
- 1已解决ERROR: Could not find a version that satisfies the requirement XXX
- 2华为nova7se活力版和华为畅享20pro的区别_华为nova12活力版怎么样
- 3Ubuntu16.04 安装 indicator-sysmonitor_indicator-sysmonitor : depends: python3-psutil but
- 4unity更改模型的坐标轴位置_unity如何改变物体坐标轴
- 5labelme使用教程_labelme打开图片闪退
- 6YOLOPose实战:手把手实现端到端的人体姿态估计+原理图与代码结构_yolo-pose如何定义姿态
- 7「AI作曲家」Suno 使用 v3 在几秒钟内创作完整的两分钟歌曲_suno生成2分钟以上的
- 8NLP与AI会议期刊详细整理「CCF, SCI」_ai比较好中的trans期刊
- 9SpringCloud-实现基于RabbitMQ的消息队列_springcloud rabbitmq
- 10大模型强化学习:RLHF、PPO_大模型 rl
自然语言处理:transfomer架构
赞
踩
介绍
transfomer是自然语言处理中的一个重要神经网络结构,算是在传统RNN和LSTM上的一个升级,接下来让我们来看看它有处理语言序列上有哪些特殊之处
模型整体架构
原论文中模型的整体架构如下,接下来我们将层层解析各层的作用和代码实现
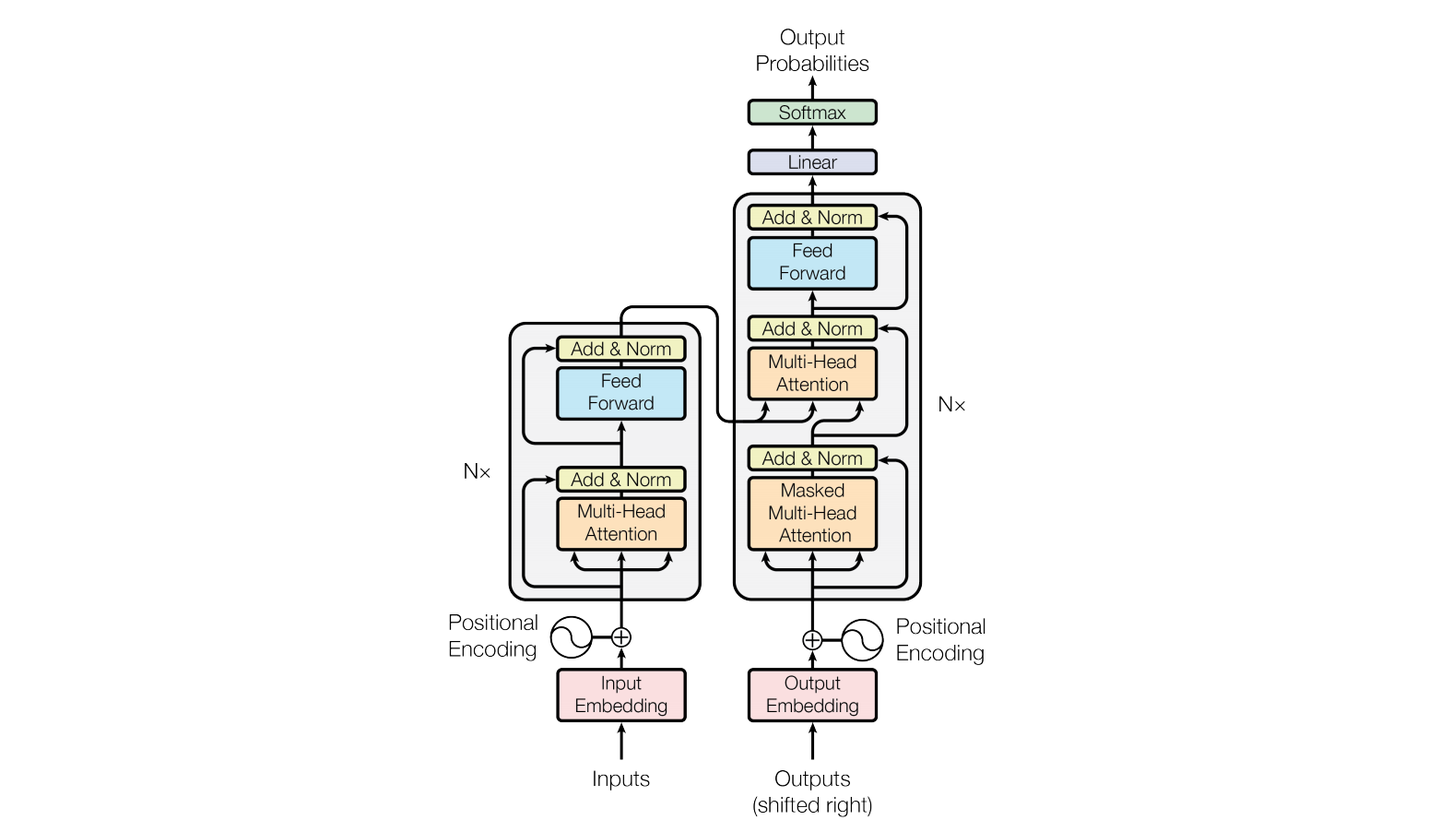
该模型架构主要包含的基本层有
- 嵌入层(Input Embedding)
- 位置编码层(Positional Encoding)
- 多头注意力层(Multi-Head Attention)
- 全连接层(Feed Forward)
位置编码层
作用
顾名思义,位置编码层使模型能够记住输入句子的位置信息,语序在理解自然语言方面起到很大的作用
位置编码层的结构
- 嵌入层(Input Embedding)
- 位置编码层(Positional Encoding)
嵌入层扩充句子维度,这也是模型训练的关键数据,位置编码层则给句子中的每个词赋予位置信息,因为嵌入层在torch中有函数可以直接调用,所以这里和位置编码层放在一起处理
位置编码的方法
我们将pe当作位置编码,pos为句子当中的第pos个词,i是第i个词向量维度,dmodel为编码维度总数。则
P E p o s , 2 i = s i n ( p o s 1000 0 i / d m o d e l ) PE_{pos, 2i}=sin(\frac{pos}{10000^{i/dmodel}}) PEpos,2i=sin(10000i/dmodelpos)
P E p o s , 2 i + 1 = c o s ( p o s 1000 0 i / d m o d e l ) PE_{pos, 2i+1}=cos(\frac{pos}{10000^{i/dmodel}}) PEpos,2i+1=cos(10000i/dmodelpos)
使用正弦和余弦函数有几个原因:
-
可学习性: 通过使用正弦和余弦函数,模型可以学习位置编码的参数。这允许模型自动调整和适应不同任务和数据集的序列长度,而无需手动调整位置编码的固定参数。
-
连续性: 正弦和余弦函数是连续的,这有助于确保位置编码的连续性。这对于模型学习和推广到未见过的序列长度是有益的。
-
相对位置信息: 正弦和余弦函数的组合能够编码相对位置信息。这意味着不同位置之间的距离和关系可以以一种更灵活的方式进行编码,而不是简单的线性关系。
-
周期性: 正弦和余弦函数具有周期性,这有助于模型在处理不同尺度的序列时更好地捕捉全局位置信息。
具体代码
接下来我们来看实现位置编码层的代码
这里以输入句子长度为50来举例
