
热门标签
热门文章
- 1分布式之Nacos配置中心
- 2鸿蒙os 2.0玩吃鸡,成功更新鸿蒙OS2.0 极致画质吃鸡王者更胜EMUI11谷歌框架照样能用...
- 3C#_模拟鼠标操作_c#模拟鼠标左键点击
- 4Stable Diffusion科普文章【附升级gpt4.0秘笈】
- 5华为nova4是不是鸿蒙系统,华为nova 4手机什么时候可以升级鸿蒙系统?鸿蒙系统nova4升级时间介绍...
- 6【HarmonyOS】如何获取公共目录的图片等文件(API7 FA模型JS语言)_harmonyos 遍历图片资源
- 7快收藏!产品经理必备的5款软件推荐_产品经理必备软件
- 8如何下载VMware17 Pro并安装_vmware17pro下载
- 9全网最详细 Opencv + OpenNi + 奥比中光(Orbbec) Astra Pro /乐视三合一体感摄像头LeTMC-520 + linux 环境搭建_乐视三合一体感摄像头连接电脑
- 10居民用电数据集_现行居民阶梯电价还适合下个夏天吗?(附全国阶梯电价表)...
当前位置: article > 正文
英伟达 vs. 华为海思:GPU性能一览_英伟达对标华为b900的产品
作者:Cpp五条 | 2024-03-12 13:32:45
赞
踩
英伟达对标华为b900的产品
本文转自SDNLAB,编译自arthurchiao的博客,主要介绍了英伟达和华为/海思主流 GPU 的型号性能,供个人参考使用,文中使用数据均源自官网。
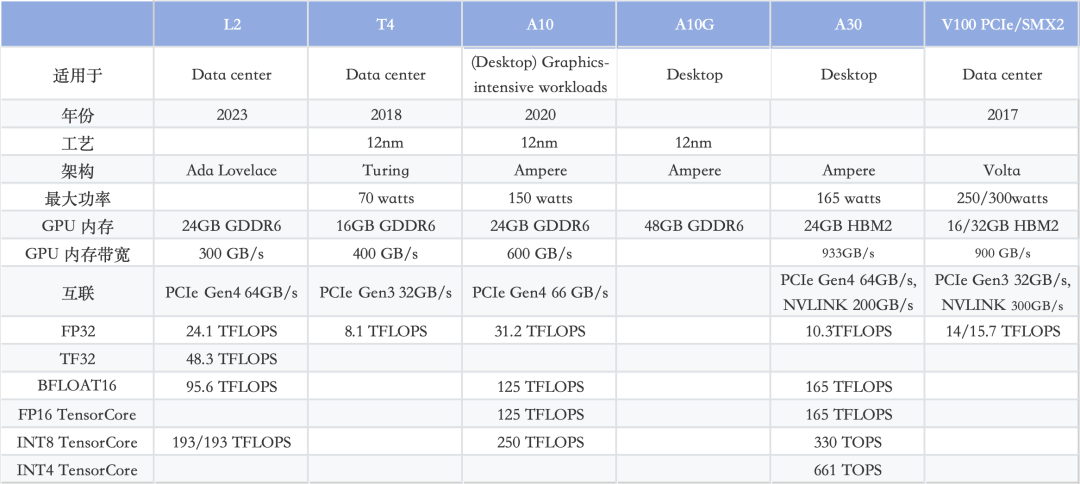
英伟达GPU L2/T4/A10/A10G/V100对比:
英伟达A100/A800/H100/H800/华为Ascend 910B对比:
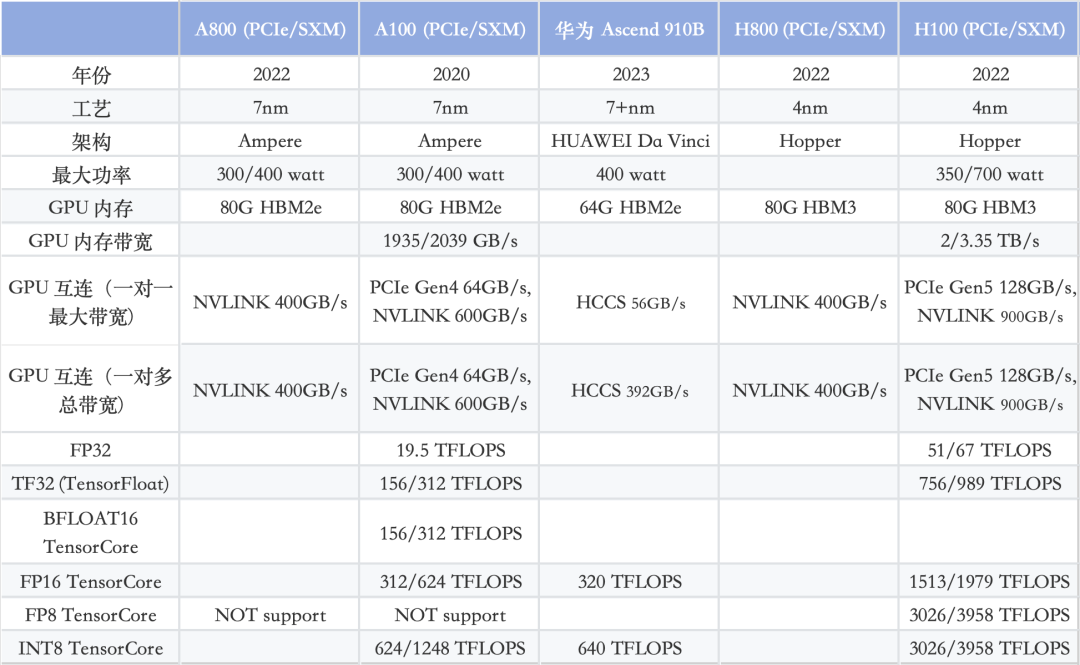
一句话总结,H100 vs. A100:3 倍性能,2 倍价格
值得注意的是,HCCS vs. NVLINK的GPU 间带宽。
对于 8 卡 A800 和 910B 模块而言,910B HCCS 的总带宽为392GB/s,与 A800 NVLink (400GB/s) 相当。然而,两者之间也存在一些区别。
