- 1HW红蓝队基本知识_hw招募红方蓝方是什么意思
- 2【微服务】- Nacos - 注册中心_nacos监控注册服务
- 3GESP C++ 2023年12月一级真题卷_c++表达式010+100+001的值为111
- 4VMware workstation12的安装及配置_vmware v12虚拟机配置要求
- 5多线程与并发 - Thread和Runnable是什么关系_java中thread和runnable的关系
- 6anaconda环境设置:设置环境默认位置为D盘_anaconda虚拟环境设为默认d盘
- 7嵌入式开发其实最需要好的软件架构
- 8又整新活,新版 IntelliJ IDEA 有点东西!_idea 集成ai
- 9学习ASM技术(四)--条带化原理和rebalance
- 10html改为php报错,php,_使用 MPDF 将HTML转为PDF,然后将该PDF转为PNG图片的时候,中文报错... ...,php - phpStudy...
Hadoop系列-HDFS HA高可用集群_hadoop集群高可用测试
赞
踩
前言:
在HDFS集群的时候我们知道,NameNode只有一个,如果现在NameNode挂掉了,或者NameNode需要硬件或者软件的升级,那么势必就有单点问题。那么HDFS HA就是来解决这个问题的。
HA架构图:
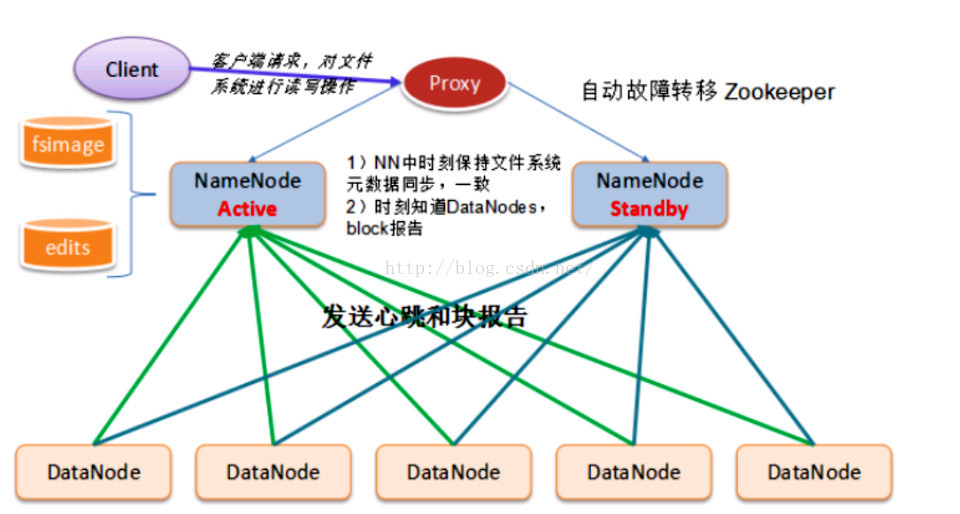
集群需要考虑的问题:
1 我们要考虑两个NM之间的元数据是共享或者同步的
NM启动的时候,会去读取fsimage和 edits文件,那么备份NM也需要读取这两个文件
而且随着ActiveNM会记录元数据的变化,那么StandbyNM也需要随时同步元数据的变化
2 必须保证日志文件的安全
方案讨论:
解决方案【一】
在以前我们可能找一些质量比较好的机器,存储相关的数据或者文件
然后ActiveNM 负责写,然后StandbyNM负责读,也能实现同步,但是成本太高
解决方案【二】
Cloudera公司提出分布式存储日志文件,日志备份数目(2n+1)
解决方案【三】
使用Zookeeper+Journalnode
另外我们不在需要SecondaryNM,因为启用SecondaryNM的目的是合并NameNode的fsimage和 edits文件,以便节省下一次NM启动的时候减少启动时间
现在有了StandbyNM 它和ActiveNM是实时同步的,所以就不需要SecondaryNM
一 搭建HA集群
搭建HadoopHA集群,可能有很多种方法,我们这里采用官方文档所提供的使用QJM (QuorumJournal Manager)仲裁日志管理的方式。
