patch_torch_functions : False # keep_batchnorm_fp32 : True # master_weights : True # loss_scale : dynamic # # Epoch: [0][10/125] Time 0.767 (0.767) Speed 260.785 (260.785) Loss 0.7579724789 (0.7580) Prec@1 53.500 (53.500) Prec@5 100.000 (100.000) # Epoch: [0][20/125] Time 0.198 (0.482) Speed 1012.135 (414.716) Loss 0.7007197738 (0.7293) Prec@1 49.000 (51.250) Prec@5 100.000 (100.000) # Epoch: [0][30/125] Time 0.198 (0.387) Speed 1010.977 (516.198) Loss 0.7113101482 (0.7233) Prec@1 55.500 (52.667) Prec@5 100.000 (100.000) # Epoch: [0][40/125] Time 0.197 (0.340) Speed 1013.023 (588.333) Loss 0.8943189979 (0.7661) Prec@1 54.000 (53.000) Prec@5 100.000 (100.000) # Epoch: [0][50/125] Time 0.198 (0.312) Speed 1010.541 (641.977) Loss 1.7113249302 (0.9551) Prec@1 51.000 (52.600) Prec@5 100.000 (100.000) # Epoch: [0][60/125] Time 0.198 (0.293) Speed 1011.163 (683.574) Loss 5.8537774086 (1.7716) Prec@1 50.500 (52.250) Prec@5 100.000 (100.000) # Epoch: [0][70/125] Time 0.198 (0.279) Speed 1011.453 (716.767) Loss 5.7595844269 (2.3413) Prec@1 46.500 (51.429) Prec@5 100.000 (100.000) # Epoch: [0][80/125] Time 0.198 (0.269) Speed 1011.827 (743.883) Loss 2.8196096420 (2.4011) Prec@1 47.500 (50.938) Prec@5 100.000 (100.000)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
以下模型列表完全支持 Channels last,并在 Volta 设备上显示 8%-35%的性能增益:alexnet,mnasnet0_5,mnasnet0_75,mnasnet1_0,mnasnet1_3,mobilenet_v2,resnet101,resnet152,resnet18,resnet34,resnet50,resnext50_32x4d,shufflenet_v2_x0_5,shufflenet_v2_x1_0,shufflenet_v2_x1_5,shufflenet_v2_x2_0,squeezenet1_0,squeezenet1_1,vgg11,vgg11_bn,vgg13,vgg13_bn,vgg16,vgg16_bn,vgg19,vgg19_bn,wide_resnet101_2,wide_resnet50_2
以下模型列表完全支持 Channels last,并在 Intel® Xeon® Ice Lake(或更新)CPU 上显示 26%-76%的性能增益:alexnet,densenet121,densenet161,densenet169,googlenet,inception_v3,mnasnet0_5,mnasnet1_0,resnet101,resnet152,resnet18,resnet34,resnet50,resnext101_32x8d,resnext50_32x4d,shufflenet_v2_x0_5,shufflenet_v2_x1_0,squeezenet1_0,squeezenet1_1,vgg11,vgg11_bn,vgg13,vgg13_bn,vgg16,vgg16_bn,vgg19,vgg19_bn,wide_resnet101_2,wide_resnet50_2
转换现有模型
Channels last 支持不仅限于现有模型,因为任何模型都可以转换为 Channels last 并在输入(或某些权重)正确格式化后通过图形传播格式。
# Need to be done once, after model initialization (or load)
model = model.to(memory_format=torch.channels_last) # Replace with your model
# Need to be done for every input
input = input.to(memory_format=torch.channels_last) # Replace with your input
output = model(input)
- 1
- 2
- 3
- 4
- 5
- 6
然而,并非所有运算符都完全转换为支持 Channels last(通常返回连续的输出)。在上面发布的示例中,不支持 Channels last 的层将停止内存格式传播。尽管如此,由于我们已将模型转换为 Channels last 格式,这意味着每个卷积层,其 4 维权重在 Channels last 内存格式中,将恢复 Channels last 内存格式并从更快的内核中受益。
但是,不支持 Channels last 的运算符会通过置换引入开销。可选地,您可以调查并识别模型中不支持 Channels last 的运算符,如果要改进转换模型的性能。
这意味着您需要根据支持的运算符列表github.com/pytorch/pytorch/wiki/Operators-with-Channels-Last-support验证所使用的运算符列表,或者在急切执行模式中引入内存格式检查并运行您的模型。
在运行以下代码后,如果运算符的输出与输入的内存格式不匹配,运算符将引发异常。
def contains_cl(args): for t in args: if isinstance(t, torch.Tensor): if t.is_contiguous(memory_format=torch.channels_last) and not t.is_contiguous(): return True elif isinstance(t, list) or isinstance(t, tuple): if contains_cl(list(t)): return True return False def print_inputs(args, indent=""): for t in args: if isinstance(t, torch.Tensor): print(indent, t.stride(), t.shape, t.device, t.dtype) elif isinstance(t, list) or isinstance(t, tuple): print(indent, type(t)) print_inputs(list(t), indent=indent + " ") else: print(indent, t) def check_wrapper(fn): name = fn.__name__ def check_cl(*args, **kwargs): was_cl = contains_cl(args) try: result = fn(*args, **kwargs) except Exception as e: print("`{}` inputs are:".format(name)) print_inputs(args) print("-------------------") raise e failed = False if was_cl: if isinstance(result, torch.Tensor): if result.dim() == 4 and not result.is_contiguous(memory_format=torch.channels_last): print( "`{}` got channels_last input, but output is not channels_last:".format(name), result.shape, result.stride(), result.device, result.dtype, ) failed = True if failed and True: print("`{}` inputs are:".format(name)) print_inputs(args) raise Exception("Operator `{}` lost channels_last property".format(name)) return result return check_cl old_attrs = dict() def attribute(m): old_attrs[m] = dict() for i in dir(m): e = getattr(m, i) exclude_functions = ["is_cuda", "has_names", "numel", "stride", "Tensor", "is_contiguous", "__class__"] if i not in exclude_functions and not i.startswith("_") and "__call__" in dir(e): try: old_attrs[m][i] = e setattr(m, i, check_wrapper(e)) except Exception as e: print(i) print(e) attribute(torch.Tensor) attribute(torch.nn.functional) attribute(torch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
