
- 1java ltp4j_ltp工具使用配置
- 2日常参考ABAP常用系统变量 (SY-)及SY-SUBRC_sap 数据更新失败sy-subrc
- 3FFmpeg命令行工具学习(二):播放媒体文件的工具ffplay
- 4云计算介绍-1.1,IaaS\PaaS\SaaS辨析_paas msb
- 5FPN+PAN结构学习_pan-fpn
- 6如何将linux ko档copy至android_linux kernel ko 编译拷贝
- 7四旋翼飞行器——飞行原理_4个螺旋桨的飞机螺旋桨怎么转
- 82022-车道线检测综述
- 9AI算力专题:算力系列之四-各省算力规划建设梳理-绿色低碳高质量发展-部署算力建设AI产业研究
- 10vue2+element ui制定义主题色_:export { theme: $--color-primary; }
声音克隆_论文翻译:2019_Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis_声音克隆论文
赞
踩
论文:2019_Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
代码:Real-Time-Voice-Cloning | Real-Time-Voice-Cloning (中文)
摘要
我们描述了一个基于神经网络的文本到语音(TTS)合成系统,它能够以不同说话者的声音生成语音,包括那些在训练期间看不见的声音。我们的系统由三个独立训练的组件组成:
- 说话人编码器网络(提取说话人特征),使用独立的噪声语音数据集进行说话人验证任务的训练,从来自目标说话人几秒钟的参考语音中 生成固定维度的 嵌入向量(说话人语音特征);
- 基于Tacotron 2的序列到序列合成网络,其基于说话者嵌入从文本生成mel谱图;
- 基于自回归waveNet的声码器网络,其将mel频谱图转换成时域波形。
我们证明了所提出的模型能够将通过区分训练(discriminatively-trained)的说话人编码器学习到的说话人可变性的知识转移到多说话人TTS任务,并且能够从训练期间看不见的说话人合成自然语音。为了获得最佳的泛化性能,我们量化了在一个大而多样的说话人数据集上训练说话人编码器的重要性。最后,我们证明了随机采样的说话人嵌入可以用于合成不同于训练中使用的新说话人的语音,这表明该模型已经学习到了高质量的说话人表示。
1 引言
2 多说话人语音合成模型
我们的系统由三个独立训练的神经网络组成,如图1所示:
(1) 基于[22]的语音特征编码器,提取说话者的声音特征信息。将说话者的语音嵌入编码为固定维度的向量,该向量表示了说话者的声音潜在特征。
(2) 基于[15]的序列到序列的映射合成网络,基于Tacotron 2的映射网络,通过文本和语音特征编码器得到的向量来生成log mel spectrogram(梅尔谱图将谱图的频率标度Hz取对数,转换为梅尔标度,使得人耳对声音的敏感度与梅尔标度承线性正相关关系)
(3) 自回归WaveNet [19]的自回归语音合成网络,将梅尔频谱图(谱域)转化为时间序列声音波形图(时域),完成语音的合成。
需要注意的是,这三部分网络都是独立训练的,声音编码器网络主要对序列映射网络起到条件监督作用,保证生成的语音具有说话者的独特声音特征。

图1 模型概述。三个部分都是独立训练的
2.1 声音特征编码器
编码器主要将 目标说话人的参考语音 嵌入编码到固定维度的向量空间,并以此为监督,使映射合成网络能生成具有相应特征的梅尔频谱。编码器的关键作用在于相似性度量,对于同一说话者的不同语音,其在嵌入向量空间中的向量距离(余弦夹角)应该尽可能小,而对不同说话者应该尽可能大。此外,编码器还应具有抗噪能力和鲁棒性,能够不受具体语音内容和背景噪声的影响,提取出说话者声音的潜在特征信息。我们发现 在与文本无关的说话人验证任务上训练的说话人辨别模型满足这些要求,因此可以进行迁移学习。
