
- 1NLP快速入门
- 2BSC 链最受欢迎的竞技游戏 — Thetan Arena
- 3百度智能云“千帆大模型平台”升级,大模型最多、Prompt模板最全—测评结果超预期_百度 我的应用使用prompt模板
- 4CNN和RNN结合与对比,实例讲解_cnn与rnn结合的神经网络
- 5机器学习与深度学习核心知识点总结(一)_随机森林的特征向量 标签向量
- 6Spring Cloud Alibaba 五大组件+代码示例_springcloud alibaba 五大组件
- 7UIE与ERNIE-Layout:智能视频问答任务初探_uiex ernie layout
- 8GPT引领前沿与应用突破之GPT4科研实践技术与AI绘图教程_gpt应用开发教程
- 9【干货】程序员使用chatgpt的40个指令教程_chatgpt指令模板
- 10几种常用的优化方法梯度下降法、牛顿法、)_阶梯分布优化方法
NLP入门——基础知识_nlp学习
赞
踩
目录
4.4.2 也要经过嵌入层和位置编码,然后进入多头自注意力层
5.1 第一步:通过大量文本进行无监督预训练得到基座模型(花费多)
5.2 第二步:通过人类撰写的高质量对话数据对基座模型进行监督微调得到微调后的基座模型(SFT)
5.3 第三步:由人类标注员对多个回答的数据进行排序打分,基于该数据训练一个能对回答进行评分预测的奖励模型
6.3 分步骤思考(let's think step by step)
1 生成式AI和AIGC:
1.1 生成式AI所生成的内容就是AIGC


