
- 1163Python数据分析师课程考核项目06_data= data.loc[data['建筑面积']<400]
- 2NVIDIA Jetson之tensorflow环境部署(最简单)_nvidia-tensorflow
- 3python大作业有哪些题目,python大作业代码及文档
- 4反射XSS和CORS漏洞的组合拳引发的血案_cors+xss漏洞
- 5总结linux查看当前用户的方法_ubuntu查看所有用户
- 6pixel 3xl 手机如何烧录自己编译的android 12代码_android 编译烧录
- 7ArkTs基础语法一_arkts方法怎么写
- 8Python3学习笔记_app自动化测试_通用操作_20200811_no 'uiautomator' process has been found
- 94年Java开发,阿里被裁两个月,想要26K的工作都找不到!投200份简历,只有4个面试邀请,准备去外包了!...
- 10Linux系统安装,教你安装一个属于自己的Linux系统_linux安装
大模型微调代码解析,哪些方法可以加速训练?_gradient_accumulation_steps
赞
踩
近期大模型层出不穷,大家对于大模型的微调也在跃跃欲试,像Lijia的BELLE,斯坦福的Alpaca[1], 清华的ChatGLM[2],中文的Chinese-Vicuna[3],让我这样的普通玩家也能训练自己的微调模型。
在微调和推理的时候仍然需要加速,有哪些方法可以加速微调呢?
Part1LoRA
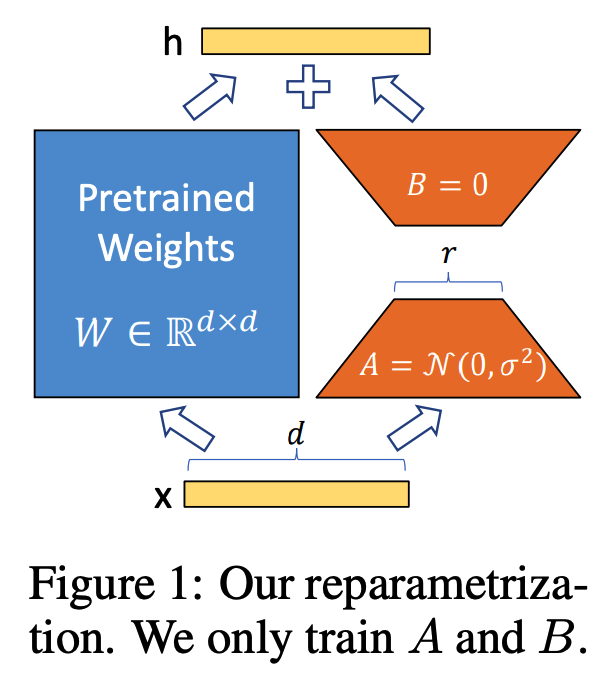
低秩矩阵分解 LoRA[4]原理:冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。LoRA 开源代码[5]见文末。
原理图:
公式:
结合原理图和公式,我们可以很容易明白LoRA了:
左侧是预训练模型的权重,输入输出维度都是d,在训练期间被冻结,不接受梯度更新。
右侧,对A使用随机的高斯初始化,B在训练开始时为零,r是秩,会对△Wx做缩放 α/r。
HuggingFace的包peft[6]对LoRA做了封装支持,几步即可使用:
- from peft import get_peft_model, LoraConfig, TaskType
-
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM,
- inference_mode=False,
- r=8,
- lora_alpha=32,
- lora_dropout=0.1,
- target_modules=['query_key_value']
- )
-
- model = "加载的模型"
- model = get_peft_model(model, peft_config)
- # 打印参数情况
- model.print_trainable_parameters()
- 接下来和正常训练模型一样

论文中提到了LoRA的诸多优点:

Part2Accelerate 和 deepspeed
Accelerate[7]库提供了简单的 API,使我们可以在任何类型的单节点或分布式节点(单CPU、单GPU、多GPU 和 TPU)上运行,也可以在有或没有混合精度(fp16)的情况下运行。
这里是我用Accelerator和DeepSpeedPlugin做个示例:
需要提前知道梯度累积步骤 gradient_accumulation_steps 和 梯度累积计算
- from accelerate import Accelerator, DeepSpeedPlugin
- import tqdm
-
- model = ...
-
- deepspeed_plugin = DeepSpeedPlugin(
- zero_stage=2,
- gradient_accumulation_steps=2)
-
- accelerator = Accelerator(
- mixed_precision='fp16',
- gradient_accumulation_steps=2,
- deepspeed_plugin=deepspeed_plugin)
-
- device = accelerator.device
- ... ...
- optimizer = ...
- lr_scheduler = ...
-
- model, optimizer, train_dataloader = accelerator.prepare(model, optimizer, train_dataloader)
-
- for epoch in range(epochs):
- total_loss = 0
- for step, batch in enumerate(t:=tqdm.tqdm(train_dataloader)):
- with accelerator.accumulate(model):
- outputs = model(**batch)
- loss_detach = outputs.loss.detach().cpu().float()
- t.set_description(f"loss: {loss_detach}")
- total_loss += loss_detach
- loss = outputs.loss
- # 不再是 loss.backward()
- accelerator.backward(loss)
- optimizer.step()
- lr_scheduler.step()
- optimizer.zero_grad()
- # 每个epoch 保存
- accelerator.wait_for_everyone()
- if accelerator.is_main_process:
- accelerator.save(model.state_dict(accelerator.unwrap_model(model), '/saved/model.pt')
-
- # 其他参考保存方法
- accelerator.wait_for_everyone()
- unwrapped_model = accelerator.unwrap_model(model)
- unwrapped_model.save_pretrained(save_dir,
- save_function=accelerator.save,
- state_dict=accelerator.get_state_dict(model))
-
Part3Autocast 自动混合精度
autocast是在GPU上训练时一种用于降低显存消耗的技术。原理是用更短的总位数来保存浮点数,能够有效将显存消耗降低,从而设置更大的batch来加速训练。但会造成精度的损失,导致收敛效果也会变差。
PyTorch的AMP有2种精度是torch.FloatTensor和torch.HalfTensor。
使用方法:
- from torch.cuda.amp import autocast as autocast, GradScaler
-
- dataloader = ...
