
- 1华为为什么还不使用鸿蒙系统,【图片】华为鸿蒙系统的厉害之处在于 你可能非用不可 !【手机吧】_百度贴吧...
- 2【华为鸿蒙系统学习】- 如何利用鸿蒙系统进行App项目开发|自学篇_鸿蒙app开发
- 3文献阅读工具-->Adobe pdf + 有道词典
- 44、HTML基本结构和常用标签_描述html常用的基本标签结构
- 5新概念英语1:Lesson7内容详解
- 6Linux——进程概念(进程状态)_kill -18
- 7LCD1602 液晶_lcd每一个字符是由多少个点阵组成
- 8android自定义窗口层级(自定义车载系统中倒车影像显示层级)_安卓修改displayframes大小
- 9浙大博士整理的计算机视觉学习路线(含时间建议分配)_计算机视觉 学习 规划
- 10面试常问集锦——分布式系列_面试分布式
AI探索实践7 - 打造企业智能体(AI Agent)的重要技术-ReAct_智能体agent 开发
赞
踩
大家好,我是Feng。欢迎关注我公众号和我一起探索AI技术。

全栈技术探索
文笔有限,这篇文章比较难写。但是ReAct的概念对于实现AI Agent很关键,文末有一些参考链接供大家辅助理解。
一、前言
AI 大模型开发中有许多概念,让刚开始学习的开发者一头雾水,比如 ReAct。
ReAct 并不是指 Facebook 开源的前端开发框架 react,而是一种实现 AI Agent 的一种重要方法。了解ReAct的概念和实现方法,对于实现 AI Agent 至为重要。
二、什么是ReAct
我们使用大模型时,你会向它提出一个问题(发送一个提示语),模型能够分析你的问题,并给出答案。有些时候,当我们提出的稍显复杂的问题时,模型的回答很可能并不理想。但当我们给模型发送的prompt,增加一句:Let’s think step by step 时,就会发现模型的表现要比之前好得多!它会因为这句提示,而试图一步步的分析、推理,直到找到答案发送给你。
在人类的认知过程中,当面对复杂问题时,我们通常会采用一步一步的思考方式,即“思维链”。这种方法帮助我们将问题分解成较小的部分,然后逐个解决,最终形成有逻辑的解答路径。
模型面对复杂问题处理的逻辑过程,其实是在模仿人类的推理过程,不仅给出答案,还会提供一连串的推理步骤。这使得AI的决策过程变得可追溯和可解释,从而让开发者和用户能更好地信任和理解AI的工作机制。这个逻辑过程,被称之为 CoT(Chain of Thought)- 链式思考。
而 Let’s think step by step 就是提醒模型:“请以 CoT 的方式处理我的问题”。
虽然CoT很棒,可以帮助大模型给我们更好的结果。但我们需要知道,LLM每次只回答了一个问题。也就是说,CoT即使有链式思考,但也只是回答了一个问题。这对于简单的对话方式的场景或许是够的,但如果问题中包含了需要多次思考并回答多个问题时,CoT就完全不够用了。比如这样的问题:"我的电脑为什么不能上网了"。

图 1
根据LLM的回答中故障原因排查列表,我们需要自己去检查回答中的一项或者多项(反馈结果),然后告诉大模型是否找到了原因:

图 2
以此类推。这个示例的问答,是一个CoT过程。每一次LLM只会输出一个答案(一段文本),LLM参考我们提供给它的检查结果,结合自身的知识训练,从而返回一次的响应。
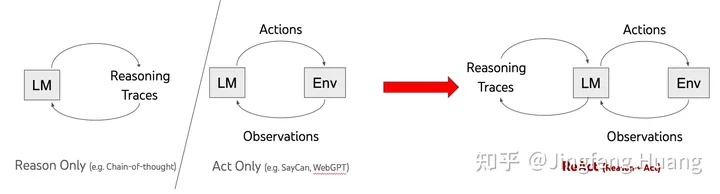
图 3
虽然大型语言模型(LLM)在语言理解和交互式决策制定等任务中表现出了令人印象深刻的能力,但它们的推理(例如思维链提示)和行动(例如行动计划生成)能力主要作为单独的主题进行研究,这两个行为是分开的。
ReAct 实际上是一种方法,通过多次调用 LLM 以交错的方式生成推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用:推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而操作允许它与外部源(例如知识库或外部环境、API)交互,以收集附加信息。
由此上面的定义可知,ReAct需要迭代的使用 3 类元素:
- Thought (思考)。LLM基于用户提出的问题进行推理(Reasoning),并根据推理的结果采取某种行为,类似人类大脑的思考、决策过程。
- Action (行为)。LLM将决策行为动作的指令发送给外部源(比如调用知识库、外部的API),这就是行为。在上面的例子中,LLM告诉你可能的原因列表,示意你去检查这些原因。
- Observation(观察)。行为会产生结果,这个结果是可以被LLM观察的。
LLM汇总用户的问题、这一次(每一次)产生的Thought、Action和Observation,进行Reasoning后,会产生新的的Thought、Action和Observation。以此类推,直到LLM的action代表结束。 上面例子的迭代示例如下:
- Step 1 中,LLM基于 Question 先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 1 和 Action 1 。执行 Action 1 获得 Observation 1。
- Step 2 中,LLM基于 Question,Thought 1 ,Action 1 和 Observation 1,汇总所有信息先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 2 和 Action 2 。执行 Action 2 获得 Observation 2。
- Step 3 中,LLM基于 Question,Thought 1 ,Action 1 ,Observation 1,Thought 2 ,Action 2 和 Observation 2,汇总所有信息先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 3 和 Action 3 。执行 Action 3 获得 Observation 3。
- 以此类推直到 Action 表示结束。
三、实现ReAct
ReAct可以基于Prompt实现,示例如下:
- Solve a question answering task with interleaving Thought, Action, Observation steps.
- Thought can reason about the current situation, and Action can be three types:
- (1) Search[entity], which searches the exact entity on Wikipedia and returns the first paragraph
- if it exists. If not, it will return some similar entities to search.
- (2) Lookup[keyword], which returns the next sentence containing keyword in the current passage.
- (3) Finish[answer], which returns the answer and finishes the task.
- Here are some examples.
-
- Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny
- extends into?
- Thought 1: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado
- orogeny extends into, then find the elevation range of the area.
- Action 1: Search[Colorado orogeny]
- Observation 1: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado
- and surrounding areas.
- Thought 2: It does not mention the eastern sector. So I need to look up eastern sector.
- Action 2: Lookup[eastern sector]
- Observation 2: (Result 1 / 1) The eastern sector extends into the High Plains and is called the
- Central Plains orogeny.
- Thought 3: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search
- High Plains and find its elevation range.
- Action 3: Search[High Plains]
- Observation 3: High Plains refers to one of two distinct land regions:
- Thought 4: I need to instead search High Plains (United States).
- Action 4: Search[High Plains (United States)]
- Observation 4: The High Plains are a subregion of the Great Plains. From east to west, the High
- Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
- Thought 5: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800
- to 7,000 ft.
- Action 5: Finish[1,800 to 7,000 ft]
-
- [More Examples]...

参考
1. ReAct: Synergizing Reasoning and Acting in Language Models
3. 2023年新生代大模型Agents技术,ReAct,Self-Ask,Plan-and-execute,以及AutoGPT, HuggingGPT等应用
4. LLM Powered Autonomous Agents
5. ReAct: Synergizing Reasoning and Acting in Language Models

