
- 1网络安全简答题
- 2社交媒体数据治理:Facebook的隐私与透明度
- 3脉冲神经网络-基于IAF神经元的手写数字识别_脉冲神经网络 可视化
- 4用 Python 轻松实现机器学习_python做machine learning
- 5怎样用Excel搜索表格内的内容?_excel表格怎么查找内容
- 6机器学习-周志华-课后习题答案-决策树_试选择 4 个 uci 数据集,对上述 3 种算法所产生的未剪枝、预剪枝、后剪枝决策树进
- 7kibana 查询ES 的一些语法_kibana查询es基本语法
- 8解密目前主流的机器人导航方法
- 9LSTM神经网络详解
- 10复试专业前沿问题问答合集7-2——神经网络与强化学习_复试问及卷积神经网络
通俗易懂讲解 Sora 工作原理_sora原理
赞
踩
这位大佬用通俗易懂的方式,逐步拆解Sora工作原理,浅显易懂,推荐看看! 本文为转载文章,原文请看链接。
- https://twitter.com/xiaohuggg/status/1760139842783248609
- https://twitter.com/thatguybg/status/1759935959792312461
概括
Sora结合使用了扩散模型(从噪声开始,逐渐精细化到所需视频)和Transformer架构(处理连续视频帧)。

空间时间补丁
Sora的独特之处在于其处理视频生成的方法。它不是直接将文本转换为视频帧,而是依赖于所谓的“空间时间补丁”。 通过空间时间补丁工作,不直接将文本转换为视频帧,而是处理空间(发生的事情)和时间(何时发生)的快照。可以看作是微观视频拼图的每一小块。
时空立方体
通过这种方式,Sora将视频视为一个包含空间和时间维度的巨大立方体,然后再将其切割成更小的立方体,每个立方体代表空间和时间的片段。
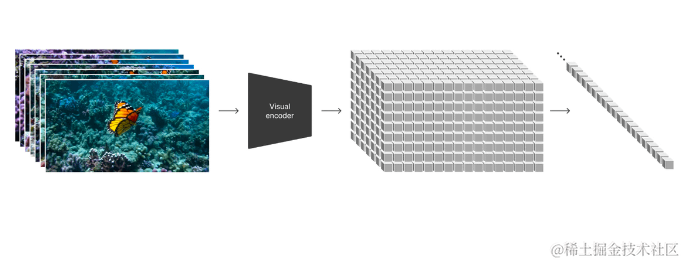
剖析描述并确定了核心要素:
- 物体(盛开的花朵、阳光普照的窗台)
- 行动(随着时间的推移而增长)
- 位置(郊区环境)
- 甚至艺术风格(定格动画美学)
知识图谱
为了能够将这些补丁有意义地组合成一个连贯的视频,Sora利用了其内部的知识图谱。这些知识图谱包含了关于物理世界、对象如何相互作用,甚至包括不同艺术风格的信息。 借助这些知识,Sora能够理解例如:一朵花如何逐渐开放(逐瓣成形)、如何与阳光互动(随时间改变光照)以及如何保持停动画风格(逐帧过渡)等复杂过程。
扩散模型和Transformer架构联动
在视频生成的下一阶段,扩散模型开始对每个嘈杂、抽象的补丁进行处理,逐渐精细化,直至最终呈现出清晰的图像。 Transformer架构负责分析时间跨度上补丁之间的关系,确保视频中的动作(如花朵的生长、阳光的移动)流畅自然,停动画风格在整个视频序列中保持一致。

能力与挑战

尽管Sora能够执行各种与视频相关的任务,并展现出惊人的视频生成能力,但仍有一些挑战需要克服。例如,它在模拟一些基础物理互动的精确性方面还有待提高,如下图有时会产生人物不自然的效果,以及人物的手势看起来不够真实的情况。尽管如此,Sora在视频生成技术方面展示了巨大的潜力,为未来的人工智能应用开辟了新的可能性。


