
- 1Python之curve_fit多元函数拟合_python多元拟合
- 2Github Copilot Chat申请,安装,及常见问题解决
- 3语言理解:图像检索的大规模视觉编码_视觉中国图片怎样编码搜寻
- 42023年Android开发前景展望_android工作展望示例
- 5VMware安装Centos7及简单配置超详细过程(图文)_vm centos7设置多少处理器数量
- 6thinkphp路由的完整匹配_thinkphp 链接完整匹配
- 7bootstrap + django的简单后台管理系统_bootstrap django
- 8不用再找了,这就是 NLP 方向最全面试题库
- 9基于QT和opencv的瞳孔定位及跟踪程序_瞳孔的定位与追踪
- 10测试常见面试题,如何有效的做自我介绍
mysql 常见锁类型_mysql 锁的模式
赞
踩
表锁 & 行锁
在 MySQL 中锁的种类有很多,但是最基本的还是表锁和行锁:表锁指的是对一整张表加锁,一般是 DDL 处理时使用,也可以自己在 SQL 中指定;而行锁指的是锁定某一行数据或某几行,或行和行之间的间隙。行锁的加锁方法比较复杂,但是由于只锁住有限的数据,对于其它数据不加限制,所以并发能力强,通常都是用行锁来处理并发事务。表锁由 MySQL 服务器实现,行锁由存储引擎实现,常见的就是 InnoDb,所以通常我们在讨论行锁时,隐含的一层意义就是数据库的存储引擎为 InnoDb ,而 MyISAM 存储引擎只能使用表锁。
表锁
表锁由 MySQL 服务器实现,所以无论你的存储引擎是什么,都可以使用。一般在执行 DDL 语句时,譬如 ALTER TABLE 就会对整个表进行加锁。在执行 SQL 语句时,也可以明确对某个表加锁,譬如下面的例子
- mysql> lock table products read;
- Query OK, 0 rows affected (0.00 sec)
-
- mysql> select * from products where id = 100;
-
- mysql> unlock tables;
- Query OK, 0 rows affected (0.00 sec)
上面的 SQL 首先对 products 表加一个表锁,然后执行查询语句,最后释放表锁。
表锁可以细分成两种:读锁和写锁,如果是加写锁,则是 lock table products write 。
关于表锁,我们要了解它的加锁和解锁原则,要注意的是它使用的是 一次封锁 技术,也就是说,我们会在会话开始的地方使用 lock 命令将后面所有要用到的表加上锁,在锁释放之前,我们只能访问这些加锁的表,不能访问其他的表,最后通过 unlock tables 释放所有表锁。这样的好处是,不会发生死锁!所以我们在 MyISAM 存储引擎中,是不可能看到死锁场景的。对多个表加锁的例子如下:
- mysql> lock table products read, orders read;
- Query OK, 0 rows affected (0.00 sec)
-
- mysql> select * from products where id = 100;
-
- mysql> select * from orders where id = 200;
-