# 定义位置编码层 class PositionEmbedding(torch.nn.Module) : def __init__(self): super().__init__() # pos是第几个词,i是第几个词向量维度,d_model是编码维度总数 def get_pe(pos, i, d_model): d = 1e4**(i / d_model) pe = pos / d if i % 2 == 0: return math.sin(pe) # 偶数维度用sin return math.cos(pe) # 奇数维度用cos # 初始化位置编码矩阵 pe = torch.empty(50, 32) for i in range(50): for j in range(32): pe[i, j] = get_pe(i, j, 32) pe = pe. unsqueeze(0) # 增加一个维度,shape变为[1,50,32] # 定义为不更新的常量 self.register_buffer('pe', pe) # 词编码层 self.embed = torch.nn.Embedding(39, 32) # 39个词,每个词编码成32维向量 # 用正太分布初始化参数 self.embed.weight.data.normal_(0, 0.1) def forward(self, x): # [8,50]->[8,50,32] embed = self.embed(x) # 词编码和位置编码相加 # [8,50,32]+[1,50,32]->[8,50,32] embed = embed + self.pe return embed

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Mask
介绍
mask就是掩码,用来掩盖句子中的某些词,使模型忽略它,在transfomer中,mask有两种
- mask_pad
- mask_tril
mask_pad的作用
我们在训练模型的时候,句子往往是一批一批放入模型的,由于每个句子的长短不一,这时我们就需要规定一个固定长度,而那些长度不够的句子我们就用PAD来补充,因为PAD本身没有意义,所以我们要使用mask_pad来遮挡,使模型忽略pad
mask_tril的作用
mask_tril也叫上三角mask,transfomer的解码器任务是根据前一个词预测下一个词,因此给出第一个词时,第一个词之后的词被遮挡,给出第二个词时,第二个词之后的词被遮挡,以此类推,就是一个上三角矩阵,仍不理解可以根据具体代码来看
具体代码
mask_pad
# 定义mask_pad函数
def mask_pad(data):
# b句话,每句话50个词,这里是还没embed的
# data = [b, 50]
# 判断每个词是不是<PAD>
mask = data == vocab_x['<PAD>']
# [b, 50] -> [b, 1, 1, 50]
mask = mask.reshape(-1, 1, 1, 50)
# 在计算注意力时,计算50个词和50个词相互之间的注意力,所以是个50*50的矩阵
# PAD的列为True,意味着任何词对PAD的注意力都是0,但是PAD本身对其它词的注意力并不是0,所以是PAD的行不为True
# 复制n次
# [b, 1, 1, 50] -> [b, 1, 50, 50]
mask = mask.expand(-1, 1, 50, 50) # 根据指定的维度扩展
return mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
mask_tril