我们遵循[22],他们 提出了一个高度可扩展并且准确的说话人验证网络框架。该网络可以从任意长度的语音中计算出对数梅尔谱图帧序列,从而映射到固定维嵌入向量,称为d-vector[20,9]。该网络使用广义端到端说话人验证损失训练,使得来自同一说话人的话语的embedding具有高余弦相似性,而来自不同说话人的话语的嵌入在嵌入空间中相距很远。训练数据集由 分割成1.6秒的语音示例和相关的说话者身份标签 组成。
编码器的输入是40通道数的 log-mel spectrograms,网络结构主要由3层 256个单元的LSTM 构成。最后一层是全连接层,全连接层输出经过L2正则化处理后,即得到整个序列的嵌入向量表示。实际推理时,任意长度的输入语音信号都会被800ms的窗口分割为多段,重叠50%,每段得到一个输出,该网络在每个窗口上独立运行,输出被平均和归一化以创建最终的嵌入向量。
虽然网络没有直接优化以学习捕获与合成相关的说话人特征的表示,但我们发现 说话人辨别任务训练的模型 生成的embedding适用于根据说话人身份 调节合成网络。
2.2 序列到序列的映射合成网络
我们使用 注意力Tacotron 2架构[15]扩展了循环序列到序列,以支持类似于[8]方案的多说话人。目标说话人的嵌入向量在每个时间步长与合成器编码器输出连接。与[8]相反,我们将embedding作为注意力层的输入,如图1所示,能使网络对不同的说话者语音收敛。
我们比较了该模型的两种变体,一种是使用说话人编码器计算embedding,另一种是优化训练集中每个说话人的固定embedding的基线,本质上是学习类似于[8,13]的说话人embedding查找表。
该网络独立于编码器网络的训练,以音频信号和对应的文本作为输入,音频信号首先经过预训练的编码器提取特征,然后再作为attention层的输入,我们将文本映射到一系列音素,从而加快收敛速度并改善稀有词和专有名词的发音。网络在迁移学习配置中进行训练,使用预训练的说话人编码器(其参数被冻结)从目标音频中提取说话人embedding,即说话人参考信号与训练期间的目标语音相同。 训练期间不使用明确的说话者标识符标签。
网络输出频谱特征由窗口长度为50ms,步长为12.5ms序列构成,通过80通道mel-scale滤波器组,然后进行对数动态范围压缩。我们通过用一个额外的L1损失增加预测谱图上的L2损失来扩展[15]。在实践中,我们发现这种组合损失能降低噪声训练数据对模型的影响。与[10]相反,我们不引入基于说话人嵌入的附加损失项。
2.3 基于WaveNet的自回归语音合成网络
我们使用逐样本自回归WaveNet [19]作为声码器,将合成网络发出的合成mel频谱图转换为时域波形。体系结构与[15]中描述的相同,由30个扩张的卷积层组成。网络不直接取决于说话人编码器的输出。合成器网络预测的mel声谱图捕捉了各种声音的高质量合成所需的所有相关细节,允许通过简单地训练来自许多说话人的数据来构建多说话人声码器。
2.4 推理和零触发说话人适应
在推断过程中,使用任意未被描述的语音音频来调节该模型,该语音音频不需要匹配要合成的文本。由于用于合成的说话人特征是从音频中推断出来的,所以它可以以来自训练集之外的说话者的音频为条件。在实践中,我们发现使用几秒钟持续时间的单个音频剪辑就足以合成具有相应说话者特征的新语音,这代表了对新说话者的零触发适应。在第3节中,我们评估了这一过程如何推广到以前看不到的说话者。
图 2 显示了推理过程的一个示例,其中显示了使用几个不同的 5 秒说话者参考话语合成的频谱图。与女性(中置和底部)说话人相比,合成的男性(顶部)说话人频谱图具有明显较低的基频,可见于低频更密集的谐波间隔(水平条纹),以及中频可见的共振峰- 元音中出现的频率峰值,例如 0.3 秒的“i” - 顶部男性 F2 在 mel 通道 35,而中间说话人的 F2 看起来更靠近通道 40。类似的差异在咝咝声中也可见,例如0.4 秒处的“s”在男声中比女声中包含更多的低频能量。最后,说话人嵌入也在一定程度上捕获了特征语速,这可以从与前两行相比底部行中更长的信号持续时间看出。可以对右栏中相应的参考话语频谱图进行类似的观察。