1.1 首先检查hadoop-env.shmapred-env.sh,yarn-env.sh的JAVA_HOME路径是否设置好
1.2 修改core-site.xml文件

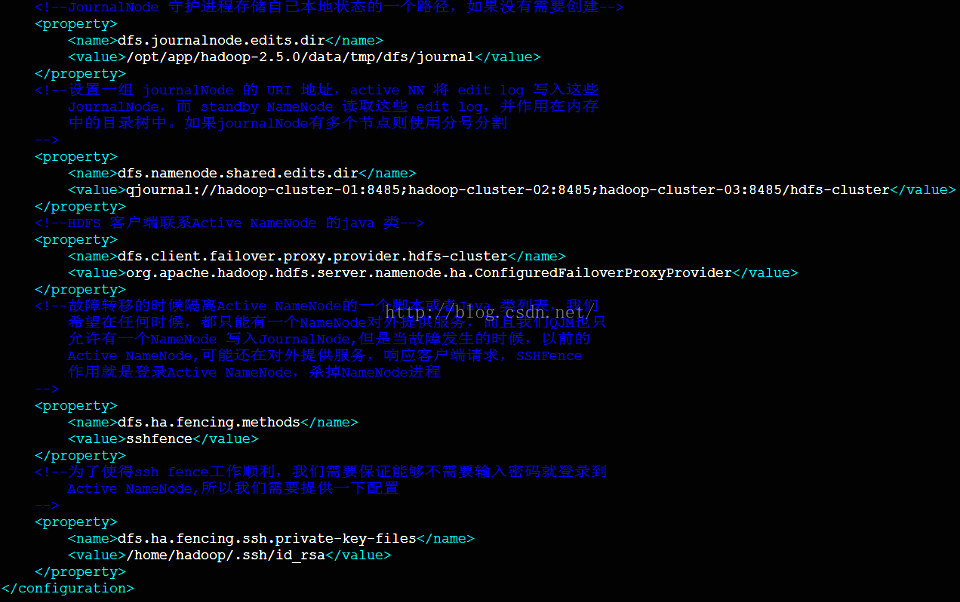
1.3 修改hdfs-site.xml
首先因为不需要SecondaryNM,所以相关的配置需要去掉。

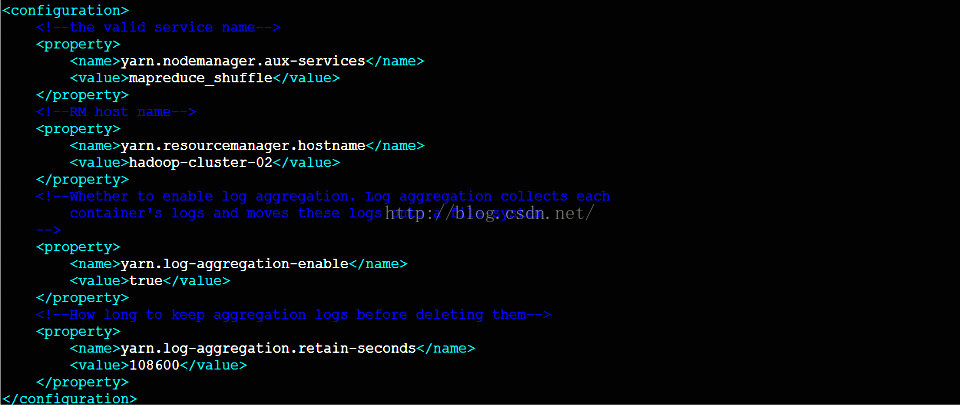
1.4 配置yarn-site.xml
1.5 配置mapred-site.xml
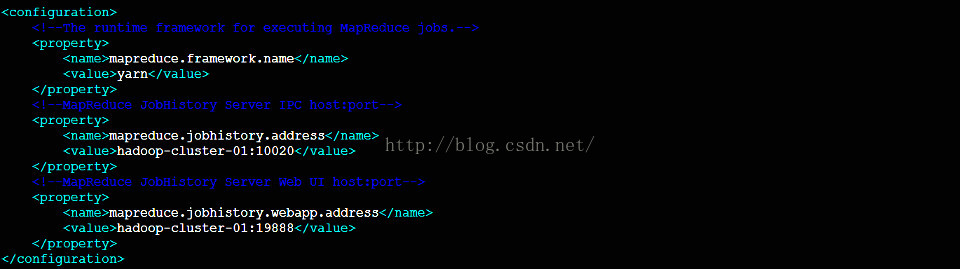
1.6 分发配置到各个节点
创建目录:
/opt/app/hadoop-2.5.0/data/tmp/dfs/journal
mkdir -p /opt/app/hadoop-2.5.0/data/tmp/dfs/journal
scp -r hadoop-2.5.0/ hadoop@hadoop-cluster-03:/opt/app
scp -r hadoop-2.5.0/ hadoop@hadoop-cluster-03:/opt/app
1.7 启动各个节点的Journal Node
/opt/app/hadoop-2.5.0/sbin/hadoop-daemon.sh start journalnode
如果启动成功应该有一个JournalNodejava进程
1.8 然后格式化Active NameNode,并启动NameNode
我们规划hadoop-cluster-01为ActiveNameNode;然后http://hadoop-cluster-02为StandbyNameNode
/opt/app/hadoop-2.5.0/bin/hdfsnamenode -format
另外一台机器不需要格式化,因为他们管理的是同一份元数据。如果元数据都不相同,那么主备也就没什么意思呢。
启动ActiveNameNode:
/opt/app/hadoop-2.5.0/sbin/hadoop-daemon.sh start namenode
1.9 在Standby NameNode同步元数据,并启动StandbyNM
/opt/app/hadoop-2.5.0/bin/hdfs namenode -bootstrapStandby
启动StandbyNameNode:
/opt/app/hadoop-2.5.0/sbin/hadoop-daemon.sh start namenode
1.10 然后启动2台namenode和 各个节点的datanode
