
- 1了解O2OA(翱途)开发平台中的VIP应用
- 2NLP_Python3——jieba中文处理_jieba lcut和lcut_for_search区别
- 3NLP算法-词性标注_nlp词性标注
- 4[深度学习TF2][RNN-LSTM]文本情感分析包含(数据预处理-训练-预测)_lstm预测模型tf2
- 5弹窗中的彩蛋,一款在线开发工具 JupyterNotebook,一篇博客就会用|Python技能树测评_在线开发notebook
- 6基于ChatGPT的智能客服助手_chatgpt怎么做客服系统
- 72022人机交互-考题复习_在人机交互领域,计算机可能指的是
- 8GroundingDINO运行教程_groundingdino_swint_ogc.pth
- 9计算机二级Ms office考试经验贴_cct二级office高级应用考试时长
- 10逐帧分析,Devin如何成为AI软件开发者_devin ai
探索华为云CCE敏捷版金融级高可用方案实践案例
赞
踩
本文分享自华为云社区《华为云CCE敏捷版金融级高可用方案实践》,作者: 云容器大未来。
一、背景
▎1.1. CCE 敏捷版介绍
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
从实践角度讲,CCE 敏捷版是在大规模高可靠的云服务和大量高性能金融级应用的驱动下产生的新一代软件开发、集成、管理和运维的云原生管理平台。CCE 敏捷版,为企业提供数字化新基建的云原生技术平台,帮助企业实现业务敏捷上线、业务战略快速落地。作为容器混合云在线下的延伸,CCE 敏捷版提供了高性能可扩展的容器服务,快速构建高可靠的容器集群,兼容 Kubernetes 及 Docker 容器生态。帮助用户轻松创建和管理多样化的容器工作负载,并提供容器故障自愈,监控日志采集,自动弹性扩容等高效运维能力。