图 2:使用所提出的系统以不同的声音合成句子的示例。 Mel 频谱图被可视化用于生成说话人嵌入(左)和相应的合成器输出(右)的参考话语。 文本到频谱图的对齐显示为红色。 使用了从训练组中取出的三个说话人:一个男性(顶部)和两个女性(中间和底部)。
3 实验
我们使用了两个公共数据集来训练语音合成和声码器网络。VCTK [21]包含了来自109位说话人的44个小时的干净语音,其中大多数人都有英国口音。我们将音频下采样到24千赫,调整前导和尾随静音(将中间持续时间从3.3秒减少到1.8秒),并分为三个子集:训练、验证(包含与训练集相同的说话人)和测试(包含从训练集和验证集伸出的11个说话人)。
LibriSpeech [12]由两个“干净”的训练集组成,包括来自1172个说话者的436个小时的语音,采样频率为16千赫。大多数讲话是美国英语,但是由于它来自有声读物,同一说话者的不同话语之间的语气和风格会有很大的不同。我们通过使用ASR模型强制将音频与抄本对齐,并在静音时中断片段,将中值持续时间从14秒减少到5秒,从而将数据重新分段为更短的话语。与原始数据集一样,成绩单中没有标点符号。说话人集合在训练、验证和测试集合中是完全不相交的。
LibriSpeech clean语料库中的许多记录包含明显的环境和静态背景噪声。我们使用简单的谱减法[4]去噪过程对目标谱图进行预处理,其中话语的背景噪声谱被估计为整个信号的每个频带中能量的第10个百分点。该过程仅用于合成目标;原始的嘈杂语音被传递给说话人编码器。
我们为这两个语料库分别训练了合成和声码器网络。在本节中,我们使用在音素输入上训练的合成网络,以便在主观评估中控制发音。对于VCTK数据集,它的音频非常干净,我们发现在地面真实mel频谱图上训练的声码器工作得很好。然而,对于噪音更大的LibriSpeech,我们发现有必要根据合成器网络预测的频谱图来训练声码器。没有对声码器训练的目标波形进行去噪。
说话人编码器是在一个专有的语音搜索语料库上训练的,该语料库包含来自美国18K英语使用者的36M话语,平均持续时间为3.9秒。该数据集未被转录,但包含匿名的说话者身份。它从未用于训练合成网络。
我们主要依靠基于主观听力测试的众包平均意见得分评估。我们所有的维护对象评估都符合绝对类别评分标准[14],评分从1到5,以0.5分为增量。我们使用这个框架从两个维度来评估合成语音:它的自然度和与来自目标说话人的真实语音的相似度。
3.1 语音自然度
我们使用在VCTK和LibriSpeech上训练的合成器和声码器来比较合成语音的自然度。我们构建了一个由100个不出现在任何训练集中的短语组成的评估集,并为每个模型评估了两组说话者:一组由训练集中的说话者组成(可见),另一组由伸出的说话者组成(不可见)。我们为VCTK使用了11个可见和不可见的说话人,为LibriSpeech使用了10个可见和不可见的说话人(附录D)。对于每个说话者,我们随机选择一个持续时间约为5秒的话语来计算说话者嵌入(见附录C)。每个短语是为每个说话者合成的,每次评估总共约有1000个合成话语。每个样本都由一名评分员进行评分,每个评估都是独立进行的:不同模型的输出没有直接比较。结果如表1所示,将建议的模型与基线多说话人模型进行了比较,基线多说话人模型使用了类似于[8,13]的说话人嵌入查找表,但在其他方面与建议的合成器网络具有相同的架构。所提出的模型在所有数据集上实现了约4.0个月平均寿命,当在可见说话者上评估时,VCTK模型获得的月平均寿命比LibriSpeech模型高约0.2个点。这是LibriSpeech数据集的两个缺点的结果:(1)抄本中缺少标点符号,这使得模型很难学会自然暂停;(2)与VCTK相比,背景噪声水平更高,尽管如上所述对训练目标进行了去噪,但合成器已经学会了再现其中的一些背景噪声。
表1:95%置信区间的语音自然度平均意见得分。

