
热门标签
热门文章
- 1android NDK——搭建Android Studio的NDK环境_both android.ndkpath and ndk.dir in local.properti
- 2Rabbitmq在java中的使用_java使用rabbitmq
- 3SpringBoot连接Redis报错:org.springframework.data.redis.RedisSystemException: Error in execution
- 42023年6月GESP能力等级认证C++四级真题_gesp4级真题
- 5Python自动化机器学习(AutoML)快速实现,只需要PyCaret 2.0、AutoGluon两个包_london_merged
- 6第十三届蓝桥杯B组C++(试题B:顺子日期)_蓝桥杯顺子日期
- 7element el-table实现可进行横向拖拽滚动_eltable横向拖拽滚动
- 8从模型到部署,教你如何用Python构建机器学习API服务
- 9计算机网络——网络层_源和目的端之间所有可能的传输路径是什么
- 10七大OSINT操作系统(开源网络情报)
当前位置: article > 正文
Transformer位置编码代码讲解_transformer时间戳编码
作者:Cpp五条 | 2024-04-06 10:45:50
赞
踩
transformer时间戳编码
在看trm源码的时候关于transformer position encoding的部分不能理解,记录一下以免以后要用到。(比较浅显,基本根据论文公式反推的)
- # For positional encoding
- num_timescales = self.hidden_size // 2##一半余弦,一半正弦
- max_timescale = 10000.0
- min_timescale = 1.0##max_timescale min_timescale是时间尺度的上下界
- ##以上:计算时间尺度
-
- log_timescale_increment = (
- math.log(float(max_timescale) / float(min_timescale)) /
- max(num_timescales - 1, 1))##感觉是(max_timescale-min_timescale)取对数。
- ##在对数空间中相邻时间尺度之间的增量
- ##计算时间尺度的增量
-
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float32) *
- -log_timescale_increment)
- ##计算时间尺度的值 ##inv_timescales是时间尺度的倒数
-
- self.register_buffer('inv_timescales', inv_timescales)
-
- def get_position_encoding(self, x):
- max_length = x.size()[1]
- position = torch.arange(max_length, dtype=torch.float32,
- device=x.device)
- ##position=[0.,1.,2.,……,max_length-1.]
- scaled_time = position.unsqueeze(1) * self.inv_timescales.unsqueeze(0)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)],
- dim=1)
- signal = F.pad(signal, (0, 0, 0, self.hidden_size % 2))
- signal = signal.view(1, max_length, self.hidden_size)
- return signal

首先看下面这张图,便于我们直观地理解pe的构成:

可以自己输出一下代码,发现torch.sin(scaled_time), torch.cos(scaled_time)的维度都是N*D/2(N是序列的最长长度,D是hidden_size),所以signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)],dim=1)后维度就是N*D,也就是对每个pos的token的每一个隐藏层维度都进行一个位置编码(其实位置编码要和词嵌入向量做加法来加入位置信息,我们知道词嵌入向量的维度是B*N*D,那么位置编码1*N*D才能做加法)
然后,我不太理解为什么下面这段代码要取个指数函数。
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float32) *
- -log_timescale_increment)
其实有下面这段推导:
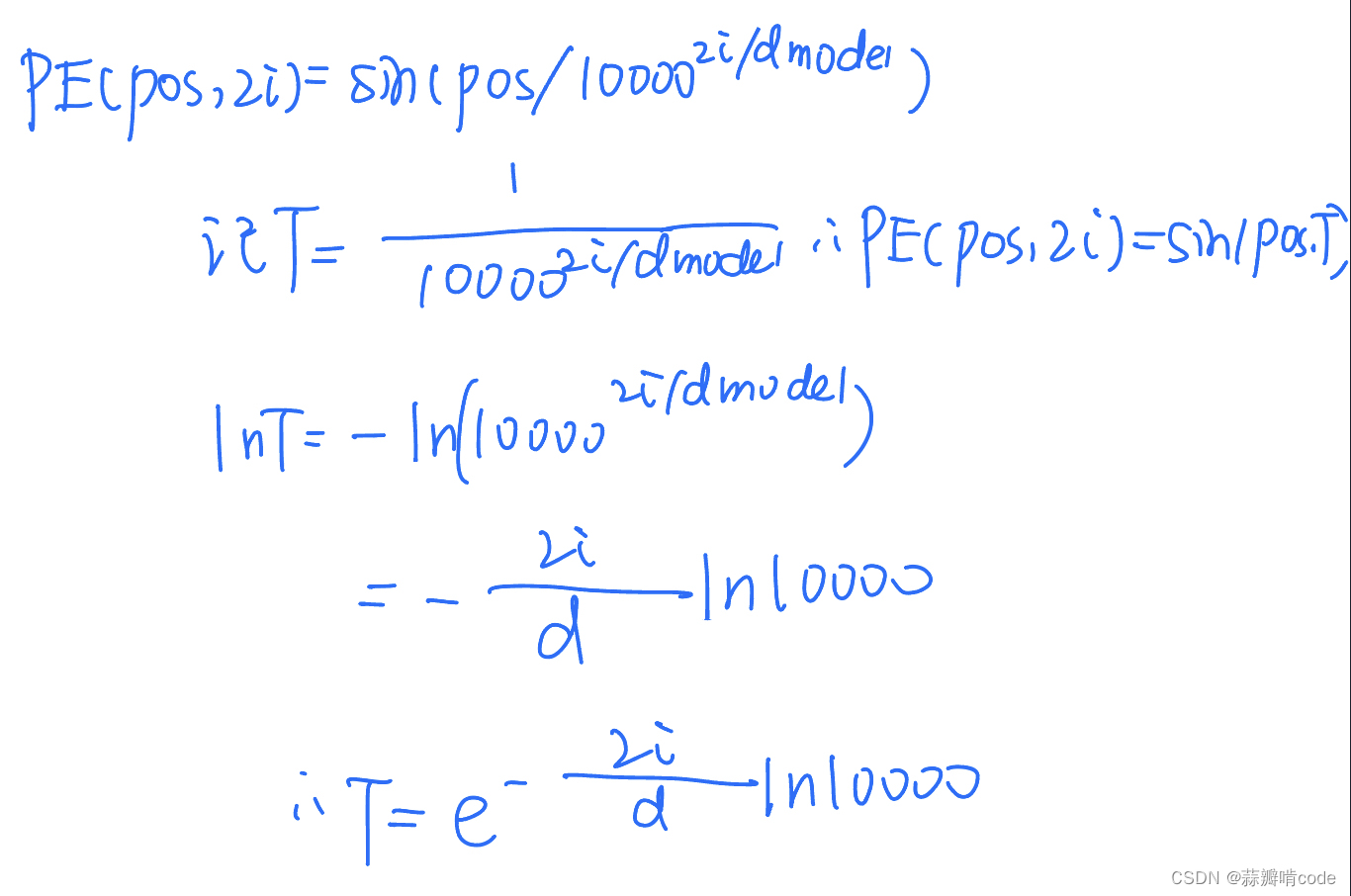
下面介绍一下各参数含义:
- num_timescales=256 ##也就是d/2
- max_timescale=10000.0 ##也就是公式中那个10000
- log_timescale_increment ##公式中的(2/d)*ln10000
- max(num_timescales - 1, 1) ##防止分母为0
- inv_timescales ##exp((2*i/d)*ln10000)
-
- def get_position_encoding(self, x):
- max_length = x.size()[1] ##x传入的参数是input B*N*D,所以这里取的是N
- position = torch.arange(max_length, dtype=torch.float32,
- device=x.device)
- ##position=tensor([0.,1.,2.,……,max_length-1.]),维度是N
- scaled_time = position.unsqueeze(1) * self.inv_timescales.unsqueeze(0)
- ##position.unsqueeze(1)后维度是N*1,inv_timescales.unsqueeze(0)后维度是1*D/2
- ##所以scaled_time维度是N*D/2
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)],
- dim=1)
- signal = F.pad(signal, (0, 0, 0, self.hidden_size % 2))
- ##signal维度是N*D
- signal = signal.view(1, max_length, self.hidden_size)
- ##把signal拉成(1*N*D)
- return signal
另外举两个例子来理解一下torch.nn.functional.pad():
直接看图
对于一个二维的矩阵 pad中的tuple参数(a,b,c,d)代表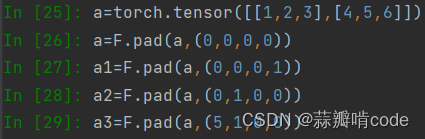

(a,b)表示对矩阵的倒数第一个维度做padding操作,在原tensor的左侧pad a个,右侧pad b个。
(c,d)表示对矩阵的倒数第二个维度做padding操作,在原tensor的左侧pad c个,右侧pad d个。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/371445
推荐阅读
相关标签