▎1.2. 为什么要两地三中心
随着互联网技术的发展,云平台建设已经成为企业信息化建设的重要组成部分。在实际的云平台建设过程中,为了保证系统的高可用性和可靠性,需要考虑到多个层次上的冗余。一般通过多副本可以实现应用层面的冗余,在地域级别的故障场景下,两地三中心的高可用架构是一种常见的设计方案。
通过将系统部署在两个地理位置,三个不同的数据中心,从而实现对系统的高可用性和容错性的保障。在实际的应用场景中,两地三中心的高可用架构主要适用于对系统可用性要求非常高的场景,例如金融、电信、医疗等行业。利用两地三中心,可以有效地避免单点故障的风险,并在系统出现故障时快速切换到备中心,从而保证系统的持续稳定运行。
▎1.3. 适用场景
两地三数据中心整体统一规划,采用华为 CCE 敏捷版的产品构建微服务应用的两地多中心的容灾方案,从单中心开始分步骤实施建设。
二、方案说明
▎2.1. 整体容灾方案
本方案描述两地三中心的方案支持客户的业务高可用;
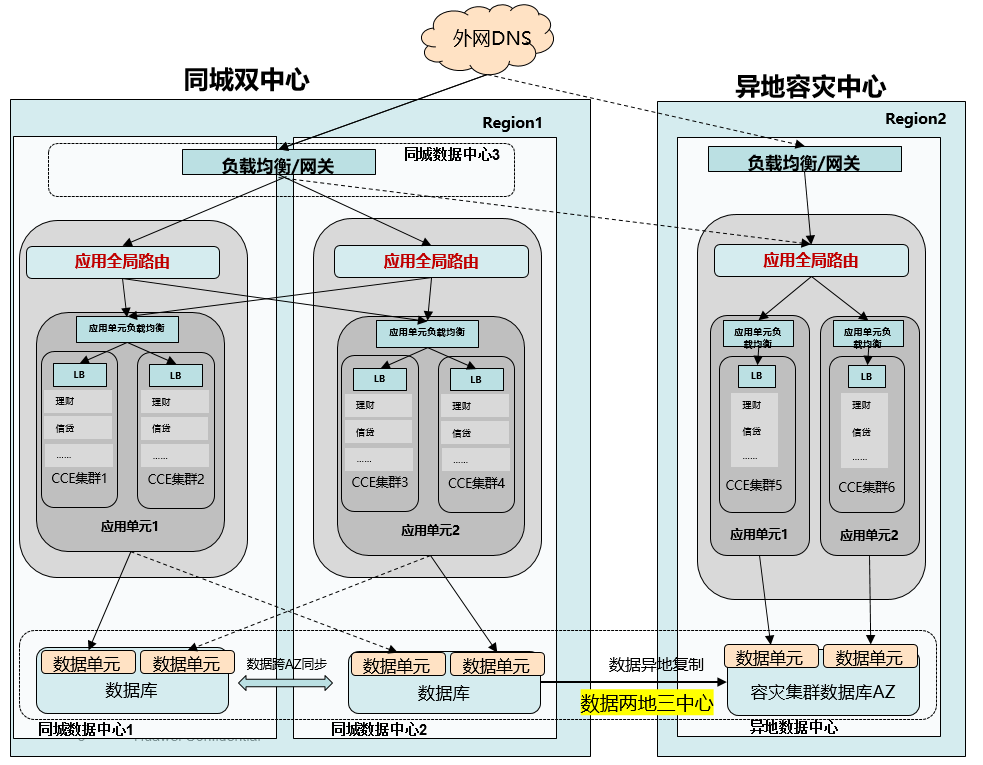
方案说明:
- 建立两地三中心的容灾架构,提供多集群部署能力,以上图为例,将 Region1 作为主区域提供同城双活,Region2 作为灾备站点。每个中心各自一套独立集群,对于核心业务可提供单中心双集群进一步提升高可用性,避免因为单集群故障导致业务受损。业务根据实际情况分配。