最重要的是,我们的模型为看不见的说话者生成的音频被认为至少和为看得见的说话者生成的音频一样自然。令人惊讶的是,看不见的说话人的金属氧化物半导体比看得见的说话人的金属氧化物半导体高0.2个百分点。这是每个说话者随机选择参考话语的结果,其中有时包含不均衡和非中性的韵律。在非正式的听力测试中,我们发现合成语音的韵律有时会模仿参考语音的韵律,类似于[16]。这种影响在LibriSpeech上更大,因为LibriSpeech包含了更多样的韵律。这表明,在合成网络中,必须额外注意将说话者身份从韵律中分离出来,可能通过集成韵律编码器,如[16,24],或者通过对来自同一说话者的随机配对的参考和目标话语进行训练。
3.2 说话人相似度
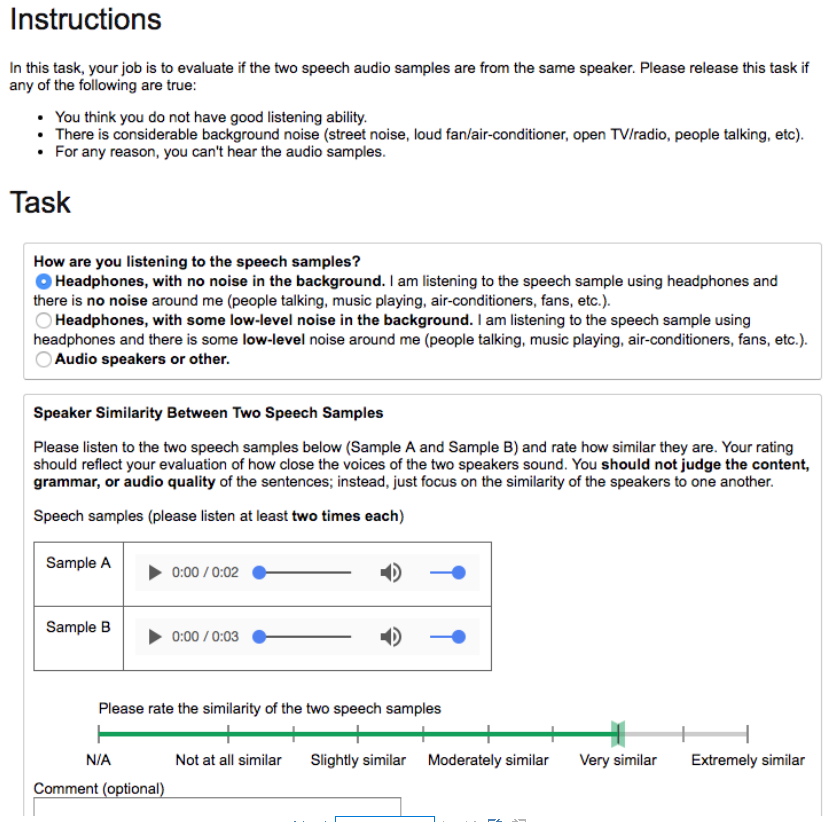
为了评估合成语音与目标说话者的匹配程度,我们将每个合成话语与来自同一说话者的随机选择的基本真实话语配对。每对句子由一名评分员按照以下说明进行评分:“你不应该判断句子的内容、语法或音频质量;相反,只需关注说话者之间的相似性。”
结果如表2所示。VCTK模型的得分往往高于LibriSpeech,反映了数据集的清洁性质。这一点在VCTK更高的基础真相基线中也很明显。对于在VCTK上看到的说话者,所提出的模型的性能与使用嵌入查找表进行说话者调节的基线相当。然而,在LibriSpeech上,所提出的模型获得了比基线更低的相似性维护对象,这可能是由于更大程度的说话人内部变化(附录B)和数据集的背景噪声水平。
表2:95%置信区间的说话者相似性平均意见得分。

在看不见的说话人身上,该模型获得了较低的背景真实度和合成语音之间的相似度。在VCTK上,3.28的相似度评分在评价量表上介于“中等相似”和“非常相似”之间。非正式地说,很明显,所提出的模型能够为看不见的说话者传递说话者特征的宽笔画,清楚地反映正确的性别、音高和共振峰范围(如图2所示)。但是看不见的说话者的相似性分数显著降低,这表明一些细微差别,例如与特征韵律相关的细微差别,丢失了。
说话人编码器只针对北美口音的语音进行训练。结果,重音不匹配限制了我们在VCTK上说话者相似性的表现,因为评分者指令没有指定如何判断重音,所以如果重音不匹配,评分者可能认为一对来自不同的说话者。事实上,对评分者评论的检查表明,我们的模型有时会产生不同于基本事实的口音,从而导致较低的分数。然而,一些评价者评论说,尽管口音不同,但声音的语气和音调变化听起来非常相似。
作为对推广到域外说话者能力的初步评估,我们使用在VCTK和LibriSpeech上训练的合成器从另一个数据集合成说话者。我们只改变了合成器和声码器网络的训练集;两种型号都使用了相同的说话人编码器。如表3所示,这些模型能够生成与表1所示的看不见但在域内的说话者具有相同自然度的语音。然而,LibriSpeech模型合成的VCTK说话人具有明显高于VCTK模型的说话人相似性,能够合成LibriSpeech说话人。LibriSpeech模型的更好概括表明,仅在100个说话人上训练合成器不足以实现高质量的说话人传输。
表3:未见过说话人的自然度和说话人相似度的跨数据集评估

3.3 说话人验证
作为未见过说话人的合成和背景真实音频之间说话人相似度的客观度量,我们评估了有限说话人验证系统区分合成语音和真实语音的能力。我们使用与第2.1节相同的网络拓扑训练了一个新的仅评估说话人编码器,但使用了不同的113K说话人的28M发音训练集。使用不同的评估模型可以确保指标不仅在特定的说话人嵌入空间有效。我们登记了21名真实说话者的声音:11名来自VCTK,10名来自LibriSpeech,并根据登记的说话者集对合成波形进行评分。在合成器培训期间,所有注册和验证说话人都不可见。说话人验证等错误率是通过将每个测试话语与每个注册说话人配对来估计的。我们为每个说话者合成了100个测试话语,所以每个评估进行了21,000或23,100次试验。
如表4所示,只要合成器在足够大的一组说话人上训练,即在LibriSpeech上,合成的语音通常最类似于地面真实声音。LibriSpeech合成器使用来自两个数据集的参考说话人获得了5-6%的相似EERs,而在VCTK上训练的合成器性能更差,尤其是在域外LibriSpeech说话人上。这些结果与表3中的主观评价一致。
表4:未见过的音箱上不同合成器的音箱验证EERs