1.2 AI的Venn图:
注意:

1.3 监督学习(训练数据带标签):
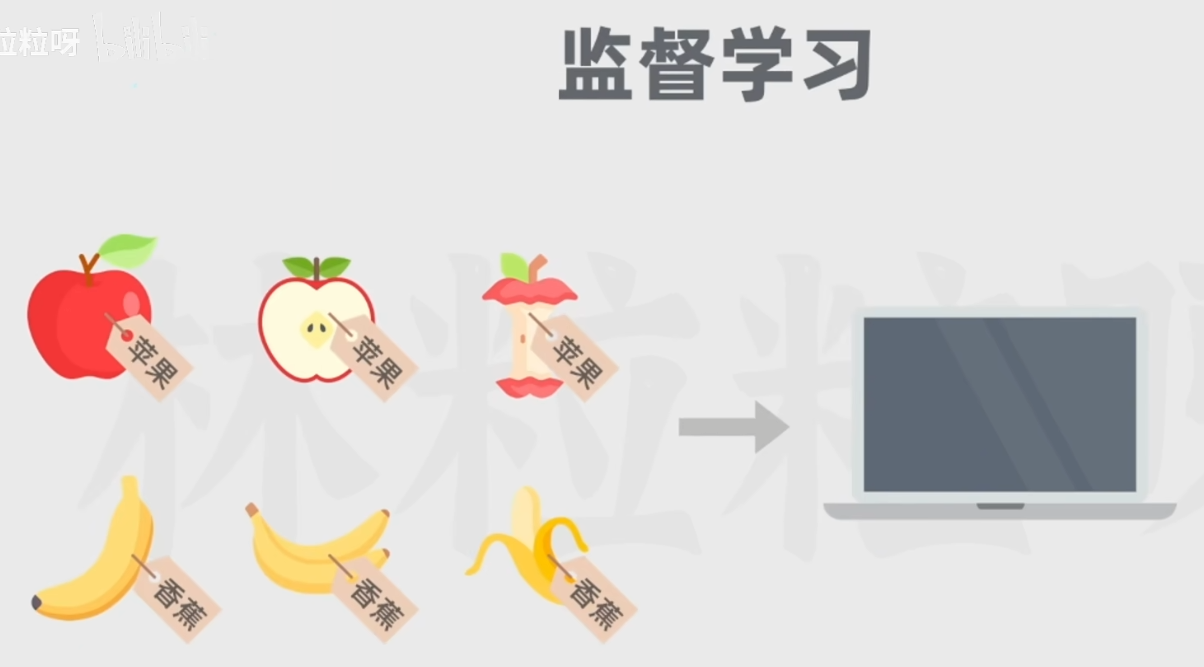
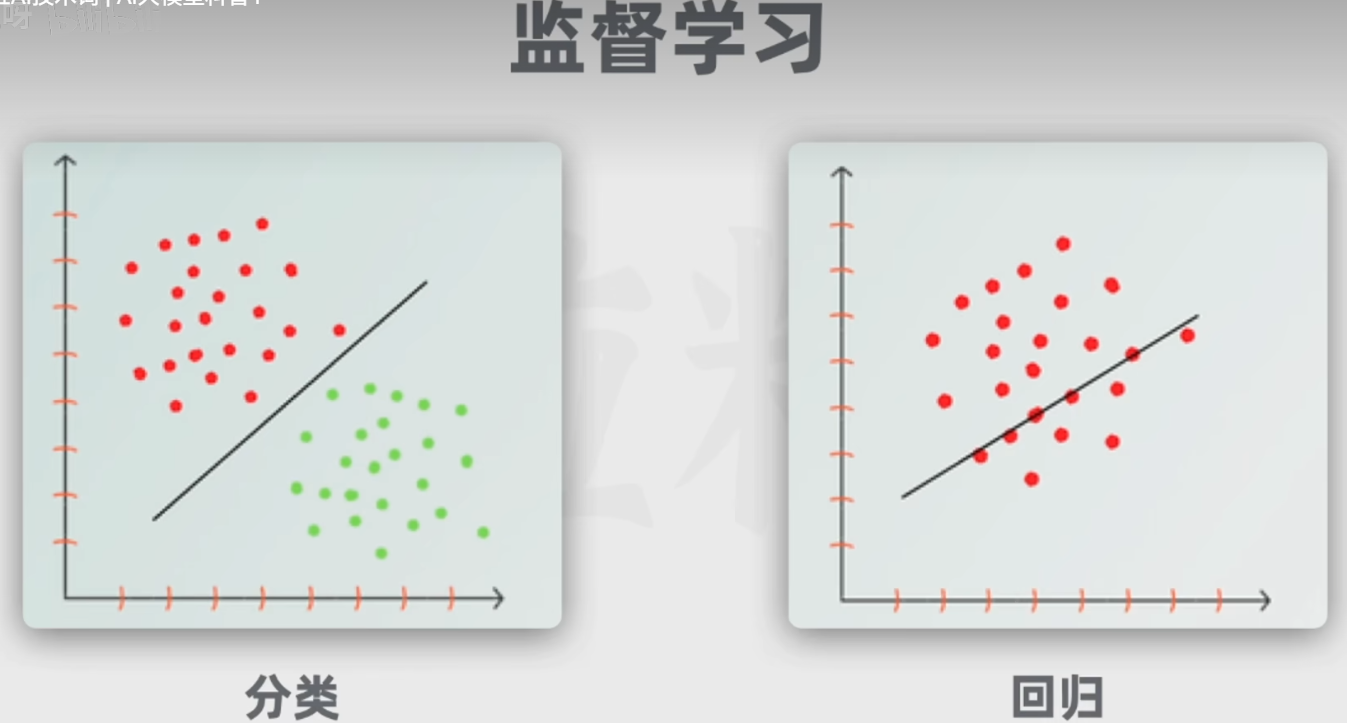
经典的监督学习任务包括分类(划分类别)和回归(预测):
1.4 无监督学习(不带标签):一般处理聚类任务
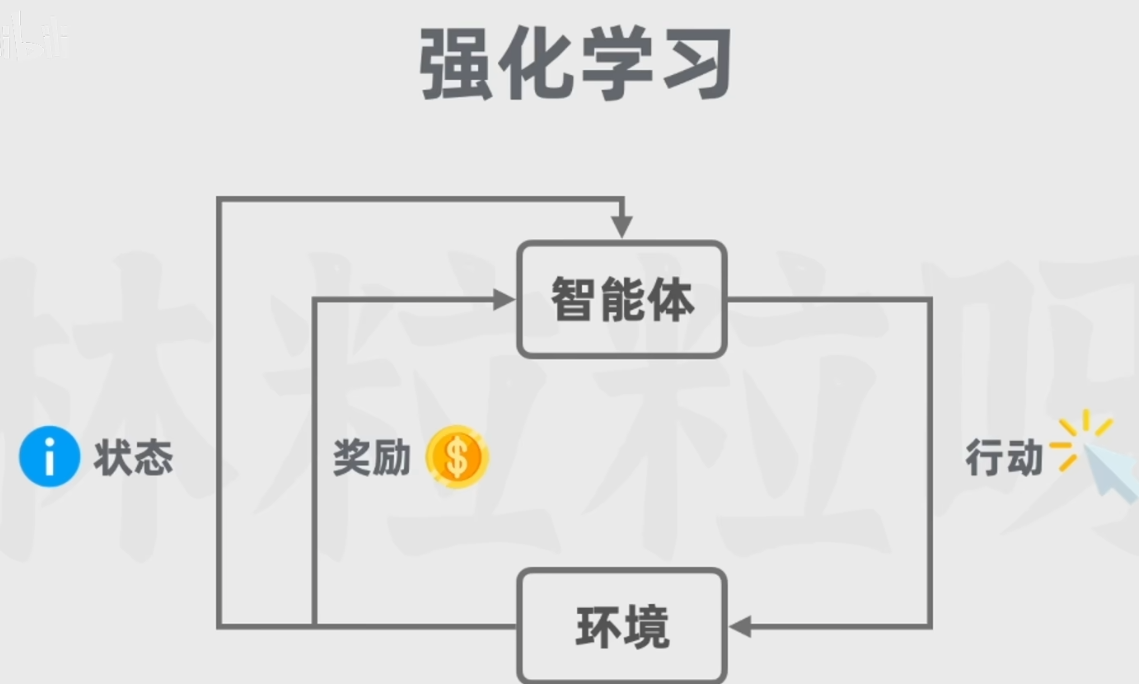
1.5 强化学习:
强化学习是一种通过主体(Agent)与环境(Environment)交互而进行学习的方法。它既不属于有监督学习,也不属于无监督学习。它的目标是要通过与环境(Environment)交互,根据环境的反馈(Reward),优化自己的策略(Policy),再根据策略行动(Action),以获得更多更好的反馈奖励(Reward)。
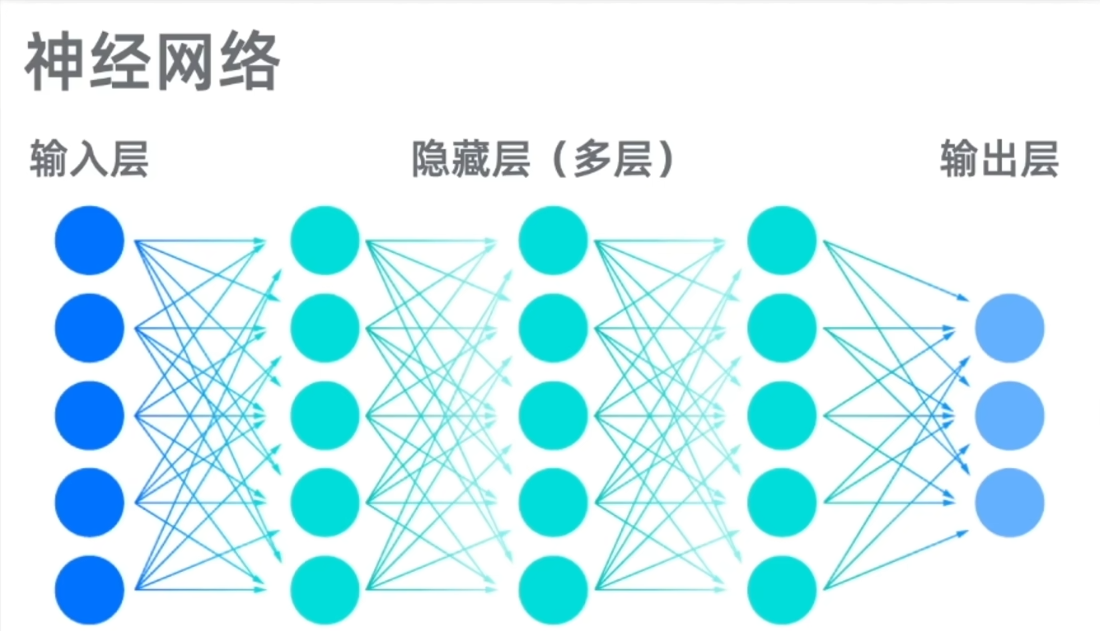
1.6 深度学习:
引入了神经元和神经网络的概念。
而生成式AI和大语言模型LLM都属于深度学习的一种应用,后者专门用于自然语言处理任务。
LLM中的大:参数多,高达数十亿;用于训练的数据多;
并非所有的生成式AI都属于大语言模型,如图像的扩散模型,并不输出文本;
大语言模型也不属于生成式AI,比如谷歌的BERT,不擅长长文本生成工作。
2 大语言模型LLM简介:
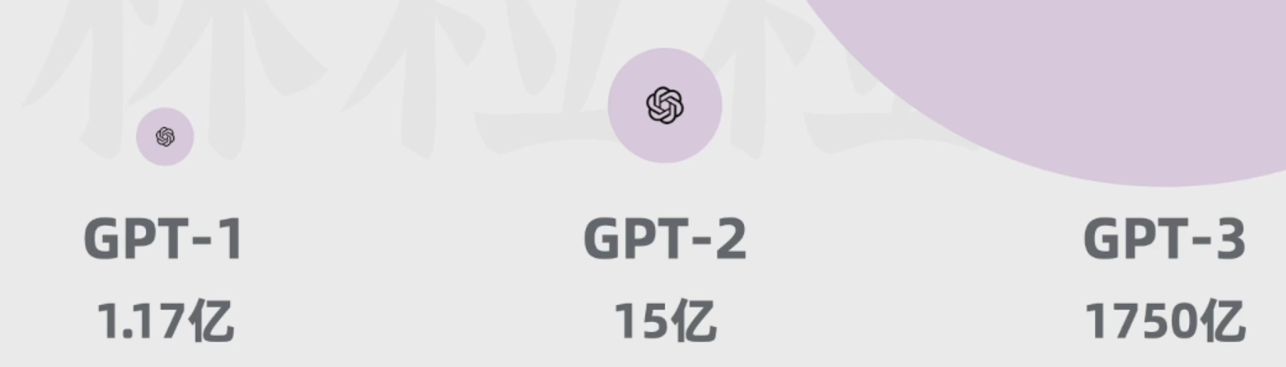
2.1 模型参数逐渐增加(泛化能力更强):
2.2 技术发展里程碑:
2017年6月,谷歌团队发表论文,提出transformer架构:
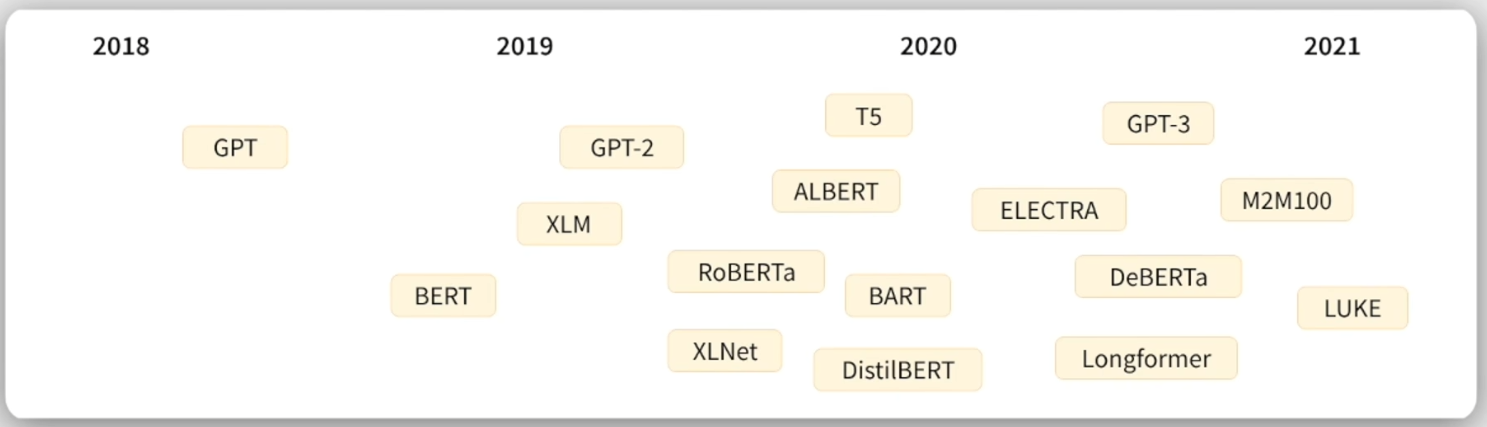
2.3 AI对话产品发展历程:
 GPT全称:(生成式预训练Transformer)
GPT全称:(生成式预训练Transformer)

3 Transformer提出之前语言模型的主流架构:
3.1 RNN(循环神经网络):
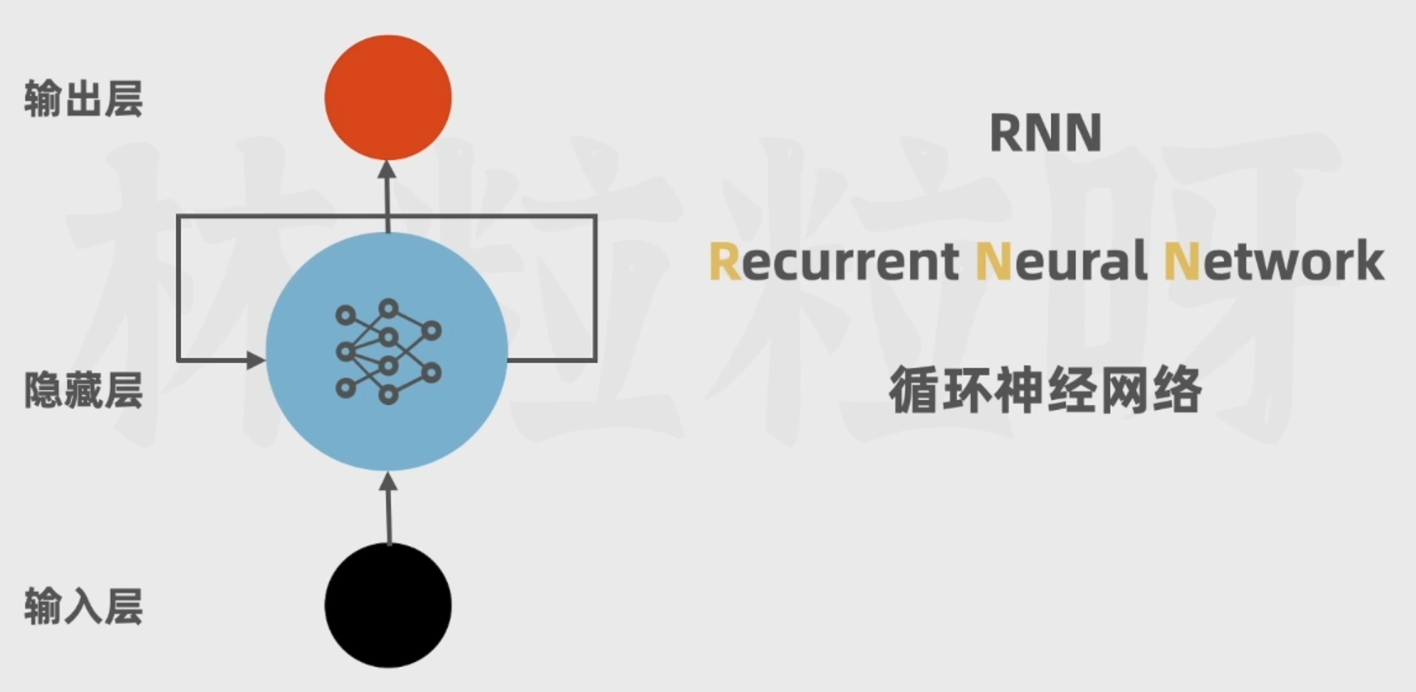
缺点:
无法并行运算,处理效率低;
不擅长处理长文本,难以捕获长距离的语义关系;比如下面这个例子:

3.2 LSTM(长短时记忆网络):
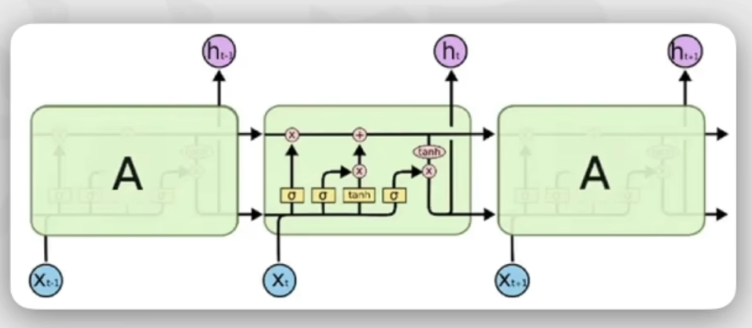
缺点:
仍然无法解决并行计算问题;
对于超长序列,仍然不能有很好的效果。
3.3 Transformer:
引入自注意力机制:计算得到每一个词和其余所有词的相关性;
位置编码:规定了词在句子中出现的顺序,便于并行训练,提高速度。
有能力学习输入序列中的所有词的相关性和上下文,不会受到短时记忆的影响;

包括词向量(文本转换为数据)和位置向量(标注在句子中出现的顺序):
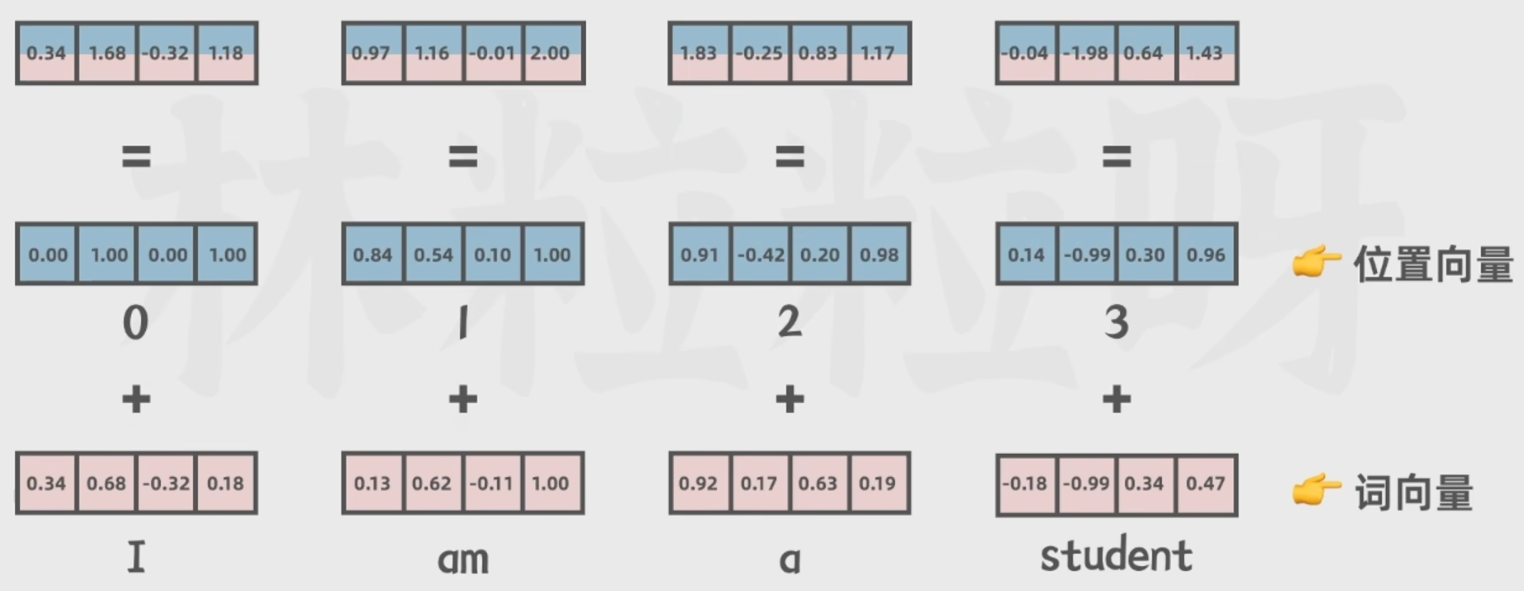
4 GPT等生成式大语言模型背后的工作原理:
4.1 公认原理:
通过预测出现概率最高的下一个词来实现文本生成(类似自动补全)