- 减小集群规模,控制故障半径:将大集群拆解到多个小集群中,单集群规模建议不超过 200 节点。灾备环境因为常态无真实业务,出于成本考虑可适当减小规模,但需要在灾备流量切换前完成数据检查和规模扩容。若无法保证规模扩容,建议按照生产环境高峰流量进行环境准备。
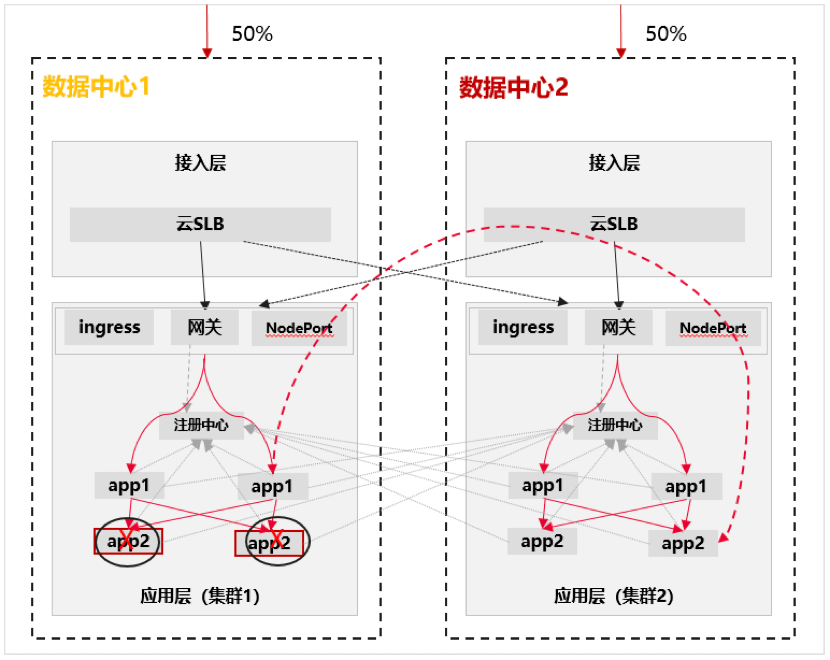
- 每个数据中心的流量通过跨云负载均衡走到云平台 SLB,再进一步将流量导入到集群中的业务网关。业务网关根据应用的注册情况将流量分配到后端应用上。正常情况下 DNS 将流量全部导向主区域站点,在灾备时将切换到容灾中心。
- 集群中的网关将流量导向后端时,可根据应用的分布和注册情况,进行流量分配,可分阶段实现集群内流量分发,以及跨集群的流量分发(需微服务框架改造)。通过业务层面的健康检查,流量探测,可实现应用路由的全局管理分发,避免单一集群、单一 AZ、单一数据中心故障,引发大量流量异常。
- 应用状态信息保存到 DB 中,应用本身无状态化,便于弹性、迁移等容灾行为处理。根据业务框架数据库可以采用同城双中心的统一单边读写机制,多中心的应用使用同一份数据库,保证一致性。同时数据库提供跨中心的实时同步到备节点,当同城双中心间发生容灾切换时,备升主,应用也切换到新的主数据库上。核心业务数据支持异地复制,确保主站点区域级别故障时提供异地的容灾拉起手段。
- 后续可针对应用业务进行单元化改造,降低单应用的故障风险面。应用单元可通过双集群等多主架构实现容灾高可用,并配套数据库的同步与容灾能力实现单元粒度的容灾切换能力。
▎2.2. 高可用关键技术
从容灾分层的角度,可以从接入层、应用层、数据层和基础设施层,分别进行高可用的设计分析。
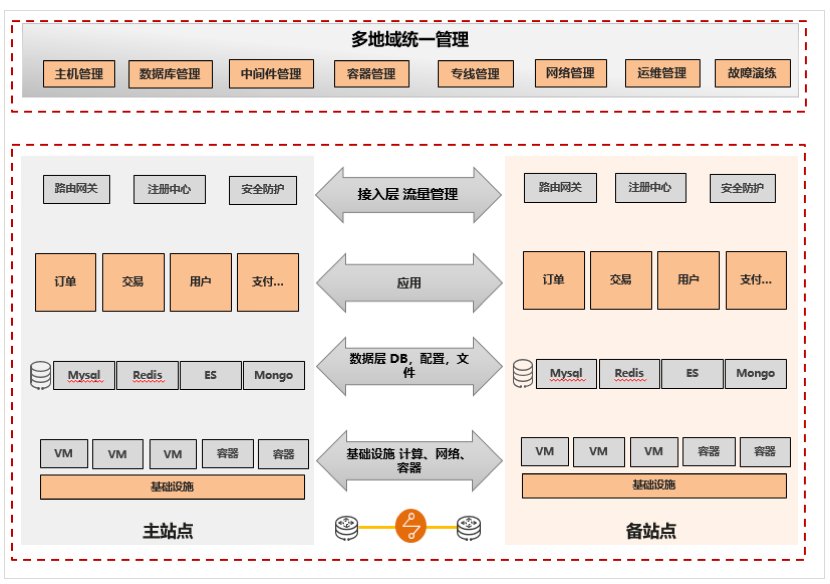
▶ 接入层流量高可用
核心要点:两层容灾,覆盖区域级别、单中心级别故障的流量切换。
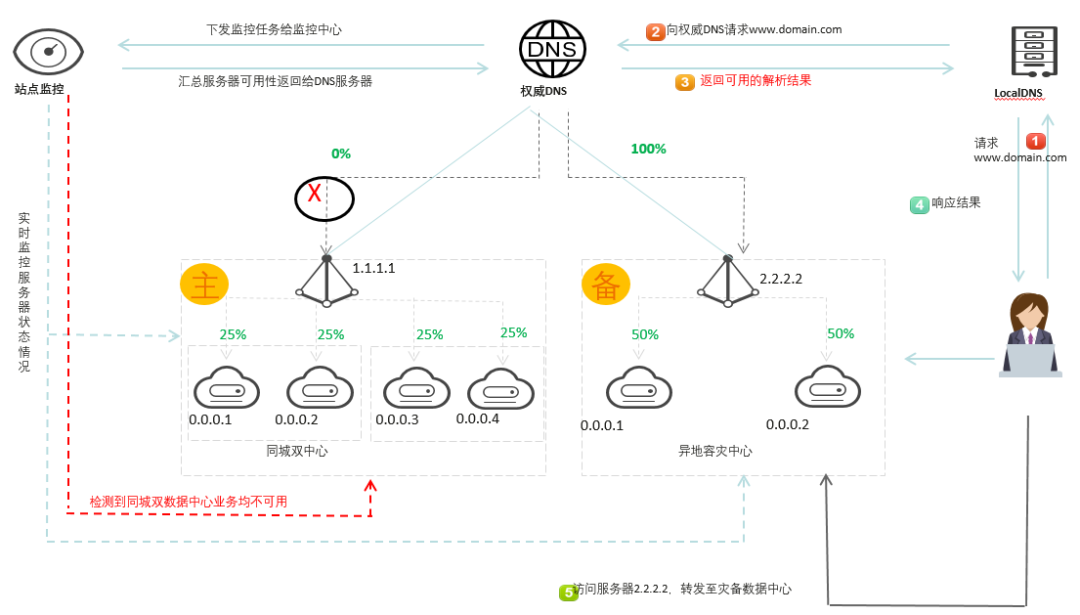
关键技术一:利用 DNS 实现路由高可用解析策略管理
1、通过 DNS A 记录权重进行轮询分流
2、支持健康检查,故障自动切换。某一地区 IP 故障,自动切换到其他可用 IP
关键技术二:单区域负载均衡权重管理
1、负载均衡同城跨中心调度流量
2、支持健康检查,根据后端负载实例情况,动态调整集群流量权重
如下图所示,当检测到故障时,公网流量切换到灾备。
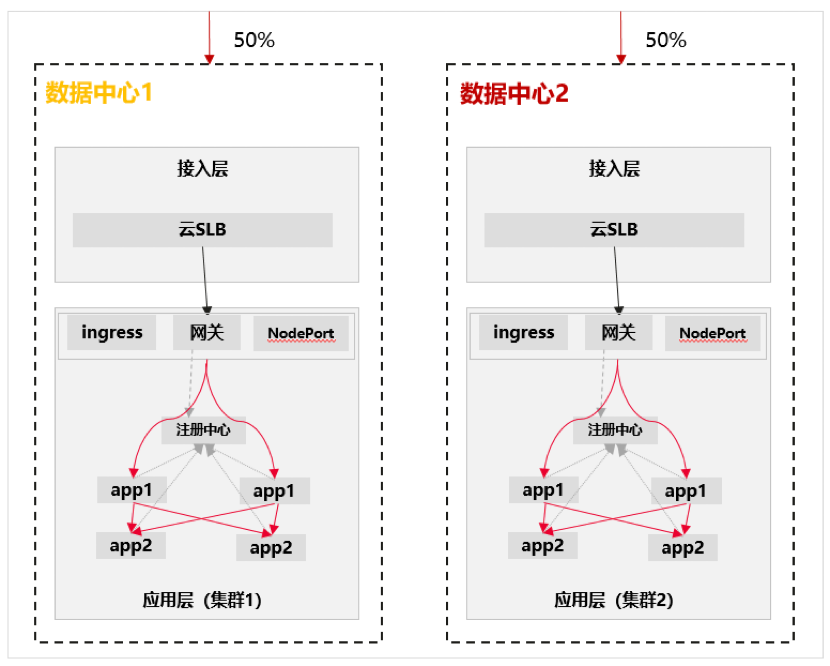
▶ 应用层容灾高可靠
核心要点,多集群多副本部署,应用路由网关实现单应用、单中心故障的业务无损,主要针对同城双活。
关键技术一:多集群多副本部署
1、通过多集群部署,避免单集群故障影响。
关键技术二:应用路由管理
1、网关基于注册信息进行流量转发。
2、Ingress、nodeport 流量基于 k8s 的 service 注册进行流量转发。
3、业务仅在单集群内访问,减少跨集群依赖。
关键技术三:跨集群路由(可逐步演进)
通过注册中心双写等机制,实现应用路由在两边集群均完整具备,当某一集群的应用全故障时可将流量导向其他的健康集群业务。在应用间互访前先读取路由,基于就近访问优先等策略进行业务间的调用转发。
1、注册中心路由注册时,将自动实现集群内的短路径以及跨集群的长路径的注册和区分。
2、集群内调用,时延最低;集群间调用,1)通过网关对外提供服务类,跨集群需通过业务网关绕行,时延有所增加,2)对于 ingress、nodeport 等 k8s 对外提供服务类, SLB 需提供健康检查机制,将流量导到对端健康的集群上。
▶ 数据库容灾高可靠
核心要点:数据库多中心部署,跨中心同步。
提供给单元化切片能力。
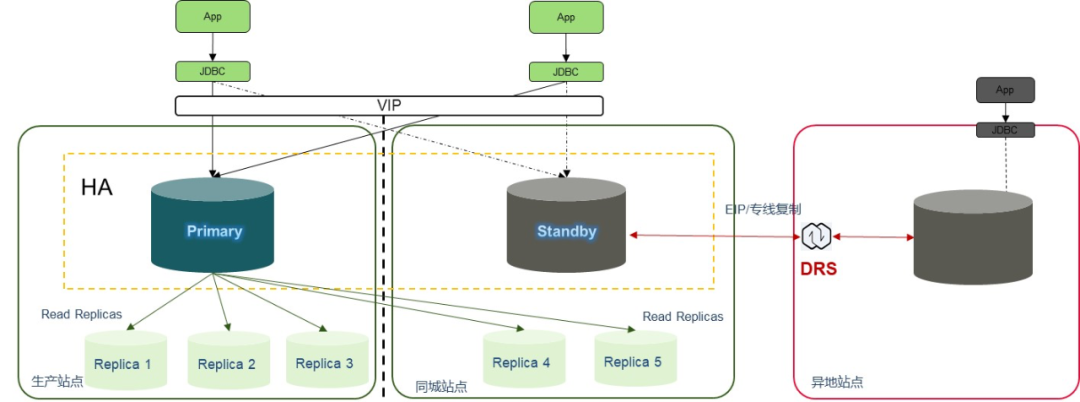
关键技术一:跨 AZ 高可用支持秒级切换
支持跨 AZ 部署,生产站点部署主库,同城站点部署备库,主备库切换为秒级
关键技术二:数据同步
支持半同步和异步两种。关注数据安全,建议选择半同步,关注性能,建议选择异步。
关键技术三:读写分离,支持多个只读实例
支持多个只读实例,分担读流量;提升查询业务吞吐能力。
关键技术四:提供对外访问的统一地址,主备切换对应用无感知
跨AZ部署的高可用实例对外采用统一的地址访问,当站点故障时,访问地址不发生变化。当主实例所在区域发生突发生自然灾害等状况,主节点(Master)和备节点(Slave)均无法连接时,可将异地灾备实例切换为主实例,在应用端修改数据库链接地址后,即可快速恢复应用的业务访问。
▶ 基础设施容灾高可靠
基础设施主要包括 IaaS、容器、存储、网络等基础资源。
对于容器而言,可以在两边的数据中心各自部署一套完整的容器平台,容器平台不跨数据中心,可以避免容器管理等业务因为跨中心的专线网络故障导致的管理受损情况。对于 IaaS、存储等基础设施,特别是存储持久化数据,则需要提供跨机房、数据中心的容灾能力。
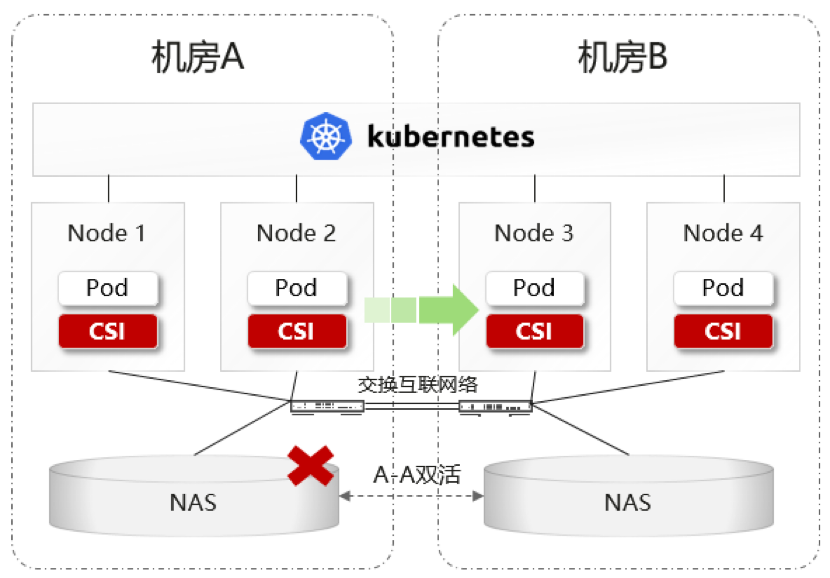
关键技术一:数据双活高可靠
对于在机房 A 运行的应用,所有数据持久化后都会立刻写入机房 B 的 NAS 存储。当机房 A 存储故障时,机房 B 存储有全量最新数据,且立即可用;业务即可快速由机房 B 接管,性能快速恢复。
关键技术二:IaaS 跨 AZ 高可用
IaaS 建设规划,需要保证数据中心内的多 AZ 建设,在多 AZ 上提供虚机、网络的高可用能力。同时,IaaS 需要评估是否需要在同城跨数据中心建设,并提供相应的技术要求。
▶ 应用单元化改造
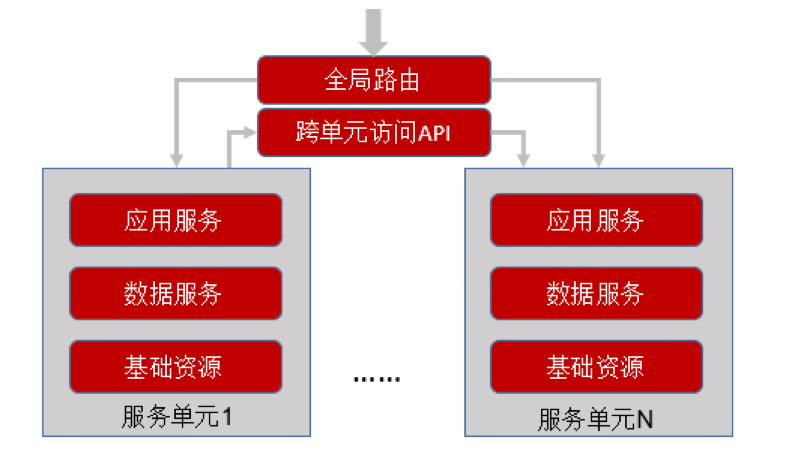
核心要点:通过单元化改造,每个单元承担全业务,从用户维度进行切分,单元包含应用+数据。
优点:故障不出单元,故障半径小;提供极致的性能和线性扩展。可通过增加单元进行水平扩展。
依赖:要求业务模型固定;应用和数据库耦合度高,需要有合适的业务分片构建全局路由,跨单元通过 API 访问,需要应用侧聚合;成本高,应用、数据需要一体化规划设计。
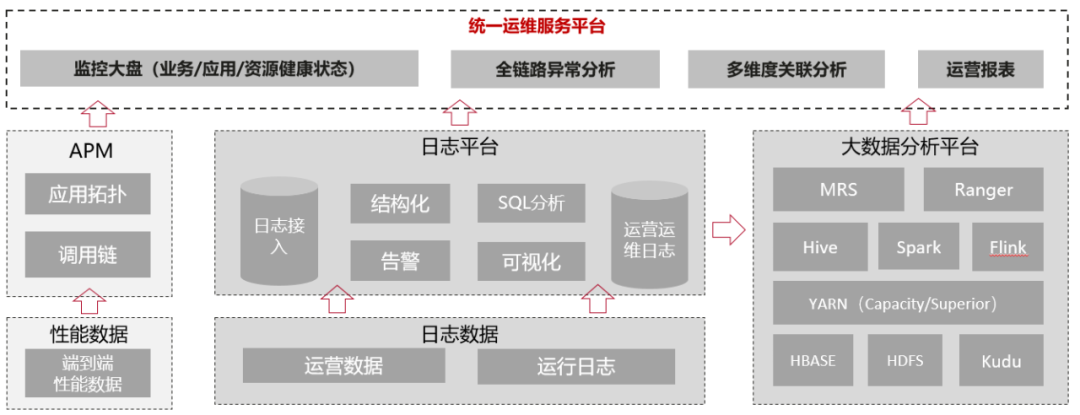
▶ 统一运维
核心要点:分层运维,提供应用的统一运维管理视图。
关键技术一:统一登录 SSO
对于 IaaS、容器、存储、数据库等多管理平台,需要与企业内部 SSO 系统打通,统一登录,统一管理,避免出现不同地域的平台登录不同的情况。
关键技术二:日志监控统一管理
多集群的应用日志、监控、链路信息,统一收集到运维服务平台,提供监控大盘、全链路分析、运营报表等能力。
三、高可用容灾系统建设
基于整体容灾方案,在基础设施建设就绪后,可以在各数据中心,进行 CCE 敏捷版的规划建设。
▎3.1. 集群容灾规划建设
采用多集群模式,一个数据中心一套独立的管控面,避免跨数据中心的依赖。在每个数据中心,存在一个管控集群,和基于业务情况规划的业务集群。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