为了测量同一说话者区分真实和合成语音的难度,我们对一组扩大的注册说话者进行了额外的评估,其中包括10个真实LibriSpeech说话者的10个合成版本。在这20个语音识别任务中,我们获得了2.86%的能效比,表明虽然合成语音倾向于接近目标说话人(余弦相似度> 0.6,如表4所示),但它几乎总是更接近同一说话人的其他合成话语(相似度> 0.7)。由此我们可以得出结论,所提出的模型可以生成与目标说话者相似的语音,但不足以与真实说话者混淆。
3.4 说话人嵌入空间
可视化说话人嵌入空间进一步将第3.2节和第3.3节中描述的量化结果联系起来。如图3所示,不同的说话人在说话人嵌入空间中彼此很好地分开。主成分分析可视化(左)显示,在嵌入空间中,合成话语往往非常接近来自同一说话者的真实语音。然而,合成语音仍然很容易与真实的人的语音区分开来,如SNE可视化(右)所示,其中来自每个合成说话者的语音形成了与来自相应说话者的真实语音的聚类相邻的不同聚类。在主成分分析和SNE可视化中,说话者似乎按性别完全分开,所有女性说话者出现在左侧,所有男性说话者出现在右侧。这表明说话人编码器已经了解了说话人空间的合理表示。

图3:从LibriSpeech话语中提取的说话者嵌入的可视化。每种颜色对应不同的说话人。当真实和合成的话语来自同一个说话者时,它们出现在附近,然而真实和合成的话语一致地形成不同的群。
3.5 说话人编码器训练说话人的数量
很可能,所提出的模型在各种各样的说话者中很好地概括的能力是基于说话者编码器所学习的表示的质量。因此,我们研究了说话人编码器训练集对合成质量的影响。我们使用了三个额外的训练集:(1)Liblispeech Other,它包含来自1,166个说话者的461个小时的语音,这些说话者与干净子集中的说话者不相交,(2)V OxCele[11],和(3)V OxCele 2[6],它们分别包含来自1,211个说话者的139K个话语和来自5,994个说话者的1.09M个话语。
表5比较了作为用于训练说话人编码器的说话人数量的函数的提议模型的性能。这衡量了训练说话人编码器时说话人多样性的重要性。为了避免过度拟合,在小数据集(前两行)上训练的说话人编码器使用较小的网络架构(256维LSTM单元,64维投影)并输出64维说话人嵌入。
表5:使用在不同数据集上训练的说话人编码器的性能。合成器都是在LibriSpeech Clean上训练的,并在手持说话人上进行评估。LS: LibriSpeech,VC:V oxcelbe。
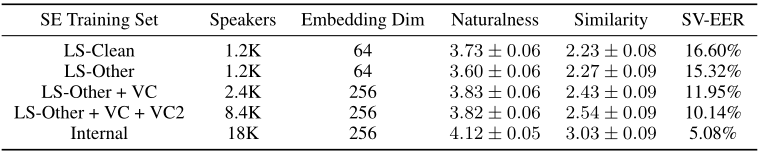
我们首先评估在LibriSpeech Clean和其他设备上训练的说话人编码器,每个设备包含相似数量的说话人。在Clean中,说话人编码器和合成器是在相同的数据上训练的,该数据与[2]中的非微调说话人编码器的基线相似,只是它的训练方式与[10]中的有区别。这种匹配的条件给出了稍微好一点的自然度和相似性分数。随着训练说话者数量的增加,自然度和相似度都显著提高。客观的能效比结果也随着主观评估而提高。
这些结果对多说话人TTS训练有重要意义。说话人编码器的数据要求比完整的TTS训练便宜得多,因为不需要抄本,并且音频质量可以低于TTS训练。我们已经表明,通过将在大量未编码数据上训练的说话人编码器网络与在更小的高质量数据集上训练的说话人编码器网络相结合,合成非常自然的说话人转换系统是可能的。
3.6 虚构的说话人
绕过说话人编码器网络,并在说话人嵌入空间中的随机点上调节合成器,会导致来自虚拟说话人的语音,这些语音不存在于合成器或说话人编码器的训练或测试集中。这在表6中得到证明,该表将从单位超球面表面上的均匀采样点生成的10个这样的说话人与它们在组件网络的训练集中的最近邻居进行了比较。在登记了10个最近邻居的声音后,使用与第3.3节相同的设置来计算奇异值分解。尽管这些说话人完全是虚构的,但合成器和声码器能够像看得见或看不见的真实说话人一样自然地产生音频。与最近邻训练话语的低余弦相似性和非常高的能效比表明它们确实不同于训练说话者。
表6:虚拟说话者的讲话与他们在列车组中最近的邻居的比较。合成器在LS Clean上训练。说话人编码器在LS-Other + VC + VC2上训练。

