
热门标签
热门文章
- 1图论——最短路算法_图论算最短距离倒数时
- 2C语言如何画饼图_c语言画饼状图
- 3华为交换机的端口组该如何配置?_交换机端口组
- 4Vue3.x API_app.config.performance
- 5数据治理实践——金融行业大数据治理的方向与实践
- 6Android ActivityManagerService总结(四)startActivity流程_android系统怎样获取activitytaskmanagerservice.java
- 7混淆报错,super classes have no public methods with the @Subscribe annotation_subscriber class and its super classes have no pub
- 8androidsdk安装_Android Studio 安装向导
- 9安卓手机怎样安装apk应用_安卓安装apk
- 10over()函数
当前位置: article > 正文
2018年京东JDATA算法 大赛:"如期而至"-用户购买时间预测,方案分享_京东竞赛数据集2018年
作者:Cpp五条 | 2024-03-17 12:15:25
赞
踩
京东竞赛数据集2018年
前言
去年6月份和实习生一起参加京东jdata2018算法大赛,取得了17名的成绩,本来以为这个成绩对于第一次参加算法大赛的我们来说已经算是不错了,但在听了决赛答辩之后感觉今后的路还很长,需要学习的东西太多,现在把我们的方案以及对比赛的理解和大家分享,欢迎大家讨论。
1、赛题描述
1.1数据说明
- 用户基本信息表:

- 商品基本信息表:

- 用户订单表:

- 用户行为表:

- 用户评论表:

- 数据描述:
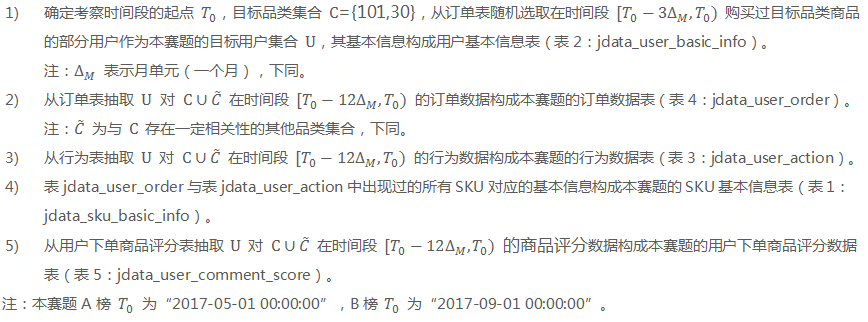
- 数据下载地址:
JData_A榜数据下载 密码:oi9t
JData_B榜数据下载 密码:h0mp
1.2赛题任务:

1.3评分标准:

S1评分思路分析:
- 实验:
在50000个用户中有25000用户有实际购买情况但排序不同的评分情况:
前25000:0.5353
后25000:0.4647
随机分布:0.4999 - 结论:
1、S1的得分是S2的基础,因此要首先保证S1的分不能太低
2、要在保证精确度的前提下,尽量让实际购买的用户往前排
2、总体思路
2.1 方案总体思路

- S1/S2的思路基本一致
3、特征工程
3.1 总体示意
假设:用户是否购买以及购买日期只和近期的行为习惯有关
训练集构建思路:尽可能多的利用数据
时间窗口的选择思路:离标签月越近分的越详细

