
- 120230115下载并编译RK3568开发板的OpenHarmony-3.1-Beta的步骤_[ohos error] [383/1102] cxx obj/foundation/ace/ace
- 2Centos 6.x 升级到 7_centos6.9升级到7.6
- 3java修改yml文件_dumperoptions
- 4ARM(IMX6U)裸机之 I.MX6ULL 启动方式详解
- 5hf-mirror 使用_hf mirror
- 6resize.cpp:4045: error: (-215:Assertion failed) !ssize.empty() in function ‘cv::resize‘_opencv(4.5.4) ../modules/imgproc/src/resize.cpp:40
- 7毕业一年后我转行NLP 这几点宝贵经验分享给大家
- 816.4 多模态情感识别
- 9【鸿蒙开发】配置文件中添加权限_鸿蒙arkts 权限
- 102023-04-13_面试题复盘笔记(81)_开望科技有限公司java
【论文阅读】Megatron-LM要点
赞
踩
Megatron-LM论文要点
本文主要是对李沐老师的b站分享做一下自己的理解和总结。
模型结构无非就是那样,相比而言,想要训练更大的模型而又能平稳进行,是一项非常高超的技术!
nvidia
跟gpipe类似,也是模型并行,但是在任务切割上面跟gpipe不一样。
gpipe: transformer也可以,cnn也可以,比较通用的方式。把不同的层放到不同的gpu,加入数据并行,成为流水线并行。
Megatron-LM:只针对特别大的使用transformer的语言模型,层中间切开,然后放到不同的gpu上。==》层切开的方法,通常命名为张量并行。
〉83亿的语言模型,使用了512块GPU,76%的分布式性能。
39亿的bert,层归一化layer norm的位置。
引言:军备竞赛
之前也有类似的工作,但是需要编译,现在这个方式更简单pytorch代码改动一点就可以了,不需要编译。
系统的文章,取舍,牺牲了通用性。
MLP层并行
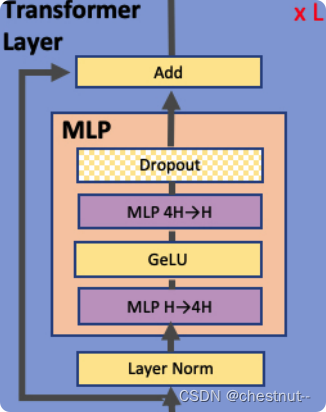
MLP输入
X
X
X,实际输入是3D的东西,改成2D的形式,方便讲解:行数是批量大小*序列长度
b
∗
l
b * l
b∗l,列数
k
k
k是隐藏层大小。
σ
(
X
⋅
A
)
⋅
B
=
Y
\sigma(X·A)·B=Y
σ(X⋅A)⋅B=Y
σ
\sigma
σ一般是GeLU。
https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/stable/nlp/megatron.html