4 结论
我们提出了一个基于神经网络的多说话人TTS合成系统。该系统将一个独立训练的说话人编码器网络与一个序列到序列的TTS合成网络和基于Tacotron 2的神经声码器相结合。通过利用辨别性说话人编码器所学习的知识,合成器不仅能够为训练期间看到的说话人生成高质量的语音,还能够为以前从未见过的说话人生成高质量的语音。通过基于说话人验证系统和主观听力测试的评估,我们证明了合成语音与来自目标说话人的真实语音相当相似,即使是在这种看不见的说话人身上。
我们运行实验来分析用于训练不同组件的数据量的影响,并且发现,给定合成器训练集中足够的说话者多样性,可以通过增加说话者编码器训练数据量来显著提高说话者传递质量。
迁移学习对实现这些结果至关重要。通过分离说话人编码器和合成器的训练,该系统显著降低了对多说话人TTS训练数据的要求。它既不需要合成器训练数据的说话者身份标签,也不需要说话者编码器训练数据的高质量干净语音或抄本。此外,与[10]相比,独立训练组件大大简化了合成器网络的训练配置,因为它不需要额外的三重或对比损耗。然而,使用低维向量建模说话人变化限制了利用大量参考语音的能力。在给定几秒钟以上的参考语音的情况下,提高说话者相似性需要一种模型自适应方法,如[2]和最近的[5]中所述。
最后,我们证明了该模型能够从不同于训练集的虚拟说话人生成逼真的语音,这意味着该模型已经学会利用说话人变化空间的逼真表示。
尽管使用了WaveNet声码器(以及其非常高的推理成本),与[15]中的单个说话者结果相比,所提出的模型没有达到人的水平的自然性。这是由于在每个说话者的数据明显较少的情况下,为各种说话者生成语音的额外困难,以及使用具有较低数据质量的数据集。另外一个限制在于模型不能转移重音。给定足够的训练数据,这可以通过在独立的说话者和重音嵌入上调节合成器来解决。最后,我们注意到,该模型也不能完全将说话者的声音从参考音频的韵律中分离出来,这与[16]中观察到的趋势相似。
致谢
作者感谢黑加·陈(Heiga Zen)、王玉轩(Y uxuan Wang)、萨米·本吉奥(Samy Bengio)、谷歌人工智能感知团队(Google AI Perception)以及谷歌TTS和DeepMind Research团队的有益讨论和反馈。
参考文献
[1] Artificial Intelligence at Google – Our Principles. https://ai.google/principles/, 2018.
[2] Sercan O Arik, Jitong Chen, Kainan Peng, Wei Ping, and Yanqi Zhou. Neural voice cloning with a few samples. arXiv preprint arXiv:1802.06006, 2018.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Y oshua Bengio. Neural machine translation by jointly learning to align and translate. In Proceedings of ICLR, 2015.
[4] Steven Boll. Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on Acoustics, Speech, and Signal Processing, 27(2):113–120, 1979.
[5] Y utian Chen, Y annis Assael, Brendan Shillingford, David Budden, Scott Reed, Heiga Zen, Quan Wang, Luis C Cobo, Andrew Trask, Ben Laurie, et al. Sample efficient adaptive text-to-speech. arXiv preprint arXiv:1809.10460, 2018.
