
- 1CTF工具(1)--- ARCHPR--含安装/使用过程
- 2让群辉支持DTS音轨_群晖music dts
- 3Android包名的含义与命名规范_安卓包名
- 4package-lock.json引用了淘宝镜像,但是淘宝镜像地址变更了_package-lock.json 镜像源修改
- 5Centos7 Docker安装APISIX_安装 apisix dashboard
- 6【谷歌开发者月刊】一月精彩内容回顾,开启开发者们的新年
- 7安装Android Studio遇到Unable to access Android SDK add-on list的错误
- 8安卓手机安卓Mysql,Termux安装MariaDB/MySQL数据库_最新termux安装 mariadb
- 915秒带你了解三款值得收藏的 AI 工具_ai数据分析工具
- 10Unity入门(一)
CVPR2021|Anchor-free新玩法,一个head统一目标检测,实例分割,姿态估计三种任务..._anchorfreehead
赞
踩
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达

本文转自小马哥@知乎,https://zhuanlan.zhihu.com/p/366651996。
大家好,我是Charmve,祝大家端午假节快乐!
今天介绍一篇被CVPR 2021接收的工作,本文将目标检测、实例分割、姿态估计这些任务概括为位置敏感的视觉识别,并提出了一个名为位置敏感网络(LSNet)的统一解决方案。>>回复”加群“加入迈微技术交流群,走在计算机视觉的最前沿。

-
论文:https://arxiv.org/abs/2104.04899
-
代码:https://github.com/Duankaiwen/LSNet
文章认为,目标检测,实例分割和姿态估计本质上都是识别物体,只是表征物体的形式有所不同,目标检测用bbox,实例分割用mask,姿态估计用keypoint。既然都是识别物体,能否只用一套方案来实现这三个任务?能。请看图1。
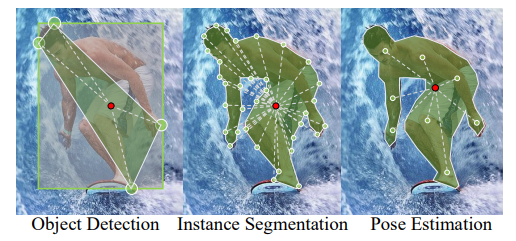
图1
目标检测。 用一个anchor点和指向极值点的四根向量就能确定目标框。注意文章中使用的是极值点,这个极值点是借助于mask标注得到的,详情参见ExtremeNet[1]。至于为什么使用极值点,文章指出极值点本身就包含了物体的语义信息。后面将介绍,这部分信息将会被有效的利用起来。反正coco有mask标注,不用白不用。但对于没有mask或极值点标注的数据集怎么办?这里有个替代方案,就是用边框的中点代替极值点,如图2。
代码中只需将 with_extreme=False即可
dict(type='LoadAnnotations', with_bbox=True, with_extreme=True)
实验表明,在ResNet50上,极值点比中点高0.4个AP左右。文章在这里顺便提了一嘴,以后在标注新的目标检测数据集时,建议标注四个极值点,而非直接画框框住物体。因为根据论文[2],标极值点比直接画框平均快4倍,而且极值点本身包含有物体的语义信息。
实例分割。 用一个anchor点和指向轮廓点的n个向量确定mask。注意这跟PolarMask[3]的做法类似,但又不同。如图3,左为PolarMask,右为LSNet。在制作训练标签时,PolarMask将物体表示在极坐标系中,因此每个方向只能取一个轮廓点,但是对于复杂的polygon,某些方向会多次穿过轮廓,这种情况PolarMask只能取最外的一圈轮廓上的轮廓点,而红色轮廓处的轮廓点将被忽略。LSNet则避免了这个问题,它对轮廓进行均匀的采样,得到n个轮廓点,然后让网络直接回归出每个轮廓点的位置。