- model = model.cuda()
- optimizer = ...
- scheduler = ...
- # scaler的大小在每次迭代中动态估计,为了尽可能减少梯度,scaler应该更大;
- # 但太大,半精度浮点型又容易 变成inf或NaN.
- # 动态估计原理就是在不出现if或NaN梯度的情况下,尽可能的增大scaler值。
- scaler = GradScaler()
-
- for epoch in range(epochs):
- for batch_idx, (data, targets) in enumerate(train_dataloader):
- optimizer.zero_grad()
- data = data.cuda(0)
- with autocast(dtype=torch.bfloat16): # 自动混精度
- logits = model(data)
- loss = loss(logits, targets)
- # 反向传播梯度放大
- scaler.scale(loss).backward()
- # 首先 把梯度值unscale回来, 优化器中的值也需要放缩
- # 如果梯度值不是inf或NaN, 则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。
- scaler.step(optimizer)
- # 看是否要增大scaler, 更新scaler
- scaler.update()
Part4单机多GPU、多机多卡
如果条件允许的话,可以使用单机多卡和多机多卡分布式训练。
那么:
-
模型怎么同步参数与梯度?
-
数据怎么划分到多个GPU中?
pytorch框架给我们封装了对应的接口函数:
- import torch.distributed as dist
- from torch.utils.data.distributed import DistributedSampler
- from torch.nn.parallel import DistributedDataParallel
PyTorch提供的torchrun命令以及一些API封装了多进程的实现。 我们只要在普通【单进程程序前后】加入: 开头 setup()和 结尾 cleanup()
- def setup(rank, world_size):
- os.environ['MASTER_ADDR'] = 'localhost' # ip
- os.environ['MASTER_PORT'] = '8848'
- dist.init_process_group("nccl", rank=rank, world_size=world_size)
-
- def cleanup():
- dist.destroy_process_group()
就能用多个进程来运行训练程序,每个进程分配一个GPU,我们可以用dist.get_rank()来查看当前进程的GPU号的。
- setup()
-
- rank = dist.get_rank()
- print(f'Current rank {rank}')
- pid = os.getpid()
- print(f'current pid: {pid}')
- device_id = rank % torch.cuda.device_count()
1数据并行:
只要在生成Dataloader时,把DistributedSampler的实例传入sampler参数就行了,DistributedSampler会自动对数据采样,并放到不同的进程中。这里需要注意的是:sampler自动完成了打乱数据集的作用,所以在定义DataLoader时,不用再开启shuffle选项
- dataset = MyDataset()
- sampler = DistributedSampler(dataset)
- dataloader = DataLoader(dataset, batch_size=2, sampler=sampler)
2模型并行
在并行训练时,各个进程并行,每个模型使用同一份模型参数 weights。在梯度下降时,各个进程会同步一次,致使每个进程的模型都更新相同的梯度。
做法也很简单,只需要把Model套一层DistributedDataParallel,就可以实现backward的自动同步梯,其他的操作都照旧,把新模型ddp_model当成旧模型model调用就行。
- model = MyModel().to(device_id)
- ddp_model = DistributedDataParallel(model, device_ids=[device_id])
- optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
训练流程照常:
在每个新epoch中,要用sampler.set_epoch(epoch)更新sampler打乱数据集。训练流程和普通深度学习训练流程一样。
- # 这里根据自己的数据格式修改一下
- for epoch in range(2):
- sampler.set_epoch(epoch)
- for data in dataloader:
- print(f'epoch {epoch}, rank {rank} data: {data}')
- data = data.to(device_id)
- y = ddp_model(data)
- optimizer.zero_grad()
- loss = loss_fn(data, y)
- loss.backward()
- optimizer.step()
3模型保存和读取:
在保存的时候,我们只需要保存一个进程下的模型即可,另外使用barrier()确保进程1在进程0保存模型之后加载模型。
存储参数时会保存设备信息。由于刚刚只保存了0号GPU进程的模型,所有参数的device都是cuda:0。而读取模型时,每个设备上都要去加载这个模型,device要做一个调整。
- # 保存模型。
- # 由于每个进程的模型都是一样的,我们只需要保存一个进程下的模型即可。
- if rank == 0:
- torch.save(ddp_model.state_dict(), ckpt_path)
- dist.barrier()
-
- cleanup()
-
- map_location = {'cuda:0': f'cuda:{device_id}'}
- state_dict = torch.load(ckpt_path, map_location=map_location)
- print(f'rank {rank}: {state_dict}')
- ddp_model.load_state_dict(state_dict)
使用DistributedDataParallel把model封装成ddp_model后,模型的参数名称里多了一个module,这是因为原来的模型model被保存到了ddp_model.module这个成员变量中(model == ddp_model.module)。
在混用单GPU和多GPU的训练代码时,要注意这个参数名不兼容的问题,包括上面我们使用LoRA加载模型的时候,也会出现模型层名称变换了的情况。最好的做法是每次存取ddp_model.module,这样单GPU和多GPU的checkpoint可以轻松兼容。
END
大模型快速微调和训练是我们做自然语言处理必备技能之一,尤其现在大语言模型及其微调模型不断涌现,只有掌握了这些技能才能跟上AI的浪潮。

