
- 1CUDA out of memory. Tried to allocate 56.00 MiB (GPU 0; 23.70 GiB total capacity; 22.18 GiB already_tried to allocate 56.00 mib 为什么越来越大
- 2详解:把 Linux 系统做成 Livecd
- 3MQTT 使用MQTT.fx实现阿里云通信_阿里云mqtt如何通信
- 420240304-2-计算机网络
- 5ConstraintLayout的一些黑科技_constraintlayout app:layout_constraintcircleradius
- 6微信群聊天记录里的信息快速导到Excel表格_聊天记录txt转化为表格文件
- 7网站去色_baxbax网站
- 8解决IE8下提示'console'未定义错误_console未定义解决方法
- 910年研发老兵:如何构建适合自己的DevOps工具与平台
- 10基于流计算 Oceanus(Flink) CDC 做好数据集成场景
【Simple Baselines】《Simple Baselines for Human Pose Estimation and Tracking》
赞
踩

ECCV-2018
1 Background and Motivation
在 《Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation》和 Deeppose 的引领下,人体姿态评估进入了 DCNN 时代,几年的发展,基于 DCNN 的人体姿态评估方法已经在 MPII 和 COCO 数据集上实现了精度上的飞跃,随着人体姿势评估的快速成熟,“simultaneous pose detection and tracking in the wild” 任务成为了人们攻克的新目标
然而,architecture and experiment practice have steadily become more complex,精度却一直比较暧昧,this makes the algorithm analysis and comparison more difficult(不知道哪个方向,哪个细节更影响精度)
于是作者大繁若简,搞了一个 Simple Baseline,除去繁华,追求最存粹的真善美(简单实用)
在 challenging benchmark 上实现了 SOTA,比 the winner of ICCV’17 PoseTrack Challenge 和 the winner of COCO 2017 keypoint Challenge 精度都高!
2 Advantages / Contributions
用简单的 resnet 配合 de-convolution,实现了 human pose estimation and tracking 的 SOTA
We hope such baselines would benefit the field by easing the idea development and evaluation.
3 Method
3.1 Pose Estimation Using A Deconvolution Head Network
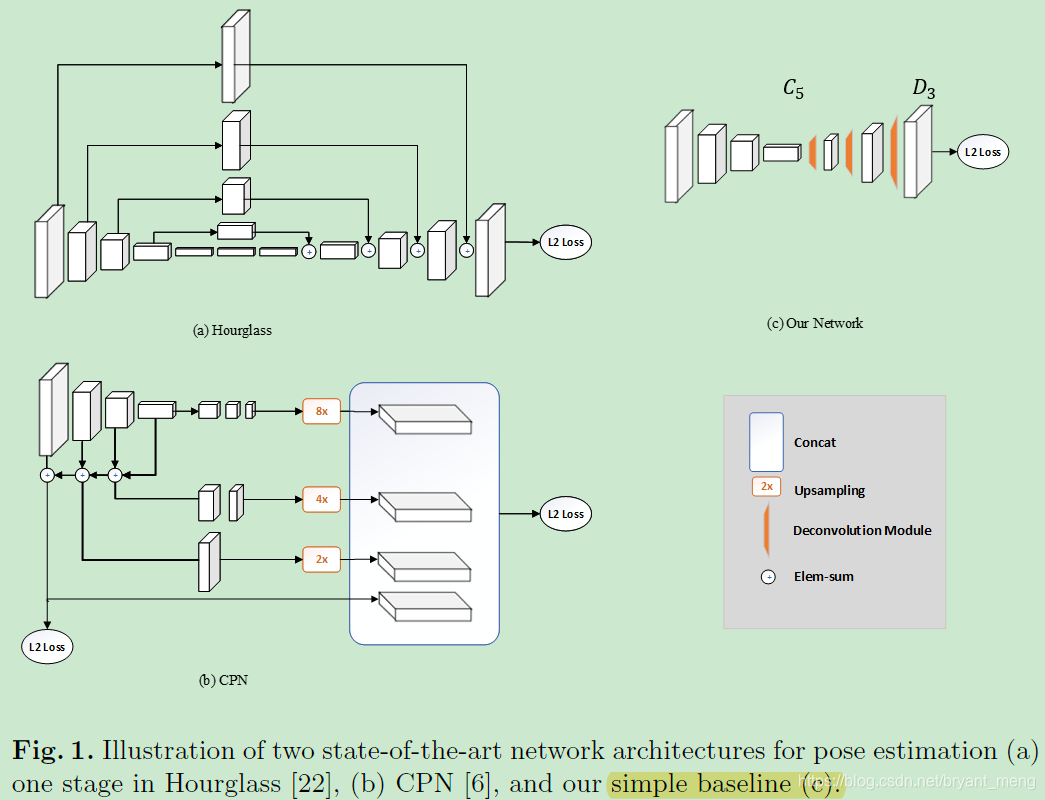
三种结构的共同点是 three upsampling steps and also three levels of non-linearity (from the deepest feature) are used to obtain high resolution feature maps and heatmaps.
作者的观测是
obtaining high resolution feature maps is crucial, but no matter how
然后还来了句
It is hard to conclude which architecture in Fig. 1 is better
反正在 MS COCO 这个数据集上,朴实无华的 resnet 有一战之力
作者的方法比较直接,用 ResNet 配合 3 个 deconvolution (deconvolution 用的是 4×4 的 kernel,256 个 filters,stride 为 2)就搞定了,学了这个方法,再看别人的方法,感觉都像是……