- mysql> select * from users where id = 300;
- ERROR 1100 (HY000): Table 'users' was not locked with LOCK TABLES
-
- mysql> update orders set price = 5000 where id = 200;
- ERROR 1099 (HY000): Table 'orders' was locked with a READ lock and can't be updated
- mysql> unlock tables;
- Query OK, 0 rows affected (0.00 sec)
可以看到由于没有对 users 表加锁,在持有表锁的情况下是不能读取的,另外,由于加的是读锁,所以后面也不能对 orders 表进行更新。MySQL 表锁的加锁规则如下:
- 对于读锁
- 持有读锁的会话可以读表,但不能写表;
- 允许多个会话同时持有读锁;
- 其他会话就算没有给表加读锁,也是可以读表的,但是不能写表;
- 其他会话申请该表写锁时会阻塞,直到锁释放。
- 对于写锁
- 持有写锁的会话既可以读表,也可以写表;
- 只有持有写锁的会话才可以访问该表,其他会话访问该表会被阻塞,直到锁释放;
- 其他会话无论申请该表的读锁或写锁,都会阻塞,直到锁释放。
锁的释放规则如下:
- 使用 UNLOCK TABLES 语句可以显示释放表锁;
- 如果会话在持有表锁的情况下执行 LOCK TABLES 语句,将会释放该会话之前持有的锁;
- 如果会话在持有表锁的情况下执行 START TRANSACTION 或 BEGIN 开启一个事务,将会释放该会话之前持有的锁;
- 如果会话连接断开,将会释放该会话所有的锁。
行锁
表锁不仅实现和使用都很简单,而且占用的系统资源少,所以在很多存储引擎中使用,如 MyISAM、MEMORY、MERGE 等,MyISAM 存储引擎几乎完全依赖 MySQL 服务器提供的表锁机制,查询自动加表级读锁,更新自动加表级写锁,以此来解决可能的并发问题。但是表锁的粒度太粗,导致数据库的并发性能降低,为了提高数据库的并发能力,InnoDb 引入了行锁的概念。行锁和表锁对比如下:
- 表锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 行锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
行锁和表锁一样,也分成两种类型:读锁和写锁。常见的增删改(INSERT、DELETE、UPDATE)语句会自动对操作的数据行加写锁,查询的时候也可以明确指定锁的类型,SELECT ... LOCK IN SHARE MODE 语句加的是读锁,SELECT ... FOR UPDATE 语句加的是写锁。
行锁这个名字听起来像是这个锁加在某个数据行上,实际上这里要指出的是:在 MySQL 中,行锁是加在索引上的。
MySQL 加锁流程
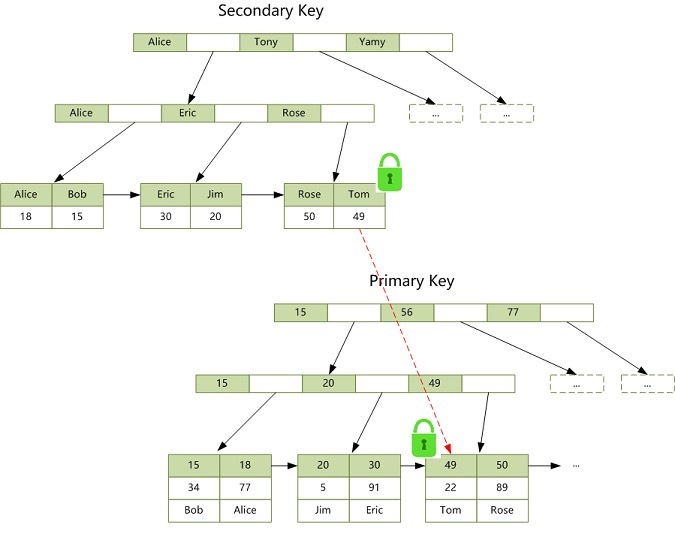
当执行下面的 SQL 时(id 为 students 表的主键),我们要知道,InnoDb 存储引擎会在 id = 49 这个主键索引上加一把 X 锁。