这时候当我们访问:
http://hadoop-cluster-01:50070/ 和http://hadoop-cluster-02:50070/
都还是standby状态,因为这时候都是待机状态,所以需要我们指定ActiveNameNode切换Active状态
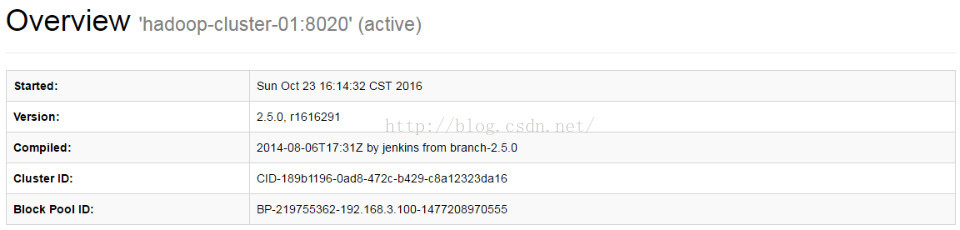
/opt/app/hadoop-2.5.0/bin/hdfs haadmin -transitionToActive
namenode100
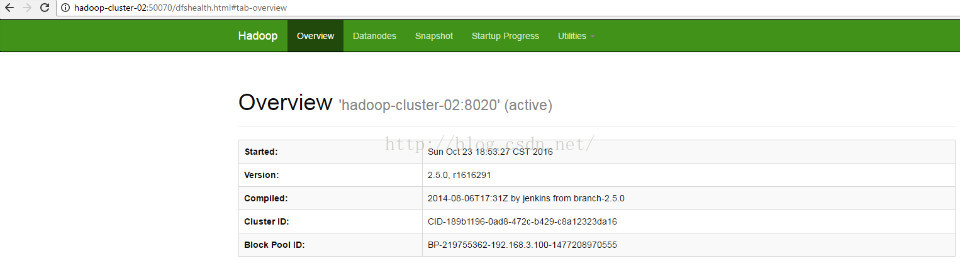
这时候ActiveNameNode 状态就是Active了,如图示:
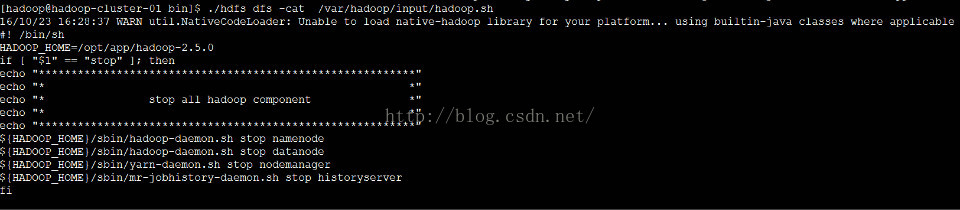
1.11 启动各个节点DN,看Active是否工作正常
./hdfs dfs -mkdir -p /var/hadoop/input
./hdfs dfs -put /opt/shell/hadoop.sh /var/hadoop/input
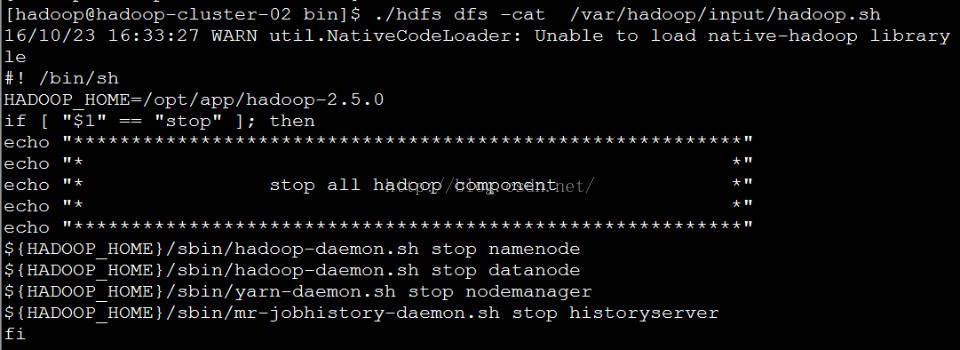
./hdfs dfs -cat /var/hadoop/input/hadoop.sh
1.12 然后测试两个NameNode是否是共享的
先杀掉ActiveNameNode进程
kill -9 10223
然后把Standby状态强制转换成Active
/opt/app/hadoop-2.5.0/bin/hdfs haadmin -transitionToActive
namenode101--forceactive
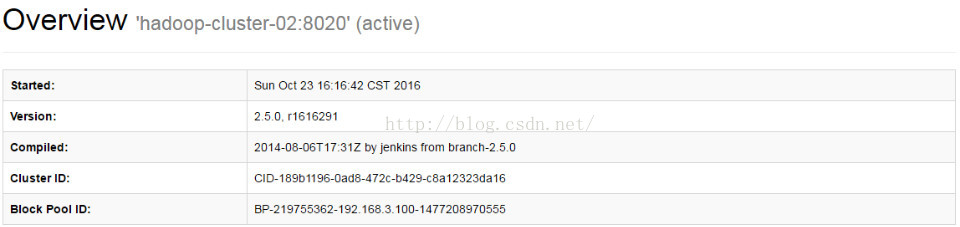
./hdfs dfs -cat /var/hadoop/input/hadoop.sh
二 自动故障转移
根据之前的配置,我们知道,如果ActiveNM挂了,那么Standby是需要我们手动切换才能转移状态,然后才对外提供服务的。
那如果是半夜宕机了,我们怎么办呢,所以我们需要一种自动故障转移的需求。
这时候需要使用到2个新的组件:
ZooKeeperquorum 和 ZKFailoverControllerprocess.
ZKFC是一个新的组件,它是一个ZooKeeper客户端,能够监视和管理NameNode的状态。每一台NameNode节点 都会运行一个ZKFC.负责:
HealthMonitoring: 健康监视,ZKFC会定期的用一个健康检查命令去ping本地的NameNode,只要NameNode即使做出响应,就被认为事实健康的。如果NameNode挂掉,假死或者其他原因造成不健康的状态,健康监视器它会标记为不健康状态