如果发现一个不支持 Channels last 张量的运算符,并且您想要贡献,可以随时使用以下开发者指南github.com/pytorch/pytorch/wiki/Writing-memory-format-aware-operators。
以下代码是为了恢复 torch 的属性。
for (m, attrs) in old_attrs.items():
for (k, v) in attrs.items():
setattr(m, k, v)
- 1
- 2
- 3
需要做的工作
还有许多事情要做,例如:
-
解决
N1HW和NC11张量的歧义; -
测试分布式训练支持;
-
提高运算符覆盖率。
如果您有反馈和/或改进建议,请通过创建一个问题让我们知道。
脚本的总运行时间:(0 分钟 0.038 秒)
下载 Python 源代码:memory_format_tutorial.py
下载 Jupyter 笔记本:memory_format_tutorial.ipynb
前向模式自动微分(Beta)
原文:
pytorch.org/tutorials/intermediate/forward_ad_usage.html译者:飞龙
注意
点击这里下载完整示例代码
本教程演示了如何使用前向模式自动微分来计算方向导数(或等效地,雅可比向量积)。
下面的教程仅使用版本 >= 1.11(或夜间构建)中才可用的一些 API。
还要注意,前向模式自动微分目前处于 beta 阶段。API 可能会发生变化,操作符覆盖仍然不完整。
基本用法
与反向模式自动微分不同,前向模式自动微分在前向传递过程中急切地计算梯度。我们可以使用前向模式自动微分来计算方向导数,方法是在执行前向传递之前,将我们的输入与另一个表示方向导数方向(或等效地,雅可比向量积中的 v)的张量相关联。当一个称为“原始”的输入与一个称为“切向”的“方向”张量相关联时,所得到的新张量对象被称为“双张量”,因为它与双重数的连接[0]。
在执行前向传递时,如果任何输入张量是双张量,则会执行额外的计算以传播函数的“敏感性”。
import torch import torch.autograd.forward_ad as fwAD primal = torch.randn(10, 10) tangent = torch.randn(10, 10) def fn(x, y): return x ** 2 + y ** 2 # All forward AD computation must be performed in the context of # a ``dual_level`` context. All dual tensors created in such a context # will have their tangents destroyed upon exit. This is to ensure that # if the output or intermediate results of this computation are reused # in a future forward AD computation, their tangents (which are associated # with this computation) won't be confused with tangents from the later # computation. with fwAD.dual_level(): # To create a dual tensor we associate a tensor, which we call the # primal with another tensor of the same size, which we call the tangent. # If the layout of the tangent is different from that of the primal, # The values of the tangent are copied into a new tensor with the same # metadata as the primal. Otherwise, the tangent itself is used as-is. # # It is also important to note that the dual tensor created by # ``make_dual`` is a view of the primal. dual_input = fwAD.make_dual(primal, tangent) assert fwAD.unpack_dual(dual_input).tangent is tangent # To demonstrate the case where the copy of the tangent happens, # we pass in a tangent with a layout different from that of the primal dual_input_alt = fwAD.make_dual(primal, tangent.T) assert fwAD.unpack_dual(dual_input_alt).tangent is not tangent # Tensors that do not have an associated tangent are automatically # considered to have a zero-filled tangent of the same shape. plain_tensor = torch.randn(10, 10) dual_output = fn(dual_input, plain_tensor) # Unpacking the dual returns a ``namedtuple`` with ``primal`` and ``tangent`` # as attributes jvp = fwAD.unpack_dual(dual_output).tangent assert fwAD.unpack_dual(dual_output).tangent is None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
使用模块
要使用前向自动微分与 nn.Module,在执行前向传递之前,将模型的参数替换为双张量。在撰写本文时,不可能创建双张量 nn.Parameter。作为解决方法,必须将双张量注册为模块的非参数属性。
import torch.nn as nn
model = nn.Linear(5, 5)
input = torch.randn(16, 5)
params = {name: p for name, p in model.named_parameters()}
tangents = {name: torch.rand_like(p) for name, p in params.items()}
with fwAD.dual_level():
for name, p in params.items():
delattr(model, name)
setattr(model, name, fwAD.make_dual(p, tangents[name]))
out = model(input)
jvp = fwAD.unpack_dual(out).tangent
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用功能模块 API(beta)
使用前向自动微分的另一种方法是利用功能模块 API(也称为无状态模块 API)。
from torch.func import functional_call # We need a fresh module because the functional call requires the # the model to have parameters registered. model = nn.Linear(5, 5) dual_params = {} with fwAD.dual_level(): for name, p in params.items(): # Using the same ``tangents`` from the above section dual_params[name] = fwAD.make_dual(p, tangents[name]) out = functional_call(model, dual_params, input) jvp2 = fwAD.unpack_dual(out).tangent # Check our results assert torch.allclose(jvp, jvp2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