mysql> update students set score = 100 where id = 49;当执行下面的 SQL 时(name 为 students 表的二级索引),InnoDb 存储引擎会在 name = 'Tom' 这个索引上加一把 X 锁,同时会通过 name = 'Tom' 这个二级索引定位到 id = 49 这个主键索引,并在 id = 49 这个主键索引上加一把 X 锁。
mysql> update students set score = 100 where name = 'Tom';加锁过程如下图所示:
多条记录的加锁流程:
mysql> update students set level = 3 where score >= 60;下图展示了当用户执行这条 SQL 时,MySQL Server 和 InnoDb 之间的执行流程:
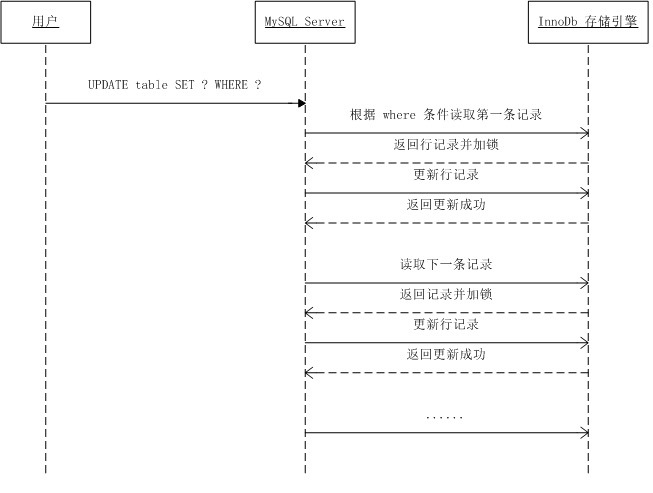
MySQL 在操作多条记录时 InnoDB 与 MySQL Server 的交互是一条一条进行的,加锁也是一条一条依次进行的,先对一条满足条件的记录加锁,返回给 MySQL Server,做一些 DML 操作,然后在读取下一条加锁,直至读取完毕。
行锁种类
根据锁的粒度可以把锁细分为表锁和行锁,行锁根据场景的不同又可以进一步细分,在 MySQL 的源码里,定义了四种类型的行锁,如下:
- #define LOCK_TABLE 16 /* table lock */
- #define LOCK_REC 32 /* record lock */
-
- /* Precise modes */
- #define LOCK_ORDINARY 0
- #define LOCK_GAP 512
- #define LOCK_REC_NOT_GAP 1024
- #define LOCK_INSERT_INTENTION 2048
- LOCK_ORDINARY:也称为 Next-Key Lock,锁一条记录及其之前的间隙,这是 RR 隔离级别用的最多的锁,从名字也能看出来;
- LOCK_GAP:间隙锁,锁两个记录之间的 GAP,防止记录插入;
- LOCK_REC_NOT_GAP:只锁记录;
- LOCK_INSERT_INTENSION:插入意向 GAP 锁,插入记录时使用,是 LOCK_GAP 的一种特例。
读锁 & 写锁
MySQL 将锁分成两类:锁类型(lock_type)和锁模式(lock_mode)。锁类型就是上文中介绍的表锁和行锁两种类型,当然行锁还可以细分成记录锁和间隙锁等更细的类型,锁类型描述的锁的粒度,也可以说是把锁具体加在什么地方;而锁模式描述的是到底加的是什么锁,譬如读锁或写锁。锁模式通常是和锁类型结合使用的,锁模式在 MySQL 的源码中定义如下:
- /* Basic lock modes */
- enum lock_mode {
- LOCK_IS = 0, /* intention shared */
- LOCK_IX, /* intention exclusive */
- LOCK_S, /* shared */
- LOCK_X, /* exclusive */
- LOCK_AUTO_INC, /* locks the auto-inc counter of a table in an exclusive mode*/
- ...