3.2 特征选择
- 与购买相关的特征:
订单数/商品数/商品种类/购买次数/有购买行为的天数/有购买行为的月数 - 与浏览和收藏相关的特征:
行为(浏览或收藏)商品数/行为(浏览或收藏)商品种类/行为(浏览或收藏)天数/收藏商品数/收藏商品种类/有收藏行为的天数 - 地理信息:
用户下单过的地点数/用户订单数最大的地点编号
参数信息:
用户所购买商品price/para1/para2/para3的最大值最小值平均值中位数 - 用户花费:
用户的总花费 - 用户购买集中度:
用户购买集中度=购买的商品次数/购买的商品种类 - 用户商品忠诚度:
用户购买同一sku的最大次数 - 用户购买转化率:
用户购买转化率=用户购买的商品种类/用户有行为(浏览或收藏)的商品种类 - 日期特征:
购买的最小的day/最大的day/平均的day
近3个月/5个月 月首购买日期的最大、最小、平均、中位数 - 特征时间窗口:7天/14天/1月/3个月/5个月
- 品类维度:总体/(101,30)目标品类
- 最终特征维度:347
- 其他:未使用离散化/one-hot
3.3数据清洗与平滑
由于618的存在,用户在6月的购买模型可以认为是噪声,去除训练集汇总6月作为标签月的特征集同时对特征进行ln(1+x)平滑处理
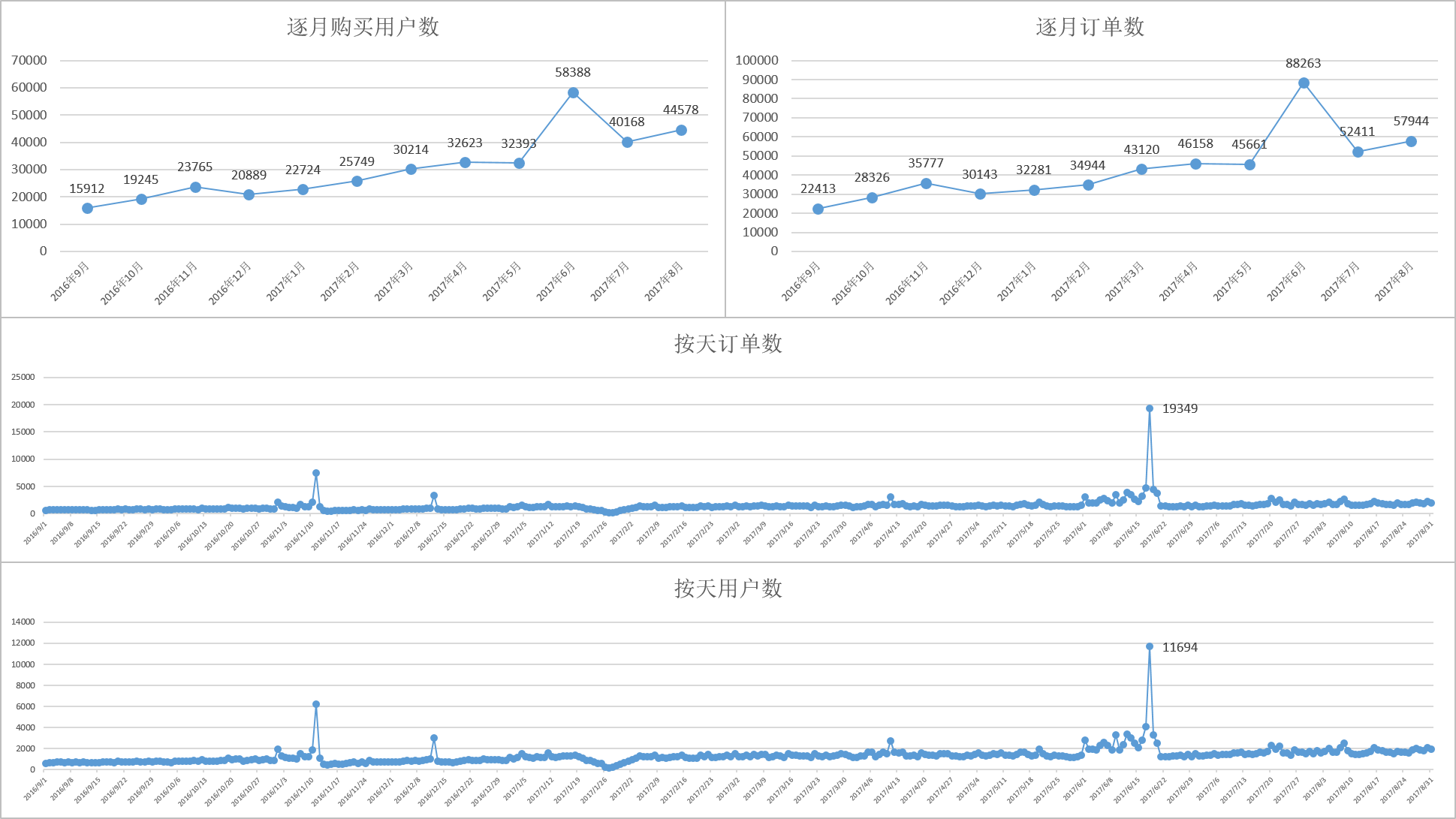
4、模型选择
- GBDT\XGBoost\LightGBM
目前各大赛事及工程应用中最流行最高效门槛最低的选择 - 开个脑洞:
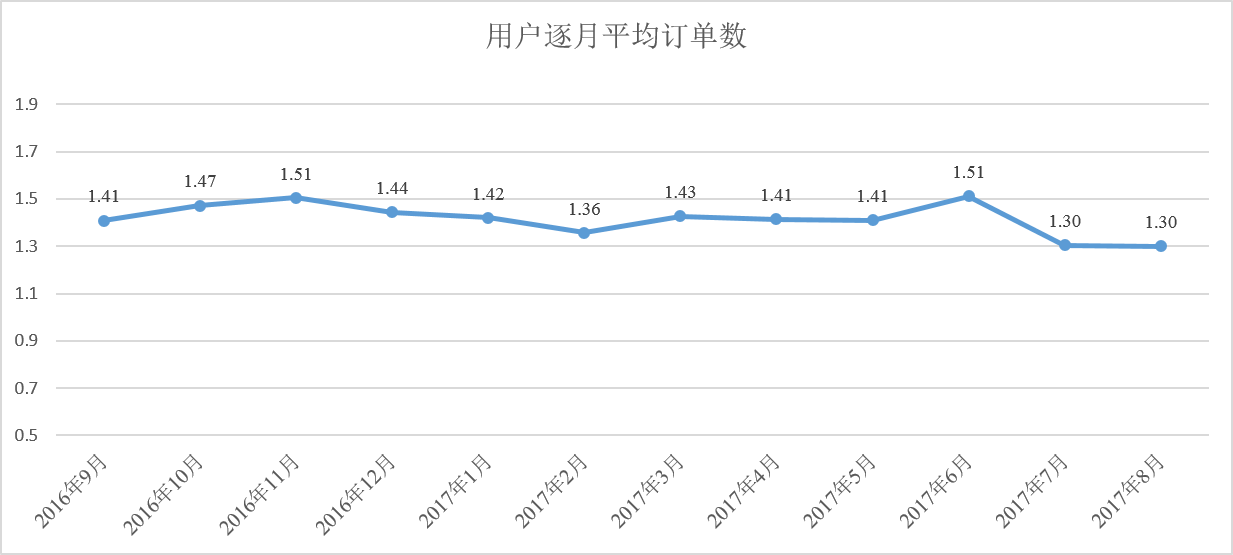
一般来说S1用分类比较普遍,通过对用户购买概率从大到小排序来完成S1任务,但是由于S1分析可得,S1得分不仅和精确率相关也和排列顺序有关,那么有没有一种方法在保证精确率的同时能获得更好的顺序呢?我们在S1的任务中另辟蹊径,通过回归用户订单数的方式来对用户排序最终获得了更好的效果 - bagging有放回采样
- 调参
使用sklearn中提供的GridSearch进行参数搜索调整参数
参数调整顺序:
1、learning rate/n_estimators调整
2、树参数(max_depth/min_sample_split/max_feature/subsample)调整
3、learning rate/n_estimators调整 - 融合的考虑
时间原因未进行融合
5、最终系统模型
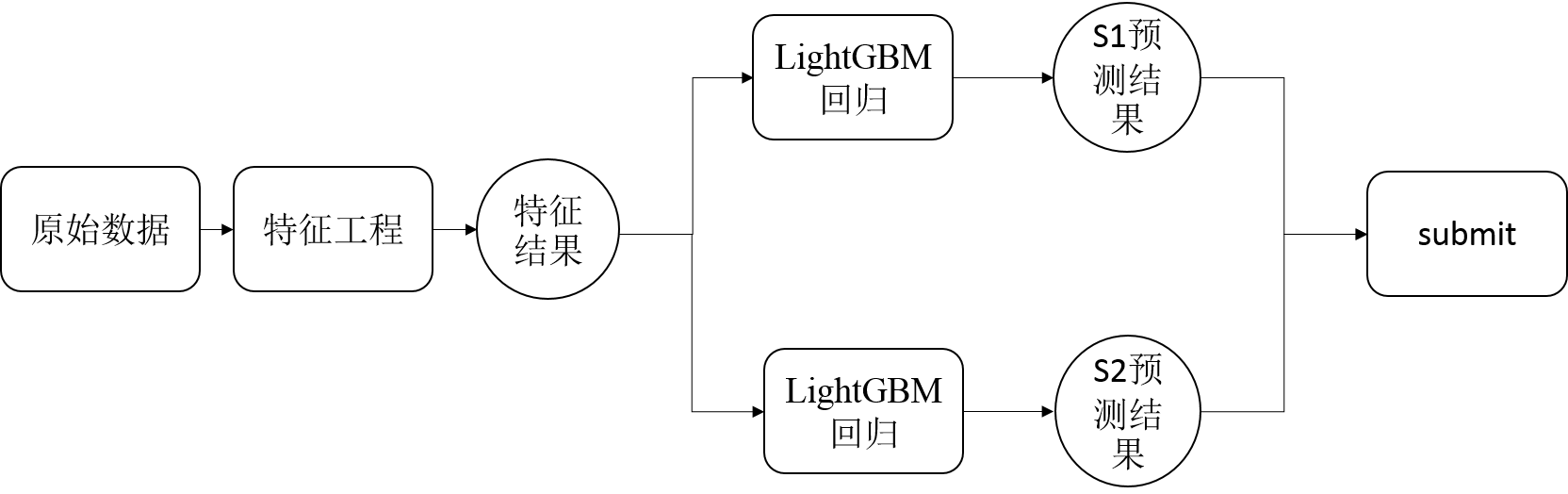
6、小结
- 本次比赛有很多收获,也有很多遗憾,收获都写上了,这里就说说遗憾,首先,在模型融合方面考虑的不多,线下训练由于计算资源有限以及平时工作比较忙的原因甚至没有使用交叉验证,直接用8月用户购买行为作为标签进行的线下训练,如果能够进行充分交叉验证和调参,再加上stacking或者blending也许会有更好的效果。
- 特征上面我们考虑相对是比较全面的,但是听了决赛答辩之后,还是漏掉了几个强特征,比如用户标签月最后一天的购买情况,用户的购买间隔,物品消耗时长等。
