- 1谷歌浏览器自定义快捷搜索引擎_chrome自定义搜索引擎
- 2在电脑上配置手机app测试环境_在家用电脑模拟软件测试吗
- 3postgresql查看数据库、表、表空间(位置大小)、索引的方法_pg数据库查看表空间路径
- 4四年背的单词 笔记目录_log infree accountall girls cams▼filterseeyamin19m
- 5数字图像处理作业(一)_数字图像处理课程作业
- 6YOLOv5/v7/v8改进实验(三)之训练技巧篇_yolov8在训练的时候,如何调整训练的权重,重点在一类标签上
- 7Android 获得设备关联的帐号信息_此 google 帐号尚未与设备关联.要安装应用,请先访问设备上的 play 商店应用
- 8android中的两种打包方式,及多渠道打包_apk a/b面怎么打包
- 9vue 2.0创建项目打包后index出现空白页面_vue build 导出的index是空的
- 10Mac 搭建本地SVN,并使用Cornerstone管理svn_ios cornerstone add repository 很慢
滑动窗口限流 java_图解+代码 | 你被限流了吗?
赞
踩

脚本之家
你与百万开发者在一起
本文转自公众号 yes的练级攻略(ID:yes_java)
如若转载请联系原公众号
今天来说说限流的相关内容,包括常见的限流算法、单机限流场景、分布式限流场景以及一些常见限流组件。
当然在介绍限流算法和具体场景之前我们先得明确什么是限流,为什么要限流?。
任何技术都要搞清它的来源,技术的产生来自痛点,明确痛点我们才能抓住关键对症下药。
限流是什么?
首先来解释下什么是限流?
在日常生活中限流很常见,例如去有些景区玩,每天售卖的门票数是有限的,例如 2000 张,即每天最多只有 2000 个人能进去游玩。
题外话:我之前看到个新闻,最不想卖门票的景区“卢旺达火山公园”,每天就卖 32 张,并且每张门票需要 1 万元!

再回到主题,那在我们工程上限流是什么呢?限制的是 「流」,在不同场景下「流」的定义不同,可以是每秒请求数、每秒事务处理数、网络流量等等。
而通常我们说的限流指代的是 限制到达系统的并发请求数,使得系统能够正常的处理 部分 用户的请求,来保证系统的稳定性。
限流不可避免的会造成用户的请求变慢或者被拒的情况,从而会影响用户体验。因此限流是需要在用户体验和系统稳定性之间做平衡的,即我们常说的 trade off。
对了,限流也称流控(流量控制)。
为什么要限流?
前面我们有提到限流是为了保证系统的稳定性。
日常的业务上有类似秒杀活动、双十一大促或者突发新闻等场景,用户的流量突增,后端服务的处理能力是有限的,如果不能处理好突发流量,后端服务很容易就被打垮。
亦或是爬虫等不正常流量,我们对外暴露的服务都要以最大恶意去防备我们的调用者。我们不清楚调用者会如何调用我们的服务。假设某个调用者开几十个线程一天二十四小时疯狂调用你的服务,不做啥处理咱服务也算完了。更胜的还有 DDos 攻击。
还有对于很多第三方开发平台来说,不仅仅是为了防备不正常流量,也是为了资源的公平利用,有些接口都免费给你用了,资源都不可能一直都被你占着吧,别人也得调的。
当然加钱的话好商量。
在之前公司还做过一个系统,当时SaaS版本还没出来。因此系统需要部署到客户方。
当时老板的要求是,我们需要给他个限流降级版本,不但系统出的方案是降级后的方案,核心接口每天最多只能调用20次,还需要限制系统所在服务器的配置和数量,即限制部署的服务器的CPU核数等,还限制所有部署的服务器数量,防止客户集群部署,提高系统的性能。
当然这一切需要能动态配置,因为加钱的话好商量。客户一直都不知道。
估计老板在等客户说感觉系统有点慢吧。然后就搞个2.0版本?我让我们研发部加班加点给你搞出来。
小结一下,限流的本质是因为后端处理能力有限,需要截掉超过处理能力之外的请求,亦或是为了均衡客户端对服务端资源的公平调用,防止一些客户端饿死。
常见的限流算法
有关限流算法我给出了对应的图解和相关伪代码,有些人喜欢看图,有些人更喜欢看代码。

计数限流
最简单的限流算法就是计数限流了,例如系统能同时处理100个请求,保存一个计数器,处理了一个请求,计数器加一,一个请求处理完毕之后计数器减一。
每次请求来的时候看看计数器的值,如果超过阈值要么拒绝。
非常的简单粗暴,计数器的值要是存内存中就算单机限流算法。存中心存储里,例如 Redis 中,集群机器访问就算分布式限流算法。
优点就是:简单粗暴,单机在 Java 中可用 Atomic 等原子类、分布式就 Redis incr。
缺点就是:假设我们允许的阈值是1万,此时计数器的值为0, 当1万个请求在前1秒内一股脑儿的都涌进来,这突发的流量可是顶不住的。缓缓的增加处理和一下子涌入对于程序来说是不一样的。
而且一般的限流都是为了限制在指定时间间隔内的访问量,因此还有个算法叫固定窗口。
固定窗口限流
它相比于计数限流主要是多了个时间窗口的概念。计数器每过一个时间窗口就重置。规则如下:
- 请求次数小于阈值,允许访问并且计数器 +1;
- 请求次数大于阈值,拒绝访问;
- 这个时间窗口过了之后,计数器清零;

看起来好像很完美,实际上还是有缺陷的。
固定窗口临界问题
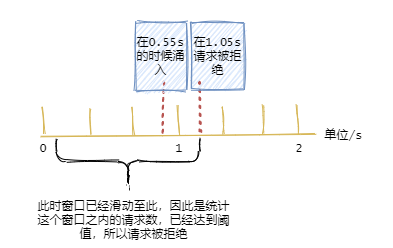
假设系统每秒允许 100 个请求,假设第一个时间窗口是 0-1s,在第 0.55s 处一下次涌入 100 个请求,过了 1 秒的时间窗口后计数清零,此时在 1.05 s 的时候又一下次涌入100个请求。
虽然窗口内的计数没超过阈值,但是全局来看在 0.55s-1.05s 这 0.1 秒内涌入了 200 个请求,这其实对于阈值是 100/s 的系统来说是无法接受的。

为了解决这个问题引入了滑动窗口限流。
滑动窗口限流
滑动窗口限流解决固定窗口临界值的问题,可以保证在任意时间窗口内都不会超过阈值。
相对于固定窗口,滑动窗口除了需要引入计数器之外还需要记录时间窗口内每个请求到达的时间点,因此对内存的占用会比较多。
规则如下,假设时间窗口为 1 秒:
- 记录每次请求的时间
- 统计每次请求的时间 至 往前推1秒这个时间窗口内请求数,并且 1 秒前的数据可以删除。
- 统计的请求数小于阈值就记录这个请求的时间,并允许通过,反之拒绝。

但是滑动窗口和固定窗口都无法解决短时间之内集中流量的突击。
我们所想的限流场景,例如每秒限制 100 个请求。希望请求每 10ms 来一个,这样我们的流量处理就很平滑,但是真实场景很难控制请求的频率。因此可能存在 5ms 内就打满了阈值的情况。
当然对于这种情况还是有变型处理的,例如设置多条限流规则。不仅限制每秒 100 个请求,再设置每 10ms 不超过 2 个。
再多说一句,这个滑动窗口可与TCP的滑动窗口不一样。TCP的滑动窗口是接收方告知发送方自己能接多少“货”,然后发送方控制发送的速率。
接下来再说说漏桶,它可以解决时间窗口类算法的痛点,使得流量更加的平滑。
漏桶算法
如下图所示,水滴持续滴入漏桶中,底部定速流出。如果水滴滴入的速率大于流出的速率,当存水超过桶的大小的时候就会溢出。
规则如下:
- 请求来了放入桶中
- 桶内请求量满了拒绝请求
- 服务定速从桶内拿请求处理
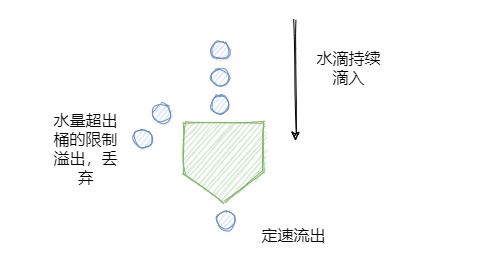

可以看到水滴对应的就是请求。它的特点就是宽进严出,无论请求多少,请求的速率有多大,都按照固定的速率流出,对应的就是服务按照固定的速率处理请求。“他强任他强,老子尼克杨”。

看到这想到啥,是不是和消息队列思想有点像,削峰填谷。一般而言漏桶也是由队列来实现的,处理不过来的请求就排队,队列满了就开始拒绝请求。看到这又想到啥,线程池不就是这样实现的嘛?
经过漏洞这么一过滤,请求就能平滑的流出,看起来很像很挺完美的?实际上它的优点也即缺点。
面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理(看看,之前滑动窗口说流量不够平滑,现在太平滑了又不行,难搞啊)。
而令牌桶在应对突击流量的时候,可以更加的“激进”。
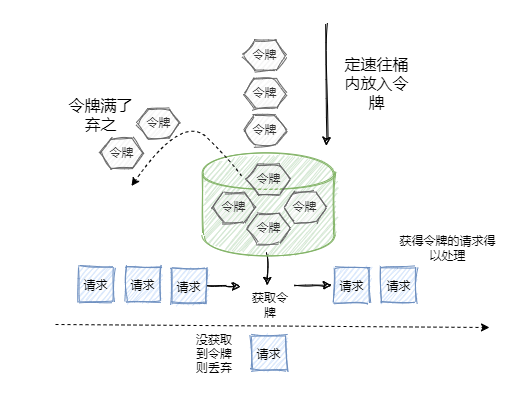
令牌桶算法
令牌桶其实和漏桶的原理类似,只不过漏桶是定速地流出,而令牌桶是定速地往桶里塞入令牌,然后请求只有拿到了令牌才能通过,之后再被服务器处理。
当然令牌桶的大小也是有限制的,假设桶里的令牌满了之后,定速生成的令牌会丢弃。
规则:
- 定速的往桶内放入令牌
- 令牌数量超过桶的限制,丢弃
- 请求来了先向桶内索要令牌,索要成功则通过被处理,反之拒绝
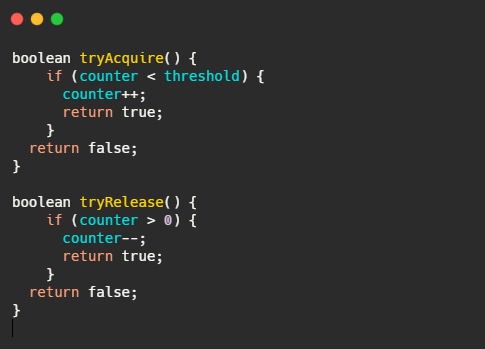
看到这又想到啥?Semaphore 信号量啊,信号量可控制某个资源被同时访问的个数,其实和咱们拿令牌思想一样,一个是拿信号量,一个是拿令牌。只不过信号量用完了返还,而咱们令牌用了不归还,因为令牌会定时再填充。
再来看看令牌桶的伪代码实现,可以看出和漏桶的区别就在于一个是加法,一个是减法。

可以看出令牌桶在应对突发流量的时候,桶内假如有 100 个令牌,那么这 100 个令牌可以马上被取走,而不像漏桶那样匀速的消费。所以在应对突发流量的时候令牌桶表现的更佳。
限流算法小结
上面所述的算法其实只是这些算法最粗略的实现和最本质的思想,在工程上其实还是有很多变型的。
从上面看来好像漏桶和令牌桶比时间窗口算法好多了,那时间窗口算法有啥子用,扔了扔了?
并不是的,虽然漏桶和令牌桶对比时间窗口对流量的整形效果更佳,流量更加得平滑,但是也有各自的缺点(上面已经提到了一部分)。
拿令牌桶来说,假设你没预热,那是不是上线时候桶里没令牌?没令牌请求过来不就直接拒了么?这就误杀了,明明系统没啥负载现在。
再比如说请求的访问其实是随机的,假设令牌桶每 20ms 放入一个令牌,桶内初始没令牌,这请求就刚好在第一个 20ms 内有两个请求,再过 20ms 里面没请求,其实从 40ms 来看只有 2 个请求,应该都放行的,而有一个请求就直接被拒了。这就有可能造成很多请求的误杀,但是如果看监控曲线的话,好像流量很平滑,峰值也控制的很好。
再拿漏桶来说,漏桶中请求是暂时存在桶内的。这其实不符合互联网业务低延迟的要求。
所以漏桶和令牌桶其实比较适合阻塞式限流场景,即没令牌我就等着,这就不会误杀了,而漏桶本就是等着。比较适合后台任务类的限流。而基于时间窗口的限流比较适合对时间敏感的场景,请求过不了您就快点儿告诉我,等的花儿都谢了(给阿姨倒一杯卡布奇诺。为什么我会突然打这句话??)。

单机限流和分布式限流
本质上单机限流和分布式限流的区别其实就在于 “阈值” 存放的位置。
单机限流就上面所说的算法直接在单台服务器上实现就好了,而往往我们的服务是集群部署的。因此需要多台机器协同提供限流功能。
像上述的计数器或者时间窗口的算法,可以将计数器存放至 Tair 或 Redis 等分布式 K-V 存储中。
例如滑动窗口的每个请求的时间记录可以利用 Redis 的 zset 存储,利用ZREMRANGEBYSCORE 删除时间窗口之外的数据,再用 ZCARD计数。
像令牌桶也可以将令牌数量放到 Redis 中。
不过这样的方式等于每一个请求我们都需要去Redis判断一下能不能通过,在性能上有一定的损耗,所以有个优化点就是 「批量」。例如每次取令牌不是一个一取,而是取一批,不够了再去取一批。这样可以减少对 Redis 的请求。
不过要注意一点,批量获取会导致一定范围内的限流误差。比如你取了 10 个此时不用,等下一秒再用,那同一时刻集群机器总处理量可能会超过阈值。
其实「批量」这个优化点太常见了,不论是 MySQL 的批量刷盘,还是 Kafka 消息的批量发送还是分布式 ID 的高性能发号,都包含了「批量」的思想。
当然分布式限流还有一种思想是平分,假设之前单机限流 500,现在集群部署了 5 台,那就让每台继续限流 500 呗,即在总的入口做总的限流限制,然后每台机子再自己实现限流。
限流的难点
可以看到每个限流都有个阈值,这个阈值如何定是个难点。
定大了服务器可能顶不住,定小了就“误杀”了,没有资源利用最大化,对用户体验不好。
我能想到的就是限流上线之后先预估个大概的阈值,然后不执行真正的限流操作,而是采取日志记录方式,对日志进行分析查看限流的效果,然后调整阈值,推算出集群总的处理能力,和每台机子的处理能力(方便扩缩容)。
然后将线上的流量进行重放,测试真正的限流效果,最终阈值确定,然后上线。
我之前还看过一篇耗子叔的文章,讲述了在自动化伸缩的情况下,我们要动态地调整限流的阈值很难,于是基于TCP拥塞控制的思想,根据请求响应在一个时间段的响应时间P90或者P99值来确定此时服务器的健康状况,来进行动态限流。在他的 Ease Gateway 产品中实现了这套算法,有兴趣的同学可以自行搜索。
其实真实的业务场景很复杂,需要限流的条件和资源很多,每个资源限流要求还不一样。所以我上面就是嘴强王者。

限流组件
一般而言我们不需要自己实现限流算法来达到限流的目的,不管是接入层限流还是细粒度的接口限流其实都有现成的轮子使用,其实现也是用了上述我们所说的限流算法。
比如Google Guava 提供的限流工具类 RateLimiter,是基于令牌桶实现的,并且扩展了算法,支持预热功能。
阿里开源的限流框架Sentinel 中的匀速排队限流策略,就采用了漏桶算法。
Nginx 中的限流模块 limit_req_zone,采用了漏桶算法,还有 OpenResty 中的 resty.limit.req库等等。
具体的使用还是很简单的,有兴趣的同学可以自行搜索,对内部实现感兴趣的同学可以下个源码看看,学习下生产级别的限流是如何实现的。
最后
今天只是粗略讲解了限流相关的内容,具体应用到工程上还是有很多点需要考虑的,并且限流只是保证系统稳定性中的一个环节,还需要配合降级、熔断等相关内容。以后有机会再讲讲。
- END - 点击卡片进入小程序,签到赢礼品 ??????
(更多精彩值得期待……)


●  收藏|Java 面试题全梳理
收藏|Java 面试题全梳理
● 积分兑换,来就“兑”了
● 人人都欠微软一个正版?
● 漫画:Java如何实现热更新?
● 2020年开发者生态报告:Python超越Java