作者采用 MSE loss 来计算 GT 和 predict 的热力图,GT 的处理和 【Stacked Hourglass】《Stacked Hourglass Networks for Human Pose Estimation》 一样,都是常规操作
给我一种,只要风大(数据够,训练的久),猪(朴实无华的网络)飞起来(效果追上来)不是不可能的感觉

3.2 Pose Tracking Based on Optical Flow
略,感觉把文章的核心给略了,哈哈

4 Experiments
4.1 Datasets
- COCO MS
train:COCO train2017 dataset (includes 57K images and 150K person instances)
ablation:COCO val2017
report the final results: COCO test-dev2017
评价指标是 AP,和目标检测的区别是用 OKS 替换了 IoU,细节可以参考 MS COCO 目标检测 、人体关键点检测评价指标
作者这两句话也提炼的蛮 nice
The OKS plays the same role as the IoU in object detection. It is calculated from the distance between predicted points and ground truth points normalized by scale of the person.
4.2 Pose Estimation on COCO
1)Training:
人的框框被设定为固定的比例,4:3,It is then cropped from the image and resized to a fixed resolution,eg:256×192
ResNet 用 ImageNet pretrained 模型
2)Testing:
先用 faster-RCNN detector with detection AP 56.4 for the person category on COCO val2017,检测出人,然后再进行关键点检测
flipping 和原图预测出来的热力图会平均起来,来预测最终的 joint location(人基本在图片的中心,所以问题不大,本来也是对称预测的)
A quarter offset in the direction from highest response to the second highest response is used to obtain the final location.
3)Ablation Study

- Heat map resolution
(a)输出的 heatmaps 分辨率为 64×48,(b)输出的分辨率为 32×24,3 次最好 - Kernel size(deconvolution)
(a、c、d),4 最好 - Backbone
(a、e、f),确实网络越大效果越好 - Image size
(a、g、h),也是越大效果越好
4)Comparison with Other Methods on COCO val2017
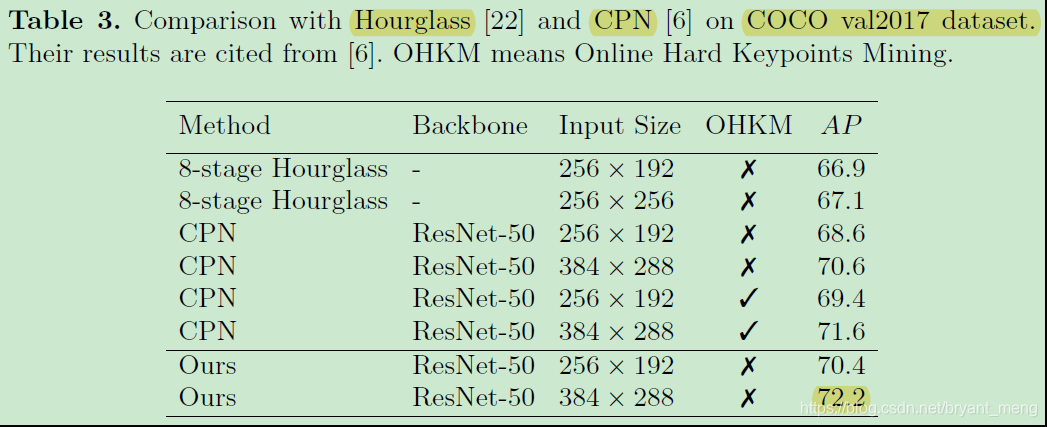
对比的方法都遵循 top-down two-stage paradigm,top-down 的意思是先检测人,再预测 joint location,two-stage 应该是 low-to-high 然后 high-to-low,U 形结构
作者这里用的 person detection AP 有 56.4
5)Comparisons on COCO test-dev dataset
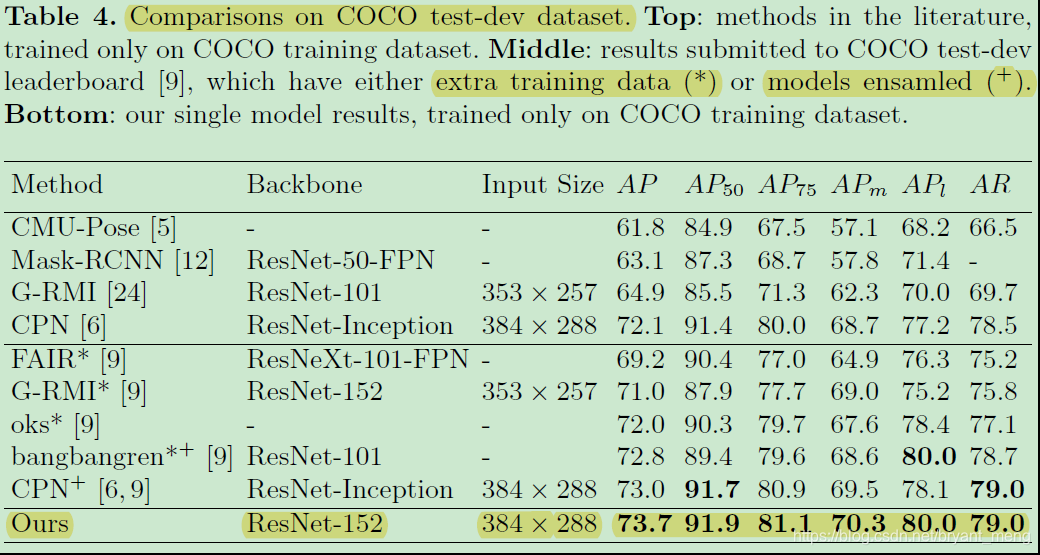
作者这里用的 person detection AP 有 60.9
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