自定义 autograd 函数
自定义函数还支持前向模式自动微分。要创建支持前向模式自动微分的自定义函数,请注册 jvp() 静态方法。自定义函数可以支持前向和反向自动微分,但这不是强制的。有关更多信息,请参阅文档。
class Fn(torch.autograd.Function): @staticmethod def forward(ctx, foo): result = torch.exp(foo) # Tensors stored in ``ctx`` can be used in the subsequent forward grad # computation. ctx.result = result return result @staticmethod def jvp(ctx, gI): gO = gI * ctx.result # If the tensor stored in`` ctx`` will not also be used in the backward pass, # one can manually free it using ``del`` del ctx.result return gO fn = Fn.apply primal = torch.randn(10, 10, dtype=torch.double, requires_grad=True) tangent = torch.randn(10, 10) with fwAD.dual_level(): dual_input = fwAD.make_dual(primal, tangent) dual_output = fn(dual_input) jvp = fwAD.unpack_dual(dual_output).tangent # It is important to use ``autograd.gradcheck`` to verify that your # custom autograd Function computes the gradients correctly. By default, # ``gradcheck`` only checks the backward-mode (reverse-mode) AD gradients. Specify # ``check_forward_ad=True`` to also check forward grads. If you did not # implement the backward formula for your function, you can also tell ``gradcheck`` # to skip the tests that require backward-mode AD by specifying # ``check_backward_ad=False``, ``check_undefined_grad=False``, and # ``check_batched_grad=False``. torch.autograd.gradcheck(Fn.apply, (primal,), check_forward_ad=True, check_backward_ad=False, check_undefined_grad=False, check_batched_grad=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
True
- 1
功能 API(beta)
我们还提供了 functorch 中用于计算雅可比向量积的更高级功能 API,根据您的用例,您可能会发现更简单使用。
功能 API 的好处是不需要理解或使用较低级别的双张量 API,并且可以将其与其他 functorch 转换(如 vmap)组合;缺点是它提供的控制较少。
请注意,本教程的其余部分将需要 functorch (github.com/pytorch/functorch) 来运行。请在指定的链接找到安装说明。
import functorch as ft primal0 = torch.randn(10, 10) tangent0 = torch.randn(10, 10) primal1 = torch.randn(10, 10) tangent1 = torch.randn(10, 10) def fn(x, y): return x ** 2 + y ** 2 # Here is a basic example to compute the JVP of the above function. # The ``jvp(func, primals, tangents)`` returns ``func(*primals)`` as well as the # computed Jacobian-vector product (JVP). Each primal must be associated with a tangent of the same shape. primal_out, tangent_out = ft.jvp(fn, (primal0, primal1), (tangent0, tangent1)) # ``functorch.jvp`` requires every primal to be associated with a tangent. # If we only want to associate certain inputs to `fn` with tangents, # then we'll need to create a new function that captures inputs without tangents: primal = torch.randn(10, 10) tangent = torch.randn(10, 10) y = torch.randn(10, 10) import functools new_fn = functools.partial(fn, y=y) primal_out, tangent_out = ft.jvp(new_fn, (primal,), (tangent,))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_functorch/deprecated.py:77: UserWarning:
We've integrated functorch into PyTorch. As the final step of the integration, functorch.jvp is deprecated as of PyTorch 2.0 and will be deleted in a future version of PyTorch >= 2.3\. Please use torch.func.jvp instead; see the PyTorch 2.0 release notes and/or the torch.func migration guide for more details https://pytorch.org/docs/master/func.migrating.html
- 1
- 2
- 3
使用功能 API 与模块
要使用 functorch.jvp 与 nn.Module 一起计算相对于模型参数的雅可比向量积,我们需要将 nn.Module 重新构建为一个接受模型参数和模块输入的函数。
model = nn.Linear(5, 5) input = torch.randn(16, 5) tangents = tuple([torch.rand_like(p) for p in model.parameters()]) # Given a ``torch.nn.Module``, ``ft.make_functional_with_buffers`` extracts the state # (``params`` and buffers) and returns a functional version of the model that # can be invoked like a function. # That is, the returned ``func`` can be invoked like # ``func(params, buffers, input)``. # ``ft.make_functional_with_buffers`` is analogous to the ``nn.Modules`` stateless API # that you saw previously and we're working on consolidating the two. func, params, buffers = ft.make_functional_with_buffers(model) # Because ``jvp`` requires every input to be associated with a tangent, we need to # create a new function that, when given the parameters, produces the output def func_params_only(params): return func(params, buffers, input) model_output, jvp_out = ft.jvp(func_params_only, (params,), (tangents,))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_functorch/deprecated.py:104: UserWarning:
We've integrated functorch into PyTorch. As the final step of the integration, functorch.make_functional_with_buffers is deprecated as of PyTorch 2.0 and will be deleted in a future version of PyTorch >= 2.3\. Please use torch.func.functional_call instead; see the PyTorch 2.0 release notes and/or the torch.func migration guide for more details https://pytorch.org/docs/master/func.migrating.html
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_functorch/deprecated.py:77: UserWarning:
We've integrated functorch into PyTorch. As the final step of the integration, functorch.jvp is deprecated as of PyTorch 2.0 and will be deleted in a future version of PyTorch >= 2.3\. Please use torch.func.jvp instead; see the PyTorch 2.0 release notes and/or the torch.func migration guide for more details https://pytorch.org/docs/master/func.migrating.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[0] en.wikipedia.org/wiki/Dual_number
脚本的总运行时间:(0 分钟 0.149 秒)
下载 Python 源代码:forward_ad_usage.py
下载 Jupyter 笔记本:forward_ad_usage.ipynb
雅可比矩阵、海森矩阵、hvp、vhp 等:组合函数转换
原文:
pytorch.org/tutorials/intermediate/jacobians_hessians.html译者:飞龙
注意
点击这里下载完整的示例代码
计算雅可比矩阵或海森矩阵在许多非传统的深度学习模型中是有用的。使用 PyTorch 的常规自动微分 API(Tensor.backward(),torch.autograd.grad)高效地计算这些量是困难的(或者烦人的)。PyTorch 的 受 JAX 启发的 函数转换 API 提供了高效计算各种高阶自动微分量的方法。
注意
本教程需要 PyTorch 2.0.0 或更高版本。
计算雅可比矩阵
import torch
import torch.nn.functional as F
from functools import partial
_ = torch.manual_seed(0)
- 1
- 2
- 3
- 4
让我们从一个我们想要计算雅可比矩阵的函数开始。这是一个带有非线性激活的简单线性函数。
def predict(weight, bias, x):
return F.linear(x, weight, bias).tanh()
- 1
- 2
让我们添加一些虚拟数据:一个权重、一个偏置和一个特征向量 x。
D = 16
weight = torch.randn(D, D)
bias = torch.randn(D)
x = torch.randn(D) # feature vector
- 1
- 2
- 3
- 4
让我们将 predict 视为一个将输入 x 从
R
D
→
R
D
R^D \to R^D
RD→RD 的函数。PyTorch Autograd 计算向量-雅可比乘积。为了计算这个
R
D
→
R
D
R^D \to R^D
RD→RD 函数的完整雅可比矩阵,我们将不得不逐行计算,每次使用一个不同的单位向量。
def compute_jac(xp):
jacobian_rows = [torch.autograd.grad(predict(weight, bias, xp), xp, vec)[0]
for vec in unit_vectors]
return torch.stack(jacobian_rows)
xp = x.clone().requires_grad_()
unit_vectors = torch.eye(D)
jacobian = compute_jac(xp)
print(jacobian.shape)
print(jacobian[0]) # show first row
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
torch.Size([16, 16])
tensor([-0.5956, -0.6096, -0.1326, -0.2295, 0.4490, 0.3661, -0.1672, -1.1190,
0.1705, -0.6683, 0.1851, 0.1630, 0.0634, 0.6547, 0.5908, -0.1308])
- 1
- 2
- 3
我们可以使用 PyTorch 的 torch.vmap 函数转换来消除循环并向量化计算,而不是逐行计算雅可比矩阵。我们不能直接将 vmap 应用于 torch.autograd.grad;相反,PyTorch 提供了一个 torch.func.vjp 转换,与 torch.vmap 组合使用:
from torch.func import vmap, vjp
_, vjp_fn = vjp(partial(predict, weight, bias), x)
ft_jacobian, = vmap(vjp_fn)(unit_vectors)
# let's confirm both methods compute the same result
assert torch.allclose(ft_jacobian, jacobian)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在后续教程中,反向模式自动微分和 vmap 的组合将给我们提供每个样本的梯度。在本教程中,组合反向模式自动微分和 vmap 将给我们提供雅可比矩阵的计算!vmap 和自动微分转换的各种组合可以给我们提供不同的有趣量。
PyTorch 提供了 torch.func.jacrev 作为一个方便的函数,执行 vmap-vjp 组合来计算雅可比矩阵。jacrev 接受一个 argnums 参数,指定我们想要相对于哪个参数计算雅可比矩阵。
from torch.func import jacrev
ft_jacobian = jacrev(predict, argnums=2)(weight, bias, x)
# Confirm by running the following:
assert torch.allclose(ft_jacobian, jacobian)
- 1
- 2
- 3
- 4
- 5
- 6
让我们比较两种计算雅可比矩阵的方式的性能。函数转换版本要快得多(并且随着输出数量的增加而变得更快)。
一般来说,我们期望通过 vmap 的向量化可以帮助消除开销,并更好地利用硬件。
vmap 通过将外部循环下推到函数的原始操作中,以获得更好的性能。
让我们快速创建一个函数来评估性能,并处理微秒和毫秒的测量:
def get_perf(first, first_descriptor, second, second_descriptor):
"""takes torch.benchmark objects and compares delta of second vs first."""
faster = second.times[0]
slower = first.times[0]
gain = (slower-faster)/slower
if gain < 0: gain *=-1
final_gain = gain*100
print(f" Performance delta: {final_gain:.4f} percent improvement with {second_descriptor} ")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后进行性能比较:
from torch.utils.benchmark import Timer
without_vmap = Timer(stmt="compute_jac(xp)", globals=globals())
with_vmap = Timer(stmt="jacrev(predict, argnums=2)(weight, bias, x)", globals=globals())
no_vmap_timer = without_vmap.timeit(500)
with_vmap_timer = with_vmap.timeit(500)
print(no_vmap_timer)
print(with_vmap_timer)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
<torch.utils.benchmark.utils.common.Measurement object at 0x7fc093552980>
compute_jac(xp)
1.43 ms
1 measurement, 500 runs , 1 thread
<torch.utils.benchmark.utils.common.Measurement object at 0x7fc0914a7790>
jacrev(predict, argnums=2)(weight, bias, x)
435.16 us
1 measurement, 500 runs , 1 thread
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
让我们通过我们的 get_perf 函数进行上述的相对性能比较:
get_perf(no_vmap_timer, "without vmap", with_vmap_timer, "vmap")
- 1
Performance delta: 69.4681 percent improvement with vmap
- 1
此外,很容易将问题转换过来,说我们想要计算模型参数(权重、偏置)的雅可比矩阵,而不是输入的雅可比矩阵
# note the change in input via ``argnums`` parameters of 0,1 to map to weight and bias
ft_jac_weight, ft_jac_bias = jacrev(predict, argnums=(0, 1))(weight, bias, x)
- 1
- 2
反向模式雅可比矩阵(jacrev) vs 正向模式雅可比矩阵(jacfwd)
我们提供了两个 API 来计算雅可比矩阵:jacrev 和 jacfwd:
-
jacrev使用反向模式自动微分。正如你在上面看到的,它是我们vjp和vmap转换的组合。 -
jacfwd使用正向模式自动微分。它是我们jvp和vmap转换的组合实现。
jacfwd 和 jacrev 可以互相替代,但它们具有不同的性能特征。
作为一个经验法则,如果你正在计算一个
R
N
→
R
M
R^N \to R^M
RN→RM 函数的雅可比矩阵,并且输出比输入要多得多(例如,
M
>
N
M > N
M>N),那么首选 jacfwd,否则使用 jacrev。当然,这个规则也有例外,但以下是一个非严格的论证:
在反向模式 AD 中,我们逐行计算雅可比矩阵,而在正向模式 AD(计算雅可比向量积)中,我们逐列计算。雅可比矩阵有 M 行和 N 列,因此如果它在某个方向上更高或更宽,我们可能更喜欢处理较少行或列的方法。
from torch.func import jacrev, jacfwd
- 1
首先,让我们使用更多的输入进行基准测试:
Din = 32 Dout = 2048 weight = torch.randn(Dout, Din) bias = torch.randn(Dout) x = torch.randn(Din) # remember the general rule about taller vs wider... here we have a taller matrix: print(weight.shape) using_fwd = Timer(stmt="jacfwd(predict, argnums=2)(weight, bias, x)", globals=globals()) using_bwd = Timer(stmt="jacrev(predict, argnums=2)(weight, bias, x)", globals=globals()) jacfwd_timing = using_fwd.timeit(500) jacrev_timing = using_bwd.timeit(500) print(f'jacfwd time: {jacfwd_timing}') print(f'jacrev time: {jacrev_timing}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
torch.Size([2048, 32])
jacfwd time: <torch.utils.benchmark.utils.common.Measurement object at 0x7fc091472d10>
jacfwd(predict, argnums=2)(weight, bias, x)
773.29 us
1 measurement, 500 runs , 1 thread
jacrev time: <torch.utils.benchmark.utils.common.Measurement object at 0x7fc0936e6b00>
jacrev(predict, argnums=2)(weight, bias, x)
8.54 ms
1 measurement, 500 runs , 1 thread
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后进行相对基准测试:
get_perf(jacfwd_timing, "jacfwd", jacrev_timing, "jacrev", );
- 1
Performance delta: 1004.5112 percent improvement with jacrev
- 1
现在反过来 - 输出(M)比输入(N)更多:
Din = 2048
Dout = 32
weight = torch.randn(Dout, Din)
bias = torch.randn(Dout)
x = torch.randn(Din)
using_fwd = Timer(stmt="jacfwd(predict, argnums=2)(weight, bias, x)", globals=globals())
using_bwd = Timer(stmt="jacrev(predict, argnums=2)(weight, bias, x)", globals=globals())
jacfwd_timing = using_fwd.timeit(500)
jacrev_timing = using_bwd.timeit(500)
print(f'jacfwd time: {jacfwd_timing}')
print(f'jacrev time: {jacrev_timing}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
jacfwd time: <torch.utils.benchmark.utils.common.Measurement object at 0x7fc0915995a0>
jacfwd(predict, argnums=2)(weight, bias, x)
7.15 ms
1 measurement, 500 runs , 1 thread
jacrev time: <torch.utils.benchmark.utils.common.Measurement object at 0x7fc091473d60>
jacrev(predict, argnums=2)(weight, bias, x)
533.13 us
1 measurement, 500 runs , 1 thread
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以及相对性能比较:
get_perf(jacrev_timing, "jacrev", jacfwd_timing, "jacfwd")
- 1
Performance delta: 1241.8207 percent improvement with jacfwd
- 1
使用 functorch.hessian 进行 Hessian 计算
我们提供了一个方便的 API 来计算 Hessian:torch.func.hessiani。Hessians 是雅可比矩阵的雅可比矩阵(或偏导数的偏导数,也称为二阶导数)。
这表明可以简单地组合 functorch 雅可比变换来计算 Hessian。实际上,在内部,hessian(f)就是jacfwd(jacrev(f))。
注意:为了提高性能:根据您的模型,您可能还希望使用jacfwd(jacfwd(f))或jacrev(jacrev(f))来计算 Hessian,利用上述关于更宽还是更高矩阵的经验法则。
from torch.func import hessian
# lets reduce the size in order not to overwhelm Colab. Hessians require
# significant memory:
Din = 512
Dout = 32
weight = torch.randn(Dout, Din)
bias = torch.randn(Dout)
x = torch.randn(Din)
hess_api = hessian(predict, argnums=2)(weight, bias, x)
hess_fwdfwd = jacfwd(jacfwd(predict, argnums=2), argnums=2)(weight, bias, x)
hess_revrev = jacrev(jacrev(predict, argnums=2), argnums=2)(weight, bias, x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
让我们验证无论是使用 Hessian API 还是使用jacfwd(jacfwd()),我们都会得到相同的结果。
torch.allclose(hess_api, hess_fwdfwd)
- 1
True
- 1
批处理雅可比矩阵和批处理 Hessian
在上面的例子中,我们一直在操作单个特征向量。在某些情况下,您可能希望对一批输出相对于一批输入进行雅可比矩阵的计算。也就是说,给定形状为(B, N)的输入批次和一个从
R
N
→
R
M
R^N \to R^M
RN→RM的函数,我们希望得到形状为(B, M, N)的雅可比矩阵。
使用vmap是最简单的方法:
batch_size = 64
Din = 31
Dout = 33
weight = torch.randn(Dout, Din)
print(f"weight shape = {weight.shape}")
bias = torch.randn(Dout)
x = torch.randn(batch_size, Din)
compute_batch_jacobian = vmap(jacrev(predict, argnums=2), in_dims=(None, None, 0))
batch_jacobian0 = compute_batch_jacobian(weight, bias, x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
weight shape = torch.Size([33, 31])
- 1
如果您有一个从(B, N) -> (B, M)的函数,而且确定每个输入产生独立的输出,那么有时也可以通过对输出求和,然后计算该函数的雅可比矩阵来实现,而无需使用vmap:
def predict_with_output_summed(weight, bias, x):
return predict(weight, bias, x).sum(0)
batch_jacobian1 = jacrev(predict_with_output_summed, argnums=2)(weight, bias, x).movedim(1, 0)
assert torch.allclose(batch_jacobian0, batch_jacobian1)
- 1
- 2
- 3
- 4
- 5
如果您的函数是从
R
N
→
R
M
R^N \to R^M
RN→RM,但输入是批处理的,您可以组合vmap和jacrev来计算批处理雅可比矩阵:
最后,批次 Hessian 矩阵的计算方式类似。最容易的方法是使用vmap批处理 Hessian 计算,但在某些情况下,求和技巧也适用。
compute_batch_hessian = vmap(hessian(predict, argnums=2), in_dims=(None, None, 0))
batch_hess = compute_batch_hessian(weight, bias, x)
batch_hess.shape
- 1
- 2
- 3
- 4
torch.Size([64, 33, 31, 31])
- 1
计算 Hessian 向量积
计算 Hessian 向量积的朴素方法是将完整的 Hessian 材料化并与向量进行点积。我们可以做得更好:事实证明,我们不需要材料化完整的 Hessian 来做到这一点。我们将介绍两种(许多种)不同的策略来计算 Hessian 向量积:-将反向模式 AD 与反向模式 AD 组合-将反向模式 AD 与正向模式 AD 组合
将反向模式 AD 与正向模式 AD 组合(而不是反向模式与反向模式)通常是计算 HVP 的更节省内存的方式,因为正向模式 AD 不需要构建 Autograd 图并保存反向传播的中间结果:
from torch.func import jvp, grad, vjp
def hvp(f, primals, tangents):
return jvp(grad(f), primals, tangents)[1]
- 1
- 2
- 3
- 4
以下是一些示例用法。
def f(x):
return x.sin().sum()
x = torch.randn(2048)
tangent = torch.randn(2048)
result = hvp(f, (x,), (tangent,))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果 PyTorch 正向 AD 没有覆盖您的操作,那么我们可以将反向模式 AD 与反向模式 AD 组合:
def hvp_revrev(f, primals, tangents):
_, vjp_fn = vjp(grad(f), *primals)
return vjp_fn(*tangents)
result_hvp_revrev = hvp_revrev(f, (x,), (tangent,))
assert torch.allclose(result, result_hvp_revrev[0])
- 1
- 2
- 3
- 4
- 5
- 6
脚本的总运行时间:(0 分钟 10.644 秒)
下载 Python 源代码:jacobians_hessians.py
下载 Jupyter 笔记本:jacobians_hessians.ipynb
模型集成
原文:
pytorch.org/tutorials/intermediate/ensembling.html译者:飞龙
注意
点击这里下载完整的示例代码
这个教程演示了如何使用torch.vmap来对模型集合进行向量化。
什么是模型集成?
模型集成将多个模型的预测组合在一起。传统上,这是通过分别在一些输入上运行每个模型,然后组合预测来完成的。然而,如果您正在运行具有相同架构的模型,则可能可以使用torch.vmap将它们组合在一起。vmap是一个函数变换,它将函数映射到输入张量的维度。它的一个用例是通过向量化消除 for 循环并加速它们。
让我们演示如何使用简单 MLP 的集成来做到这一点。
注意
这个教程需要 PyTorch 2.0.0 或更高版本。
import torch import torch.nn as nn import torch.nn.functional as F torch.manual_seed(0) # Here's a simple MLP class SimpleMLP(nn.Module): def __init__(self): super(SimpleMLP, self).__init__() self.fc1 = nn.Linear(784, 128) self.fc2 = nn.Linear(128, 128) self.fc3 = nn.Linear(128, 10) def forward(self, x): x = x.flatten(1) x = self.fc1(x) x = F.relu(x) x = self.fc2(x) x = F.relu(x) x = self.fc3(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
让我们生成一批虚拟数据,并假装我们正在处理一个 MNIST 数据集。因此,虚拟图像是 28x28,我们有一个大小为 64 的小批量。此外,假设我们想要将来自 10 个不同模型的预测组合起来。
device = 'cuda'
num_models = 10
data = torch.randn(100, 64, 1, 28, 28, device=device)
targets = torch.randint(10, (6400,), device=device)
models = [SimpleMLP().to(device) for _ in range(num_models)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们有几种选项来生成预测。也许我们想给每个模型一个不同的随机小批量数据。或者,也许我们想通过每个模型运行相同的小批量数据(例如,如果我们正在测试不同模型初始化的效果)。
选项 1:为每个模型使用不同的小批量
minibatches = data[:num_models]
predictions_diff_minibatch_loop = [model(minibatch) for model, minibatch in zip(models, minibatches)]
- 1
- 2
选项 2:相同的小批量
minibatch = data[0]
predictions2 = [model(minibatch) for model in models]
- 1
- 2
使用vmap来对集合进行向量化
让我们使用vmap来加速 for 循环。我们必须首先准备好模型以便与vmap一起使用。
首先,让我们通过堆叠每个参数来将模型的状态组合在一起。例如,model[i].fc1.weight的形状是[784, 128];我们将堆叠这 10 个模型的.fc1.weight以产生形状为[10, 784, 128]的大权重。
PyTorch 提供了torch.func.stack_module_state便利函数来执行此操作。
from torch.func import stack_module_state
params, buffers = stack_module_state(models)
- 1
- 2
- 3
接下来,我们需要定义一个要在上面vmap的函数。给定参数和缓冲区以及输入,该函数应该使用这些参数、缓冲区和输入来运行模型。我们将使用torch.func.functional_call来帮助:
from torch.func import functional_call
import copy
# Construct a "stateless" version of one of the models. It is "stateless" in
# the sense that the parameters are meta Tensors and do not have storage.
base_model = copy.deepcopy(models[0])
base_model = base_model.to('meta')
def fmodel(params, buffers, x):
return functional_call(base_model, (params, buffers), (x,))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
选项 1:为每个模型使用不同的小批量获取预测。
默认情况下,vmap将一个函数映射到传入函数的所有输入的第一个维度。在使用stack_module_state之后,每个params和缓冲区在前面都有一个大小为“num_models”的额外维度,小批量有一个大小为“num_models”的维度。
print([p.size(0) for p in params.values()]) # show the leading 'num_models' dimension
assert minibatches.shape == (num_models, 64, 1, 28, 28) # verify minibatch has leading dimension of size 'num_models'
from torch import vmap
predictions1_vmap = vmap(fmodel)(params, buffers, minibatches)
# verify the ``vmap`` predictions match the
assert torch.allclose(predictions1_vmap, torch.stack(predictions_diff_minibatch_loop), atol=1e-3, rtol=1e-5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
[10, 10, 10, 10, 10, 10]
- 1
选项 2:使用相同的小批量数据获取预测。
vmap有一个in_dims参数,指定要映射的维度。通过使用None,我们告诉vmap我们希望相同的小批量适用于所有 10 个模型。
predictions2_vmap = vmap(fmodel, in_dims=(0, 0, None))(params, buffers, minibatch)
assert torch.allclose(predictions2_vmap, torch.stack(predictions2), atol=1e-3, rtol=1e-5)
- 1
- 2
- 3
一个快速说明:关于哪些类型的函数可以被vmap转换存在一些限制。最适合转换的函数是纯函数:输出仅由没有副作用(例如突变)的输入决定的函数。vmap无法处理任意 Python 数据结构的突变,但它可以处理许多原地 PyTorch 操作。
性能
对性能数字感到好奇吗?这里是数字的表现。
from torch.utils.benchmark import Timer
without_vmap = Timer(
stmt="[model(minibatch) for model, minibatch in zip(models, minibatches)]",
globals=globals())
with_vmap = Timer(
stmt="vmap(fmodel)(params, buffers, minibatches)",
globals=globals())
print(f'Predictions without vmap {without_vmap.timeit(100)}')
print(f'Predictions with vmap {with_vmap.timeit(100)}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Predictions without vmap <torch.utils.benchmark.utils.common.Measurement object at 0x7f48efb85b40>
[model(minibatch) for model, minibatch in zip(models, minibatches)]
2.26 ms
1 measurement, 100 runs , 1 thread
Predictions with vmap <torch.utils.benchmark.utils.common.Measurement object at 0x7f48efb85ea0>
vmap(fmodel)(params, buffers, minibatches)
791.58 us
1 measurement, 100 runs , 1 thread
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用vmap有很大的加速!
一般来说,使用vmap进行向量化应该比在 for 循环中运行函数更快,并且与手动批处理竞争。不过也有一些例外,比如如果我们没有为特定操作实现vmap规则,或者底层内核没有针对旧硬件(GPU)进行优化。如果您看到这些情况,请通过在 GitHub 上开启一个问题来告诉我们。
脚本的总运行时间:(0 分钟 0.798 秒)
下载 Python 源代码:ensembling.py
下载 Jupyter 笔记本: ensembling.ipynb
每个样本的梯度
原文:
pytorch.org/tutorials/intermediate/per_sample_grads.html译者:飞龙
注意
点击这里下载完整示例代码
它是什么?
每个样本梯度计算是计算批量数据中每个样本的梯度。在差分隐私、元学习和优化研究中,这是一个有用的量。
注意
本教程需要 PyTorch 2.0.0 或更高版本。
import torch import torch.nn as nn import torch.nn.functional as F torch.manual_seed(0) # Here's a simple CNN and loss function: class SimpleCNN(nn.Module): def __init__(self): super(SimpleCNN, self).__init__() self.conv1 = nn.Conv2d(1, 32, 3, 1) self.conv2 = nn.Conv2d(32, 64, 3, 1) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = torch.flatten(x, 1) x = self.fc1(x) x = F.relu(x) x = self.fc2(x) output = F.log_softmax(x, dim=1) output = x return output def loss_fn(predictions, targets): return F.nll_loss(predictions, targets)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
让我们生成一批虚拟数据,并假装我们正在处理一个 MNIST 数据集。虚拟图像是 28x28,我们使用大小为 64 的小批量。
device = 'cuda'
num_models = 10
batch_size = 64
data = torch.randn(batch_size, 1, 28, 28, device=device)
targets = torch.randint(10, (64,), device=device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在常规模型训练中,人们会将小批量数据通过模型前向传播,然后调用 .backward() 来计算梯度。这将生成整个小批量的‘平均’梯度:
model = SimpleCNN().to(device=device)
predictions = model(data) # move the entire mini-batch through the model
loss = loss_fn(predictions, targets)
loss.backward() # back propagate the 'average' gradient of this mini-batch
- 1
- 2
- 3
- 4
- 5
与上述方法相反,每个样本梯度计算等同于:
- 对于数据的每个单独样本,执行前向和后向传递以获得单个(每个样本)梯度。
def compute_grad(sample, target): sample = sample.unsqueeze(0) # prepend batch dimension for processing target = target.unsqueeze(0) prediction = model(sample) loss = loss_fn(prediction, target) return torch.autograd.grad(loss, list(model.parameters())) def compute_sample_grads(data, targets): """ manually process each sample with per sample gradient """ sample_grads = [compute_grad(data[i], targets[i]) for i in range(batch_size)] sample_grads = zip(*sample_grads) sample_grads = [torch.stack(shards) for shards in sample_grads] return sample_grads per_sample_grads = compute_sample_grads(data, targets)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
sample_grads[0] 是模型 conv1.weight 的每个样本梯度。model.conv1.weight.shape 是 [32, 1, 3, 3];注意每个样本在批处理中有一个梯度,总共有 64 个。
print(per_sample_grads[0].shape)
- 1
torch.Size([64, 32, 1, 3, 3])
- 1
每个样本梯度,高效的方式,使用函数转换
我们可以通过使用函数转换来高效地计算每个样本的梯度。
torch.func 函数转换 API 对函数进行转换。我们的策略是定义一个计算损失的函数,然后应用转换来构建一个计算每个样本梯度的函数。
我们将使用 torch.func.functional_call 函数来将 nn.Module 视为一个函数。
首先,让我们从 model 中提取状态到两个字典中,parameters 和 buffers。我们将对它们进行分离,因为我们不会使用常规的 PyTorch autograd(例如 Tensor.backward(),torch.autograd.grad)。
from torch.func import functional_call, vmap, grad
params = {k: v.detach() for k, v in model.named_parameters()}
buffers = {k: v.detach() for k, v in model.named_buffers()}
- 1
- 2
- 3
- 4
接下来,让我们定义一个函数来计算模型给定单个输入而不是一批输入的损失。这个函数接受参数、输入和目标是很重要的,因为我们将对它们进行转换。
注意 - 因为模型最初是为处理批量而编写的,我们将使用 torch.unsqueeze 来添加一个批处理维度。
def compute_loss(params, buffers, sample, target):
batch = sample.unsqueeze(0)
targets = target.unsqueeze(0)
predictions = functional_call(model, (params, buffers), (batch,))
loss = loss_fn(predictions, targets)
return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在,让我们使用 grad 转换来创建一个新函数,该函数计算相对于 compute_loss 的第一个参数(即 params)的梯度。
ft_compute_grad = grad(compute_loss)
- 1
ft_compute_grad 函数计算单个(样本,目标)对的梯度。我们可以使用 vmap 来让它计算整个批量样本和目标的梯度。注意 in_dims=(None, None, 0, 0),因为我们希望将 ft_compute_grad 映射到数据和目标的第 0 维,并对每个使用相同的 params 和 buffers。
ft_compute_sample_grad = vmap(ft_compute_grad, in_dims=(None, None, 0, 0))
- 1
最后,让我们使用我们转换后的函数来计算每个样本的梯度:
ft_per_sample_grads = ft_compute_sample_grad(params, buffers, data, targets)
- 1
我们可以通过使用 grad 和 vmap 来双重检查结果,以确保与手动处理每个结果一致:
for per_sample_grad, ft_per_sample_grad in zip(per_sample_grads, ft_per_sample_grads.values()):
assert torch.allclose(per_sample_grad, ft_per_sample_grad, atol=3e-3, rtol=1e-5)
- 1
- 2
一个快速说明:关于哪些类型的函数可以被 vmap 转换存在一些限制。最适合转换的函数是纯函数:输出仅由输入决定,并且没有副作用(例如突变)。vmap 无法处理任意 Python 数据结构的突变,但它可以处理许多原地 PyTorch 操作。
性能比较
想知道 vmap 的性能如何?
目前最佳结果是在新型 GPU(如 A100(Ampere))上获得的,在这个示例中我们看到了高达 25 倍的加速,但是这里是我们构建机器上的一些结果:
def get_perf(first, first_descriptor, second, second_descriptor): """takes torch.benchmark objects and compares delta of second vs first.""" second_res = second.times[0] first_res = first.times[0] gain = (first_res-second_res)/first_res if gain < 0: gain *=-1 final_gain = gain*100 print(f"Performance delta: {final_gain:.4f} percent improvement with {first_descriptor} ") from torch.utils.benchmark import Timer without_vmap = Timer(stmt="compute_sample_grads(data, targets)", globals=globals()) with_vmap = Timer(stmt="ft_compute_sample_grad(params, buffers, data, targets)",globals=globals()) no_vmap_timing = without_vmap.timeit(100) with_vmap_timing = with_vmap.timeit(100) print(f'Per-sample-grads without vmap {no_vmap_timing}') print(f'Per-sample-grads with vmap {with_vmap_timing}') get_perf(with_vmap_timing, "vmap", no_vmap_timing, "no vmap")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Per-sample-grads without vmap <torch.utils.benchmark.utils.common.Measurement object at 0x7f883d01eaa0>
compute_sample_grads(data, targets)
92.24 ms
1 measurement, 100 runs , 1 thread
Per-sample-grads with vmap <torch.utils.benchmark.utils.common.Measurement object at 0x7f883cf3bf40>
ft_compute_sample_grad(params, buffers, data, targets)
8.65 ms
1 measurement, 100 runs , 1 thread
Performance delta: 966.7210 percent improvement with vmap
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在 PyTorch 中有其他优化的解决方案(例如 github.com/pytorch/opacus)来计算每个样本的梯度,这些解决方案的性能也比朴素方法更好。但是将 vmap 和 grad 组合起来给我们带来了一个很好的加速。
一般来说,使用 vmap 进行向量化应该比在 for 循环中运行函数更快,并且与手动分批处理相竞争。但也有一些例外情况,比如如果我们没有为特定操作实现 vmap 规则,或者如果底层内核没有针对旧硬件(GPU)进行优化。如果您遇到这些情况,请通过在 GitHub 上开启一个问题来告诉我们。
脚本的总运行时间: ( 0 分钟 10.810 秒)
下载 Python 源代码: per_sample_grads.py
下载 Jupyter 笔记本: per_sample_grads.ipynb