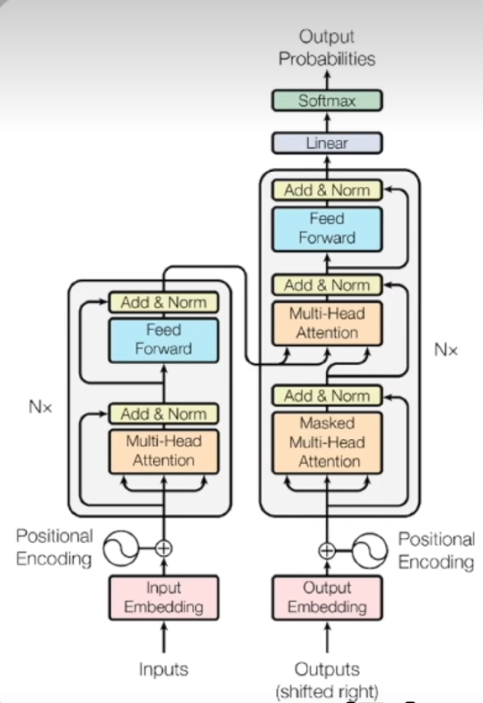
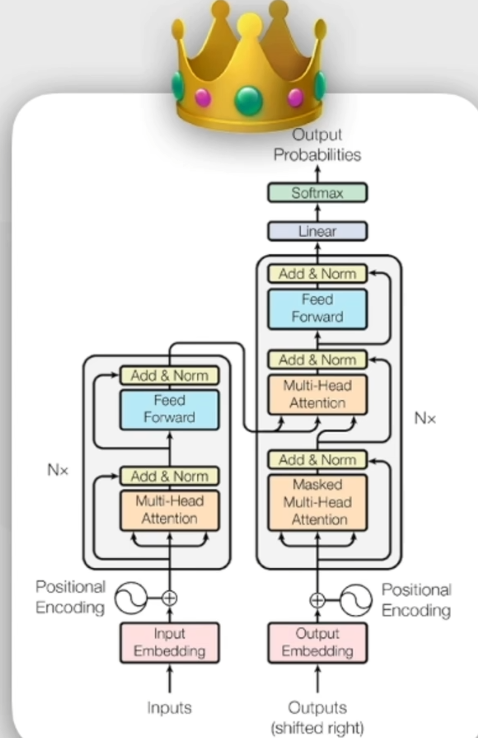
4.2 框架示意图:
4.3 编码器工作流程:
4.3.1 输入文本token化:
token:可以认为其是输入文本的基本单位,可以是一整个短词,也可以是一个长词的一部分。
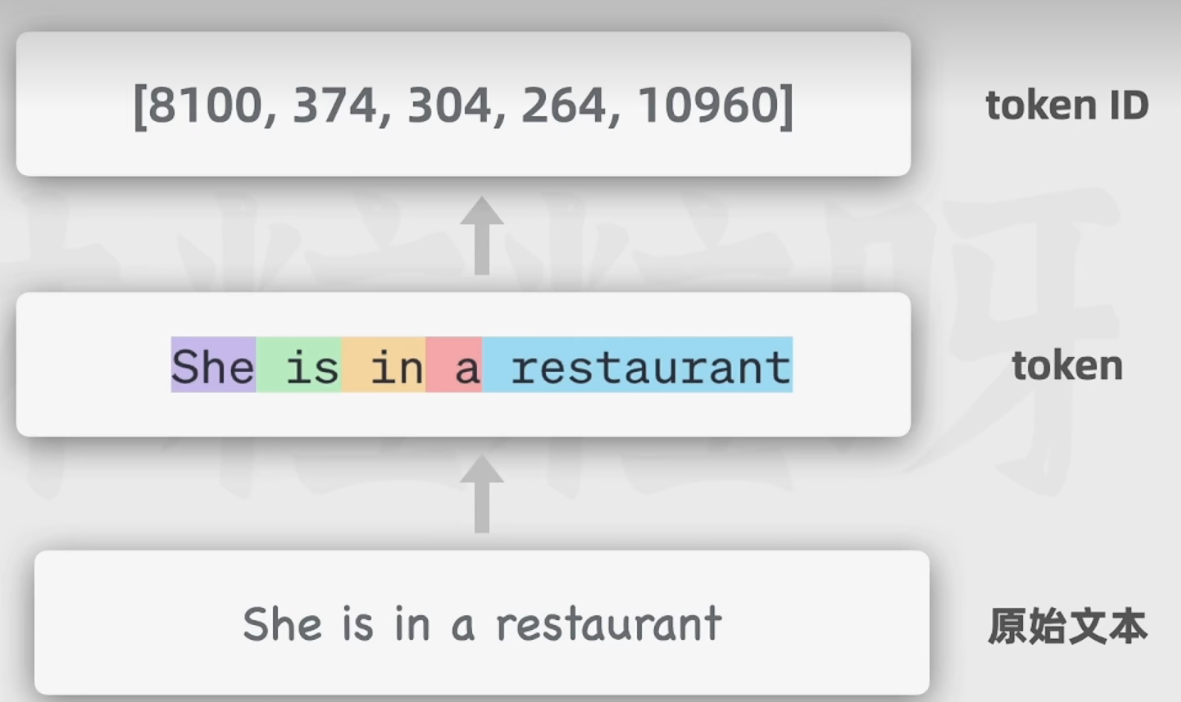
4.3.2 向量嵌入:
向量(一串数字):可以包含更多的语法语义信息;


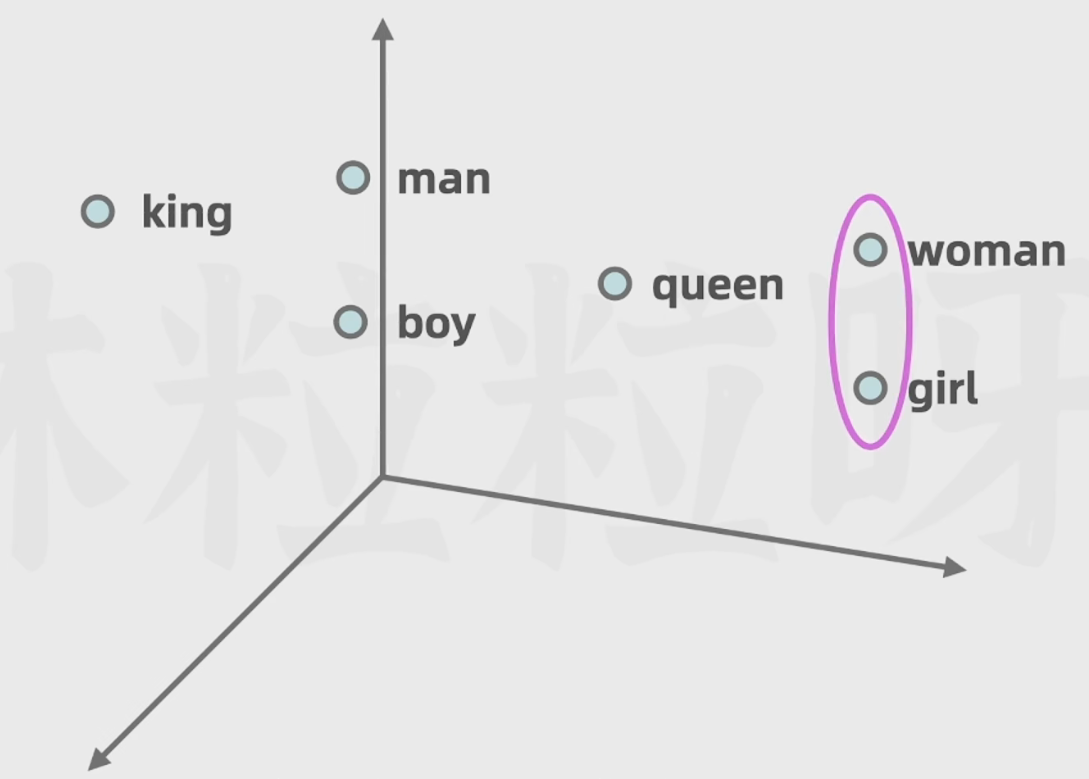
相似的词在向量空间中距离较近,不相似的词则在向量空间中距离较远。
进而便于模型计算向量空间中两个向量的距离进而得到相似度。
GPT3的向量长度高达12288.
4.3.3 位置编码:
将上文得到的词向量和位置向量(词在文本中出现的位置)经过一个线性层得到位置编码。
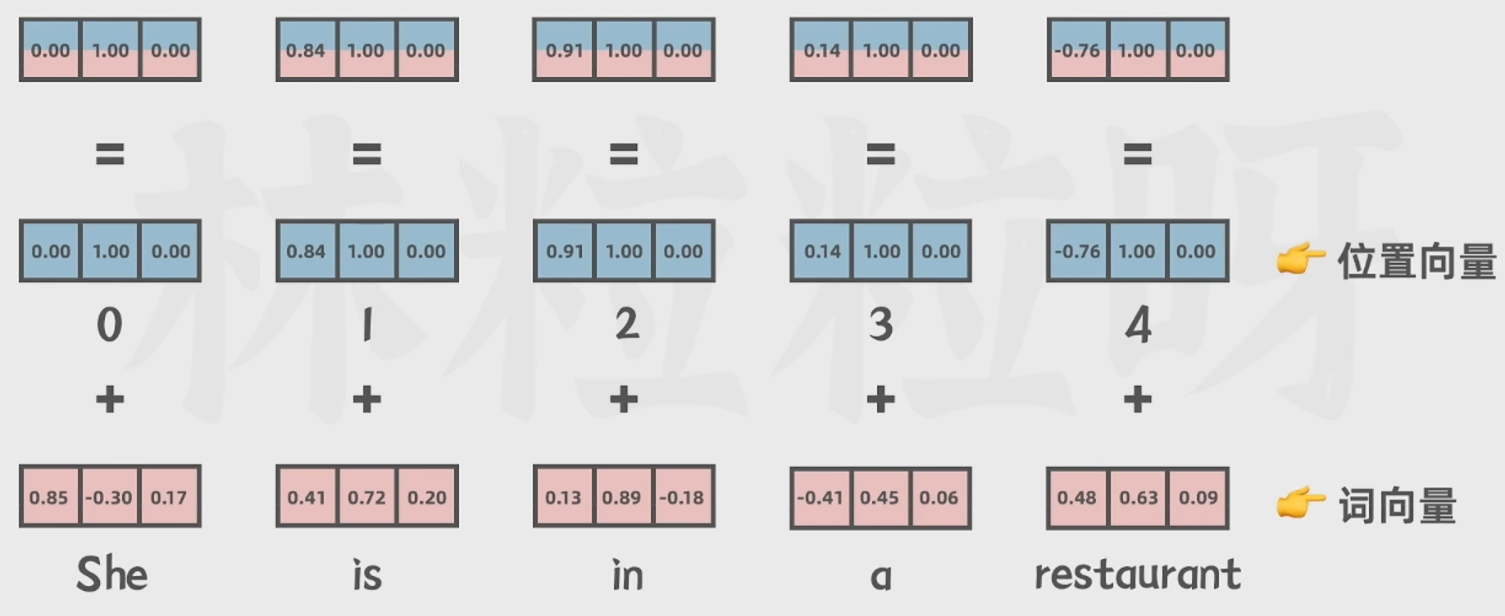
4.3.4 自注意力机制:
为了融合上下文之间的相关信息,引入自注意力机制,通过计算每对词之间的相关性来决定注意力权重。