# 定义mask_tril函数 def mask_tril(data): # b句话,每句话50个词,这里是还没embed的 # data = [b, 50] # 50*50的矩阵表示每个词对其它词是否可见 # 上三角矩阵,不包括对角线,意味着对每个词而言它只能看到它自己和它之前的词,而看不到之后的词 # [1, 50, 50] """ [[0, 1, 1, 1, 1], [0, 0, 1, 1, 1], [0, 0, 0, 1, 1], [0, 0, 0, 0, 1], [0, 0, 0, 0, 0]] """ tril = 1 - torch.tril(torch.ones(1, 50, 50, dtype=torch.long)) # torch.tril返回下三角矩阵,则1-tril返回上三角矩阵 # 判断y当中每个词是不是PAD, 如果是PAD, 则不可见 # [b, 50] mask = data == vocab_y['<PAD>'] # mask的shape为[b, 50] # 变形+转型,为了之后的计算 # [b, 1, 50] mask = mask.unsqueeze(1).long() # 在指定位置插入维度,mask的shape为[b, 1, 50] # mask和tril求并集 # [b, 1, 50] + [1, 50, 50] -> [b, 50, 50] mask = mask + tril # 转布尔型 mask = mask > 0 # mask的shape为[b, 50, 50] # 转布尔型,增加一个维度,便于后续的计算 mask = (mask == 1).unsqueeze(dim=1) # mask的shape为[b, 1, 50, 50] return mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
注意力层
为什么需要注意力层
首先我们要知道在transfomer中,每个词都有一个注意力矩阵,包含对句子中其他词语的注意程度,计算注意力就是在模型训练中使模型学习到每个词语与其他词语关联程度的大小
注意力的计算
我们给每一个词向量三个矩阵,Q,K,V,再定义注意力为Z,则
Z = S o f t m a x ( Q ⋅ K d k ) ⋅ V Z=Softmax(\frac{Q·K}{\sqrt{d_{k}}})·V Z=Softmax(dk Q⋅K)⋅V
其中 d k d_{k} dk是向量编码维度
其中还要对mask进行操作
具体流程可见下列代码
具体代码
# 定义注意力计算函数 def attention(Q, K, V, mask): """ Q:torch.randn(8, 4, 50, 8) K:torch.randn(8, 4, 50, 8) V:torch.randn(8, 4, 50, 8) mask:torch.zeros(8, 1, 50, 50) """ # b句话,每句话50个词,每个词编码成32维向量,4个头,每个头分到8维向量 # Q、K、V = [b, 4, 50, 8] # [b, 4, 50, 8] * [b, 4, 8, 50] -> [b, 4, 50, 50] # Q、K矩阵相乘,求每个词相对其它所有词的注意力 score = torch.matmul(Q, K.permute(0, 1, 3, 2)) # K.permute(0, 1, 3, 2)表示将K的第3维和第4维交换 # 除以每个头维数的平方根,做数值缩放 score /= 8**0.5 # mask遮盖,mask是True的地方都被替换成-inf,这样在计算softmax时-inf会被压缩到0 # mask = [b, 1, 50, 50] score = score.masked_fill_(mask, -float('inf')) # masked_fill_()函数的作用是将mask中为1的位置用value填充 score = torch.softmax(score, dim=-1) # 在最后一个维度上做softmax # 以注意力分数乘以V得到最终的注意力结果 # [b, 4, 50, 50] * [b, 4, 50, 8] -> [b, 4, 50, 8] score = torch.matmul(score, V) # 每个头计算的结果合一 # [b, 4, 50, 8] -> [b, 50, 32] score = score.permute(0, 2, 1, 3).reshape(-1, 50, 32) return score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

