
- 1yum基本使用方法
- 2Akka源码分析-Persistence-AtLeastOnceDelivery
- 3socket编程——UDP协议(C语言编程)_udp socket c语言
- 4kubectl常用相关命令_kubectl apply -f -n
- 5django搭建一个小型的服务器运维网站-拿来即用的bootstrap模板
- 6HTTP和HTTPS详解
- 7阿里云服务器命令_阿里云命令码
- 82 交换机的Telnet远程登陆配置_交换机的telnet远程登录配置
- 9ubuntu12.04 安装配置mysql_ubuntu12配置mysql
- 10VMware Workstation15.1.0安装Windows 1903虚拟机_vm安装1903
面向端边协同分类推理任务的语义隐私保护机制研究
赞
踩
面向端边协同分类推理任务的语义隐私保护
机制研究
1
.研究背景
近年来,端边协同的深度神经网络推理(Device-Edge Collaborative Deep Neural Network Inference,简称DNN Co-inference)技术备受瞩目,已广泛运用于多种基于神经网络的编码器-解码器结构语义通信框架。该技术的核心思想是将深度神经网络分段部署在终端设备和边缘服务器上,以提高推理任务速度、效率,并降低能源消耗。
在各类DNN中,分类器(Classifier)是最常见、应用范围最广的模型,其应用时,用户数据隐私问题也备受关注。尽管在DNN Co-inference模式下,不要求用户在推理时直接上传原始数据,但研究发现,攻击者仍然可以从用户上传的中间特征向量中提取敏感信息。例如,在人脸识别任务中,攻击者可以获取性别、人种等信息,甚至还原用户的完整人脸图像。
为了应对这一挑战,已经涌现出一些隐私保护方法,大致可分为两类。首先是直接加密、加噪方法,如同态加密、安全多方计算和基于差分隐私的加噪方法。它们不考虑数据语义,统一对要上传的信息进行加密或加噪,但通常伴随着昂贵的计算开销或精度损失。另一类是过滤干扰方法,包括对抗训练和部分加噪等。这些方法通常关注于保护与分类结果无关的隐私信息,即将分类结果假定为不需要保护的内容。然而,现实情况是,分类结果通常也是用户非常关注的敏感信息,往往蕴含与用户高度相关的私有语义信息。例如,在人脸性别识别中,用户可能需要性别判别服务,但并不希望透露自己的性别信息给边缘智能服务提供商。
为了应对以上挑战,我们设计了Roulette,一个面向端边协同分类推理任务的语义隐私保护框架。Roulette在分类任务语义数据隐私保护和分类模型性能精度之间取得了很好平衡,为进一步发展未来6G DNN Co-inference实用技术提供了有益的参考。
2
.所提出方法
首先,让我们通过示意图1来了解Roulette的核心思想。考虑一个图片分类系统,其中包含了至少两个类别:“猫”和“狗”。假设一张输入图片的真实类别是“猫”。在传统的Co-inference框架下,经过协同推理,将得到正确的推理结果:“猫”。然而,Roulette采用一种独特的方法。它通过本地数据重新训练了部署在用户终端的神经网络。这个重新训练的网络使得边缘服务器能够从中间特征向量中进一步计算并获得推理结果:“狗”,而不是“猫”。然后,服务器将这个“狗”的结果发送回用户终端。接着,用户终端使用一个预定义的映射表来转换这个“狗”的结果,最终得到了正确的分类结果:“猫”。
这个过程中需要特别强调的是,Roulette与传统的迁移学习方法有所不同。传统方法通常会将网络的前半部分固定不动,然后微调网络的后半部分。而Roulette则采用一种创新性的方式,它一直保持用户终端的神经网络不变,而是利用本地数据对终端模型进行重新训练。这个独特的方法使得用户仍然可以获得正确的推理结果,同时边缘服务器却无法获知真实的类别信息。
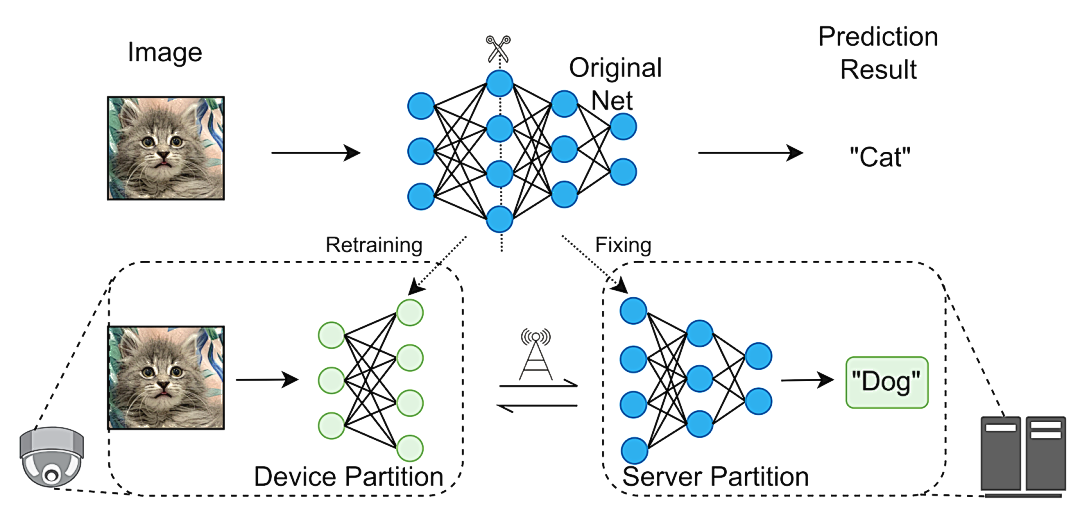
图1. Roulette核心思路示意图.
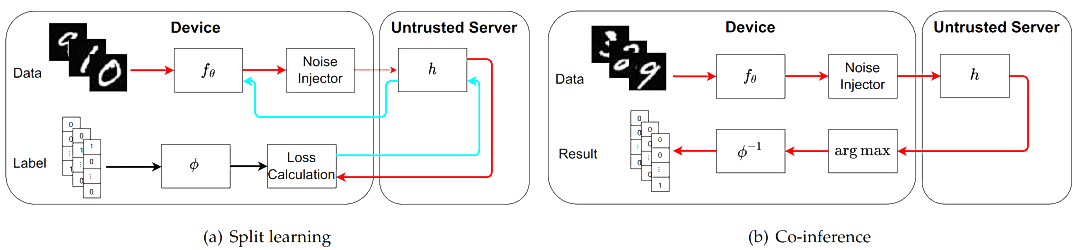
图2. 一个批次(batch)数据分别在训练 (a) 和推理 (b) 中的数据流.
接下来,我们将深入探讨Roulette在处理数据批次时的流程,如图2所示。这个流程包括训练和推理两个关键环节。值得注意的是,在本地DNN计算完成后,Roulette采取了一项关键举措,即在发送中间向量之前对其进行加噪处理,以提供差分隐私保障。这一步骤确保了本地数据隐私的安全性。接着,在边缘服务器完成计算后,服务器将计算结果返回给用户端设备,实现了全过程的协同推理。
为了满足用户需求,Roulette需要随机重新生成图片类别与原有标签之间的映射关系。因此,除了优化分类精度,我们还需要进行特征对齐。我们采用了对抗训练的方法来实现这一目标,其中包括两个重要的损失函数:
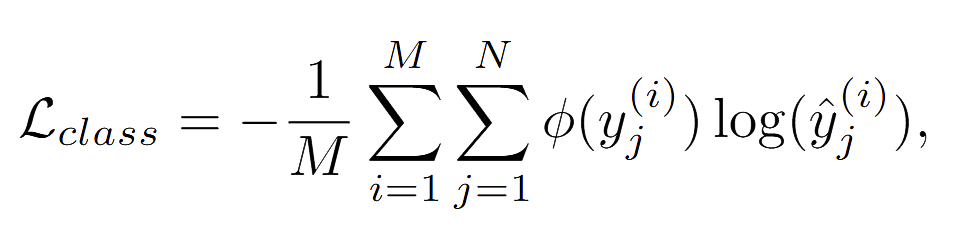
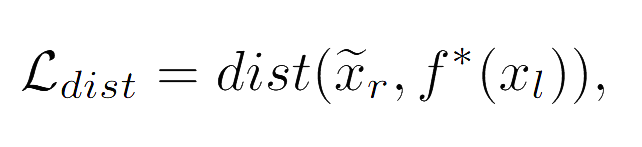
其中,第一项损失函数是常规的交叉熵函数,其主要作用是降低分类任务的经验损失。而第二项损失函数则致力于确保经过修改的本地模型所产生的中间向量尽可能地接近未修改模型的本地输出。这两个损失函数共同构成了我们训练模型的目标。
为了实现模型的训练,我们采用了一种交替更新的策略,如图3所示。在这个过程中,我们将上述两个损失函数的和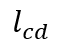 作为优化的目标,不断迭代更新模型,以确保模型能够兼顾分类精度和特征对齐的需求。这一训练策略是Roulette框架的重要组成部分,有助于实现模型的优化和精细调整。
作为优化的目标,不断迭代更新模型,以确保模型能够兼顾分类精度和特征对齐的需求。这一训练策略是Roulette框架的重要组成部分,有助于实现模型的优化和精细调整。

图3. 混合交替训练算法
最后,我们对Roulette进行了深入的理论分析,首先提供了Roulette的差分隐私预算理论上界,这为隐私保护提供了强有力的理论支撑。此外,我们从计算复杂性的角度证明了对中间向量进行推理攻击的困难性。具体而言,如果边缘服务器对于本地模型参数或本地数据分布的知识缺乏其中之一,那么有效近似恢复本地原始数据将变得极为困难。
当然,Roulette还包含许多其他设计细节,在本文中,我们仅着重介绍了其核心原理和工作流程,以帮助读者迅速理解其关键概念。实际上,Roulette的细节非常丰富且具有深度,例如图2中映射函数φ的设计等。对于对Roulette的详细了解感兴趣的读者,欢迎阅读 [1] 以获悉详情。
3
.实验结果
我们对Roulette保护隐私的效果进行了测试。我们总共对其进行了三种攻击测试,分别是模型反解攻击(model inversion attack), 梯度反解攻击(gradient inversion attack)和影子模型攻击(shadow model attack)。图4和图5分别是模型反解攻击的视觉和量化指标对比结果。可以看到相比于其他基线方法,比如单纯加噪和Dropout,Roulette隐私保护效果显著。图6是梯度反解攻击与联邦学习FedAvg相比的结果,结果显示Roulette可以较好地抵御联邦学习经典算法FedAvg不容易抵御的梯度反解攻击。影子模型攻击是对框架Roulette最有针对性的攻击,实验结果显示(图7),即使设定边缘服务器获悉本地模型结构(一般而言不可能),如果本地分布和原训练模型的数据分布差距略微较大,Roulette即可实现较好隐私保护效果。同时还可以从图7中看出,Roulette可以提高模型精度。我们还测试了在不同的总隐私预算下,Roulette的精度(图8),实验结果表明,在相当宽范围的隐私预算下,Roulette可以达到很好的模型精度。


图4. 模型反解攻击视觉效果对比

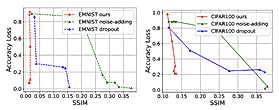
图5. 模型反解攻击量化指标对比

图6. 梯度反解攻击
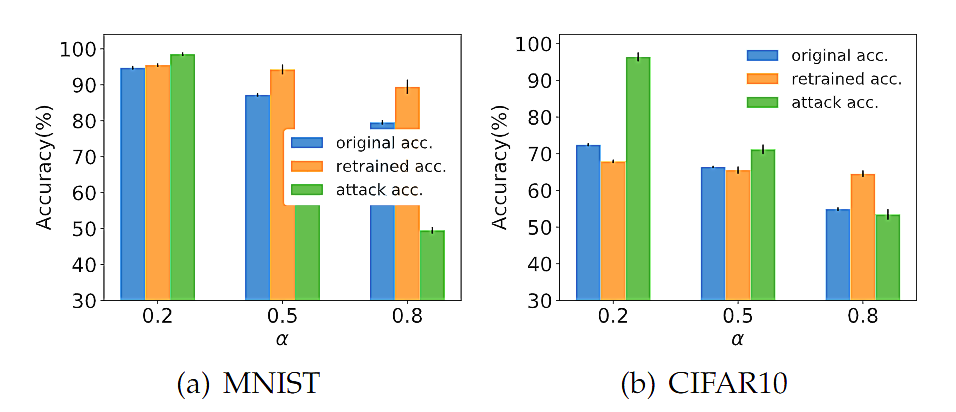