说到在轮廓上均匀的采样n个轮廓点,那么n到底取多少合适?n的大小依数据集的不同而不同。文章提供了一个可迅速判断n取值的方法,那就是把gt polygon分别均匀的采样n1, n2, n3, ...,个轮廓点。然后用n1, n2, n3, ...,分别组成新的polygon,与gt polygon进行比较,计算mask AP, 寻找最优的轮廓点采样数。以coco数据集为例,分别对每个gt polygon均匀采样18, 36, 72个轮廓点,然后分别用18, 36, 72个轮廓点分别组成新的polygon,计算mask AP得到如下结果,因此选取n=36。
| n | 18 | 36 | 72 |
|---|---|---|---|
| mask AP (%) | 89.0 | 97.4 | 99.2 |
像LSNet这样直接回归每个轮廓点位置的做法看上去简单,但真要做好其实很难,原因在于轮廓点的位置变化多端,而目前只能通过smooth L1 loss来约束,说实话smooth L1很难hold住。因此文章提出了一个新的loss来更好的处理回归问题,这在后面讲。
姿态估计。 姿态估计的思路参考了CenterNet[4]的做法。用一个anchor点和指向17个关键点点的17个向量确定pose。
到这里,LSNet通过用一个anchor点和n个向量的方式,把目标检测,实例分割和姿态估计统一了起来,而这三个task的唯一区别就是n的数值不一样,对于目标检测,实例分割和姿态估计,n分别=4,36,17。接下来需要对向量的回归进行优化,smooth L1 loss效果不够好,因此文章提出了一种新的距离回归的loss,Cross-IOU Loss。
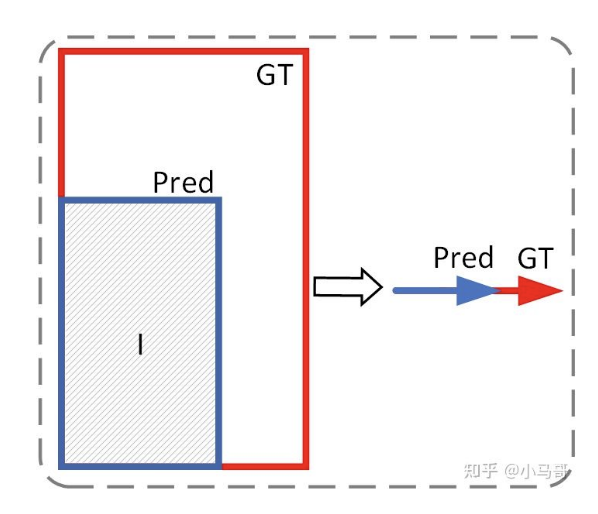
Cross-IOU Loss。 回顾在矩形框的回归优化中,之所以IOU loss表现比smooth L1 loss好,一个很重要的原因是IOU loss是一个比值的形式,其预测结果跟gt的偏差始终保持在[0,1], 使训练过程更加稳定。但IOU loss只在优化矩形回归时比较方便,当优化的图形是polygon时,IOU 的计算就变得很困难 (PolarMask的polar IOU loss一定程度上解决了这个问题,但也存在缺陷,如前面所述),当优化pose的回归时,更是无法计算出IOU。Cross-IOU loss的做法是对每一根向量的回归都运用IOU的思想。首先考虑将二维的IOU压缩到一维,如图4,两个矩形的IOU就变成了两条线段的IOU,且 ,其中p, g分别表示pred和gt,且pred和gt需同向,若pred和gt方向相反,则 。
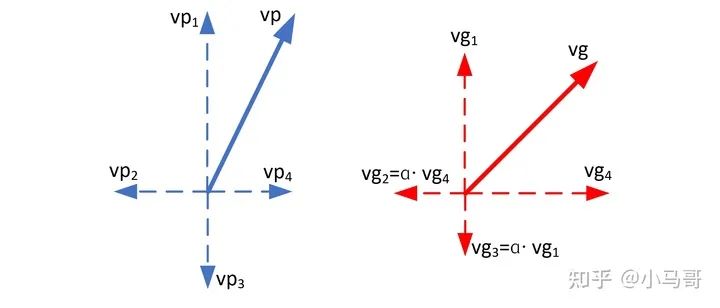
对于回归一条向量,将其分解为x分量和y分量, 图5,则IOU定义为:

如果vp和vg只在第一象限,这是没问题的,当vp和vg在其他象限或vp和vg在不同的象限时,如图6,此时IOU却无法优化预测向量的方向。因此需要做进一步的改进。

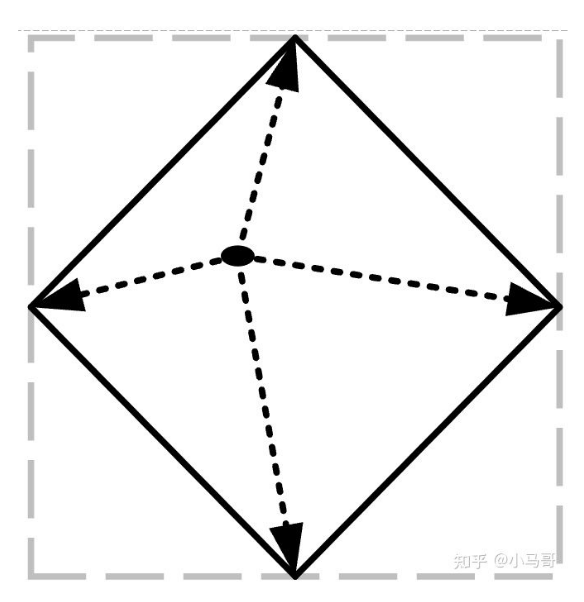
将一个向量用4个分量表示,如图7, , 其中 均大于0。制作训练标签时,先将vg分解成x向量和y向量,例如图7中的vg,先分解为vg4和vg1,然后分别将其对侧延长自身长度的 倍( 也均大于0),实验中, 取。于是重新得到 。对于n个要回归的向量,定义cross-IOU loss为:
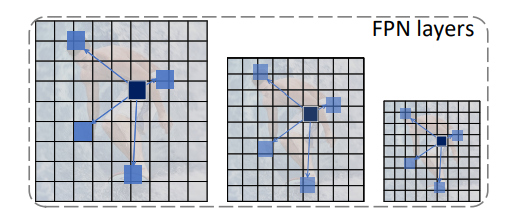
Pyramid DCN。 LSNet的回归过程采取了init+refine的方式。先回归一组初始的向量,这些向量已经比较接近极值点或轮廓点或关键点(文章称为landmarks)。因此这些位置处的特征不能浪费,可以利用DCN (deformable convolution)获取这写些landmarks处的特征。文章进一步提出了Pyramid DCN来更加充分的提取landmarks特征,如图8。也就是说DCN不仅只在目标所在的FPN层计算,还会把DCN的offsets等比例映射至相邻的FPN层进行计算,将三层的所得特征相加,形成最终的landmarks特征。利用这些特征再预测一组向量,两组向量叠加最终形成预测向量。
实验结果。 实验在coco数据集上进行。
 可视化结果
可视化结果
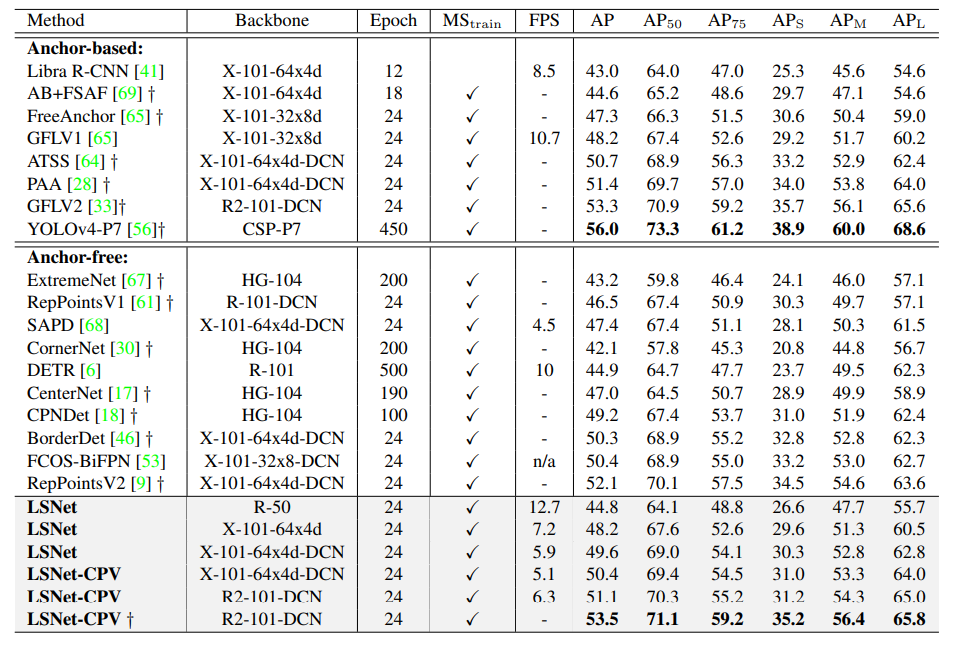 目标检测结果
目标检测结果
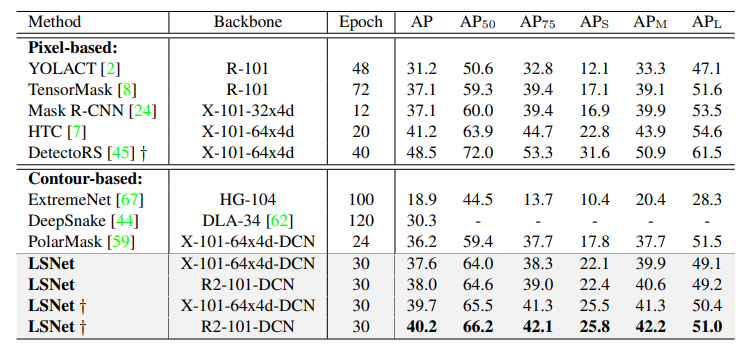 实例分割结果
实例分割结果
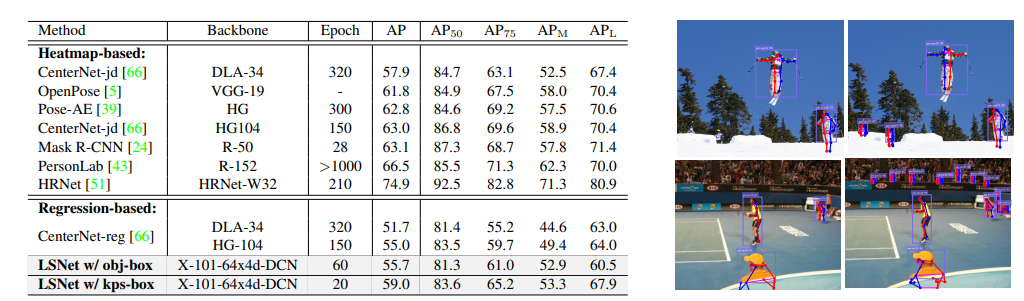 姿态估计结果 图9
姿态估计结果 图9
姿态估计中,LSNet使用了两种样本分配策略进行训练。一种是通过数据集中自带的目标框(对应表中的obj-box)进行样本分配,即只要靠近目标框的样本就被认为是正样本。但coco的标注中有很多目标,尤其是尺度较小的目标,只有目标框的标注,没有关键点的标注。对于这样的目标,其分类分支按照正样本训练,回归分支不参与训练(因为没有关键点的标注)。因此在实际的预测结果中,可以看到LSNet预测出了很多小目标的pose。如图9所示,左边是CenterNet的预测结果,右边是LSNet w/obj-box的预测结果。但反映在AP上,这会降低AP值,因为在GT pose中,是没有小目标的标注的,LSNet预测出的小目标pose都被当做了错误预测。这是导致LSNet没有达到SOTA的原因之一。
因此LSNet又使用了第二种样本分配策略,使用pose形成的目标框(对应表中的kps-box,具体做法为取17个关键点中最上,最左,最下和最右的四个关键点形成的框)进行样本分配。这样的话对于那些只有目标框标注而没有关键点标注的目标就不会当作正样本,这与测试集保持了一致,因此AP有了一个较大提升,但是一些小目标的pose就检测不到了。图10展示了obj-box和kps-box的不同。