- 特征重构及变换上面我们也有很多可以改进的地方,例如通过LDA对sku进行重聚类,计算用户和商品的共现矩阵,hawkes模型的应用等等。
- 一些比赛技巧上我们也有待加强,例如可以通过重写损失函数的方法,将S2的损失函数由系统默认的MSE改为赛题对S2的评分,据说这个方法在线上有百分位的提升。
- 模型融合的思考:
这次京东的大赛分为A榜和B榜两个不同的数据集,最终取B榜数据为最终排名,这极大考验模型的稳定性,有些选手A榜成绩不错,但是B榜就掉链子了,我们是从A榜的33名到B榜的17名,说明整体模型的稳定性还不错。另外通过观察现场决赛答辩,我们发现前三名的选手都没有或者只用了非常轻度的模型融合,这也从侧面反映了,单模型在稳定性上的优势。实际生产系统不是比赛,要求模型长期稳定的运行,持续输出较好的结果,而不是追求某一次的极大精度。这次比赛也让我们在使用模型融合方面有了很多的思考。 - 深度学习应用的思考:
限于时间、精力和硬件资源的限制,本次比赛并未尝试使用深度学习相关技术,从赛题题意上来说是可以使用LSTM/GRU等模型进行尝试的,另外如果赛题方能够提供具体的用户聊天和评论具体信息,也可以应用Bert、ELMo、GPT等深度语言模型进行尝试。
项目地址及其他
项目的源代码,大家可以通过:https://github.com/Francis1986/Jdata_2018下载,如果对大家有帮助,可以点个赞。
本文如需转载请注明出处,感谢!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/255980
推荐阅读
相关标签