图7. 不同分布下,原始精度、重训精度和攻击精度对比
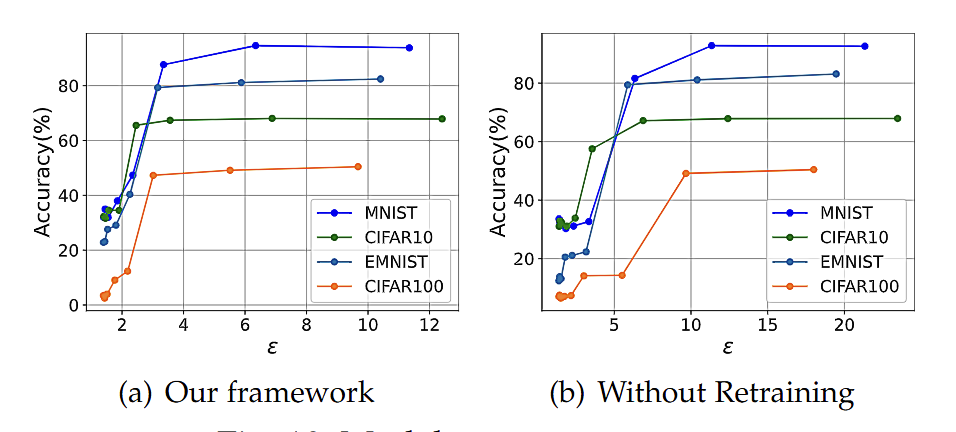
图8. 模型精度与差分隐私预算
最后,我们还测试了在不同分割点下,Roulette可以达到的推理精度,如图9所示。我们可以观察到,在很多选择下,模型可以达到一个令人满意的精度同时本地模型大小相对较小,中间向量大小也比较小,这意味着Roulette可以在Co-inference框架下,兼顾精度和效率。
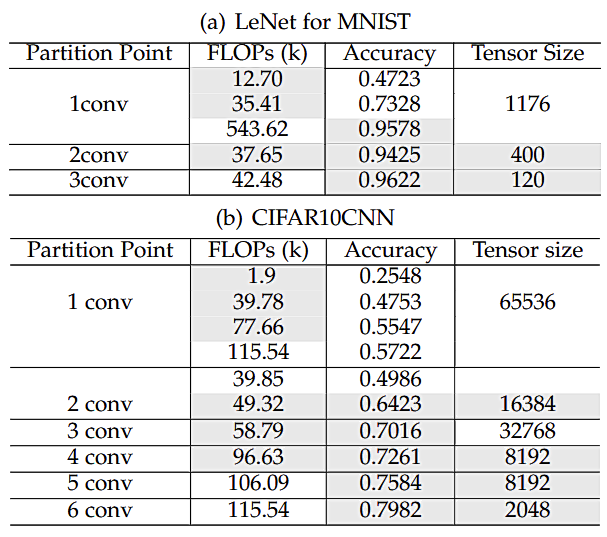
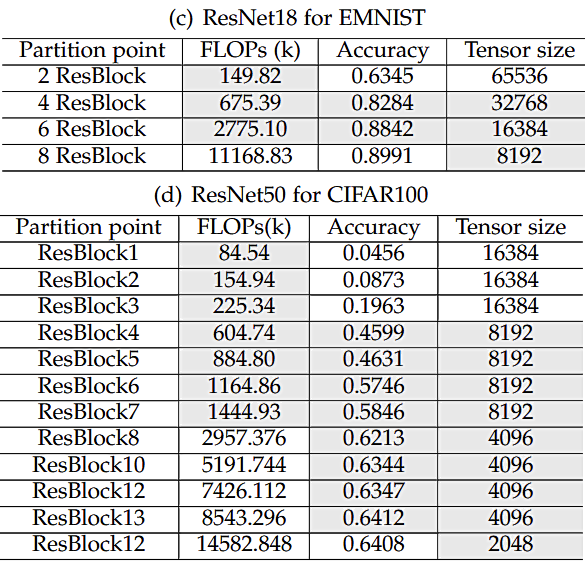
图9. 不同本地模型大小和分割点下Roulette可以达到的精度

总结
在本文中,针对端边协同的深度学习分类器,我们设计了一个名为Roulette的分类任务语义隐私保护框架。与传统的协同推理方法不同,我们采用了分割学习的策略,对本地网络进行重新训练,以确保远程网络无法获取准确的推理结果,从而保护了语义隐私并提高了模型的准确性。此外,为了实现差分隐私,我们允许本地设备在将深度神经网络的中间表示上传到边缘服务器之前,对输入数据进行无效化处理并添加噪声。我们进行了广泛的评估实验,测试了Roulette框架在抵御各种主要攻击方案下的性能表现。实验结果表明,我们提出的框架能够高效保护分类任务语义隐私,同时保持出色的模型准确性。
[1] J. Li, G. Liao, L. Chen and X. Chen, "Roulette: A Semantic Privacy-Preserving Device-Edge Collaborative Inference Framework for Deep Learning Classification Tasks" , accepted by IEEE Transactions on Mobile Computing, 2023.
Online: https://arxiv.org/abs/2309.02820