- };
- LOCK_IS:读意向锁;
- LOCK_IX:写意向锁;
- LOCK_S:读锁;
- LOCK_X:写锁;
- LOCK_AUTO_INC:自增锁;
将锁分为读锁和写锁主要是为了提高读的并发,如果不区分读写锁,那么数据库将没办法并发读,并发性将大大降低。而 IS(读意向)、IX(写意向)只会应用在表锁上,方便表锁和行锁之间的冲突检测。LOCK_AUTO_INC 是一种特殊的表锁。下面依次进行介绍。
读写锁
读锁和写锁都是最基本的锁模式,它们的概念也比较容易理解。读锁,又称共享锁(Share locks,简称 S 锁),加了读锁的记录,所有的事务都可以读取,但是不能修改,并且可同时有多个事务对记录加读锁。写锁,又称排他锁(Exclusive locks,简称 X 锁),或独占锁,对记录加了排他锁之后,只有拥有该锁的事务可以读取和修改,其他事务都不可以读取和修改,并且同一时间只能有一个事务加写锁。(注意:这里说的读都是当前读,快照读是无需加锁的,记录上无论有没有锁,都可以快照读)
读写意向锁
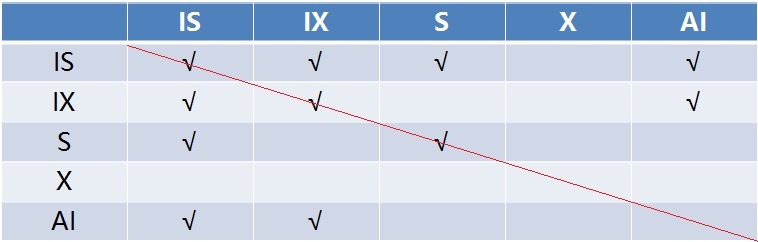
表锁锁定了整张表,而行锁是锁定表中的某条记录,它们俩锁定的范围有交集,因此表锁和行锁之间是有冲突的。譬如某个表有 10000 条记录,其中有一条记录加了 X 锁,如果这个时候系统需要对该表加表锁,为了判断是否能加这个表锁,系统需要遍历表中的所有 10000 条记录,看看是不是某条记录被加锁,如果有锁,则不允许加表锁,显然这是很低效的一种方法,为了方便检测表锁和行锁的冲突,从而引入了意向锁。
意向锁为表级锁,也可分为读意向锁(IS 锁)和写意向锁(IX 锁)。当事务试图读或写某一条记录时,会先在表上加上意向锁,然后才在要操作的记录上加上读锁或写锁。这样判断表中是否有记录加锁就很简单了,只要看下表上是否有意向锁就行了。意向锁之间是不会产生冲突的,也不和 AUTO_INC 表锁冲突,它只会阻塞表级读锁或表级写锁,另外,意向锁也不会和行锁冲突,行锁只会和行锁冲突。
下面是各个表锁之间的兼容矩阵:
AUTO_INC 锁
AUTO_INC 锁又叫自增锁(一般简写成 AI 锁),它是一种特殊类型的表锁,当插入的表中有自增列(AUTO_INCREMENT)的时候可能会遇到。当插入表中有自增列时,数据库需要自动生成自增值,在生成之前,它会先为该表加 AUTO_INC 表锁,其他事务的插入操作阻塞,这样保证生成的自增值肯定是唯一的。AUTO_INC 锁具有如下特点:
- AUTO_INC 锁互不兼容,也就是说同一张表同时只允许有一个自增锁;
- 自增锁不遵循二段锁协议,它并不是事务结束时释放,而是在 INSERT 语句执行结束时释放,这样可以提高并发插入的性能。
- 自增值一旦分配了就会 +1,如果事务回滚,自增值也不会减回去,所以自增值可能会出现中断的情况。
显然,AUTO_INC 表锁会导致并发插入的效率降低,为了提高插入的并发性,MySQL 从 5.1.22 版本开始,引入了一种可选的轻量级锁(mutex)机制来代替 AUTO_INC 锁,我们可以通过参数 innodb_autoinc_lock_mode 控制分配自增值时的并发策略。参数 innodb_autoinc_lock_mode 可以取下列值:
-
innodb_autoinc_lock_mode = 0 (traditional lock mode)
- 使用传统的 AUTO_INC 表锁,并发性比较差。
-
innodb_autoinc_lock_mode = 1 (consecutive lock mode)
- MySQL 默认采用这种方式,是一种比较折中的方法。
- MySQL 将插入语句分成三类:
Simple inserts、Bulk inserts、Mixed-mode inserts。通过分析 INSERT 语句可以明确知道插入数量的叫做Simple inserts,譬如最经常使用的 INSERT INTO table VALUE(1,2) 或 INSERT INTO table VALUES(1,2), (3,4);通过分析 INSERT 语句无法确定插入数量的叫做 Bulk inserts,譬如 INSERT INTO table SELECT 或 LOAD DATA 等;还有一种是不确定是否需要分配自增值的,譬如 INSERT INTO table VALUES(1,'a'), (NULL,'b'), (5, 'C'), (NULL, 'd') 或 INSERT ... ON DUPLICATE KEY UPDATE,这种叫做Mixed-mode inserts。 - Bulk inserts 不能确定插入数使用表锁;Simple inserts 和 Mixed-mode inserts 使用轻量级锁 mutex,只锁住预分配自增值的过程,不锁整张表。Mixed-mode inserts 会直接分析语句,获得最坏情况下需要插入的数量,一次性分配足够的自增值,缺点是会分配过多,导致浪费和空洞。
- 这种模式的好处是既平衡了并发性,又能保证同一条 INSERT 语句分配的自增值是连续的。
-
innodb_autoinc_lock_mode = 2 (interleaved lock mode)
- 全部都用轻量级锁 mutex,并发性能最高,按顺序依次分配自增值,不会预分配。
- 缺点是不能保证同一条 INSERT 语句内的自增值是连续的,这样在复制(replication)时,如果 binlog_format 为 statement-based(基于语句的复制)就会存在问题,因为是来一个分配一个,同一条 INSERT 语句内获得的自增值可能不连续,主从数据集会出现数据不一致。所以在做数据库同步时要特别注意这个配置。
细说行锁
前面在讲行锁时有提到,在 MySQL 的源码中定义了四种类型的行锁,我们这一节将学习这四种锁。
记录锁 Record Locks
记录锁 是最简单的行锁。
mysql> UPDATE accounts SET level = 100 WHERE id = 5;
这条 SQL 语句就会在 id = 5 这条记录上加上记录锁,防止其他事务对 id = 5 这条记录进行修改或删除。记录锁永远都是加在索引上的,就算一个表没有建索引,数据库也会隐式的创建一个索引。如果 WHERE 条件中指定的列是个二级索引,那么记录锁不仅会加在这个二级索引上,还会加在这个二级索引所对应的聚簇索引上(参考上面的加锁流程一节)。
注意,如果 SQL 语句无法使用索引时会走主索引实现全表扫描,这个时候 MySQL 会给整张表的所有数据行加记录锁。如果一个 WHERE 条件无法通过索引快速过滤,存储引擎层面就会将所有记录加锁后返回,再由 MySQL Server 层进行过滤。不过在实际使用过程中,MySQL 做了一些改进,在 MySQL Server 层进行过滤的时候,如果发现不满足,会调用 unlock_row 方法,把不满足条件的记录释放锁(显然这违背了两段锁协议)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。可见在没有索引时,不仅会消耗大量的锁资源,增加数据库的开销,而且极大的降低了数据库的并发性能,所以说,更新操作一定要记得走索引。
间隙锁 Gap Locks
还是看上面的那个例子,如果 id = 5 这条记录不存在,这个 SQL 语句还会加锁吗?