[6] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. V oxCeleb2: Deep speaker recognition. In Interspeech, pages 1086–1090, 2018.
[7] Rama Doddipatla, Norbert Braunschweiler, and Ranniery Maia. Speaker adaptation in dnnbased speech synthesis using d-vectors. In Proc. Interspeech, pages 3404–3408, 2017.
[8] Andrew Gibiansky, Sercan Arik, Gregory Diamos, John Miller, Kainan Peng, Wei Ping, Jonathan Raiman, and Y anqi Zhou. Deep V oice 2: Multi-speaker neural text-to-speech. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 2962–2970. Curran Associates, Inc., 2017.
[9] Georg Heigold, Ignacio Moreno, Samy Bengio, and Noam Shazeer. End-to-end text-dependent speaker verification. In Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on, pages 5115–5119. IEEE, 2016. [10] Eliya Nachmani, Adam Polyak, Y aniv Taigman, and Lior Wolf. Fitting new speakers based on a short untranscribed sample. arXiv preprint arXiv:1802.06984, 2018.
[11] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. V oxCeleb: A large-scale speaker identification dataset. arXiv preprint arXiv:1706.08612, 2017.
[12] V assil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. LibriSpeech: an ASR corpus based on public domain audio books. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, pages 5206–5210. IEEE, 2015.
[13] Wei Ping, Kainan Peng, Andrew Gibiansky, Sercan O. Arik, Ajay Kannan, Sharan Narang, Jonathan Raiman, and John Miller. Deep V oice 3: 2000-speaker neural text-to-speech. In Proc. International Conference on Learning Representations (ICLR), 2018.
[14] ITUT Rec. P . 800: Methods for subjective determination of transmission quality. International Telecommunication Union, Geneva, 1996.
[15] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Y u Zhang, Y uxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, and Y onghui. Wu. Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions. In Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018.
[16] RJ Skerry-Ryan, Eric Battenberg, Ying Xiao, Y uxuan Wang, Daisy Stanton, Joel Shor, Ron J. Weiss, Rob Clark, and Rif A. Saurous. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron. arXiv preprint arXiv:1803.09047, 2018. 10
[17] Jose Sotelo, Soroush Mehri, Kundan Kumar, João Felipe Santos, Kyle Kastner, Aaron Courville, and Y oshua Bengio. Char2Wav: End-to-end speech synthesis. In Proc. International Conference on Learning Representations (ICLR), 2017.
[18] Yaniv Taigman, Lior Wolf, Adam Polyak, and Eliya Nachmani. V oiceLoop: V oice fitting and synthesis via a phonological loop. In Proc. International Conference on Learning Representations (ICLR), 2018.
[19] Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. CoRR abs/1609.03499, 2016.
[20] Ehsan V ariani, Xin Lei, Erik McDermott, Ignacio Lopez Moreno, and Javier GonzalezDominguez. Deep neural networks for small footprint text-dependent speaker verification. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on, pages 4052–4056. IEEE, 2014.
[21] Christophe V eaux, Junichi Y amagishi, Kirsten MacDonald, et al. CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit, 2017.
[22] Li Wan, Quan Wang, Alan Papir, and Ignacio Lopez Moreno. Generalized end-to-end loss for speaker verification. In Proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2018.
[23] Y uxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Y onghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Y ang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Y annis Agiomyrgiannakis, Rob Clark, and Rif A. Saurous. Tacotron: Towards end-to-end speech synthesis. In Proc. Interspeech, pages 4006–4010, August 2017.
[24] Y uxuan Wang, Daisy Stanton, Y u Zhang, RJ Skerry-Ryan, Eric Battenberg, Joel Shor, Ying Xiao, Fei Ren, Ye Jia, and Rif A Saurous. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. arXiv preprint arXiv:1803.09017, 2018.