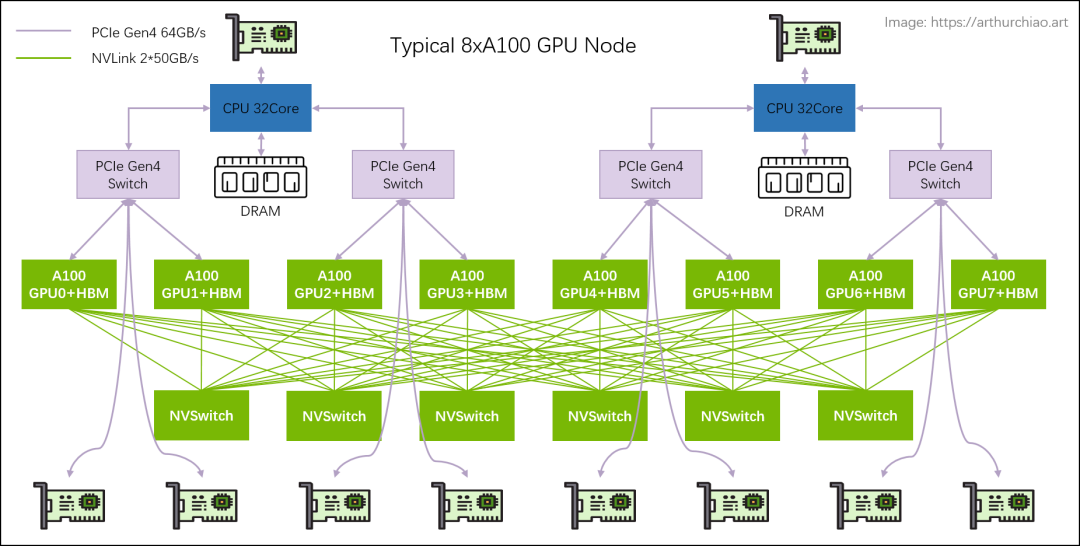
NVIDIA NVLink采用全网状拓扑,如下所示,(双向)GPU-to-GPU 最大带宽可达到400GB/s (需要注意的是,下方展示的是8*A100模块时的600GB/s速率,8*A800也是类似的全网状拓扑);
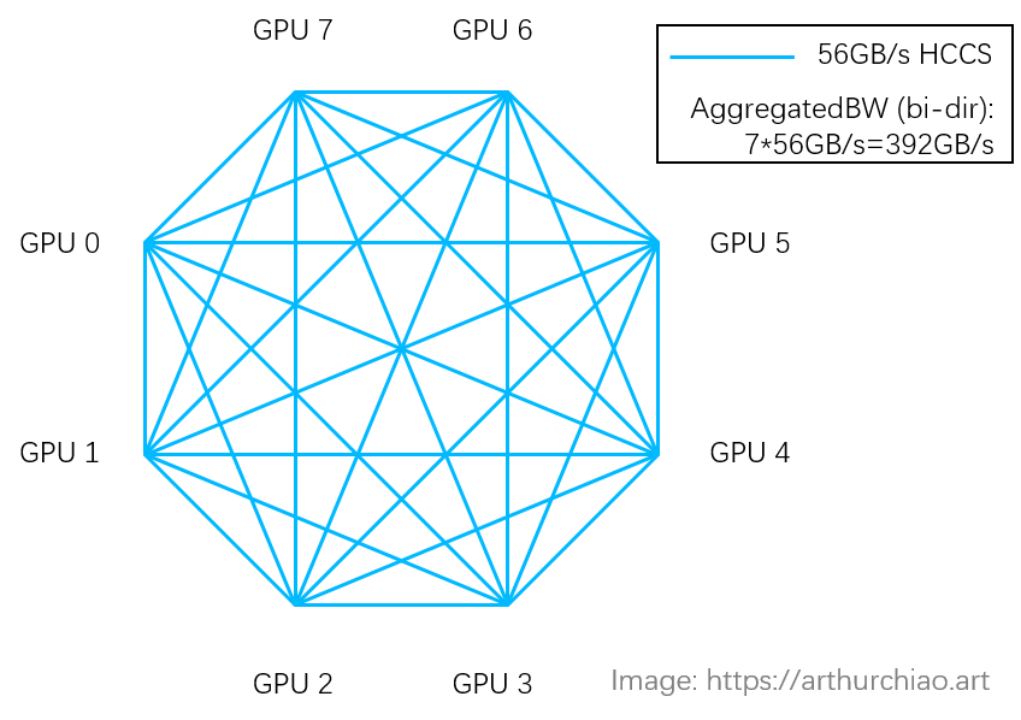
华为HCCS采用对等拓扑(没有 NVSwitch 芯片之类的东西),所以(双向) GPU-to-GPU 最大带宽是56GB/s;
H20/L20/Ascend 910B对比:
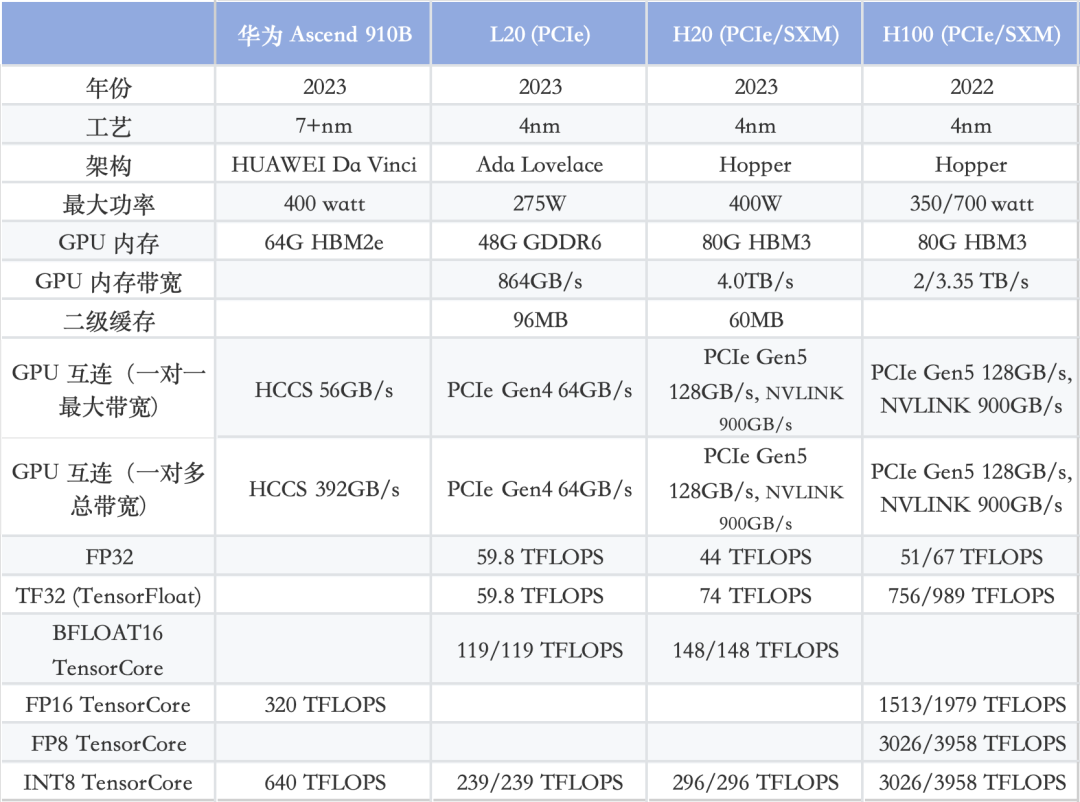
以上内容来自架构师联盟

多年来一直专注于科学计算服务器,入围政采平台,H100、A100、H800、A800、L40、L40S、RTX6000 Ada,RTX A6000,单台双路256核心服务器等。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/224282
推荐阅读
相关标签