图10,左边obj-box,右边kps-box
对于姿态估计AP没有达到SOTA的另外一个原因是,通过heatmap预测关键点的方式比回归方式在像素级尺度上能够更加接近GT。而计算keypoint AP的metric对于这种像素级的偏差很敏感。为了证明这一点,文章做了一个实验,将CenterNet-jd (HG104)的预测结果中,分别向每个预测关键点的位置加入1个,2个,3个像素的扰动,其AP由63.0%迅速降到了61.1%, 53.4%,44.0%。但一两个像素的偏差肉眼却无法察觉。因此虽然AP低点,但其实也能适用于很多场景。
后续计划: 加入BiFPN,DLA34,在精度和速度上进一步提升一下。
参考文献:
-
X. Zhou, J. Zhuo, and P. Krahenbuhl. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 850–859, 2019.
-
D. P. Papadopoulos, J. R. Uijlings, F. Keller, and V. Ferrari. Extreme clicking for efficient object annotation. In Proceedings of the IEEE international conference on computer vision, pages 4930–4939, 2017.
-
E. Xie, P. Sun, X. Song, W.Wang, X. Liu, D. Liang, C. Shen, and P. Luo. Polarmask: Single shot instance segmentation with polar representation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 12193–12202, 2020.
-
X. Zhou, D. Wang, and P. Kr¨ahenb¨uhl. Objects as points. arXiv preprint arXiv:1904.07850, 2019
本文亮点总结
1.文章认为,目标检测,实例分割和姿态估计本质上都是识别物体,只是表征物体的形式有所不同。本文只用一套方案统一了三种任务。
2.对于PolarMask只能取最外的一圈轮廓上的轮廓点,而红色轮廓处的轮廓点将被忽略的情况,LSNet则避免了这个问题,它对轮廓进行均匀的采样,得到n个轮廓点,然后让网络直接回归出每个轮廓点的位置。
3.文章提供了一个可迅速判断n取值的方法,把gt polygon分别均匀的采样n1, n2, n3, ...,个轮廓点。然后用n1, n2, n3, ...,分别组成新的polygon,与gt polygon进行比较,计算mask AP, 寻找最优的轮廓点采样数。
更多细节可参考论文原文。
推荐阅读
(点击标题可跳转阅读)

# CV技术社群邀请函 #

△长按添加迈微官方微信号
备注:姓名-学校/公司-研究方向-城市(如:小C-北大-目标检测-北京)
△点击卡片关注迈微AI研习社,获取最新CV干货
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:yidazhang1@gmail.com

觉得有用麻烦给个三连啦~ ![]()