附录一 附加联合培训基线
表7:语音自然度和说话者相似性平均意见得分(MOS),基线模型的95%置信区间,其中说话者编码器和合成器网络被联合训练(前两行)。用于比较的包括来自表5(中间行)的单独训练的基线,以及来自表1和2(底部两行)的嵌入查找表基线和建议模型。除了最后一排,所有人都是完全在图书馆接受培训的。最下面一行使用在单独的说话人语料库上训练的说话人编码器。所有评估都在图书馆网页上。

尽管如3.5节所述,如果说话人编码器是在更大的未编码语音语料库上训练的,那么说话人编码器和合成器网络的单独训练是必要的,但在本节中,我们评估说话人编码器和合成器网络的联合训练作为基线的有效性,类似于[10]。
我们在LibriSpeech的干净子集上训练,包含1.2K说话人,并在第3.5节之后使用64的说话人嵌入维度。我们比较了两个基线联合训练系统:一个对说话人编码器的输出没有任何约束,类似于[16],另一个具有额外的说话人识别损失,通过线性投影传递64维说话人嵌入来形成softmax说话人分类器的逻辑,优化相应的交叉熵损失。
自然度和说话者相似性的金属氧化物半导体结果如表7所示,将这些联合训练的基线与前面章节中报告的结果进行比较。我们发现,两个联合训练的模型在可见的说话者身上获得了相似的自然性,而包含有区别性说话者损失的变体在不可见的说话者身上表现更好。就未见过的说话人的自然度和相似度而言,包含说话人损失的模型与表5中的基线具有几乎相同的性能,表5使用了单独训练的说话人编码器,该编码器也经过优化以区分说话人。最后,我们注意到,所提出的模型使用在18K说话者语料库上单独训练的说话者编码器,显著优于所有基线,再次强调了迁移学习对于该任务的有效性。
附录二 说话人变体
LibriSpeech的语调和风格在不同的话语之间有很大的差异,即使是来自同一个说话者。在一些例子中,说话者甚至试图模仿不同性别的声音。结果,比较来自同一说话者的不同话语之间的说话者相似性(即自相似性)有时可能相对较低,并且因说话者而异。由于LibriSpeech录音中的噪音水平,一些说话人的自然度得分明显较低。这也因人而异。这可以在表8中看到。相比之下,VCTK在自然性和自相似性两个方面都更加一致。
表4显示了不同说话人在合成音频上的MOS的差异。它比较了Ground truth 和合成的不同说话人的模型,揭示了我们提出的模型在VCTK上的性能也非常依赖于说话人。比如说话人“p240”获得了4.48的MOS,与地面真值(4.57)的MOS非常接近,但说话人“p260”却比其地面真值落后整整0.5分。
表8:Ground truth MOS评价对看不见的说话者的分类。相似性评估比较同一说话者的两种话语。
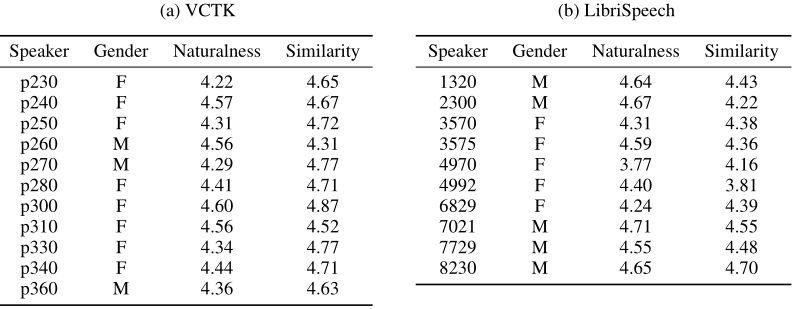

图4:在看不见的VCTK说话人上的地面真实和合成语音的每说话人自然度MOS
附录C:参考语音时长的影响
表9:参考语音话语持续时间的影响。在VCTK上评价

所提出的模型依赖于馈送到说话者编码器的参考语音信号。如表9所示,增加参考语音的长度显著提高了相似性,因为我们可以用它来计算更精确的说话人嵌入。质量在VCTK上大约5秒钟达到饱和。较短的参考话语给出了稍好的自然度,因为它们更好地匹配用于训练合成器的参考话语的持续时间,合成器的中值持续时间为1.8秒。所提出的模型仅使用2秒的参考音频就实现了接近最佳的性能。仅使用5秒钟语音的性能饱和突出了所提出的模型的局限性,其受到说话人嵌入的小容量的限制。在[2]中也发现了类似的缩放,其中在有限的自适应数据下,仅自适应说话人嵌入被证明是有效的,但是如果有更多的数据可用,则需要对整个模型进行微调以提高性能。这种模式在最近的工作中也得到了证实[5]。
附录D:评估说话人集合

附录E:虚构的说话人

图5:一个句子的合成例子,条件是从单位超球体中采样的几个随机说话人嵌入。所有样本都包含一致的语音内容,但基频和语速有明显的变化。对应于这些话语的音频文件包含在演示页面中(https://google.github.io/tacotron/publications/说话人适应)。
附录F 说话人相似性MOS评估界面
【CSDN文章】阅读理解:Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
【深声科技】声音克隆产品
【CSDN文章】只需5秒音源,这个网络就能实时“克隆”你的声音