这个 SQL 语句在 RC 隔离级别不会加任何锁,在 RR 隔离级别为了避免幻读会在 id = 5 前后两个索引之间加上间隙锁。
间隙锁和间隙锁之间是互不冲突的,间隙锁唯一的作用就是为了防止其他事务的插入。
Next-Key Locks
Next-key 锁 是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁。假设一个索引包含10、11、13 和 20 这几个值,可能的 Next-key 锁如下:
- (-∞, 10]
- (10, 11]
- (11, 13]
- (13, 20]
- (20, +∞)
通常我们都用这种左开右闭区间来表示 Next-key 锁,前面四个都是 Next-key 锁,最后一个为间隙锁。
和间隙锁一样,在 RC 隔离级别下没有 Next-key 锁,只有 RR 隔离级别才有。继续拿上面的 SQL 例子来说,如果 id 不是主键,而是二级索引,且不是唯一索引,那么这个 SQL 在 RR 隔离级别下会加什么锁呢?答案就是 Next-key 锁,如下:
- (a, 5]
- (5, b)
其中,a 和 b 是 id = 5 前后两个索引,我们假设 a = 1、b = 10,那么此时如果插入一条 id = 3 的记录将会阻塞住。之所以要把 id = 5 前后的间隙都锁住,仍然是为了解决幻读问题,因为 id 是非唯一索引,所以 id = 5 可能会有多条记录,为了防止再插入一条 id = 5 的记录,必须将下面标记 ^ 的位置都锁住,因为这些位置都可能再插入一条 id = 5 的记录:1 ^ 5 ^ 5 ^ 5 ^ 10 11 13 15
可以看出来,Next-key 锁确实可以避免幻读,但是带来的副作用是连插入 id = 3 这样的记录也被阻塞了。
关于 Next-key 锁,有一个比较有意思的问题,比如下面这个 orders 表(id 为主键,order_id 为二级非唯一索引):
- +-----+----------+
- | id | order_id |
- +-----+----------+
- | 1 | 1 |
- | 3 | 2 |
- | 5 | 5 |
- | 7 | 5 |
- | 10 | 9 |
- +-----+----------+
这个时候不仅 order_id = 5 这条记录会加上 X 记录锁,而且这条记录前后的间隙也会加上锁,加锁位置如下:1 2 ^ 5 ^ 5 ^ 9
可以看到 (2, 9) 这个区间都被锁住了,这个时候如果插入 order_id = 4 或者 order_id = 8 这样的记录肯定会被阻塞,这没什么问题,那么现在问题来了,如果插入一条记录 order_id = 2 或者 order_id = 9 会被阻塞吗?答案是可能阻塞,也可能不阻塞,这取决于插入记录主键的值。
插入意向锁 Insert Intention Locks
插入意向锁是一种特殊的间隙锁(所以有的地方把它简写成 II GAP),这个锁表示插入的意向,只有在 INSERT 的时候才会有这个锁。注意,这个锁虽然也叫意向锁,但是和上面介绍的表级意向锁是两个完全不同的概念,不要搞混淆了。插入意向锁和插入意向锁之间互不冲突,所以可以在同一个间隙中有多个事务同时插入不同索引的记录。譬如在上面的例子中,id = 1 和 id = 5 之间如果有两个事务要同时分别插入 id = 2 和 id = 3 是没问题的,虽然两个事务都会在 id = 1 和 id = 5 之间加上插入意向锁,但是不会冲突。
插入意向锁只会和间隙锁或 Next-key 锁冲突,正如上面所说,间隙锁唯一的作用就是防止其他事务插入记录造成幻读,那么间隙锁是如何防止幻读的呢?正是由于在执行 INSERT 语句时需要加插入意向锁,而插入意向锁和间隙锁冲突,从而阻止了插入操作的执行。
行锁的兼容矩阵
下面我们对这四种行锁做一个总结,它们之间的兼容矩阵如下图所示:
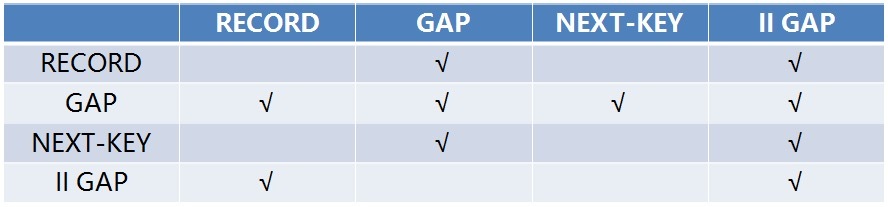
其中,行表示已有的锁,列表示要加的锁。