ZooKeepersession management: Zookeeper 会话管理。当本地NameNode是健康的,ZKFC在Zookeeper会持有一个session,如果ActiveNameNode是健康的,他会持有一个锁 znode,如果session到期,这个lockznode将会自动释放
ZooKeeper-basedelection:基于ZooKeeper的选举。如果本地NameNode是健康的,他会去查看是不是没有其他node在持有锁,他自己会去询问这个锁,如果成功,他将赢得选举。
2.1 配置core-site.xml
我们需要在core-site追加如下配置:
<!--指定运行zookeeper的节点信息,多个用逗号分割-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-cluster-01:2181,hadoop-cluster-02:2181,hadoop-cluster-03:2181
</value>
</property>
2.2 配置hdfs-site.xml
我们需要在hdfs-site.xml追加以下的配置:
<!--安装automiaticfailover-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2.3 初始化在ZooKeeper的状态
初始化会在Zookeeper生成一个hadoop-ha的znode.
/opt/app/hadoop-2.5.0/bin/hdfs zkfc -formatZK
只需要一台机器初始化就行。
在zookeeper查看是否创建集群成功
/opt/app/zookeeper-3.4.6/bin/zkCli.sh
然后ls / 如果成功会看到/hadoop-ha节点
2.4停止所有hdfs进程然后重启
/opt/app/hadoop-2.5.0/sbin/stop-dfs.sh
/opt/app/hadoop-2.5.0/sbin/start-dfs.sh
这时候你会发现每一个namenode都起了一个这样的进程:
DFSZKFailoverController
如果你没发现有这样的进程启动,你也是可以手动启动的:
/opt/app/hadoop-2.5.0/sbin/hadoop-daemon.sh start zkfc
2.5 测试自动故障转移
杀掉ActiveNameNode 进程
kill-9 11708
现在查看StandbyNameNode: