
- 1接入飞书的 ChatGPT 对话机器人,SAM 来了
- 2Linux驱动开发入门_linux驱动开发入门 李山文
- 3Hive--清除/删除Hive表数据,where条件_hive 清空表
- 43dmax渲染全景图参数设置 3dmax云渲染插件使用_3dmax全景摄像机怎么设置
- 52021年南昌十五中高考成绩查询,喜报|2020年南昌市高考喜报合集(更新时间:2020.9.14))...
- 6自然语言处理NLP:LTP、SnowNLP、HanLP 常用NLP工具和库对比_nltk和snownlp比较
- 7探秘Fake SMTP Server:一款强大的模拟邮件服务器工具
- 8git:git用户push后无法弹出输入指定gitee的用户及密码的窗口_git push 指定用户
- 9论前端信息加密必须性(要不要加密、如何加密)
- 10基于ksvd分解的过完备字典在一维机械信号重构上的应用_ksvd机械信号
2022李宏毅机器学习深度学习学习笔记第六周--BERT的变体_机器学习中的token
赞
踩
前言
本文讲怎么得到pre-train的模型以及预测下一个token模型,介绍两种盖住token的方法,之后讲UniLM的运作过程。
我们希望可以有一个pre-train的模型,把一串token吃进去,把每一串token变成一个embedding vector,我们希望这些embedding vector是可以考虑上下文的,训练这种model多数情况下用的方法是unsupervised。
Pre-training by Translation
1.context vector (cove)
用Translation的方法来训练model的。
怎么用Translation来得到model呢?
把model当作Translation的encoder,如下图,在训练Translation的时候,输入是一个A language,decoder根据encoder的输出得到B language的输出,最大的问题就是需要大量的pairs data才能训练这样的model。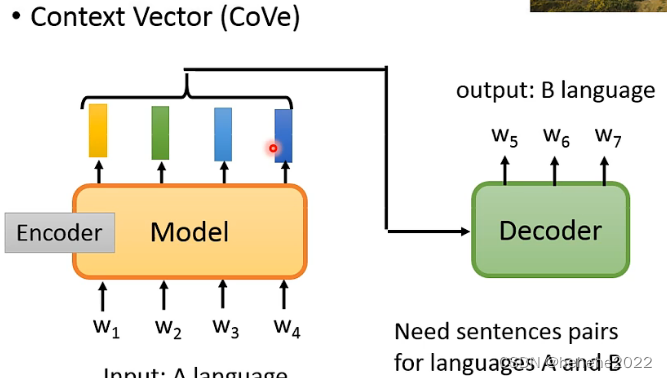
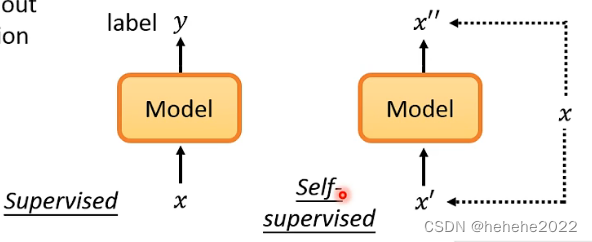
怎样用没有标注的文字就可以直接训练一个模型,过去这样的方法叫做unsupervised learning,近年来更长被叫做Self-supervised Learning (用部分的输入去预测另外一部分的输入)。
Predict Next Token
预测下一个token
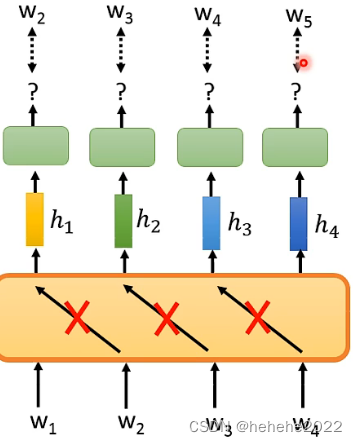
训练一个模型,输入w1,输出h1,根据h1预测w2。
h1怎么预测w2?
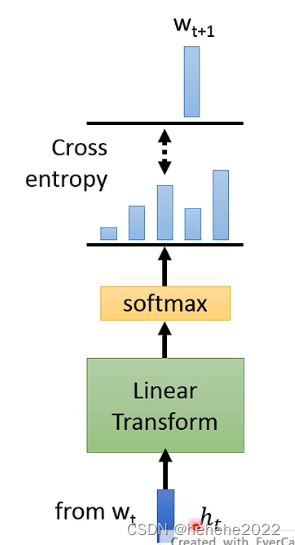
有一个ht,是从wt得到的,通过一个Linear Transform,再加softmax,每个token都给他一个几率,希望和训练的目标的Cross emtropy 越小越好。
预测下一个token是最早的unsupervised的模型。
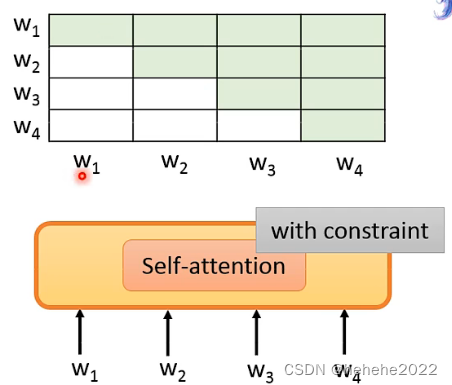
如果network的架构是Self-attention 要注意控制attention的范围,Self-attention 做的就是把整个序列读进去,每一个位置都可以看到其他的位置,表中有涂色的位置代表可以attention的位置,在w1的位置只能attention自己,在w2的位置只能attention w1和w2,就可以避免模型在预测下一个token看到下一个答案。
ELMO考虑了right context的事情。
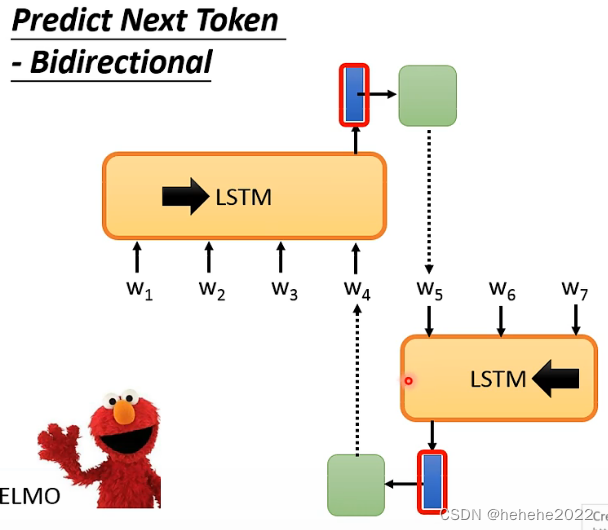
ELMO有一个LSTM,看w1-4来预测w5,有一个由右到左的LSTM,w7-5,产生一个embedding,来预测w4,在得到w4的输出时,不止考虑左边的上下文,也考虑了右边的上下文,正逆向LSTM没有交际。
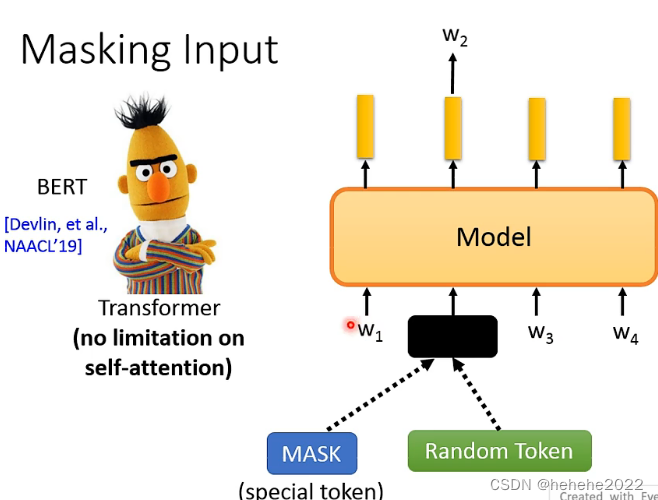
Masking Input
BERT做的事情是把输入的一些token盖住,盖住有两种做法,MASK(有一个特别的符号叫MASK,把原来的token盖住)和Random Token(随机生成一个token盖住),根据这个位置输出的embedding预测盖起来的token原来是什么。BERT里面用的是transformer(用Self-attention是没有限制的)
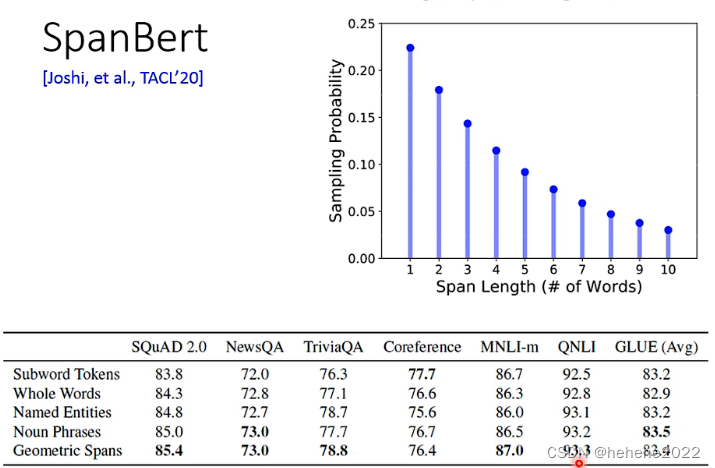
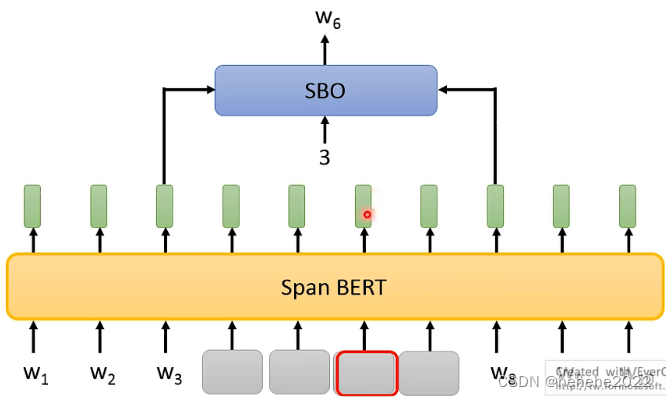
在原始的BERT中要mask的token是随机的,有一些复杂的masking的方法,比如whole word masking (wwm)一次盖一整个word词;Phrase-level(好几个word合起来就是一个phrase)&Entity-level(关心的人、地名等就是entity)。还有一种masking的方法叫做SpanBert,一次覆盖掉一个很长的范围。
提出了一种训练的方法叫做Span Boundary Objective(SBO),希望从盖住范围的两边的embedding去预测盖住范围内有什么样的东西,给他输入3,代表要还原w6。
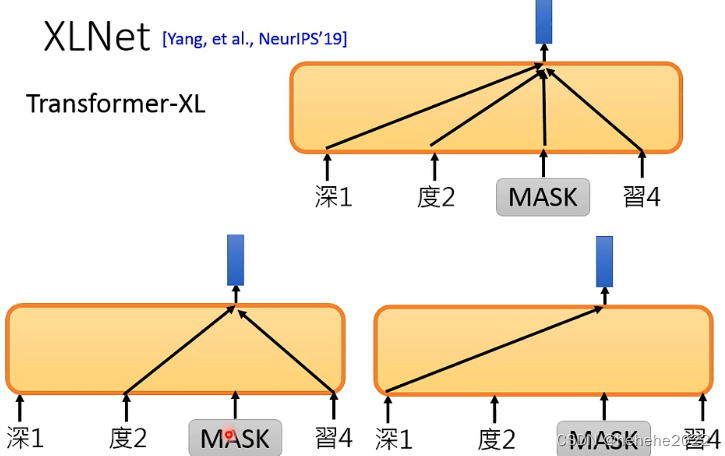
XLNet
Transformer-XL
只根据句子的一部分去预测token,但具体是那一部分是随机的。
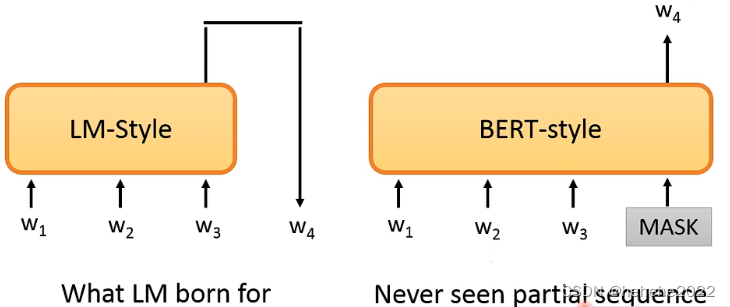
BERT cannot talk?
BERT 不擅长做generation task,把BERT用在seq2seq需要产生句子,需要给部分的句子然后预测下一个token。
怎么用这种self-supervised learning的方法来pre-train一个seq2seq的模型。
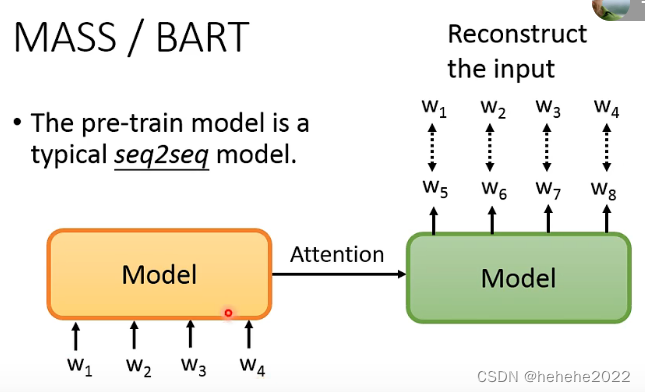
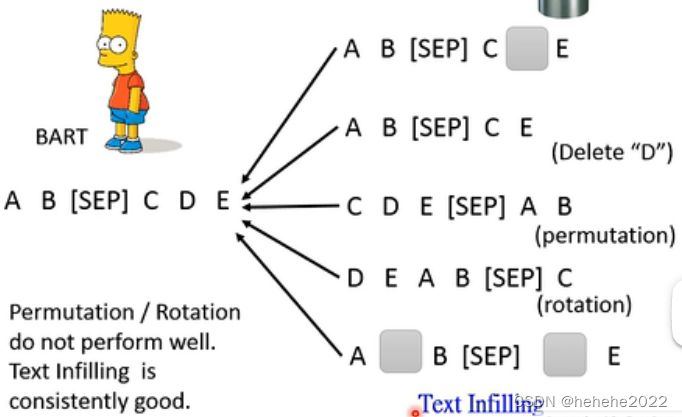
输入一个序列,进入encoder,通过attention,再decoder,输出也是w1-w4,要把输入的部分做某种程度的破坏。破坏的方法有MASS(MAsked sequence to sequence pre-train)和BART(Bidirectional and Auto-Regressive Transformers)。
MASS把一些部分随机用mass的token替代掉,还有一个方法是直接删掉,permutation是把顺序打乱,rotation是把某些放在尾部的拿到前面来,text infilling是会在句子中加入mask。BART的结论是permutation和rotation不太好,最好的方法是text infilling。
UniLM
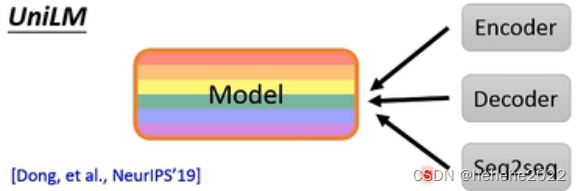
还有一个叫UniLM,这个model同时是encoder、decoder、seq2seq。
UniLM的运作图:
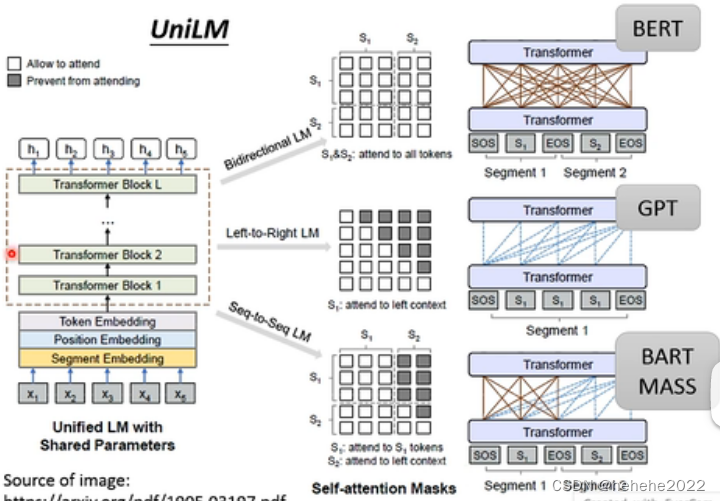
就是一个有很多self-attention layer的模型,一个model同时进行三种训练,第一种训练和BERT 一样,把一些token mask起来,预测mask的token,同时也做GPT的训练,把它当作一个language model来用,也可以当作seq2seq来使用,把token序列分成两部分,输入第一个token序列时可以互相看做self-attention,但是第二个token都只能看左边。
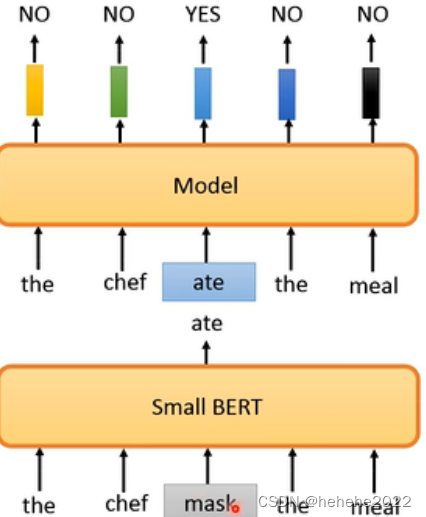
到目前为止讲的pre-train的方法都是要预测一些资讯,要么是预测下一个部分,要么是预测被盖起来的部分,但是有没有其他的做法,有一个叫做ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)的,不做预测只回答yes/no,它的model吃一个句子进来,把其中一些部分置换成其他词汇,输出yes表示被置换掉,no表示没有被置换掉,好处是预测YES/NO比reconstruction简单。
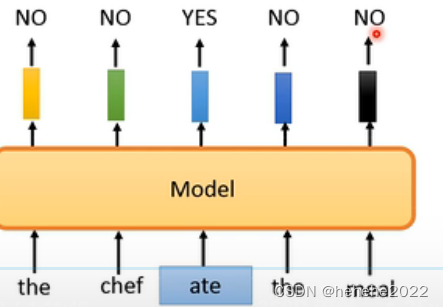
如果置换成一些奇怪的token,很容易被发现,ELECTRA学不到什么,所以用一个比较小的BERT去产生mask起来的东西。
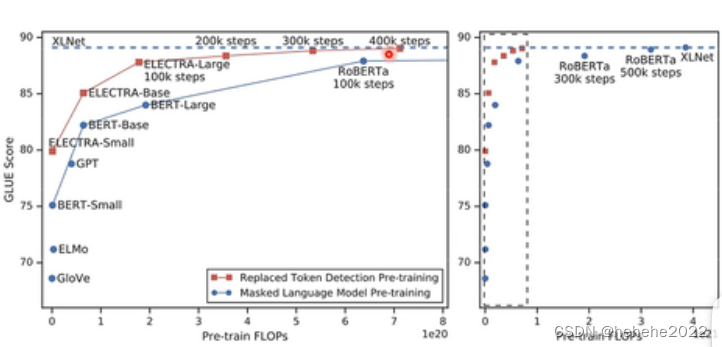
ELECTRA的结果
横轴是训练时的运算量,纵轴是在八个子任务上的平均成绩,运算量越多,performance也越好。
有时候要给整个序列一个embedding,比如对整个句子做分类的时候。
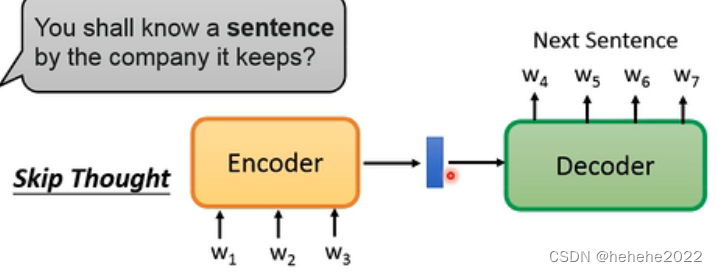
Skip Thought
训练一个seq2seq的模型,把句子读进去通过一个encoder变成一个向量,根据decoder预测下一句是什么。
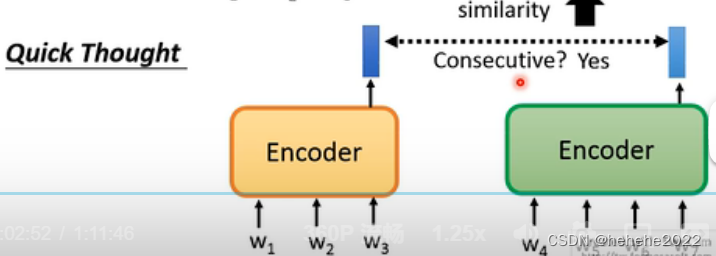
Quick Thought
有两个句子各自通过encoder得到embedding,这两个句子相邻,就让embedding越相近越好。
总结
BERT的两个预训练任务分别是:随机抹去一个/几个词,预测被抹去的词是什么;以及判定两句话是否相邻。然后了解了BERT的变体。