Transformer实际使用的是多注意力头机制,每个头都有它自己的注意力权重,用来关注文本里不同特征或方面,比如有的关注动词,有的关注修饰词。
而且他们之间互不影响,可以做并行运算;
每个自注意力头的权重都是模型在之前的训练过程中,从大量文本中逐渐学习和调整的。
4.3.5 前馈神经网络:
对自注意力模块的输出做进一步处理,增强模型的表达能力。
4.3.6 注意:
编码器在transformer中可能不止一个,实际上是由多个堆叠在一起,每个编码器内部结构一样,但不共享权重,这保证了模型可以更深入理解数据,处理更复杂的文本语言内容。

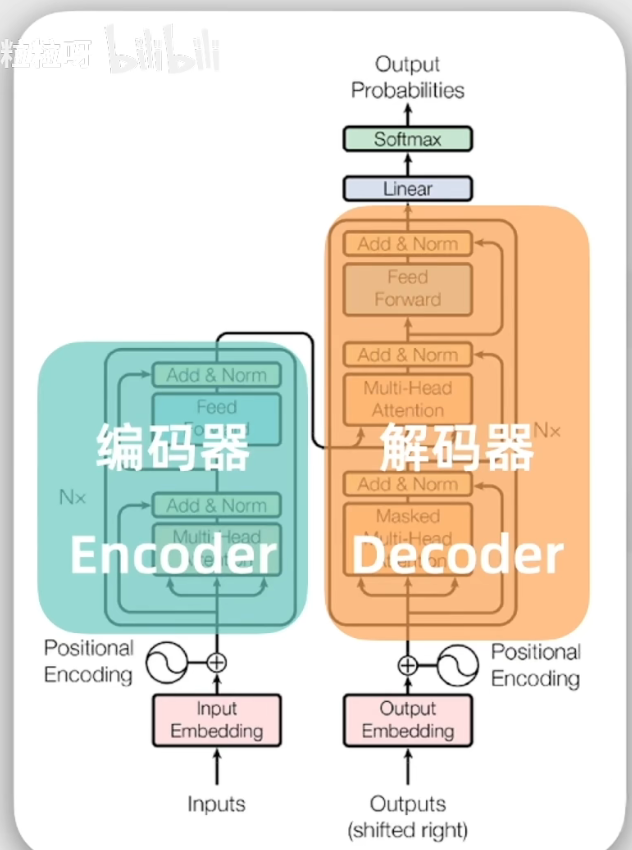
4.4 解码器工作流程:
通过前面的编码器我们有了输入序列中各个token序列的抽象表示。
4.4.1 接受一个特殊值(作为开头):
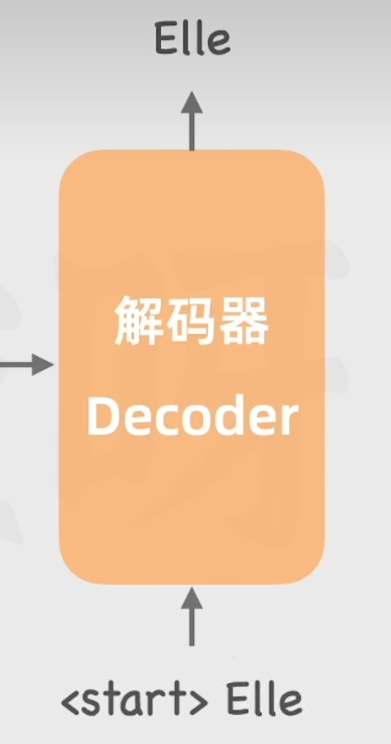
不仅会将来自编码器的抽象表示作为输入,还会把之前已经生成的文本也作为输入,进而保证连贯性。
4.4.2 也要经过嵌入层和位置编码,然后进入多头自注意力层
4.4.3 编码器和解码器多头自注意力层的区别:
解码器的多头自注意力层只关注前缀(只使用当前词以及前面的词作为上下文 ),称为带掩码的多头自注意力层:

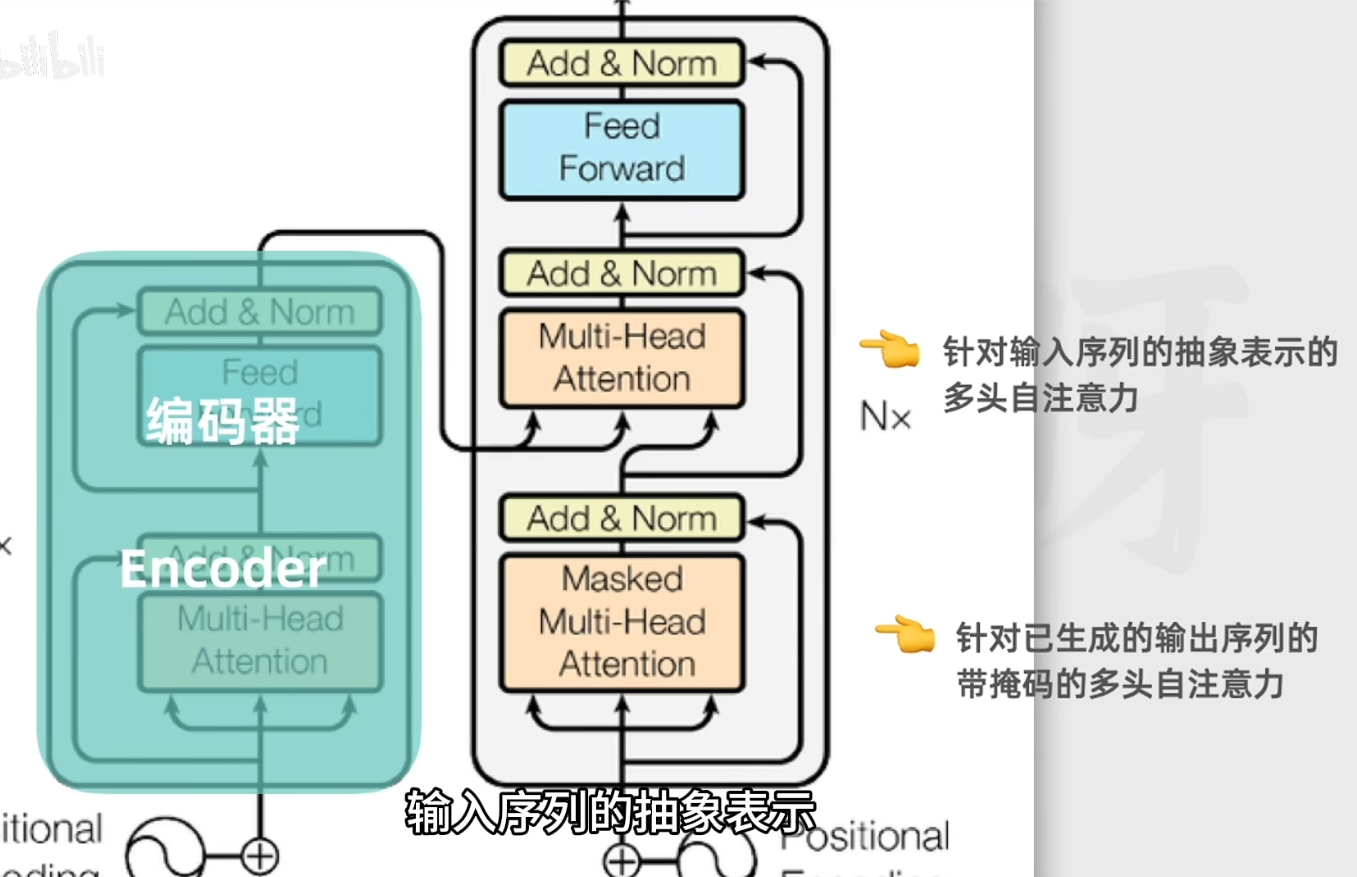
内部有两个多头自注意力层数,其中一个是针对(输出序列),还有一个是针对输入序列(来自编码器的输出)。
4.4.4 注意:
解码器中也有多层堆叠:

4.4.5 线性层和softmax层:
解码器的最后阶段是该两层,作用是把解码器输出的表示转换为词汇表的概率分布(也即下一个生成Token的概率)
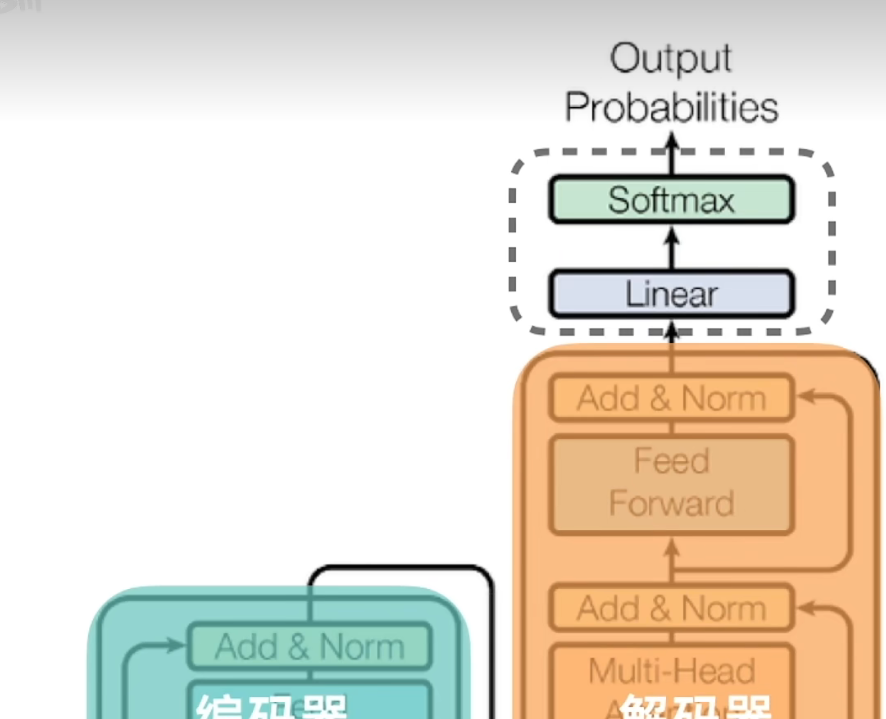
 至于输出是否符合客观事实,模型不得而知,它只是输出其当前计算得到的最大概率的一个Token。
至于输出是否符合客观事实,模型不得而知,它只是输出其当前计算得到的最大概率的一个Token。
模型一本正经的胡说八道(比如讲述“林黛玉倒拔垂杨柳”)被称之为“幻觉”现象。

解码器的整个流程会持续多次,直到生成的是一个用来表示序列结束的特殊token。
4.5 三个变种:
4.5.1 仅编码器:
适用于理解语言任务

4.5.2仅解码器(自回归模型):
非常擅长预测下一个词

4.5.3 编码器和解码器(序列到序列):
适用于将一个序列转换为另一个序列的任务

5 GPT的构建历程:
5.1 第一步:通过大量文本进行无监督预训练得到基座模型(花费多)
利用海量文本自行学习人类语言的语义和语法,了解表达结构和模式
预测过程中不断更新权重,从而逐渐能根据上文生成合适的下文


该模型可以进行文本生成(根据上文补充文本)
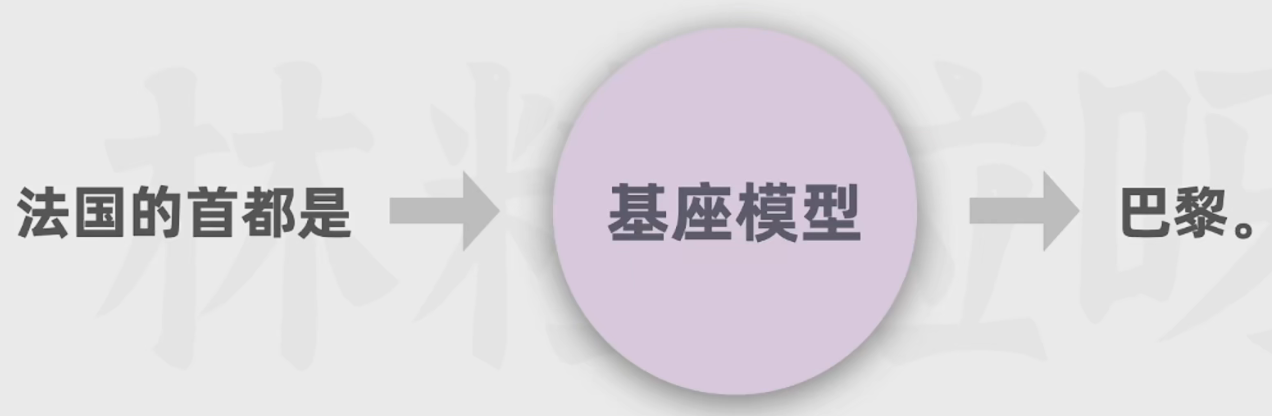
给它一个问题可以帮你生成更多类似的问题:

5.2 第二步:通过人类撰写的高质量对话数据对基座模型进行监督微调得到微调后的基座模型(SFT)
该模型可以进行文本生成和对话能力
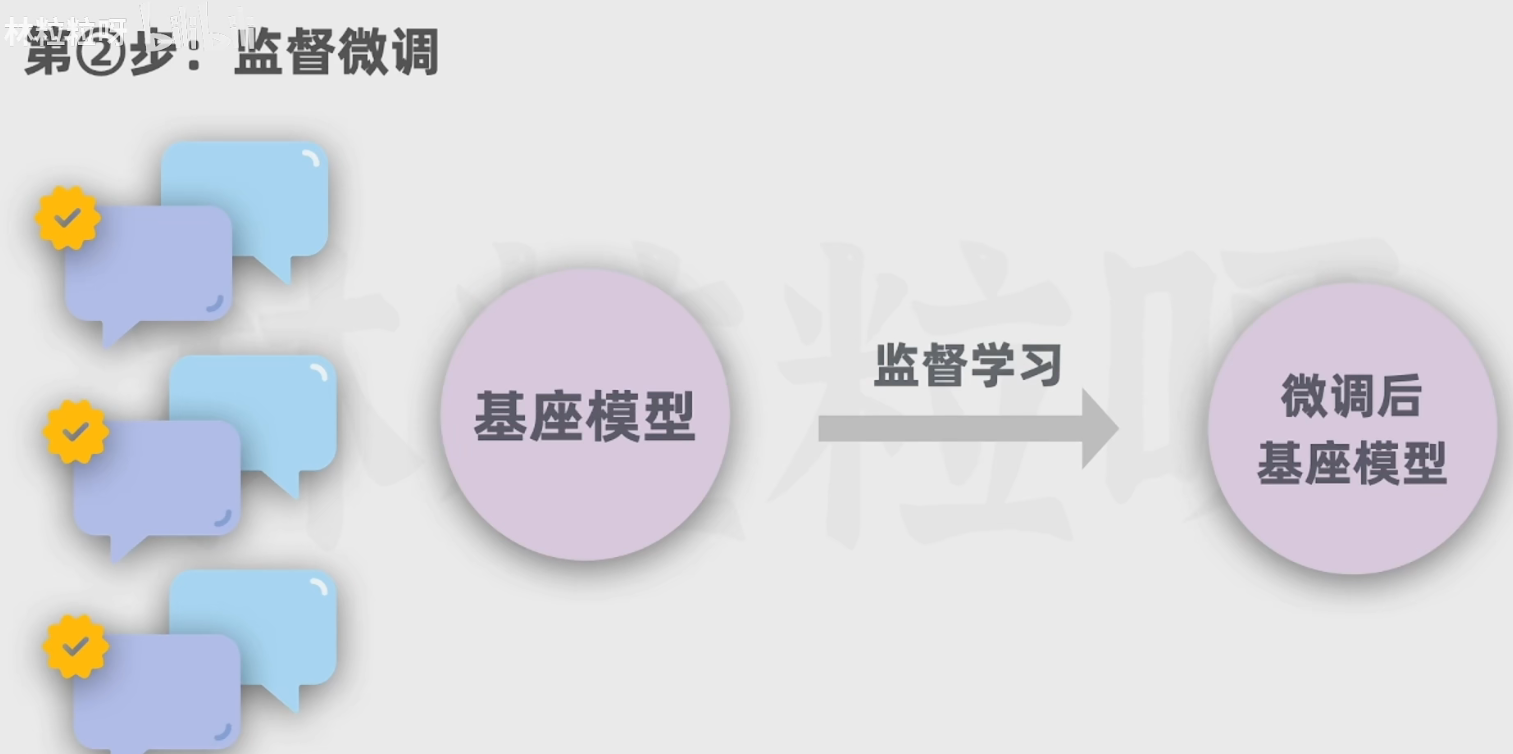
已经可以进行对话了,但是质量并不高:

5.3 第三步:由人类标注员对多个回答的数据进行排序打分,基于该数据训练一个能对回答进行评分预测的奖励模型
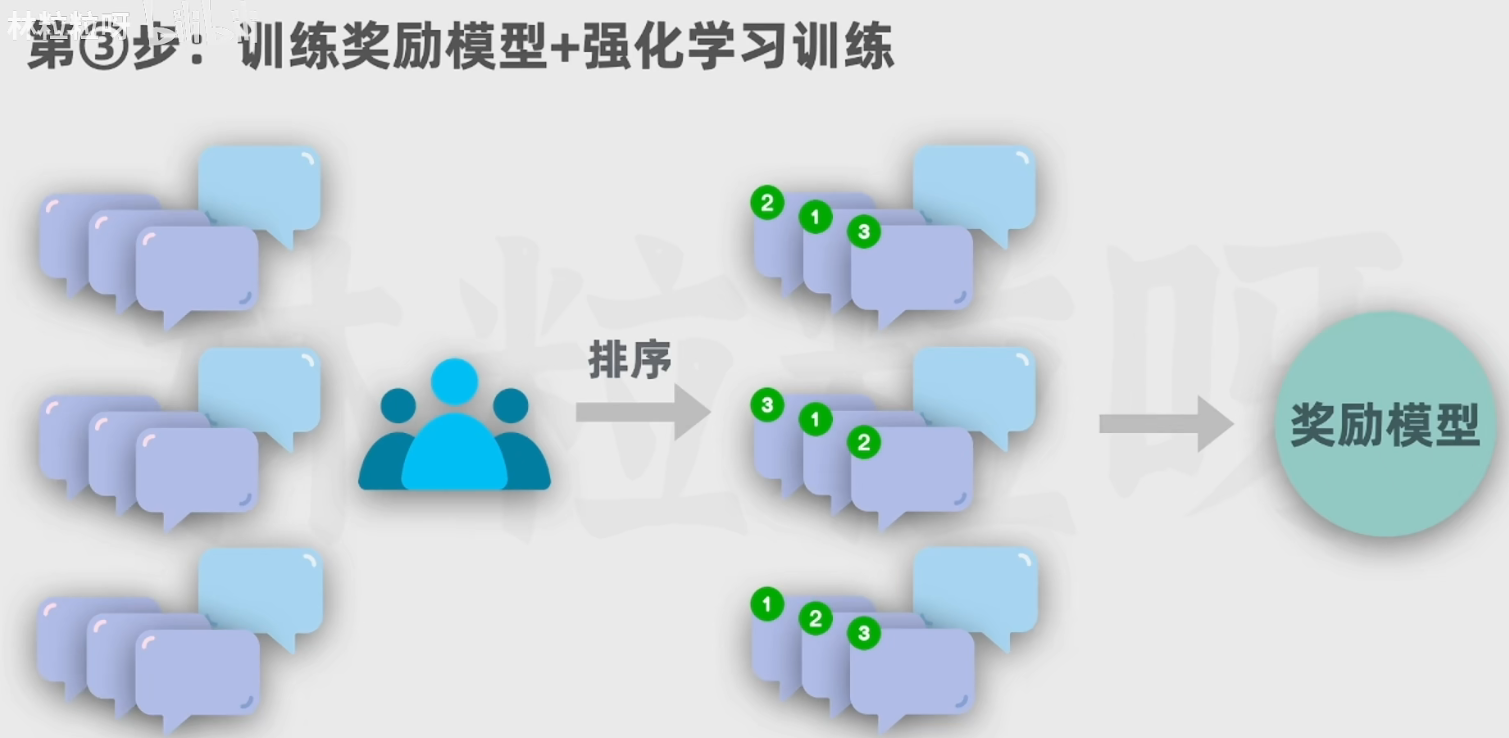
让chatGPT对问题做出回答,人类标注员回答进行打分(3H原则)


让第二步得到的SFT模型对问题生成多个回答,人类标注员对回答进行排序,得到排序数据,进而用于训练奖励模型

从回答和回答对应的评分中学习,得到奖励模型

5.4 第四步:训练奖励模型+强化学习训练

GPT的参数会随着训练被更新,但是奖励模型的参数却不再会变化了。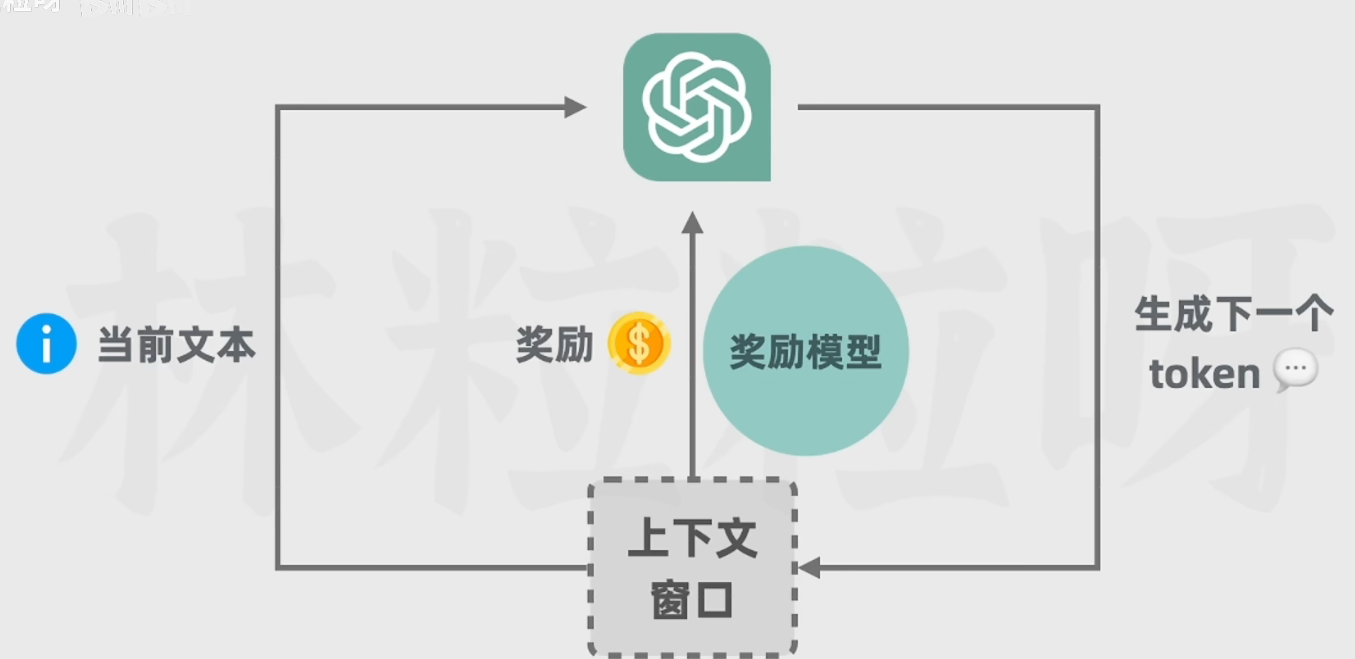
6 改进GPT的思路:
6.1 小样本提示:
给示例。

优点:AI回应的内容风格会大概率遵循我们给的提示(JSON格式)。
缺点:不适合用于需要数学计算等推理思维能力的问题
6.2 思维链:
给出的示例中不仅给出结果,更要给出推理得到结果的过程

优点:非常适合解决推理计算等问题
6.3 分步骤思考(let's think step by step)

7 GPT目前存在的短板及解决措施:
7.1 GPT目前存在的短板:
数据过时,编造事实,计算不准
7.2 检索增强生成RAG:
问题背景:如果训练数据里对某个领域的文本覆盖不多,那么我们在提问相关领域的问题时,AI可能会生成不准确或者错误的回答。
因此,我们可以提供外部文档,然后将这些文档分为几个段落(因为LLM一次接受的文本序列有限),然后转换为向量,存进向量数据库。

当我们提出问题的时候,这个问题也会转化为向量,然后进入向量数据库中查找与该向量最为接近的段落向量。
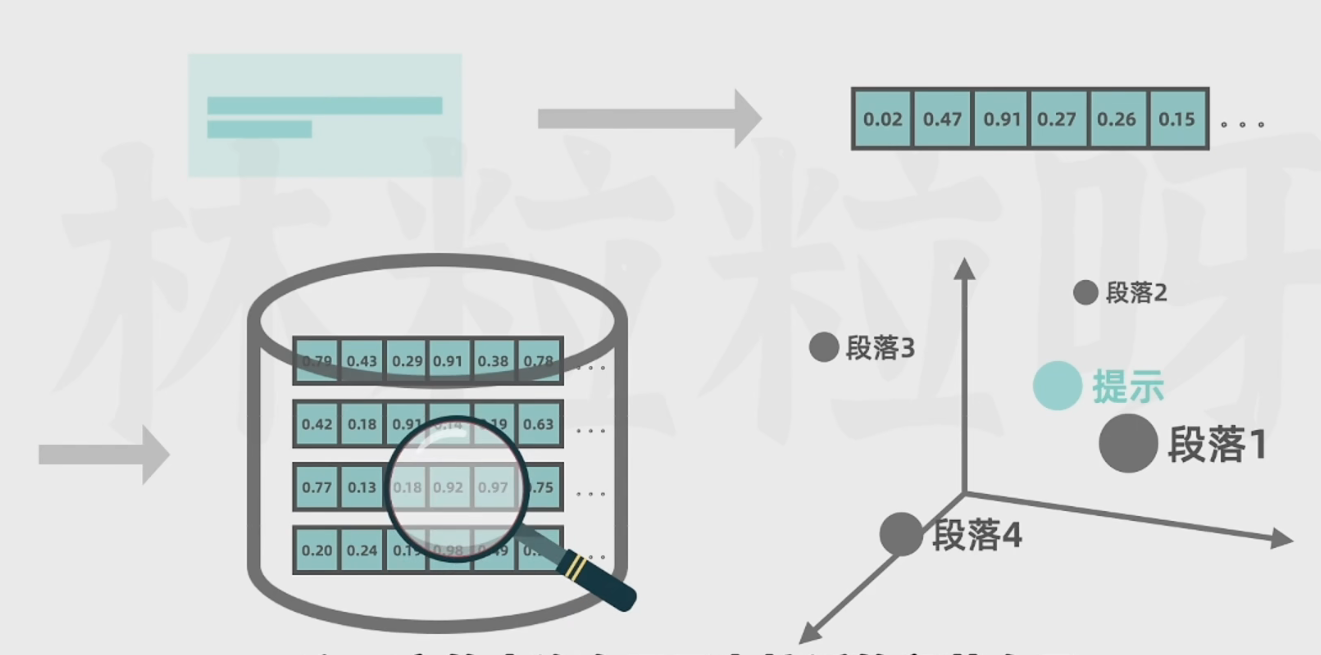 找到以后,段落信息和原本的问题查询向量组合在一起,一块传给AI,然后AI会把查询向量作为上下文,基于里面的信息给出更严谨的回答。
找到以后,段落信息和原本的问题查询向量组合在一起,一块传给AI,然后AI会把查询向量作为上下文,基于里面的信息给出更严谨的回答。
整体的流程如下图所示:

想要了解更多可以参考下面这个博客:
RAG (检索增强生成)技术详解:揭秘基于垂直领域专有数据的Chatbots是如何实现的 - 知乎 (zhihu.com)
7.3 程序辅助语言模型(PAL)
问题背景:针对AI不善于做计算的问题
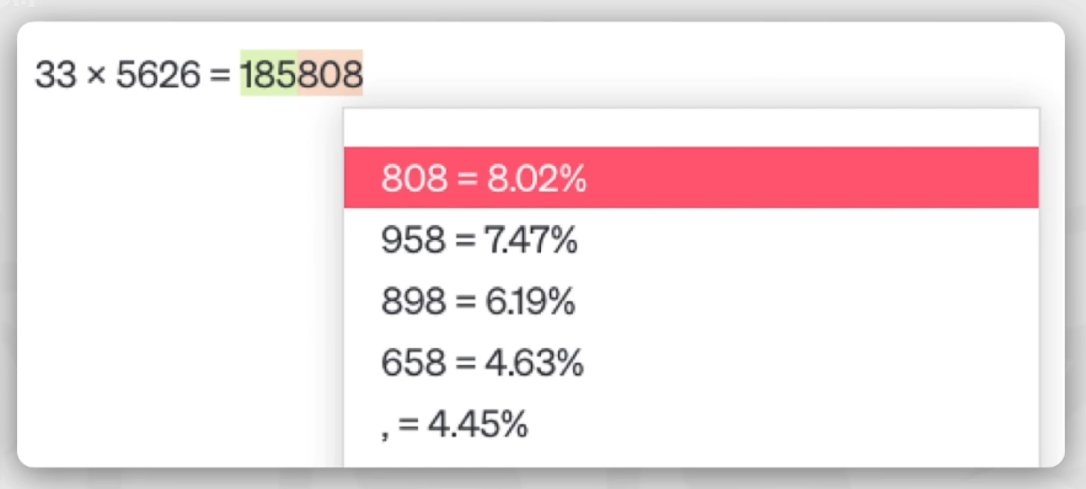
在思维链的基础上,让AI写出python代码,然后提交给python解释器(等计算工具),然后将计算结果返回给AI。(现在也有一种讨论是“用变量表示,然后用数学公式求解器”计算,这样子及绝了按序计算(一行一行的python代码执行)可能造成的错误。

7.4 协同推理与行动ReAct:
问题背景:数据过时问题,知识截断,重新训练模型开销巨大

上网+分布推理的思维链:(如web browing)功能

注意:行动不一定指的是输入关键词进行搜索、点击链接等等;
- 如果可以和python等代码解释器进行交互,那么运行代码也可以作为可选项;
- 如果模型可以访问外部文档,那么从文档中获取关键字也可以作为行动选项;
- 如果模型可以调用某个应用的API,那么和那个应用交互也可以作为行动选项。
可以使用LangChain实现此目的:
什么是LangChain呢?
答:LangChain是一个开源框架,允许从事人工智能的开发者将例如GPT-4的大语言模型与外部计算和数据来源结合起来。该框架目前以Python或JavaScript包的形式提供。
假设,你想从你自己的数据、文件中具体了解一些情况(可以是一本书、一个pdf文件、一个包含专有信息的数据库)。LangChain可以将GPT-4和这些外部数据连接起来,甚至可以让LangChain帮助你采取你想采取的行动,例如发一封邮件。
想要对LangChain了解更多可以参考下面这个博客:


