
- 1LSTM网络结构_lstm隐藏层神经元个数
- 2Unity Mesh简化为Cube mesh
- 3钉钉杯初赛A题建模-多模型融合预测银行卡诈骗模型(详细代码、解释)_distance_from_home
- 4解决jetson xavier nx在安装torchvision是因为权限问题而按不上的问题_torchvision 安装不上
- 5Rasa 安装过程中的坑_rasa cannot import _ssl
- 6代码随想录算法训练营第四十天|leetcode139题
- 7爬虫工作量由小到大的思维转变---<第六十六章 > Scrapy去重机制:BaseDupeFilter与request_fingerprint研究(2)
- 8用gdal正射校正遥感影像_gdal 正射校正
- 9图卷积神经网络GCN---池化层代表作_sortpooling
- 10ES性能优化最佳实践- 检索性能提升30倍!_elasticsearch 搜索性能
构建安全可靠的系统:第一章到第五章
赞
踩
第一章:安全性和可靠性的交集
原文:1. The Intersection of Security and Reliability
译者:飞龙
由亚当·斯塔布菲尔德、马西米利亚诺·波莱托和皮奥特·莱万多夫斯基撰写
与大卫·胡斯卡和贝琪·拜尔一起
关于密码和电钻
2012 年 9 月 27 日,一封无辜的谷歌公司范围内的公告在内部服务中引发了一系列连锁故障。最终,从这些故障中恢复需要使用电钻。
谷歌有一个内部密码管理器,允许员工存储和共享第三方服务的密码,这些服务不支持更好的身份验证机制。其中一个秘密是连接谷歌旧金山湾区校园的大型巴士上的访客 WiFi 系统的密码。
在那个九月的一天,公司的交通团队向成千上万的员工发送了一封电子邮件公告,称 WiFi 密码已更改。由此产生的流量激增远远超过了密码管理系统的处理能力,该系统多年前为一小群系统管理员开发而成。
密码管理器的主要副本由于负载过大而变得无响应,因此负载均衡器将流量转移到次要副本,但次要副本立即以相同的方式失败。此时,系统呼叫了值班工程师。工程师没有经验来应对服务的故障:密码管理器是在尽力支持的基础上运行的,并且在其存在的五年中从未发生过故障。工程师试图重新启动服务,但不知道重新启动需要硬件安全模块(HSM)智能卡。
这些智能卡存放在全球不同的谷歌办公室的多个保险柜中,但不在值班工程师所在的纽约市。当服务无法重新启动时,工程师联系了澳大利亚的一位同事来取回智能卡。令他们大为沮丧的是,澳大利亚的工程师无法打开保险柜,因为组合密码存储在现在已经离线的密码管理器中。幸运的是,加利福尼亚的另一位同事记住了现场保险柜的组合密码,并成功取回了智能卡。然而,即使加利福尼亚的工程师插入了卡片,服务仍然无法重新启动,显示了“密码无法加载任何保护此密钥的卡片”的加密错误。
此时,澳大利亚的工程师决定采用蛮力方法解决保险柜的问题,并用电钻进行了尝试。一个小时后,保险柜被打开了,但即使新取回的卡片也触发了相同的错误消息。
团队花了额外一个小时才意识到智能卡读卡器上的绿灯实际上并没有正确插入卡片。当工程师们翻转卡片时,服务重新启动,故障结束了。
可靠性和安全性都是真正值得信赖的系统的关键组成部分,但构建既可靠又安全的系统是困难的。虽然可靠性和安全性的要求有许多共同的属性,但它们也需要不同的设计考虑。很容易忽视可靠性和安全性之间微妙的相互作用,这可能导致意想不到的结果。密码管理器的故障是由可靠性问题引发的——负载均衡和负载分担策略不佳——而其恢复后又受到了多项旨在增加系统安全性的措施的影响。
可靠性与安全性:设计考虑
在设计可靠性和安全性时,您必须考虑不同的风险。主要的可靠性风险是非恶意的,例如,糟糕的软件更新或物理设备故障。然而,安全风险来自积极试图利用系统漏洞的对手。在设计可靠性时,您假设某些事情在某个时候会出错。在设计安全性时,您必须假设对手可能在任何时候试图让事情出错。
因此,不同的系统设计以非常不同的方式响应故障。在没有对手的情况下,系统通常会失败安全(或开放):例如,电子锁设计为在停电时保持开放,以便通过门安全出口。失败安全/开放行为可能导致明显的安全漏洞。为了防御可能利用停电的对手,您可以设计门在停电时失败安全并保持关闭。
保密性、完整性、可用性
安全性和可靠性都关注系统的保密性、完整性和可用性,但它们通过不同的视角看待这些属性。两种观点之间的关键区别在于是否存在恶意对手。可靠的系统不得意外泄露保密性,例如,一个有缺陷的聊天系统可能会误送、弄乱或丢失消息。此外,安全系统必须防止积极的对手访问、篡改或销毁机密数据。让我们看一些例子,说明可靠性问题如何导致安全问题。
注意
保密性、完整性和可用性一直被认为是安全系统的基本属性,并被称为CIA 三位一体。尽管许多其他模型将安全属性的集合扩展到这三个之外,但 CIA 三位一体随着时间的推移仍然很受欢迎。尽管有这个缩写,但这个概念与中央情报局没有任何关系。
保密性
在航空业中,麦克风卡在传输位置是一个显著的保密问题。在几个有记录的案例中,卡住的麦克风在驾驶舱中广播了飞行员之间的私人对话,这代表了保密的违反。在这种情况下,没有恶意的对手参与:硬件可靠性缺陷导致设备在飞行员不打算时进行传输。
完整性
同样,数据完整性损害不一定涉及主动对手。2015 年,谷歌的网站可靠性工程师(SREs)注意到一些数据块的端到端加密完整性检查失败了。因为一些处理数据的机器后来表现出不可纠正的内存错误的证据,SREs 决定编写软件,详尽地计算每个数据版本的完整性检查,只需一个位翻转(0 变为 1,反之亦然)。这样,他们可以看到是否有一个结果与原始完整性检查的值匹配。所有错误确实都是单位翻转,SREs 恢复了所有数据。有趣的是,这是一个安全技术在可靠性事件中发挥作用的例子。(谷歌的存储系统也使用非加密的端到端完整性检查,但其他问题阻止了 SREs 检测到位翻转。)
可用性
最后,当然,可用性既是可靠性问题,也是安全问题。对手可能利用系统的弱点使系统停止运行或损害其对授权用户的操作。或者他们可能控制世界各地的大量设备来执行经典的分布式拒绝服务(DDoS)攻击,指示许多设备向受害者发送流量。
拒绝服务(DoS)攻击是一个有趣的案例,因为它们跨越了可靠性和安全性的领域。从受害者的角度来看,恶意攻击可能与设计缺陷或合法的流量激增无法区分。例如,2018 年的软件更新导致一些谷歌 Home 和 Chromecast 设备在调整时钟时生成大量同步的网络流量,对谷歌的中央时间服务造成意外负载。同样,一条重大新闻报道或其他事件可能导致数百万人发出几乎相同的查询,看起来非常像传统的应用层 DDoS 攻击。如图 1-1 所示,在 2019 年 10 月的一个深夜,当 4.5 级地震袭击旧金山湾区时,谷歌为该地区提供服务的基础设施遭受了大量查询。
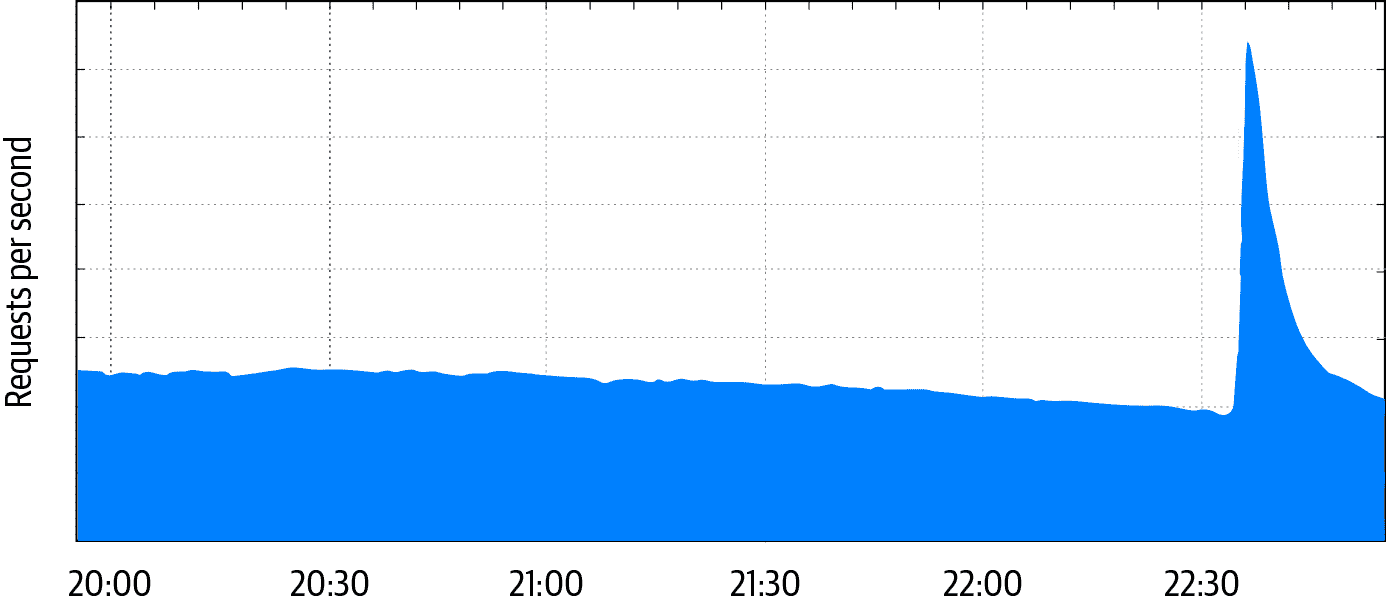
图 1-1:2019 年 10 月 14 日,当 4.5 级地震袭击旧金山湾区时,测量到达谷歌基础设施为用户提供服务的 HTTP 请求每秒的网络流量
可靠性和安全性:共同点
可靠性和安全性——与许多其他系统特性不同——是系统设计的新兴属性。它们都很难在事后添加,因此最好从最早的设计阶段就考虑它们。它们还需要在整个系统生命周期中进行持续关注和测试,因为系统变化很容易无意中影响它们。在复杂系统中,可靠性和安全性属性通常由许多组件的相互作用决定,一个组件的看似无害的更新可能最终影响整个系统的可靠性或安全性,直到引发事故才会显现。让我们更详细地研究这些和其他共同点。
不可见性
可靠性和安全性在一切顺利时大多是看不见的。但可靠性和安全团队的目标之一是赢得并保持客户和合作伙伴的信任。良好的沟通——不仅在麻烦时,而且在一切顺利时——是建立这种信任的坚实基础。信息的诚实和具体性非常重要,不应包含陈词滥调和行话。
不幸的是,在没有紧急情况下,可靠性和安全性的固有不可见性意味着它们经常被视为可以减少或推迟的成本,而不会立即产生后果。然而,可靠性和安全性失败的成本可能是严重的。据媒体报道,数据泄露可能导致 Verizon 在 2017 年收购 Yahoo!互联网业务时减少了 3.5 亿美元的价格。同年,一次停电导致达美航空的关键计算机系统关闭,并导致近 700 次航班取消和数千次延误,使达美航空当天的航班吞吐量减少了约 60%。
评估
因为实现完美的可靠性或安全性并不切实际,所以可以使用基于风险的方法来估计负面事件的成本,以及预防这些事件的前期成本和机会成本。然而,应该以不同的方式衡量可靠性和安全性的负面事件的概率。您可以推断系统组合的可靠性,并根据所需的错误预算计划工程工作,至少部分原因是您可以假设各个组件之间的故障是独立的。这样的组合的安全性更难评估。分析系统的设计和实现可以提供一定程度的保证。对抗性测试——通常从定义的对手的角度进行的模拟攻击——也可以用来评估系统对特定类型攻击的抵抗能力,攻击检测机制的有效性以及攻击的潜在后果。
简单
将系统设计尽可能简单是提高系统可靠性和安全性评估能力的最佳途径之一。简单的设计减少了攻击面,减少了意外系统交互的可能性,并使人类更容易理解和推理系统。在紧急情况下,可理解性尤为重要,因为它可以帮助应对者快速缓解症状并减少修复时间(MTTR)。第六章详细讨论了这个话题,并讨论了诸如最小化攻击面和将安全不变量的责任隔离到可以独立推理的小型简单子系统等策略。
演变
无论最初的设计多么简单和优雅,系统很少会随着时间保持不变。新的功能要求、规模变化以及基础架构的演变都往往引入复杂性。在安全方面,需要跟上不断演变的攻击和新的对手也可能增加系统的复杂性。此外,满足市场需求的压力可能导致系统开发人员和维护人员采取捷径并积累技术债务。第七章讨论了其中一些挑战。
复杂性往往是无意中积累的,但这可能导致临界点情况,即一个小的看似无害的变化对系统的可靠性或安全性产生重大后果。2006 年引入的一个错误,几乎两年后在 Debian GNU/Linux 版本的 OpenSSL 库中被发现,提供了一个臭名昭著的例子,即由一个小的变化引起的重大故障。一个开源开发人员注意到 Valgrind,一个用于调试内存问题的标准工具,报告了关于初始化前使用的内存的警告。为了消除警告,开发人员删除了两行代码。不幸的是,这导致 OpenSSL 的伪随机数生成器只使用了一个进程 ID 作为种子,而在当时的 Debian 默认为 1 到 32,768 之间的一个数字。然后可以轻松地破解加密密钥。
谷歌并不免于由看似无害的变化引发的故障。例如,2018 年 10 月,由于一个通用日志记录库的小改动,YouTube 全球宕机超过一个小时。一个旨在改善事件记录粒度的变化对其作者和指定的代码审查者来说看起来是无害的,并且通过了所有测试。然而,开发人员并没有完全意识到在 YouTube 规模下这种改变的影响:在生产负载下,这个改变迅速导致 YouTube 服务器耗尽内存并崩溃。随着故障将用户流量转移到其他仍然健康的服务器,级联故障使整个服务停止运行。
韧性
当然,内存利用问题不应该导致全球服务中断。系统应该被设计成在不利或意外情况下具有弹性。从可靠性的角度来看,这些情况通常是由意外高负载或组件故障引起的。负载是系统请求的数量和平均成本的函数,因此你可以通过减少一部分传入负载(处理更少)或减少每个请求的处理成本(更便宜地处理)来实现弹性。为了解决组件故障,系统设计应该包括冗余和不同的故障域,这样你就可以通过重新路由请求来限制故障的影响。第八章进一步讨论了这些话题,第十章则深入探讨了特定的 DoS 缓解措施。
然而,无论系统的个别组件有多么具有弹性,一旦它变得足够复杂,你就无法轻易证明整个系统对妥协是免疫的。你可以部分地通过深度防御和不同的故障域来解决这个问题。深度防御是应用多种,有时是冗余的防御机制。不同的故障域限制了故障的“爆炸半径”,因此也增加了可靠性。一个良好的系统设计限制了对手利用受损主机或被盗凭证进行横向移动或提升特权并影响系统其他部分的能力。
你可以通过对权限进行分隔或限制凭证的范围来实现不同的故障域。例如,谷歌的内部基础设施支持明确限定地理区域的凭证。这些类型的功能可以限制攻击者在一个地区损坏服务器后横向移动到其他地区的能力。
为敏感数据使用独立的加密层是深度防御的另一个常见机制。例如,尽管磁盘提供设备级加密,但在应用层也加密数据通常是一个好主意。这样,即使驱动控制器中的加密算法实现有缺陷,也不足以 compromise 受保护数据的机密性,如果攻击者获得对存储设备的物理访问。
虽然迄今为止引用的例子都依赖于外部攻击者,但你也必须考虑来自恶意内部人员的潜在威胁。尽管内部人员可能比第一次窃取员工凭证的外部攻击者更了解潜在的滥用途径,但在实践中这两种情况通常并没有太大的区别。最小权限原则可以缓解内部威胁。它规定用户在特定时间内应该具有执行工作所需的最小权限集。例如,像 Unix 的sudo这样的机制支持细粒度策略,指定哪些用户可以以哪种角色运行哪些命令。
在谷歌,我们还使用多方授权来确保敏感操作得到特定员工组的审查和批准。这种多方机制既可以防范恶意内部人员,也可以减少无辜人为错误的风险,这是可靠性故障的常见原因。最小权限和多方授权并不是新概念——它们在许多非计算场景中都有应用,从核导弹发射井到银行保险库。第五章深入讨论了这些概念。
从设计到生产
即使是将坚实的设计转化为完全部署的生产系统时,也应该牢记安全性和可靠性考虑。从编写代码开始,通过代码审查可以发现潜在的安全性和可靠性问题,甚至可以通过使用常见的框架和库来预防整类问题。第十二章讨论了一些这些技术。
在部署系统之前,您可以使用测试来确保它在正常情况下和通常影响可靠性和安全性的边缘情况下都能正确运行。无论您使用负载测试来了解系统在大量查询下的行为,模糊测试来探索可能意外的输入的行为,还是专门的测试来确保加密库不会泄露信息,测试在获得保证实际构建的系统与设计意图匹配方面发挥着关键作用。第十三章深入讨论了这些方法。
最后,一些部署代码的方法(见第十四章)可以限制安全性和可靠性风险。例如,金丝雀发布和缓慢的部署可以防止您同时为所有用户破坏系统。同样,一个只接受经过适当审查的代码的部署系统可以帮助减轻内部人员将恶意二进制文件推送到生产环境的风险。
调查系统和日志记录
到目前为止,我们已经专注于设计原则和实现方法,以防止可靠性和安全性故障。不幸的是,实现完美的可靠性或安全性通常是不切实际或成本过高的。您必须假设预防机制会失败,并制定一个计划来检测和从故障中恢复。
正如我们在第十五章中讨论的那样,良好的日志记录是检测和故障准备的基础。一般来说,您的日志越完整和详细,越好,但这个指导原则也有一些注意事项。在足够大的规模下,日志量会带来显著的成本,并且有效分析日志可能变得困难。本章前面的 YouTube 示例说明了日志记录也可能引入可靠性问题。安全日志带来了额外的挑战:日志通常不应包含敏感信息,例如身份验证凭据或个人可识别信息(PII),以免日志本身成为对手的吸引目标。
危机响应
在紧急情况下,团队必须迅速而顺利地合作,因为问题可能会立即产生后果。在最坏的情况下,一次事件可能会在几分钟内摧毁一家企业。例如,2014 年,一名攻击者通过接管服务的管理工具并删除所有数据(包括所有备份)使代码托管服务 Code Spaces 在几个小时内破产。熟练的协作和良好的事件管理对及时应对这些情况至关重要。
组织危机响应是具有挑战性的,因此最好在紧急情况发生之前制定计划。当你发现事件时,时间可能已经过去了一段时间。无论如何,响应者都在压力和时间压力下运作,并且(至少最初)具有有限的情境意识。如果一个组织很大,事件需要 24/7 的响应能力或跨时区的协作,那么在团队之间保持状态并在工作时间交接边界处交接事件管理的需求进一步复杂化了操作。安全事件通常也涉及在需要知道的基础上限制信息共享的冲动与法律或监管要求驱使的需要之间的紧张关系。此外,最初的安全事件可能只是冰山一角。调查可能会超出公司范围或涉及执法机构。
在危机期间,拥有清晰的指挥链和一套可靠的检查表、操作手册和协议至关重要。正如第十六章和第十七章中所讨论的,谷歌已经将危机响应编码化为一个名为谷歌事件管理(IMAG)的项目,该项目建立了一种标准、一致的处理各种事件的方式,从系统故障到自然灾害,并组织有效的响应。IMAG 是基于美国政府的事件指挥系统(ICS)建立的,这是一种在多个政府机构的应急响应者之间进行指挥、控制和协调的标准化方法。
当没有面临持续事件的压力时,响应者通常会在很长的间隔时间内进行很少的活动。在这些时候,团队需要保持个人的技能和动力,并改进流程和基础设施,以应对下一次紧急情况。谷歌的灾难恢复测试计划(DiRT)定期模拟各种内部系统故障,并迫使团队应对这些类型的场景。频繁的攻击性安全演习测试我们的防御,并帮助发现新的漏洞。谷歌甚至针对小事件也使用 IMAG,这进一步促使我们定期练习紧急工具和流程。
恢复
从安全失败中恢复通常需要修补系统以修复漏洞。直觉上,你希望这个过程尽快进行,使用经常练习并因此相当可靠的机制。然而,快速推送更改的能力是一把双刃剑:虽然这种能力可以帮助快速关闭漏洞,但也可能引入导致大量损害的错误或性能问题。如果漏洞被广泛知晓或严重,那么推送补丁的压力就会更大。是否慢慢推送修复补丁——因此更有把握确保没有意外副作用,但风险是漏洞会被利用——或者快速推送补丁,最终取决于风险评估和商业决策。例如,为了修复严重漏洞,可能可以接受一些性能损失或增加资源使用。
这样的选择凸显了可靠的恢复机制的必要性,这些机制使我们能够快速推出必要的更改和更新,而不会影响可靠性,并且在造成大范围故障之前也能发现潜在问题。例如,一个强大的机群恢复系统需要可靠地表示每台机器的当前状态和期望状态,并且还需要提供后备措施,以确保状态永远不会回滚到过时或不安全的版本。第九章涵盖了这一点以及许多其他方法,第十八章讨论了一旦发生事件后如何实际恢复系统。
结论
安全性和可靠性有很多共同点——它们都是所有信息系统固有的属性,一开始很容易在速度的名义下牺牲,但事后修复却代价高昂。本书旨在帮助您在系统发展和成长过程中及早解决与安全性和可靠性相关的不可避免的挑战。除了工程努力外,每个组织都必须了解有助于建立安全性和可靠性文化的角色和责任(参见第二十章),以持续实践。通过分享我们的经验和教训,我们希望能够使您在系统生命周期的早期采纳本书中描述的一些原则,从而避免在未来付出更大的代价。
我们撰写本书时考虑了广泛的受众,希望您会发现它与您的项目的阶段或范围无关。阅读时,请牢记您项目的风险概况——运营股票交易所或为异见者提供通信平台与运营动物庇护所网站具有截然不同的风险概况。下一章将详细讨论对手的类别及其可能的动机。
¹ 更多关于错误预算的信息,请参阅SRE 书中的第三章。
第二章:了解对手
原文:2. Understanding Adversaries
译者:飞龙
作者:Heather Adkins 和 David Huska
作者:Jen Barnason
1986 年 8 月,劳伦斯利弗莫尔实验室的系统管理员克利福德·斯托尔(Clifford Stoll)偶然发现了一个看似无害的会计错误,导致了对从美国窃取政府机密的人进行了为期 10 个月的搜寻。1 这被普遍认为是其类别的第一个公开例子,斯托尔主导了一项调查,揭示了对手用来实现目标的具体战术、技术和程序(TTPs)。通过仔细研究,调查团队能够构建出攻击者如何针对和从受保护系统中吸取数据的画面。许多系统设计者已经吸收了从斯托尔的开创性文章中得出的教训,该文章描述了团队的努力,“追踪狡猾的黑客”。
在 2012 年 3 月,谷歌对其比利时数据中心的一次异常停电做出了回应,最终导致了当地数据损坏。调查发现,一只猫损坏了附近的外部电源,触发了建筑物电力系统的一系列级联故障。通过研究类似方式中复杂系统的故障,谷歌已经能够在全球范围内采用具有弹性的设计实践,悬挂、埋藏和浸入电缆。
了解系统的对手对于建立各种灾难的弹性和生存能力至关重要。在可靠性的背景下,对手通常以良性意图行事,并采取抽象的形式。它们可能存在为例常的硬件故障或者用户兴趣的压倒性案例(所谓的“成功灾难”)。它们也可能是导致系统以意想不到的方式行事的配置更改,或者意外切断海底光纤电缆的渔船。相比之下,在安全的背景下,对手是人类;他们的行动是经过计算的,以影响目标系统的不良方式。尽管这些对立的意图和方法,研究可靠性和安全对手对于理解如何设计和实现具有弹性的系统至关重要。没有这些知识,预测狡猾黑客或好奇猫的行动将是非常具有挑战性的。
在本章中,我们深入探讨了安全对手,以帮助不同领域的专家发展对抗性思维。也许会诱人地通过流行的刻板印象来思考安全对手:在黑暗地下室中的攻击者,有着聪明的绰号和潜在的可疑行为。虽然这样的丰富多彩的角色确实存在,但任何有时间、知识或金钱的人都可以破坏系统的安全。只需支付少许费用,任何人都可以购买软件,使他们能够接管他们可以物理接触的计算机或手机。政府经常购买或制造软件来破坏他们的目标系统。研究人员经常探究系统的安全机制,以了解它们的工作原理。因此,我们鼓励您保持客观的观点,了解谁在攻击系统。
没有两次攻击或攻击者是相同的。我们建议查看第二十一章讨论处理对手文化方面的内容。预测未来的安全灾难大多是一个猜测游戏,即使对于知识渊博的安全专家也是如此。在接下来的几节中,我们提出了三种框架来理解攻击者,这些框架多年来对我们有所帮助,探讨了攻击系统的人们的潜在动机,一些常见的攻击者档案,以及如何思考攻击者的方法。我们还在这三个框架内提供了说明性(并且希望有趣的)例子。
攻击者动机
安全对手首先是人类(至少目前是这样)。因此,我们可以通过攻击者的眼睛来考虑攻击的目的。这样做可能更好地装备我们了解我们应该如何做出反应,无论是主动(在系统设计期间)还是被动(在事件期间)。考虑以下攻击动机:
娱乐
为了纯粹的乐趣而破坏系统的安全性,因为他们知道这是可以做到的。
名望
为了展示技术技能而获得恶名。
活动主义
为了表达观点或传播信息,通常是政治观点,广泛传播。
经济利益
赚钱
胁迫
让受害者有意做一些他们不想做的事情。
操纵
创建预期的结果或改变行为,例如发布虚假数据(错误信息)。
间谍活动
获取可能有价值的信息(间谍活动,包括工业间谍活动)。这些攻击通常由情报机构执行。
破坏
破坏系统,销毁其数据,或者只是将其下线。
攻击者可能同时是一个出于经济动机的漏洞研究人员、政府间谍特工和犯罪行为者!例如,2018 年 6 月,美国司法部起诉了朝鲜公民朴振赫,指控他代表政府参与了各种活动,包括制造臭名昭著的 2017 年 WannaCry 勒索软件(用于谋取经济利益),2014 年侵犯索尼影视公司(旨在迫使索尼不发布一部有争议的电影,并最终损害公司的基础设施),以及电力公用事业的侵犯(据推测是出于间谍或破坏目的)。研究人员还观察到政府攻击者使用相同的恶意软件在国家级攻击中用于在视频游戏中窃取电子货币以获取个人利益。
在设计系统时,重要的是要记住这些多样的动机。考虑一个正在代表其客户进行资金转账的组织。如果我们了解攻击者可能对该系统感兴趣的原因,我们就可以更安全地设计系统。在这种情况下,一个可能的动机的很好的例子可以在一群朝鲜政府攻击者(包括朴)的活动中看到,他们据称企图通过侵入银行系统并利用 SWIFT 交易系统从客户账户中转移资金来窃取数百万美元。
攻击者档案
通过考虑这些人本身,我们可以更好地理解攻击者的动机:他们是谁,他们是为自己还是为他人进行攻击,以及他们的一般兴趣。在本节中,我们概述了一些攻击者的档案,指出他们与系统设计者的关系,并包括一些保护系统免受这些类型攻击者侵害的建议。为了简洁起见,我们对一些概括进行了一些自由解释,但请记住:没有两次攻击或攻击者是相同的。这些信息旨在作为说明性的,而不是决定性的。
业余爱好者
最早的计算机黑客是“业余爱好者”——渴望了解系统工作原理的好奇技术人员。在拆解计算机或调试程序的过程中,这些“黑客”发现了原始系统设计者没有注意到的缺陷。一般来说,业余爱好者的动机是对知识的渴望;他们以娱乐为目的进行黑客攻击,并且可以成为希望在系统中建立弹性的开发者的盟友。通常情况下,业余爱好者遵守有关不损害系统的个人道德规范,并且不会涉足犯罪行为。通过利用对这些黑客如何思考问题的洞察,您可以使您的系统更加安全。
漏洞研究人员
漏洞研究人员将他们的安全专业知识作为职业。他们可以作为全职员工、兼职自由职业者,甚至作为偶然发现漏洞的普通用户。许多研究人员参与漏洞奖励计划,也被称为漏洞赏金(见第二十章)。
漏洞研究人员通常受到改善系统的动机,并且可以成为寻求保护其系统的组织的重要盟友。他们往往遵循一套可预测的披露规范,这些规范设定了系统所有者和研究人员之间关于漏洞的发现、报告、修复和讨论的期望。遵循这些规范的研究人员避免不当访问数据、造成伤害或违法行为。通常来说,违反这些规范会使得获得奖励的可能性无效,并且可能被视为犯罪行为。
与此相关的,红队和渗透测试人员在获得系统所有者的许可下攻击目标,并且可能会被明确聘请进行这些练习。与研究人员一样,他们寻找击败系统安全的方法,专注于改善安全,并遵守一套道德准则。有关红队的更多讨论,请参见第二十章。
政府和执法机构
政府组织(例如执法机构和情报机构)可能会聘请安全专家来收集情报、打击国内犯罪、进行经济间谍活动,或者辅助军事行动。到目前为止,大多数国家政府都投资于培养这些目的的安全专业知识。在某些情况下,政府可能会转向刚刚毕业的有才华的学生、在监狱度过时间的改过自新的攻击者,或者安全行业的知名人士。虽然我们无法在这里广泛涵盖这些类型的攻击者,但我们提供了一些他们最常见活动的例子。
情报收集
情报收集可能是最公开讨论的政府活动,这些活动雇佣了懂得如何侵入系统的人。在过去的几十年中,包括信号情报(SIGINT)和人员情报(HUMINT)在内的传统间谍技术随着互联网的出现而现代化。在 2011 年的一个著名例子中,安全公司 RSA 遭到了攻击,许多专家将这些攻击者与中国的情报机构联系在一起。攻击者侵入 RSA 以窃取其流行的双因素身份验证令牌的加密种子。一旦他们获得了这些种子,攻击者就不需要物理令牌来生成一次性身份验证凭证,以登录美国军方技术承包商洛克希德·马丁公司的系统。曾经,侵入像洛克希德这样的公司会由现场的人员操作,例如贿赂员工或者在公司雇佣间谍。然而,系统入侵的出现使得攻击者能够使用更复杂的电子技术以新的方式获取秘密。
军事目的
政府可能侵入系统用于军事目的,专家们通常称之为网络战或信息战。想象一下,一个政府想要入侵另一个国家。他们是否能够攻击目标的防空系统,并欺骗他们不认出来袭击的空军?他们是否能够关闭他们的电力、水务或银行系统?或者,想象一下,一个政府想要阻止另一个国家建造或获取武器。他们是否能够远程和悄悄地干扰他们的进展?这种情况据说发生在 2000 年代末的伊朗,当时攻击者非法地将一款模块化软件引入用于浓缩铀的离心机的控制系统。研究人员称之为Stuxnet,这次行动据说旨在摧毁离心机并停止伊朗的核计划。
监管国内活动
政府也可能侵入系统以监管国内活动。最近的一个例子是,网络安全承包商 NSO 集团向各国政府出售软件,允许私人监视人们之间的通信,而这些人并不知情(通过远程监视手机通话)。据报道,这款软件旨在监视恐怖分子和罪犯,这些目标相对不具争议。不幸的是,NSO 集团的一些政府客户也使用该软件监听记者和活动人士,有时导致骚扰、逮捕,甚至可能导致死亡。政府使用这些能力对待自己的人民的伦理问题是一个备受争议的话题,特别是在法律框架不健全、监督不到位的国家。
保护您的系统免受国家行为者的侵害
系统设计者应仔细考虑他们是否可能成为国家行为者的目标。为此,您需要了解您的组织所进行的可能对这些行为者具有吸引力的活动。考虑一个构建和销售微处理器技术给政府军事部门的技术公司。其他政府可能也对这些芯片感兴趣,并可能通过电子手段窃取其设计。
您的服务可能也拥有政府想要但难以获取的数据。一般来说,情报机构和执法部门重视个人通信、位置数据和类似类型的敏感个人信息。2010 年 1 月,谷歌宣布它目睹了来自中国的一次复杂的有针对性的攻击(研究人员称之为“奥罗拉行动”),针对的是长期访问 Gmail 账户的企业基础设施。存储客户的个人信息,特别是私人通信,可能会增加情报或执法机构对您的系统感兴趣的风险。
有时候您可能是一个目标,却没有意识到。奥罗拉行动不仅限于大型科技公司——它影响了至少 20 个受害者,涉及金融、技术、媒体和化工等多个领域。这些组织既有大型也有小型,许多人并不认为自己处于国家攻击的风险之中。
例如,一个旨在为运动员提供数据跟踪分析的应用程序。这些数据是否会成为情报机构的吸引目标?2018 年,分析人员在健身追踪公司 Strava 创建的公共热图上考虑了这个确切的问题,当他们注意到美国军队使用该服务跟踪他们的锻炼时,揭示了叙利亚秘密军事基地的位置。
系统设计者还应该意识到,政府通常可以投入大量资源来获取他们感兴趣的数据。对抗对你的数据感兴趣的政府可能需要远远超出你的组织可以投入的资源来实现安全解决方案。我们建议组织在建立安全防御方面采取长远眼光,通过早期投资保护他们最敏感的资产,并通过持续的严格计划,随着时间的推移应用新的保护层。理想的结果是迫使对手耗费大量资源来针对你,增加他们被抓到的风险,以便他们的活动可以被揭露给其他可能的受害者和政府当局。
活动分子
骇客活动是利用技术呼吁社会变革的行为。这个术语被宽泛地应用于各种在线政治活动,从颠覆政府监视到对系统的恶意破坏。⁴为了考虑如何设计系统,我们在这里考虑后一种情况。
骇客活动分子已经被知晓破坏网站,即用政治信息替换正常内容。在2015 年的一个例子中,叙利亚电子军(支持巴沙尔·阿萨德政权的一群恶意行为者)接管了为www.army.mil提供网页流量的内容分发网络(CDN)。攻击者随后能够插入一条支持阿萨德的信息,随后被访问网站的访客看到。这种攻击对网站所有者来说可能非常尴尬,并可能破坏用户对网站的信任。
其他骇客活动分子的攻击可能会更具破坏性。例如,2012 年 11 月,分散的国际骇客活动分子组织匿名者⁵ 通过拒绝服务攻击使许多以色列网站下线。结果,访问受影响的网站的人经历了缓慢的服务或错误。这种性质的分布式拒绝服务攻击向受害者发送来自全球数千台受损机器的洪水式流量。这些所谓的僵尸网络经纪人通常在线提供这种能力,使攻击变得普遍且易于实现。在严重程度的另一端,攻击者甚至可能威胁要完全摧毁或破坏系统,这促使一些研究人员将他们标记为网络恐怖分子。
与其他类型的攻击者不同,骇客活动分子通常会公开宣称他们的活动,并经常公开宣称。这可以通过多种方式表现出来,包括在社交媒体上发布或破坏系统。参与此类攻击的活动分子甚至可能并不具备很高的技术水平。这可能使得预测或防御骇客活动变得困难。
保护你的系统免受骇客活动分子的攻击
我们建议思考你的业务或项目是否涉及可能引起活动分子注意的有争议的话题。例如,你的网站是否允许用户托管他们自己的内容,比如博客或视频?你的项目是否涉及政治问题,比如动物权利?活动分子是否使用你的产品,比如消息服务?如果对任何一个问题的答案是“是”,你可能需要考虑非常强大的、分层的安全控制,以确保你的系统修补漏洞并且能够抵御 DoS 攻击,并且你的备份能够快速恢复系统和数据。
犯罪行为者
攻击技术用于执行与其非数字化表亲非常相似的犯罪行为 - 例如,身份欺诈,盗窃钱财和勒索。犯罪分子具有各种技术能力。有些可能很复杂,并编写自己的工具。其他人可能购买或借用其他人构建的工具,依赖于它们易于使用的点击式攻击界面。事实上,社会工程 - 欺骗受害者协助您进行攻击的行为 - 尽管难度最低,但非常有效。对于大多数犯罪分子来说,进入的唯一障碍是一点时间,一台计算机和一点现金。
提供数字领域中发生的各种犯罪活动的完整目录是不可能的,但我们在这里提供了一些说明性的例子。例如,想象一下,你想预测并购活动,以便相应地安排某些股票交易。2014 年至 2015 年,中国的三名犯罪分子就有这个想法,并通过从毫不知情的律师事务所窃取敏感信息赚了几百万美元。
在过去的 10 年中,攻击者还意识到受害者在其敏感数据受到威胁时会交出钱财。勒索软件是一种软件,它将系统或其信息扣为人质(通常是通过加密),直到受害者向攻击者支付赎金。通常,攻击者通过利用漏洞,将勒索软件与合法软件捆绑在一起,或者欺骗用户自行安装来感染受害者的机器。
犯罪活动并不总是以公开的偷钱行为表现出来。跟踪软件 - 通常以低至 20 美元的价格出售的间谍软件旨在在不知情的情况下收集有关另一个人的信息。恶意软件被引入受害者的计算机或手机上,要么是通过欺骗受害者安装它,要么是通过攻击者直接安装到设备上。一旦安装完成,该软件就可以记录视频和音频。由于跟踪软件通常由受害者身边的人使用,比如配偶,这种信任的滥用可能会产生毁灭性的效果。
并非所有犯罪分子都为自己工作。公司,律师事务所,政治活动,卡特尔,帮派和其他组织都会为了自己的目的而雇佣恶意行为者。例如,一名哥伦比亚攻击者声称他被聘请协助墨西哥 2012 年总统竞选候选人以及拉丁美洲其他选举,通过窃取反对派信息和散布虚假信息。在利比里亚的一个惊人案例中,一家移动电话服务提供商 Cellcom 的雇员据称聘请了一名攻击者来破坏其竞争对手 Lonestar 的网络。这些攻击破坏了 Lonestar 为其客户提供服务的能力,导致该公司损失了大量收入。
保护您的系统免受犯罪分子的攻击
在设计系统以抵御犯罪行为者时,请记住这些行为者往往倾向于选择最简单的方式以最小的成本和努力来实现他们的目标。如果你的系统足够强大,他们可能会将注意力转移到另一个受害者身上。因此,请考虑他们可能会瞄准哪些系统,以及如何使他们的攻击变得昂贵。完全自动化的公共图灵测试(CAPTCHA)系统的发展是如何随着时间增加攻击成本的一个很好的例子。CAPTCHA 用于确定网站是否与人类或自动机器人进行交互,例如在登录时。机器人通常是恶意活动的迹象,因此能够确定用户是否为人类可能是一个重要的信号。早期的 CAPTCHA 系统要求人类验证略微扭曲的字母或数字,这些对机器人来说很难识别。随着机器人变得更加复杂,CAPTCHA 实现者开始使用扭曲图片和物体识别。这些策略旨在随着时间的推移显著增加攻击 CAPTCHA 的成本。⁶
自动化和人工智能
2015 年,美国国防高级研究计划局(DARPA)宣布了网络大挑战比赛,旨在设计一个网络推理系统,能够自学习并在没有人类干预的情况下发现软件漏洞,开发利用这些漏洞的方法,然后修补这些利用。七个团队参加了现场的“最终事件”,并观看他们完全独立的推理系统在一个大型舞厅内相互攻击。第一名的团队成功开发了这样一个自学习系统!
网络大挑战的成功表明,未来至少有一些攻击可能会在没有人类直接控制的情况下执行。科学家和伦理学家在思考是否完全有意识的机器可能足够能够学会如何相互攻击。自主攻击平台的概念也促使了对越来越自动化的防御的需求,我们预测这将是未来系统设计者重要的研究领域。
保护您的系统免受自动化攻击
为了抵御自动化攻击的冲击,开发人员需要默认考虑到弹性系统设计,并能够自动迭代其系统的安全姿态。我们在本书中涵盖了许多这些主题,比如第五章中的自动化配置分发和访问理由;第十四章中的代码的自动构建、测试和部署;以及第八章中的处理 DoS 攻击。
内部人员
每个组织都有内部人员:目前或曾经的员工,他们被信任可以内部访问系统或专有知识。内部人员风险就是这些个人带来的威胁。当一个人能够执行一系列恶意、疏忽或意外情况的行动时,他就成为了内部人员威胁,这可能会对组织造成伤害。内部风险是一个庞大的主题,可以填满几本书的篇幅。为了帮助系统设计者,我们在这里简要介绍这个主题,考虑了三个一般类别,如表 2-1 中所述。
表 2-1. 内部人员的一般类别和示例
| 第一方内部人员 | 第三方内部人员 | 相关内部人员 |
|---|---|---|
| 员工 | 第三方应用程序开发人员 | 朋友 |
| 实习生 | 开源贡献者 | 家人 |
| 高管 | 受信任的内容贡献者 | 室友 |
| 董事会成员 | 商业合作伙伴 | |
| 承包商 | ||
| 供应商 | ||
| 审计员 |
第一方内部人员
第一方内部人员是为了特定目的而被引入的人员,通常是直接参与实现业务目标。这个类别包括直接为公司工作的员工、高管和做出关键公司决策的董事会成员。您可能还能想到其他属于这个类别的人。具有对敏感数据和系统的第一方访问权限的内部人员占据了大多数关于内部风险的新闻报道。以通用电气公司的工程师为例,他于 2019 年 4 月被起诉窃取专有文件,将其嵌入照片中使用隐写软件(以掩盖其盗窃行为),并将其发送到他的个人电子邮件账户。检察官声称,他的目标是使他和他在中国的商业伙伴能够生产通用电气公司的涡轮机的低成本版本,并将其出售给中国政府。这样的故事在生产下一代技术的高科技公司中普遍存在。
对个人数据的访问也可能诱惑内部人员具有窥视倾向的人,那些想要因为拥有特权访问而显得重要的人,甚至那些想要出售此类信息的人。在2008 年的一个臭名昭著的案例中,几名医院工作人员因不当查看患者文件(包括知名名人)而被 UCLA 医疗中心解雇。随着越来越多的消费者注册社交网络、消息传递和银行服务,保护他们的数据免受不当员工访问比以往任何时候都更为重要。
一些最激进的内部风险故事涉及不满的内部人员。2019 年 1 月,一名因绩效不佳而被解雇的男子被判删除了他前雇主的 23 个虚拟服务器。这一事件使公司失去了重要合同和大量收入。几乎任何存在一段时间的公司都有类似的故事。由于就业关系的动态性质,这种风险是不可避免的。
前面的例子涵盖了恶意意图影响系统和信息安全的情况。然而,正如本书前面的一些例子所说明的,第一方内部人员也可能影响系统的可靠性。例如,前一章讨论了一系列不幸的内部人员行为,这些行为影响了密码存储系统的设计、运行和维护,从而阻止了 SRE 在紧急情况下访问凭据。正如我们将看到的,预见内部人员可能引入的错误对于保证系统完整性至关重要。
第三方内部人员
随着开源软件和开放平台的兴起,越来越有可能内部威胁可能是您组织中很少有人(或没有人)见过的人。考虑以下情景:您的公司开发了一个有助于处理图像的新库。您决定开源该库并接受公众的代码更改列表。除了公司员工,您现在还必须考虑开源贡献者作为内部人员。毕竟,如果您从未见过的世界另一端的开源贡献者提交了恶意更改列表,他们可以伤害使用您的库的人。
同样,开源开发人员很少有能力在可能部署其代码的所有环境中测试其代码。对代码库的添加可能引入不可预测的可靠性问题,例如意外的性能下降或硬件兼容性问题。在这种情况下,您需要实现控制,确保所有提交的代码都经过彻底审查和测试。有关该领域最佳实践的更多详细信息,请参阅第十三章和第十四章。
您还应该仔细考虑如何通过应用程序编程接口(API)扩展产品的功能。假设您的组织开发了一个人力资源平台,具有第三方开发者 API,以便公司可以轻松地扩展软件的功能。如果第三方开发者对数据拥有特权或特殊访问权限,他们现在可能是内部威胁。仔细考虑通过 API 提供的访问权限,以及第三方获得访问权限后可以做什么。您能否限制这些扩展内部人员对系统可靠性和安全性的影响?
相关内部人员
我们经常会对我们生活在一起的人有隐含的信任,但是系统设计者在设计安全系统时经常忽视这些关系。考虑这样一种情况,员工在周末把他们的笔记本电脑带回家。当它在厨房桌子上解锁时,谁可以访问该设备,他们可能会产生什么影响,无论是恶意还是无意的?远程办公、在家工作和深夜的值班对技术工作者来说越来越普遍。在考虑内部风险威胁模型时,一定要使用“工作场所”的广泛定义,其中也包括家庭。键盘后面的人可能并不总是“典型”的内部人员。
内部风险威胁建模
存在许多用于建模内部风险的框架,从简单到高度专题特定、复杂和详细。如果您的组织需要一个简单的模型来开始,我们已成功使用表 2-2 中的框架。这个模型也适用于快速的头脑风暴会议或有趣的卡牌游戏。
表 2-2. 内部风险建模框架
| 角色/行为者 | 动机 | 行为 | 目标 |
|---|---|---|---|
| 工程 | 意外 | 数据访问 | 用户数据 |
| 运营 | 疏忽 | 外泄(盗窃) | 源代码 |
| 销售 | 受损 | 删除 | 文档 |
| 法律 | 金融 | 修改 | 日志 |
| 市场营销 | 意识形态 | 注入 | 基础设施 |
| 高管 | 报复性 | 向媒体泄露 | 服务 |
| 虚荣 | 财务 |
首先,建立组织中存在的角色/行为者列表。尝试考虑可能造成伤害(包括意外)和潜在目标(数据、系统等)的所有行为。您可以从每个类别中组合项目以创建许多场景。以下是一些示例,供您开始:
-
一名拥有源代码访问权限的工程师对他们的绩效评估不满,并通过在生产中注入恶意后门来报复,窃取用户数据。
-
一名 SRE 拥有网站 SSL 加密密钥的访问权限,被一个陌生人接触,并被强烈鼓励(例如通过对其家人的威胁)交出敏感材料。
-
一名财务分析师在加班准备公司财务报表时意外修改了最终年度营收数字,使其增加了 1000%。
-
SRE 的孩子在家使用他们父母的笔记本电脑,并安装了一个捆绑了恶意软件的游戏,导致电脑被锁定,阻止了 SRE 对严重故障的响应。
内部风险设计
这本书提供了许多安全设计策略,适用于防范内部风险和恶意的“外部”攻击者。在设计系统时,您必须考虑到有权访问系统或其数据的人可能是本章概述的任何攻击者类型。因此,检测和减轻两种类型风险的策略是相似的。
我们发现在思考内部风险时,有一些概念特别有效:
最小权限
授予执行工作职责所需的最少权限,无论是范围还是访问的持续时间。请参见第五章。
零信任
设计自动化或代理机制来管理系统,以便内部人员不具有广泛访问权限,从而导致他们造成伤害。参见第三章。
多方授权
使用技术控制要求多人授权敏感操作。参见第五章。
业务理由
要求员工正式记录他们访问敏感数据或系统的原因。参见第五章。
审计和检测
审查所有访问日志和理由,确保它们是适当的。参见第十五章。
可恢复性
在发生破坏性行为后恢复系统的能力,比如不满的员工删除关键文件或系统。参见第九章。
攻击者方法
我们描述的威胁行为者是如何进行攻击的?了解这个问题的答案对于理解某人可能如何破坏您的系统以及您如何保护它们至关重要。了解攻击者的操作方式可能感觉像复杂的魔术。试图预测任何特定攻击者在任何给定日子可能做什么是不可行的,因为攻击方法的多样性。我们无法在这里呈现每种可能的方法,但幸运的是,开发人员和系统设计师可以利用越来越大的示例和框架库来解决这个问题。在本节中,我们讨论了几种研究攻击者方法的框架:威胁情报、网络杀伤链和 TTPs。
威胁情报
许多安全公司都会详细描述他们在野外看到的攻击。这种威胁情报可以帮助系统防御者了解真实攻击者每天的工作方式以及如何击退他们。威胁情报有多种形式,每种形式都有不同的用途:
-
书面报告描述了攻击发生的方式,对于了解攻击者的进展和意图特别有用。这些报告通常是作为实际响应活动的结果生成的,根据研究人员的专业知识可能质量不同。
-
威胁指标(IOCs)通常是攻击的有限属性,例如攻击者托管网络钓鱼网站的 IP 地址或恶意二进制文件的 SHA256 校验和。IOCs 通常使用通用格式结构化⁸,并通过自动化源获取,以便用于自动配置检测系统。
-
恶意软件报告提供了对攻击工具能力的洞察,并可以成为 IOCs 的来源。这些报告是由专家使用标准工具(如 IDA Pro 或 Ghidra)对二进制文件进行反向工程生成的。恶意软件研究人员还使用这些研究来根据它们的共同软件属性交叉相关无关的攻击。
从声誉良好的安全公司获取威胁情报,最好是有客户参考的公司,可以帮助您更好地了解攻击者的观察活动,包括影响同行组织的攻击。了解类似您的组织所面临的攻击类型可以提供您可能在未来面临的早期警告。许多威胁情报公司还免费公开发布每年的摘要和趋势报告。⁹
网络杀伤链™
为了应对攻击,一种方法是列出攻击者可能需要采取的所有步骤来实现他们的目标。一些安全研究人员使用形式化的框架,如网络攻击链¹⁰来分析攻击。这些框架可以帮助您绘制攻击的正式进展以及需要考虑的防御控制。表 2-3 显示了假想攻击的阶段相对于一些防御层。
表 2-3.假想攻击的网络攻击链
| 攻击阶段 | 攻击示例 | 示例防御 |
|---|---|---|
| 侦察:监视目标受害者,了解他们的弱点。 | 攻击者使用搜索引擎查找目标组织员工的电子邮件地址。 | 教育员工有关在线安全。 |
| 入口:获取进入网络、系统或账户的权限,以执行攻击。 | 攻击者向员工发送钓鱼邮件,导致账户凭证被盗。攻击者然后使用这些凭证登录到组织的虚拟专用网络(VPN)服务。 | 对 VPN 服务使用双因素身份验证(如安全密钥)。只允许组织管理的系统连接 VPN。 |
| 横向移动:在系统或账户之间移动,以获取额外的访问权限。 | 攻击者使用被盗的凭证远程登录到其他系统。 | 允许员工只能登录到自己的系统。要求多用户系统登录使用双因素身份验证。 |
| 持久性:确保持续访问被损害的资产。 | 攻击者在新被损害的系统上安装后门,以提供远程访问。 | 使用应用程序白名单,只允许授权软件运行。 |
| 目标:采取攻击目标的行动。 | 攻击者从网络中窃取文件,并使用远程访问后门将其外泄。 | 对敏感数据启用最低特权访问,并监控员工账户。 |
战术、技术和程序
系统地对攻击者的 TTP 进行分类是一种越来越常见的分类攻击方法的方式。最近,MITRE 已经开发了ATT&CK 框架来更彻底地实现这一想法。简而言之,该框架将网络攻击链的每个阶段扩展为详细的步骤,并提供了攻击者如何执行攻击的正式描述。例如,在凭证访问阶段,ATT&CK 描述了用户的*.bash_history*可能包含攻击者可以通过简单阅读文件获得的意外输入的密码。ATT&CK 框架列出了攻击者可能操作的数百(甚至数千)种方式,以便防御者可以针对每种攻击方法建立防御措施。
风险评估考虑因素
了解潜在对手、他们是谁以及他们可能使用的方法可能是复杂而微妙的。在评估各种攻击者所构成的风险时,我们发现以下考虑因素很重要:
你可能没有意识到自己是一个目标。
你的公司、组织或项目可能是潜在目标并不是立即显而易见的。许多组织,尽管规模较小或不涉及处理敏感信息,也可以被利用来进行攻击。2012 年 9 月,Adobe 公司(以能够让内容创作者使用的软件而闻名)披露攻击者已经侵入其网络,并明确表示要使用公司的官方软件签名证书来数字签名其恶意软件。这使攻击者能够部署看起来合法的恶意软件,以躲避杀毒软件和其他安全防护软件的检测。考虑一下你的组织是否拥有攻击者感兴趣的资产,无论是直接获利还是作为对其他人的更大规模攻击的一部分。
攻击的复杂性并不是成功的真正预测因素。
即使攻击者拥有大量资源和技能,也不要假设他们总是会选择最困难、昂贵或晦涩的手段来实现他们的目标。一般来说,攻击者选择最简单和成本效益最高的方法来破坏系统,以满足他们的目标。例如,一些最显著和有影响力的情报收集行动依赖于基本的钓鱼——诱使用户交出他们的密码。因此,在设计你的系统时,一定要先涵盖安全的基本要点(如使用双因素认证),然后再担心晦涩和奇特的攻击(如固件后门)。
不要低估你的对手。
不要假设对手无法获取资源来进行昂贵或困难的攻击。仔细考虑你的对手愿意花费多少。美国国家安全局在路上拦截装运给客户的思科硬件并在其中植入后门的非凡故事说明了资金充裕和有才能的攻击者为实现目标所付出的努力。然而,请记住,这类案例很大程度上是例外而不是常规。
归因很难。
2016 年 3 月,研究人员发现了一种新型勒索软件——一种恶意程序,使数据或系统无法使用,直到受害者支付赎金,他们将其命名为 Petya。Petya 似乎是出于经济动机。一年后,研究人员发现了一种新的恶意软件,它与原始的 Petya 程序共享许多元素。这个被称为NotPetya的新恶意软件迅速在全球传播,但主要出现在乌克兰的系统上,而且正好是在乌克兰的一个节日前夕。为了传播 NotPetya,攻击者侵入了一家专门为乌克兰市场生产产品的公司,并滥用他们的软件分发机制来感染受害者。一些研究人员认为,这次攻击是由俄罗斯政府支持的行为者进行的,目的是针对乌克兰。
这个例子表明,有动机的攻击者可以以创造性的方式隐藏他们的动机和身份——在这种情况下,伪装成可能更温和的东西。由于攻击者的身份和意图可能并不总是被充分理解,我们建议你专注于攻击者的工作方式(他们的 TTPs),而不是担心他们具体是谁。
攻击者并不总是害怕被抓。
即使你设法追踪到攻击者的位置和身份,刑事系统(尤其是国际上)可能会使他们难以对他们的行为承担法律责任。这对于直接为可能不愿意引渡他们进行刑事起诉的政府工作的国家行为者尤其如此。
结论
所有安全攻击都可以追溯到一个有动机的人。我们已经介绍了一些常见的攻击者档案,以帮助你确定谁可能想要攻击你的服务以及为什么,从而让你能够相应地优先考虑你的防御。
评估谁可能会以你为目标。你有什么资产?谁购买你的产品或服务?你的用户或他们的行为是否会激励攻击者?你的防御资源与潜在对手的进攻资源相比如何?即使面对资金充裕的攻击者,本书的其余信息也可以帮助你成为一个更昂贵的目标,可能消除攻击的经济动机。不要忽视那些更小、不太显眼的对手——匿名性、位置、充裕的时间以及起诉的困难都可以成为攻击者的优势,使他们能够给你造成不成比例的大量损害。考虑你的内部风险,因为所有组织都面临来自内部人员的恶意和非恶意潜在威胁。内部人员被授予的提升访问权限使他们能够造成重大损害。
及时了解安全公司发布的威胁情报。虽然多步攻击方法可能有效,但它也提供了多个接触点,您可以在那里检测和阻止攻击。要注意复杂的攻击策略,但不要忘记简单、不成熟的攻击,比如网络钓鱼,可能会非常有效。不要低估你的对手或你作为目标的价值。
¹ 斯托尔在《ACM 通讯》的一篇文章中记录了这次攻击,“追踪狡猾的黑客”,以及书籍《布谷鸟的蛋:在计算机间谍的迷宫中追踪间谍》(画廊书籍)。这两本书对于任何设计安全可靠系统的人来说都是很好的资源,因为它们的发现今天仍然相关。
² 作为这个领域复杂性的一个例子,在这类冲突中,并非所有攻击者都是有组织的军队的一部分。例如,据报道,荷兰攻击者在波斯湾战争(1991 年)期间入侵了美国军方,并向伊拉克政府提供了窃取的信息。
³ NSO 集团的活动已经被多伦多大学蒙克全球事务与公共政策学院的研究和政策实验室公民实验室研究和记录。例如,请参见https://oreil.ly/IqDN_。
⁴ 关于谁创造了这个术语以及它的含义存在一些争论,但在 1996 年之后,它在Hacktivismo采用后被广泛使用,这是与死牛(cDc)邪教有关的一个团体。
⁵ 匿名是许多人在黑客行动(和其他行动)中使用的别名。根据情况,它可能(或可能不)指的是单个人或一群相关的人。
⁶ 提高 CAPTCHA 技术效果的竞赛仍在继续,最新的进展利用用户与 CAPTCHA 交互时的行为分析。reCAPTCHA是您可以在您的网站上使用的免费服务。有关研究文献的相对最新概述,请参见 Chow Yang-Wei,Willy Susilo 和 Pairat Thorncharoensri。2019 年的文章“CAPTCHA 设计和安全问题”。在《网络安全的进展:原理、技术和应用》中,由 Kuan-Ching Li,Xiaofeng Chen 和 Willy Susilo 编辑,69–92。新加坡:斯普林格出版社。
⁷ 有关考虑安全和隐私功能如何受家庭伴侣虐待影响的例子,请参见马修斯(Matthews, Tara)等人 2017 年的文章“幸存者的故事:应对亲密伴侣虐待时的隐私和安全实践。”《2017 年人机交互计算系统 CHI 会议论文集》:2189–2201。https://ai.google/research/pubs/pub46080。
⁸ 例如,许多工具正在将结构威胁信息表达(STIX)语言纳入标准化的 IOC 文档,这些文档可以在使用受信任的自动化指标信息交换(TAXII)项目等服务之间交易。
⁹ 值得注意的例子包括每年的Verizon 数据泄露调查报告和 CrowdStrike 的年度全球威胁报告。
¹⁰ 由洛克希德·马丁公司构思(并注册商标)的网络杀伤链是传统军事攻击结构的改编。它定义了网络攻击的七个阶段,但我们发现这可以被改编;一些研究人员将其简化为四到五个关键阶段,就像我们在这里所做的那样。
¹¹ 格林沃尔德,格伦。2014 年。《无处可藏:爱德华·斯诺登、NSA 和美国监视国家》。纽约:大都会图书,149 页。
第二部分:设计系统
译者:飞龙
第二部分着重于以尽可能早的阶段,在设计系统时实现安全性和可靠性要求的最具成本效益的方式。
尽管产品设计理想上应该从一开始就考虑安全性和可靠性,但你将开发的许多与安全性和可靠性相关的功能可能会被添加到现有产品中。第三章提供了一个例子,说明了我们是如何使谷歌已经运行的系统更安全,更不容易发生故障的。您可以为您的系统添加许多类似的增强功能,并且当配合一些后续的设计原则时,它们将更加有效。
第四章考虑了将安全性和可靠性问题推迟处理以换取持续速度的自然倾向。我们认为功能和非功能要求不一定需要相互对立。
如果你想知道从哪里开始将安全性和可靠性原则融入到你的系统中,第五章——讨论如何根据风险评估访问的优点——是一个很好的起点。第六章然后探讨了如何通过不变量和心智模型来分析和理解你的系统。特别是,该章建议使用建立在标准化框架上的分层系统架构,用于身份、授权和访问控制。
为了应对不断变化的风险格局,您需要能够频繁快速地改变您的基础设施,同时保持高度可靠的服务。第七章介绍了让您适应短期、中期和长期变化,以及在运行服务时可能出现的意外复杂性的做法。
到目前为止提到的指导方针,如果系统无法经受重大故障或中断,将会有限的好处。第八章讨论了在事故期间保持系统运行的策略,也许是以降级模式。第九章从修复系统的角度来看待系统。最后,第十章介绍了一种可靠性和安全性相交的场景,并举例说明了在服务堆栈的每一层中一些成本效益的 DoS 攻击缓解技术。
第三章:案例研究:安全代理
原文:3. Case Study: Safe Proxies
译者:飞龙
作者:Jakub Warmuz 和 Ana Oprea
与 Thomas Maufer,Susanne Landers,Roxana Loza,Paul Blankinship 和 Betsy Beyer 一起
生产环境中的安全代理
总的来说,代理提供了一种解决新的可靠性和安全性要求的方法,而无需对已部署的系统进行重大更改。您可以简单地使用代理来路由本来直接到达系统的连接。代理还可以包括控件,以满足您的新安全性和可靠性要求。在本案例研究中,我们将研究谷歌使用的一组安全代理,以限制特权管理员在生产环境中意外或恶意引起问题的能力。
安全代理是一个框架,允许授权人员访问或修改物理服务器、虚拟机或特定应用程序的状态。在谷歌,我们使用安全代理来审查、批准和运行风险命令,而无需与系统建立 SSH 连接。使用这些代理,我们可以授予细粒度的访问权限以调试问题,或者可以限制机器重新启动的速率。安全代理代表网络之间的单个入口点,并且是使我们能够执行以下操作的关键工具:
-
审计舰队中的每个操作
-
控制对资源的访问
-
保护生产环境免受人为错误的影响
Zero Touch Prod是谷歌的一个项目,要求所有生产中的更改都由自动化(而不是人类)进行,经过软件预验证,或者通过经过审计的紧急机制触发。¹ 安全代理是我们用来实现这些原则的一组工具。我们估计,谷歌评估的所有故障中约 13%可以通过 Zero Touch Prod 预防或减轻。
在安全代理模型中,显示在图 3-1 中,客户端与目标系统直接交流,而是与代理交流。在谷歌,我们通过限制目标系统仅接受代理的调用来强制执行此行为。此配置指定了通过访问控制列表(ACL)可以由哪些客户端角色执行哪些应用层远程过程调用(RPC)。检查访问权限后,代理将请求发送到目标系统以通过 RPC 执行。通常,每个目标系统都有一个应用层程序,该程序接收请求并直接在系统上执行。代理记录与其交互的所有请求和命令。
我们发现使用代理来管理系统有多个好处,无论客户是人类、自动化还是两者兼而有之。代理提供以下功能:
-
强制执行多方授权(MPA)的中心点,²我们为与敏感数据交互的请求做出访问决策
-
管理使用审计,我们可以跟踪特定请求的执行时间和执行者
-
速率限制,例如系统重新启动逐渐生效,并且我们可能限制错误的影响范围
-
与闭源第三方目标系统兼容,我们通过代理的附加功能控制组件的行为(我们无法修改)
-
持续改进集成,我们在中央代理点添加安全性和可靠性增强功能

图 3-1:安全代理模型
代理也有一些缺点和潜在的陷阱:
-
成本增加,包括维护和运营开销。
-
单点故障,如果系统本身或其依赖项之一不可用。我们通过运行多个实例来减轻这种情况,以增加冗余性。我们确保我们系统的所有依赖项都具有可接受的服务级别协议(SLA),并且每个依赖项的运营团队都有记录的紧急联系人。
-
访问控制的策略配置本身可能是错误的来源。我们通过提供模板或自动生成默认安全设置来引导用户做出正确的选择。在创建这样的模板或自动化时,我们遵循第 II 部分中提出的设计策略。
-
对手可能控制的中央机器。上述策略配置要求系统转发客户端的身份并代表客户端执行任何操作。代理本身并不赋予高权限,因为没有请求是在代理角色下执行的。
-
对变化的抵抗,因为用户可能希望直接连接到生产系统。为了减少代理施加的摩擦,我们与工程师密切合作,确保他们在紧急情况下可以通过紧急机制访问系统。我们将在第二十一章中更详细地讨论这些话题。
由于安全代理的主要用例是添加与访问控制相关的安全性和可靠性功能,因此代理公开的接口应使用与目标系统相同的外部 API。因此,代理不会影响整体用户体验。假设安全代理是透明的,它可以在执行一些预处理和后处理进行验证和日志记录后简单地转发流量。下一节将讨论我们在谷歌使用的安全代理的一个具体实例。
谷歌工具代理
谷歌员工使用命令行界面(CLI)工具执行大部分管理操作。其中一些工具可能很危险,例如,某些工具可以关闭服务器。如果这样的工具指定了不正确的范围选择器,命令行调用可能会意外地停止几个服务前端,导致中断。跟踪每个 CLI 工具,确保它执行集中式日志记录,并确保敏感操作有进一步的保护将是困难且昂贵的。为了解决这个问题,谷歌创建了一个工具代理:一个公开通用 RPC 方法的二进制文件,通过 fork 和 exec 内部执行指定的命令行。所有调用都受到策略的控制,用于审计的日志记录,并具有要求 MPA 的能力。
使用工具代理实现了零接触生产的主要目标之一:通过不允许人员直接访问生产使生产更安全。工程师无法直接在服务器上运行任意命令;他们需要通过工具代理进行联系。
我们通过使用一组细粒度的策略来配置谁被允许执行哪些操作,这些策略执行 RPC 方法的授权。示例 3-1 中的策略允许group:admin的成员在group:admin-leads中的某人批准命令后运行borg CLI 的最新版本以及任何参数。工具代理实例通常作为 Borg 作业部署。
示例 3-1. 谷歌工具代理 Borg 策略
config = { proxy_role = 'admin-proxy' tools = { borg = { mpm = 'client@live' binary_in_mpm = 'borg' any_command = true allow = ['group:admin'] require_mpa_approval_from = ['group:admin-leads'] unit_tests = [{ expected = 'ALLOW' command = 'file.borgcfg up' }] } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
示例 3-1 中的策略允许工程师通过类似以下命令来从他们的工作站停止生产中的 Borg 作业:
$ tool-proxy-cli --proxy_address admin-proxy borg kill ...
- 1
该命令向指定地址的代理发送 RPC,这将启动以下事件链,如图 3-2 所示:
-
代理记录所有 RPC 和执行的检查,提供了审计先前运行的管理操作的简单方法。
-
代理检查策略,以确保调用者在
group:admin中。 -
由于这是一个敏感命令,MPA 被触发,代理等待
group:admin-leads中的人员授权。 -
如果获得批准,代理执行命令,等待结果,并将返回代码、stdout 和 stderr 附加到 RPC 响应。
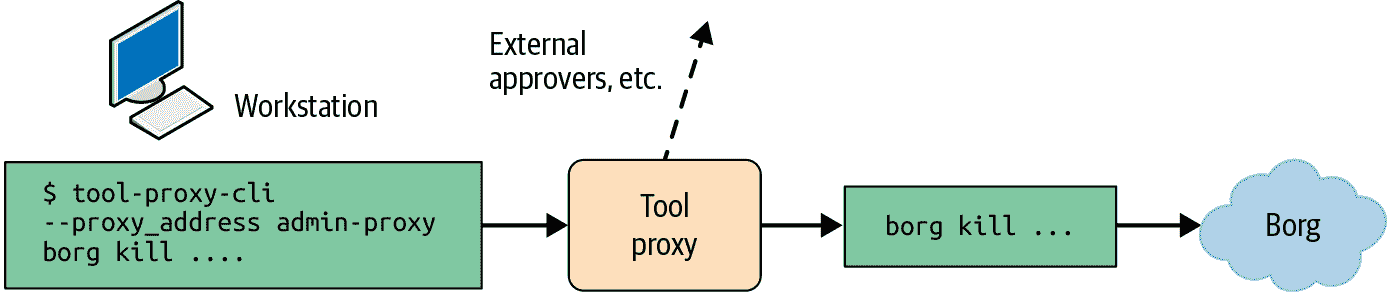
图 3-2:工具代理使用工作流程
工具代理需要对开发工作流程进行小的更改:工程师需要在他们的命令前加上 tool-proxy-cli --proxy_address。为了确保特权用户不会规避代理,我们修改了服务器,只允许对 admin-proxy 进行管理操作,并在非紧急情况下拒绝任何直接连接。
结论
使用安全代理是向系统添加日志记录和多方授权的一种方式。代理可以帮助使您的系统更安全、更可靠。这种方法可以是现有系统的一种经济有效的选择,但如果与第二部分中描述的其他设计原则配对使用,将会更加强大。正如我们在第四章中讨论的那样,如果您正在启动一个新项目,最好使用与日志记录和访问控制模块集成的框架来构建系统架构。
¹ 紧急情况机制是一种可以绕过策略以允许工程师快速解决故障的机制。参见“紧急情况”。
² 多方授权要求在允许操作发生之前,需要额外的用户批准。参见“多方授权(MPA)”。
第四章:设计权衡
译者:飞龙
由 Christoph Kern
与 Brian Gustafson,Paul Blankinship 和 Felix Gröbert 合作
所以你要构建一个(软件)产品!在这个复杂的旅程中,你会有很多事情要考虑,从制定高层计划到部署代码。
通常,你会对产品或服务要做什么有一个大致的想法。例如,这可能是一个游戏的高层概念,或者是基于云的生产力应用的高层业务需求。你还会制定关于服务提供方式的高层计划。
当你深入设计过程,对产品形状的想法变得更加具体时,对应用程序的设计和实现会出现额外的需求和约束。产品的功能性将有特定的需求,还有一般的约束,比如开发和运营成本。你还会遇到安全性和可靠性的需求和约束:你的服务可能会有一定的可用性和可靠性需求,你可能会有保护应用程序处理的敏感用户数据的安全性需求。
其中一些需求和约束可能会相互冲突,你需要做出权衡,并找到它们之间的平衡。
设计目标和需求
产品的功能需求往往具有与安全性和可靠性需求显着不同的特征。让我们更仔细地看看在设计产品时你将面临的需求类型。
功能需求
功能需求,也称为功能性需求,¹标识了服务或应用程序的主要功能,并描述了用户如何完成特定任务或满足特定需求。它们通常以用例、用户故事或用户旅程的形式表达——用户与服务或应用程序之间的交互序列。关键需求是功能需求的子集,对产品或服务至关重要。如果设计不满足关键需求或关键用户故事,那么你就没有一个可行的产品。
功能需求通常是你设计决策的主要驱动因素。毕竟,你正在尝试构建一个满足特定一组用户需求的系统或服务。你经常需要在各种需求之间做出权衡决策。考虑到这一点,区分关键需求和其他功能需求是有用的。
通常,许多需求适用于整个应用程序或服务。这些需求通常不会出现在用户故事或个别功能需求中。相反,它们在集中的需求文档中一次性陈述,甚至是隐含地假定。这里有一个例子:
应用程序的 Web UI 的所有视图/页面必须:
-
遵循常见的视觉设计指南
-
遵守无障碍指南
-
在页脚上加上链接,链接到隐私政策和服务条款(Terms of Service)
非功能性需求
几类需求关注的是系统的一般属性或行为,而不是特定的行为。这些非功能性需求与我们的关注——安全性和可靠性相关。例如:
-
在哪些独特的情况下,某人(外部用户、客户支持代理或运维工程师)可以访问某些数据?
-
对于诸如正常运行时间或 95th 百分位和 99th 百分位响应延迟等指标的服务水平目标(SLOs)是什么?系统在超过某个阈值的负载下如何响应?
在平衡要求时,同时考虑系统本身以外领域的要求可能会有所帮助,因为这些领域的选择可能会对核心系统要求产生重大影响。这些更广泛的领域包括以下内容:
开发效率和速度
考虑到所选择的实现语言、应用程序框架、测试流程和构建流程,开发人员能够多有效地迭代新功能吗?开发人员能够多有效地理解、修改或调试现有代码吗?
部署速度
从功能开发到该功能对用户/客户可用需要多长时间?
功能与紧急属性
功能要求通常在要求、满足这些要求的代码和验证实现的测试之间有着相当直接的联系。例如:
规范
用户故事或需求可能规定了应用程序的已登录用户如何查看和修改与其用户配置文件相关的个人数据(例如姓名和联系信息)。
实现
基于此规范的 Web 或移动应用程序通常会有与该要求非常相关的代码,例如以下内容:
-
结构化类型来表示配置文件数据
-
UI 代码来呈现和允许修改配置文件数据
-
服务器端 RPC 或 HTTP 操作处理程序从数据存储中查询已登录用户的配置文件数据,并接受要写入数据存储的更新信息
验证
通常会有一个集成测试,基本上逐步执行指定的用户故事。测试可能使用 UI 测试驱动程序填写并提交“编辑配置文件”表单,然后验证提交的数据是否出现在预期的数据库记录中。该用户故事的各个步骤可能还有单元测试。
相比之下,像可靠性和安全性要求这样的非功能性要求往往更难以确定。如果您的 Web 服务器有一个--enable_high_reliability_mode标志,而要使您的应用程序可靠,您只需要翻转该标志并支付您的托管或云提供商高级服务费就可以了。但是没有这样的标志,也没有任何应用程序源代码中“实现”可靠性的特定模块或组件。
例如:谷歌设计文档
谷歌使用设计文档模板来指导新功能设计,并在启动工程项目之前收集利益相关者的反馈意见。
与可靠性和安全性考虑相关的模板部分提醒团队考虑其项目的影响,并在适当的情况下启动生产准备或安全审查流程。设计审查有时会在工程师正式开始考虑启动阶段之前的多个季度进行。
平衡要求
由于满足安全性和可靠性要求的系统属性很大程度上是紧急属性,它们往往既与功能要求的实现相互作用,又与彼此相互作用。因此,很难单独推理涉及安全性和可靠性的权衡。
本节提供了一个示例,说明了您可能需要考虑的权衡。这个示例的一些部分深入到技术细节,这些细节本身并不一定重要。设计支付处理系统及其运作所涉及的所有合规性、监管、法律和商业考虑对于这个示例也不重要。相反,目的是说明要求之间复杂相互依赖的思维过程。换句话说,重点不是保护信用卡号的细枝末节,而是设计具有复杂安全性和可靠性要求的系统所需的思维过程。
示例:支付处理
想象一下,你正在构建一个在线服务,向消费者销售小部件。该服务的规范包括一个用户故事,规定用户可以通过使用移动或网络应用程序从在线目录中选择小部件。然后用户可以购买所选的小部件,这需要他们提供付款方式的详细信息。
安全性和可靠性考虑
接受付款信息会为系统的设计和组织流程引入重大的安全性和可靠性考虑。姓名、地址和信用卡号码是需要特殊保护的敏感个人数据,并且根据适用的司法管辖区,可能会使您的系统受到监管标准的约束。接受付款信息还可能使服务受到符合行业或监管安全标准(如 PCI DSS)的合规范围。
对这些敏感用户信息的妥协,尤其是个人可识别信息(PII),可能会对项目甚至整个组织/公司产生严重后果。您可能会失去用户和客户的信任,并因此失去他们的业务。近年来,立法机构已颁布了法律和法规,对受数据泄露影响的公司施加了可能耗时和昂贵的义务。一些公司甚至因严重的安全事件而完全倒闭,如第一章所述。
在某些情况下,产品设计层面的更高级别权衡可能会使应用程序摆脱处理支付的需求,例如,也许产品可以以基于广告或社区资助的模式重塑。对于我们的例子,我们将坚持接受付款是一个关键要求的前提。
使用第三方服务提供商处理敏感数据
通常,减轻对敏感数据的安全担忧的最佳方法是根本不保存这些数据(有关此主题的更多信息,请参见第五章)。您可以安排敏感数据永远不会通过您的系统,或者至少设计系统不会持久存储数据。您可以选择各种商业支付服务 API 与应用程序集成,并将支付信息、支付交易和相关问题(如欺诈对策)的处理外包给供应商。
好处
根据情况,使用支付服务可能会降低风险,并减少您需要在这一领域建立内部专业知识的程度,而是依赖供应商的专业知识:
-
您的系统不再保存敏感数据,减少了系统或流程中的漏洞可能导致数据泄露的风险。当然,第三方供应商的妥协仍可能危及您的用户数据。
-
根据具体情况和适用要求,您在支付行业安全标准下的合同和合规义务可能会简化。
-
您无需构建和维护基础设施来保护系统数据存储中的数据。这可能消除了大量的开发和持续运营工作。
-
许多第三方支付提供商提供对抗欺诈交易和支付风险评估服务。您可以使用这些功能来减少支付欺诈风险,而无需自行构建和维护基础设施。
另一方面,依赖第三方服务提供商会带来自己的成本和风险。
成本和非技术风险
显然,供应商将收取费用。交易量可能会影响你的选择 - 超过一定量后,可能更划算在内部处理交易。
你还需要考虑依赖第三方的工程成本:你的团队将不得不学习如何使用供应商的 API,并且你可能需要按照供应商的时间表跟踪 API 的更改/发布。
可靠性风险
通过外包支付处理,你为你的应用程序增加了一个额外的依赖关系 - 在这种情况下,是第三方服务。额外的依赖通常会引入额外的故障模式。在第三方依赖的情况下,这些故障模式可能部分地超出你的控制。例如,如果支付提供商的服务停机或通过网络无法访问,你的用户故事“用户可以购买他们选择的小部件”可能会失败。这种风险的重要性取决于你与该提供商的SLAs的遵守程度。
你可以通过在系统中引入冗余来解决这个风险(参见第八章) - 在这种情况下,通过添加备用支付提供商,你的服务可以切换到备用支付提供商。这种冗余引入了成本和复杂性 - 两个支付提供商很可能有不同的 API,因此你必须设计你的系统能够与两者通信,以及所有额外的工程和运营成本,以及增加对错误或安全妥协的暴露。
你也可以通过你自己的后备机制来减轻可靠性风险。例如,如果支付服务不可达,你可以在通信渠道与支付提供商中插入一个队列机制来缓冲交易数据。这样做将允许“购买流程”用户故事在支付服务中断期间继续进行。
然而,添加消息队列机制会引入额外的复杂性,并可能引入自己的故障模式。如果消息队列没有设计成可靠的(例如,它只在易失性内存中存储数据),你可能会丢失交易 - 这是一个新的风险。更一般地说,只在罕见和特殊情况下使用的子系统可能隐藏着隐藏的错误和可靠性问题。
你可以选择使用更可靠的消息队列实现。这可能涉及分布在多个物理位置的内存存储系统,再次引入复杂性,或者存储在持久性磁盘上。即使只在特殊情况下将数据存储在磁盘上,也会重新引入关于存储敏感数据(妥协风险、合规考虑等)的担忧,这正是你一开始想要避免的。特别是,一些支付数据甚至不允许命中磁盘,这使得依赖持久存储的重试队列难以应用在这种情况下。
在这种情况下,你可能需要考虑攻击(特别是内部人员的攻击),他们有意打破与支付提供商的联系,以激活交易数据的本地排队,然后可能被 compromise。
总之,你最终会遇到一个安全风险,这是由于你试图减轻可靠性风险而产生的,而这又是因为你试图减轻安全风险!
安全风险
依赖第三方服务的设计选择也立即引起了安全考虑。
首先,你正在把敏感的客户数据交给第三方供应商。你需要选择一个安全立场至少与你自己相等的供应商,并且必须在选择和持续评估供应商时进行仔细评估。这不是一项容易的任务,还有复杂的合同、监管和责任考虑因素,这些都超出了本书的范围,应该咨询你的法律顾问。
其次,与供应商服务集成可能需要您将供应商提供的库链接到您的应用程序中。这会带来一个风险,即该库中的漏洞,或者其传递依赖关系中的一个漏洞,可能导致您系统中的漏洞。您可以考虑通过对该库进行沙盒化⁵并准备快速部署更新版本来减轻这种风险(参见第七章)。您可以通过使用不需要您将专有库链接到您的服务中的供应商(参见第六章)来基本避免这种担忧。如果供应商使用像 REST+JSON、XML、SOAP 或 gRPC 这样的开放协议来公开其 API,那么可以避免使用专有库。
您可能需要在您的 Web 应用程序客户端中包含一个 JavaScript 库,以便与供应商集成。这样做可以避免通过您的系统传递付款数据,即使是暂时的——相反,付款数据可以直接从用户的浏览器发送到提供商的 Web 服务。然而,这种集成引发了与包含服务器端库类似的担忧:供应商的库代码在您应用程序的 Web 来源中以完全权限运行。⁶该代码的漏洞或者提供该库的服务器的妥协可能导致您的应用程序受到威胁。您可以考虑通过在单独的 Web 来源或沙箱 iframe 中对与付款相关的功能进行沙盒化来减轻这种风险。然而,这种策略意味着您需要一个安全的跨来源通信机制,这再次引入了复杂性和额外的故障模式。另外,付款供应商可能提供基于 HTTP 重定向的集成,但这可能导致用户体验不够流畅。
与非功能性需求相关的设计选择可能在领域特定技术专业知识领域产生相当深远的影响:我们开始讨论与处理付款数据相关的风险缓解相关的权衡,最终考虑到了深入到 Web 平台安全领域的考虑。在这个过程中,我们还遇到了合同和监管方面的问题。
管理紧张关系和调整目标
通过一些前期规划,您通常可以满足重要的非功能性需求,如安全性和可靠性,而无需放弃功能,并且成本合理。当回顾整个系统和开发运营工作流程的背景来考虑安全性和可靠性时,往往会发现这些目标与一般软件质量属性非常一致。
示例:微服务和谷歌 Web 应用程序框架
考虑谷歌内部微服务和 Web 应用程序框架的演变。创建该框架的团队的主要目标是简化大型组织的应用程序和服务的开发和运营。在设计这个框架时,团队融入了一个关键的想法,即应用静态和动态的符合性检查,以确保应用代码符合各种编码准则和最佳实践。例如,符合性检查验证在并发执行上下文之间传递的所有值都是不可变类型——这种做法极大地降低了并发错误的可能性。另一组符合性检查强制执行组件之间的隔离约束,这样就不太可能导致应用程序中一个组件的更改导致另一个组件中的错误。
因为基于这个框架构建的应用程序具有相当严格和明确定义的结构,所以该框架可以为许多常见的开发和部署任务提供开箱即用的自动化功能——从新组件的脚手架搭建,到持续集成(CI)环境的自动设置,再到大部分自动化的生产部署。这些优势使得这个框架在谷歌开发人员中非常受欢迎。
所有这些与安全性和可靠性有什么关系?该框架开发团队在设计和实现阶段与 SRE 和安全团队合作,确保安全性和可靠性最佳实践被编织到框架的结构中,而不是在最后才添加。该框架负责处理许多常见的安全性和可靠性问题。同样,它还自动设置了操作指标的监控,并整合了可靠性功能,如健康检查和 SLA 合规性。
例如,该框架的 Web 应用程序支持处理了大多数常见类型的 Web 应用程序漏洞。通过 API 设计和代码符合性检查的结合,它有效地防止开发人员在应用程序代码中意外引入许多常见类型的漏洞。就这些类型的漏洞而言,该框架不仅仅是“默认安全性”,而是全面负责安全,并积极确保基于它的任何应用程序不受这些风险的影响。我们将在第六章和第十二章中更详细地讨论这是如何实现的。
对新出现的属性要求进行对齐
该框架示例说明,与常见看法相反,与其他产品目标(尤其是代码和项目健康、可维护性和长期持续的项目速度)相关的安全性和可靠性目标通常是很好对齐的。相比之下,试图作为后期附加的方式来追加安全性和可靠性目标通常会导致增加风险和成本。
安全性和可靠性的优先级也可以与其他领域的优先级对齐:
-
正如在第六章中讨论的那样,使人们能够有效和准确地推理系统的不变量和行为对于安全性和可靠性至关重要。可理解性也是代码和项目健康属性的关键,也是开发速度的关键支持:一个可理解的系统更容易调试和修改(而不会在一开始引入错误)。
-
设计用于恢复(见第九章)使我们能够量化和控制由变更和部署引入的风险。通常,这里讨论的设计原则支持更高的变更速度(即部署速度),这是我们以其他方式无法实现的。
-
安全性和可靠性要求我们设计一个不断变化的环境(见第七章)。这样做使我们的系统设计更具适应性,不仅能迅速应对新出现的漏洞和攻击场景,还能更快地适应不断变化的业务需求。
初始速度与持续速度
特别是在较小的团队中,有一种自然倾向,即将安全性和可靠性问题推迟到将来的某个时间点(“等我们有了一些客户后,我们会加入安全性并担心扩展问题”)。团队通常会以“速度”为借口,忽视安全性和可靠性作为早期和主要的设计驱动因素,他们担心花时间思考和解决这些问题会减慢开发速度,并在首次发布周期中引入不可接受的延迟。
重要的是要区分初始速度和持续速度。选择不考虑安全、可靠性和可维护性等关键要求可能确实会增加项目在项目生命周期早期的速度。然而,经验表明,这样做通常也会在项目后期显著减速。在项目周期后期进行大规模修改以满足作为新兴属性出现的要求的成本可能非常高。此外,为了解决安全和可靠性风险而进行侵入性的后期更改本身可能会引入更多的安全和可靠性风险。因此,早期将安全和可靠性融入团队文化非常重要。
互联网的早期历史和 IP、TCP、DNS 和 BGP 等基础协议的设计和演变,为这个话题提供了有趣的视角。可靠性——特别是在节点故障的情况下网络的生存能力以及在容易出现故障的链路上通信的可靠性——是早期互联网的早期前身,如 ARPANET 的明确和高优先级的设计目标。
然而,在早期的互联网论文和文档中并没有多少提到安全。早期的网络基本上是封闭的,由受信任的研究和政府机构操作节点。但在今天的开放互联网中,这种假设根本不成立——许多类型的恶意行为者参与了网络。
互联网的基础协议——IP、UDP 和 TCP——没有规定对传输发起者进行身份验证,也没有检测网络中间节点对数据的故意恶意修改。许多更高级的协议,如 HTTP 或 DNS,天生就容易受到网络中恶意参与者的各种攻击。随着时间的推移,已经开发了安全协议或协议扩展来抵御此类攻击。例如,HTTPS 通过在经过身份验证的安全通道上传输数据来增强 HTTP。在 IP 层,IPsec 通过加密对网络级对等体进行身份验证,并提供数据完整性和保密性。IPsec 可用于在不受信任的 IP 网络上建立 VPN。
然而,广泛部署这些安全协议已被证明相当困难。我们现在大约已经进入互联网历史的第 50 年,互联网的重要商业用途可能始于 25 或 30 年前,但仍有相当大比例的网络流量不使用 HTTPS。
另一个关于初始和持续速度之间权衡的例子(在这种情况下来自安全和可靠性领域之外),请考虑敏捷开发流程。敏捷开发工作流的主要目标是增加开发和部署速度,特别是减少功能规范和部署之间的延迟。然而,敏捷工作流通常依赖于相当成熟的单元和集成测试实践以及稳固的持续集成基础设施,这需要前期投资来建立,以换取长期的速度和稳定性。
更一般地,您可以选择将初始项目速度置于一切之上——您可以开发 Web 应用的第一个迭代而不进行测试,并且发布过程相当于将 tarballs 复制到生产主机。您可能会相对快速地完成第一个演示,但到第三个发布时,您的项目很可能会拖后腿,并且负担着技术债务。
我们已经提到了可靠性和速度之间的一致性:投资于成熟的持续集成/持续部署(CI/CD)工作流和基础设施支持频繁的生产发布,同时管理和接受可靠性风险(参见第七章)。但是设置这样的工作流需要一些前期投资——例如,你将需要以下内容:
-
足够健壮的单元和集成测试覆盖率,以确保生产发布的缺陷风险可接受,而不需要进行主要的人工发布资格工作
-
本身可靠的 CI/CD 流水线
-
经常使用的、可靠的基础设施,用于分阶段的生产发布和回滚
-
允许代码和配置的解耦部署的软件架构(例如,“功能标志”)
这种投资在产品生命周期的早期进行时通常是适度的,而且只需要开发人员持续付出一些增量努力来保持良好的测试覆盖率和持续构建的“绿色”。相比之下,具有较差的测试自动化、依赖于部署中的手动步骤和长周期发布的开发工作流往往会在项目变得复杂时最终拖慢项目的速度。在那时,为成熟系统添加测试和发布自动化往往需要一次性进行大量工作,可能会进一步减慢项目的速度。此外,为成熟系统添加的测试有时会陷入陷阱,更多地测试当前存在的错误行为而不是正确的预期行为。
这些投资对各种规模的项目都是有益的。然而,较大的组织可以享受更多规模效益,因为你可以将成本分摊到许多项目中——一个单独项目的投资最终归结为承诺使用集中维护的框架和工作流程。
在做出专注于安全的设计选择以促进持续速度时,我们建议选择一个框架和工作流,提供针对相关漏洞类别的构造安全防御。这种选择可以大大减少甚至消除在应用程序代码库的持续开发和维护过程中引入此类漏洞的风险(参见第6 章和12 章)。这种承诺通常不需要重大的前期投资——相反,它需要持续的、通常是适度的努力来遵守框架的约束。作为回报,你大大降低了系统意外停机或安全响应火灾演习对部署计划造成混乱的风险。此外,你的发布时安全性和生产准备审查更有可能顺利进行。
结论
设计和构建安全可靠的系统并不容易,特别是因为安全性和可靠性主要是整个开发和运营工作流的新兴属性。这项工作涉及思考许多相当复杂的主题,其中许多起初似乎与解决服务的主要功能要求并不那么相关。
你的设计过程将涉及安全性、可靠性和功能要求之间的许多权衡。在许多情况下,这些权衡起初似乎是直接冲突的。在项目的早期阶段避开这些问题可能会很诱人,然后“以后再处理”——但这样做往往会对项目造成重大的成本和风险:一旦你的服务上线,可靠性和安全性就不是可选的。如果你的服务中断,你可能会失去业务;如果你的服务受到损害,应对将需要全员出动。但通过良好的规划和谨慎的设计,通常可以满足这三个方面。更重要的是,你可以在较少的额外前期成本和通常减少系统寿命内的总工程工作量的情况下做到这一点。
¹ For a more formal treatment, see The MITRE Systems Engineering Guide and ISO/IEC/IEEE 29148-2018(E).
² For the purposes of the example, it’s not relevant what exactly is being sold—a media outlet might require payments for articles, a mobility company might require payments for transportation, an online marketplace might enable the purchase of physical goods that are shipped to consumers, or a food-ordering service might facilitate the delivery of takeout orders from local restaurants.
³ See, for example, McCallister, Erika, Tim Grance, and Karen Scarfone. 2010. NIST Special Publication 800-122, “Guide to Protecting the Confidentiality of Personally Identifiable Information (PII).” https://oreil.ly/T9G4D.
⁴ Note that whether or not this is appropriate may depend on regulatory frameworks your organization is subject to; these regulatory matters are outside the scope of this book.
⁵ See, e.g., the Sandboxed API project.
⁶ For more on this subject, see Zalewski, Michał. 2011. The Tangled Web: A Guide to Securing Modern Web Applications. San Francisco, CA: No Starch Press.
⁷ See, e.g., the OWASP Top 10 and CWE/SANS TOP 25 Most Dangerous Software Errors.
⁸ See Kern, Christoph. 2014. “Securing the Tangled Web.” Communications of the ACM 57(9): 38–47. doi:10.1145/2643134.
⁹ At Google, software is typically built from the HEAD of a common repository, which causes all dependencies to be updated automatically with every build. See Potvin, Rachel, and Josh Levenberg. 2016. “Why Google Stores Billions of Lines of Code in a Single Repository.” Communications of the ACM 59(7): 78–87. https://oreil.ly/jXTZM.
¹⁰ See the discussion of tactical programming versus strategic programming in Ousterhout, John. 2018. A Philosophy of Software Design. Palo Alto, CA: Yaknyam Press. Martin Fowler makes similar observations.
¹¹ See RFC 2235 and Leiner, Barry M. et al. 2009. “A Brief History of the Internet.” ACM SIGCOMM Computer Communication Review 39(5): 22–31. doi:10.1145/1629607.1629613.
¹² Baran, Paul. 1964. “On Distributed Communications Networks.” IEEE Transactions on Communications Systems 12(1): 1–9. doi:10.1109/TCOM.1964.1088883.
¹³ Roberts, Lawrence G., and Barry D. Wessler. 1970. “Computer Network Development to Achieve Resource Sharing.” Proceedings of the 1970 Spring Joint Computing Conference: 543–549. doi:10.1145/1476936.1477020.
¹⁴ 费尔特,阿德里安·波特,理查德·巴恩斯,艾普里尔·金,克里斯·帕尔默,克里斯·本策尔和帕里萨·塔布里兹。2017 年。 “测量网络上的 HTTPS 采用情况。” 第 26 届 USENIX 安全研讨会论文集:1323–1338。https://oreil.ly/G1A9q。
第五章:面向最小特权的设计
原文:5. Design for Least Privilege
译者:飞龙
作者:Oliver Barrett,Aaron Joyner 和 Rory Ward
与 Guy Fischman 和 Betsy Beyer 合著
公司通常希望假设他们的工程师有最好的意图,并依赖他们无缺地执行艰巨的任务。这不是一个合理的期望。作为一种思考练习,想想如果你想做一些邪恶的事情,你可以对你的组织造成什么样的伤害。你能做什么?你会怎么做?你会被发现吗?你能掩盖你的踪迹吗?或者,即使你的意图是好的,你(或具有等效访问权限的人)可能犯下的最严重错误是什么?在调试、应对故障或执行紧急响应时,你或你的同事使用的多少临时手动命令离造成或加剧故障只有一个打字错误或复制粘贴失败的距离?
因为我们不能依赖人类的完美,我们必须假设任何可能的坏行为或结果都可能发生。因此,我们建议设计系统以最小化或消除这些坏行为的影响。
即使我们通常信任访问我们系统的人类,我们也需要限制他们的特权和我们对他们凭证的信任。事情可能会出错。人们会犯错,误操作命令,被攻击,上当受骗。期望完美是不现实的假设。换句话说,引用 SRE 的格言——希望不是一种策略。
概念和术语
在我们深入探讨设计和操作访问控制系统的最佳实践之前,让我们为行业和谷歌使用的一些特定术语建立工作定义。
最小特权
最小特权是安全行业中已经确立的一个广泛概念。本章的高级最佳实践可以为系统奠定为任何特定任务或行动路径授予最小特权的基础。这一目标适用于分布式系统包括的人类、自动化任务和个别机器。最小特权的目标应该贯穿系统的所有身份验证和授权层。特别是,我们推荐的方法拒绝将隐含的权限扩展给工具(如“工作示例:配置分发”中所示),并努力确保用户尽可能不具有环境权限——例如,以 root 用户登录的能力。
零信任网络
我们讨论的设计原则始于零信任网络——即用户的网络位置(在公司网络内)不授予任何特权访问的概念。例如,在会议室的网络端口插入并不比在互联网其他地方连接获得更多访问权限。相反,系统基于用户凭证和设备凭证的组合来授予访问权限——我们对用户和设备的了解。谷歌通过其BeyondCorp 计划成功实现了大规模的零信任网络模型。
零接触
谷歌的 SRE 组织正在努力通过自动化来建立在最小特权概念之上,目标是实现我们所称的零接触接口。这些接口的具体目标——比如第三章中描述的零接触生产(ZTP)和零信任网络(ZTN)——是通过工具和自动化使谷歌更安全,减少故障,从而消除人类对生产角色的直接访问。这种方法需要大量的自动化、新的安全 API 和弹性的多方批准系统。
基于风险分类访问
任何风险降低策略都伴随着权衡。减少人为因素引入的风险可能需要额外的控制或工程工作,并可能会对生产力产生权衡;它可能会增加工程时间,流程变更,运营工作或机会成本。您可以通过明确定义和优先考虑您想要保护的内容来限制这些成本。
并非所有数据或操作都是平等的,您的访问组成可能会根据系统的性质而有很大不同。因此,您不应该以相同程度保护所有访问。为了应用最合适的控制措施并避免全有或全无的心态,您需要根据影响,安全风险和/或重要性对访问进行分类。例如,您可能需要以不同方式处理对不同类型数据(公开可用数据与公司数据与用户数据与加密密钥)的访问。同样,您可能需要以不同方式处理可以删除数据的管理 API 与特定服务的读取 API。
您的分类应该清晰定义,一贯应用,并广泛理解,以便人们可以设计“讲”这种语言的系统和服务。您的分类框架将根据系统的大小和复杂性而变化:您可能只需要依赖临时标记的两种或三种类型,或者您可能需要一个强大和程序化的系统来对系统的部分(API 分组,数据类型)进行分类。这些分类可能适用于用户在工作过程中可能访问的数据存储,API,服务或其他实体。确保您的框架可以处理系统中最重要的实体。
一旦您建立了分类的基础,您应该考虑每个分类中的控制措施。您需要考虑几个方面:
-
谁应该有访问权限?
-
该访问应该受到多大程度的控制?
-
用户需要什么类型的访问(读/写)?
-
基础设施控制措施是什么?
例如,如表 5-1 所示,一家公司可能需要三种分类:公开,敏感和高度敏感。该公司可能会根据访问如果被不当授予可能造成的损害程度,将安全控制分类为低风险,中风险或高风险。
表 5-1。基于风险的访问分类示例
| 描述 | 读取访问 | 写入访问 | 基础设施访问ᵃ | |
|---|---|---|---|---|
| 公开 | 对公司内任何人开放 | 低风险 | 低风险 | 高风险 |
| 敏感 | 仅限于具有业务目的的群体 | 中/高风险 | 中风险 | 高风险 |
| 高度敏感 | 无永久访问 | 高风险 | 高风险 | 高风险 |
| ᵃ 绕过正常访问控制的管理能力。例如,减少日志级别,更改加密要求,获得对机器的直接 SSH 访问,重新启动和重新配置服务选项,或以其他方式影响服务的可用性。 |
您的目标应该是构建一个访问框架,从中您可以应用适当的控制,以实现生产力,安全性和可靠性的正确平衡。最小特权应该适用于所有数据访问和操作。基于这个基础框架,让我们讨论如何设计具有最小特权原则和控制的系统。
最佳实践
在实现最小特权模型时,我们建议遵循这里详细介绍的几项最佳实践。
小型功能 API
使每个程序都做一件事情。要做一项新工作,最好重新构建,而不是通过添加新的“功能”来使旧程序变得复杂。
——McIlroy, Pinson, and Tague (1978)¹
正如这句引语所传达的,Unix 文化的核心是围绕着可以组合的小而简单的工具。因为现代分布式计算是从 20 世纪 70 年代的单一时间共享计算系统发展而来的,演变成了全球范围内连接的分布式系统,所以作者的建议在 40 多年后仍然是正确的。为了适应当前的计算环境,人们可能会说,“让每个 API 端点都做好一件事。”在构建系统时,要考虑安全性和可靠性,避免开放式的交互式接口,而是设计小型的功能性 API。这种方法使您能够应用最小权限的经典安全原则,并授予执行特定功能所需的最低权限。
我们所说的API究竟是什么意思?每个系统都有一个 API:它只是系统呈现的用户界面。有些 API 非常大(比如 POSIX API 或 Windows API),有些相对较小(比如 memcached 和 NATS),有些非常小(比如 World Clock API、TinyURL 和 Google Fonts API)。当我们谈论分布式系统的 API 时,我们只是指您可以查询或修改其内部状态的所有方式的总和。API 设计在计算文献中已经得到很好的覆盖;本章重点介绍如何通过暴露具有少量明确定义基元的 API 端点来设计和安全地维护安全系统。例如,您评估的输入可能是对唯一 ID 的 CRUD(创建、读取、更新和删除)操作,而不是接受编程语言的 API。
除了面向用户的 API,还要特别关注管理 API。管理 API 对于应用程序的可靠性和安全性同样重要(可以说更重要)。在使用这些 API 时出现拼写错误和错误可能导致灾难性的中断或暴露大量数据。因此,管理 API 也是恶意行为者最感兴趣的攻击面之一。
管理 API 只能由内部用户和工具访问,因此相对于面向用户的 API,它们可能更快速和更容易更改。然而,一旦内部用户和工具开始构建任何 API,更改它仍然会有成本,因此我们建议仔细考虑其设计。管理 API 包括以下内容:
-
设置/拆卸 API,例如用于构建、安装和更新软件或提供其运行的容器的 API
-
维护和紧急 API,例如管理访问以删除损坏的用户数据或状态,或重新启动行为不端的进程
在访问和安全性方面,API 的大小是否重要?考虑一个熟悉的例子:POSIX API,这是我们之前提到的一个非常大的 API。这个 API 很受欢迎,因为它灵活并且为许多人所熟悉。作为一个生产机器管理 API,它通常用于相对明确定义的任务,比如安装软件包、更改配置文件或重新启动守护进程。
用户通常通过交互式的 OpenSSH 会话或使用针对 POSIX API 的脚本工具执行传统的 Unix 主机设置和维护。这两种方法都向调用者公开整个 POSIX API。在交互式会话期间难以限制和审计用户的操作。特别是如果用户恶意尝试规避控制,或者连接的工作站受到损害。
您可以使用各种机制来限制通过 POSIX API 授予用户的权限¹⁰,但这是暴露非常庞大的 API 的基本缺陷。相反,最好将这个庞大的管理 API 减少和分解成更小的部分。然后,您可以遵循最小权限原则,仅授予特定调用者所需的特定操作的权限。
注意
暴露的 POSIX API 不应与 OpenSSH API 混淆。可以利用 OpenSSH 协议及其身份验证、授权和审计(AAA)控件,而无需暴露整个 POSIX API;例如,使用git-shell。
紧急功能
以火警拉环的名字命名,指示用户“在紧急情况下打破玻璃”的紧急功能机制在紧急情况下提供对系统的访问,并完全绕过您的授权系统。这对于从意想不到的情况中恢复很有用。有关更多上下文,请参见“优雅失败和紧急功能机制”和“诊断访问拒绝”。
审计
审计主要用于检测错误的授权使用。这可能包括恶意系统操作员滥用其权力,外部参与者窃取用户凭据,或者恶意软件对另一个系统采取意外行动。您对审计和有意义地检测噪音中的信号的能力在很大程度上取决于您审计的系统的设计:
-
访问控制决策的粒度有多大,或者是否被绕过?(什么?在哪里?)
-
您能清楚地捕获与请求相关的元数据吗?(谁?何时?为什么?)
以下提示将有助于制定健全的审计策略。最终,您的成功也将取决于与审计相关的文化。
收集良好的审计日志
使用小型功能 API(如“小型功能 API”中讨论的)对您的审计能力提供了最大的单一优势。最有用的审计日志捕获了一系列细粒度的操作,例如“推送了一个带有密码哈希 123DEAD…BEEF456 的配置”或“执行了<x>命令”。考虑如何向客户显示和证明您的管理操作也有助于使您的审计日志更具描述性,从而在内部更有用。细粒度的审计日志信息使您能够对用户执行或未执行的操作做出强有力的断言,但一定要专注于捕获有用部分的操作。
特殊情况需要特殊访问权限,这需要强大的审计文化。如果您发现现有的小型功能 API 界面不足以恢复系统,您有两个选择:
-
提供紧急功能,允许用户打开与强大且灵活的 API 的交互式会话。
-
允许用户以一种无法合理审计其使用情况的方式直接访问凭据。
在这两种情况下,您可能无法构建粒度细致的审计跟踪。记录用户打开与大型 API 的交互式会话并不能有意义地告诉您他们做了什么。一个有动机和知识的内部人员可以轻松地绕过许多捕获交互式会话的会话日志的解决方案,例如记录 bash 命令历史。即使您可以捕获完整的会话记录,有效地审计它可能会非常困难:使用 ncurses 的可视应用程序需要重播才能被人类读取,并且诸如 SSH 多路复用之类的功能可能进一步复杂化捕获和理解交织状态。
对过于宽泛的 API 和/或频繁的紧急访问的解药是培养重视仔细审计的文化。这对可靠性和安全性都至关重要,你可以利用这两种动机来吸引负责任的人。两双眼睛有助于避免拼写错误和错误,你应该始终防范对用户数据的单方面访问。
最终,建立管理 API 和自动化的团队需要以促进审计的方式设计它们。经常访问生产系统的人应该有动力共同解决这些问题,并理解良好审计日志的价值。如果没有文化的强化,审计可能会变成橡皮图章,而紧急访问可能会变成每天的事情,失去了其重要性或紧迫性。文化是确保团队选择、构建和使用支持审计的系统的关键;这些事件只会偶尔发生;审计事件得到应有的审查。
选择审计员
一旦你收集了一个良好的审计日志,你需要选择合适的人来检查(希望是罕见的)记录事件。审计员需要具有正确的上下文和正确的目标。
在上下文方面,审计员需要知道特定操作的作用,最好知道执行该操作的原因。因此,审计员通常会是一个队友、经理或熟悉需要执行该操作的工作流程的人。你需要在充分的上下文和客观性之间取得平衡:虽然内部审查员可能与生成审计事件的人有密切的个人关系和/或希望组织取得成功,但外部私人审计员可能希望继续受雇于一个组织。
选择具有正确目标的审计员取决于审计的目的。在谷歌,我们进行两种广泛的审计:
-
审计以确保遵循最佳实践
-
审计以识别安全漏洞
一般来说,“最佳实践”审计支持我们的可靠性目标。例如,一个 SRE 团队可能会选择在每周团队会议期间审计上周的紧急访问事件。这种做法提供了一种文化上的同行压力,以使用和改进更小的服务管理 API,而不是使用紧急使用 API 来访问更灵活的紧急使用 API。广泛范围的紧急访问通常会绕过一些或全部安全检查,使服务面临更高的人为错误风险。
谷歌通常将紧急访问审查下放到团队级别,这样我们就可以利用伴随团队审查的社会规范。进行审查的同行具有上下文,使他们能够发现即使是伪装得很好的行为,这对于防止内部滥用和阻止恶意内部人员至关重要。例如,同事很容易注意到如果一个同事反复使用紧急访问操作来访问一个他们可能实际上并不需要的不寻常资源。这种团队审查还有助于发现管理 API 的不足。当特定任务需要紧急访问时,通常表明需要提供一种更安全或更安全的方式来执行该任务作为正常 API 的一部分。您可以在第二十一章中阅读更多关于这个主题的内容。
在谷歌,我们倾向于集中第二类审计,因为识别外部安全漏洞有利于对组织的广泛视野。一个高级攻击者可能会侵入一个团队,然后利用该访问来侵入另一个团队、服务或角色。每个单独的团队可能不会注意到一些异常的行为,并且没有跨团队的视野来连接不同的行为集。
中央审计团队也可以配备额外的信号和添加代码以进行额外的审计事件,这些事件可能并不广为人知。这些类型的警报在早期检测中可能特别有用,但您可能不希望广泛共享其实现细节。您可能还需要与组织中的其他部门(如法律和人力资源)合作,以确保审计机制是适当的、范围适当的并且有文档记录。
我们在谷歌使用结构化理由将审计日志事件与结构化数据关联起来。当发生生成审计日志的事件时,我们可以将其与结构化引用(例如 bug 编号、工单编号或客户案例编号)关联起来。这样做可以让我们构建审计日志的程序检查。例如,如果支持人员查看客户的付款详情或其他敏感数据,他们可以将这些数据与特定客户案例相关联。因此,我们可以确保观察到的数据属于开启案例的客户。如果我们依赖自由文本字段,要自动化日志验证将会更加困难。结构化理由对于扩展我们的审计工作至关重要,它为中央审计团队提供了关键的上下文,对于有效的审计和分析至关重要。
测试和最小权限
适当的测试是任何良好设计系统的基本属性。测试在最小权限方面有两个重要的维度:
-
最小权限的测试,以确保访问仅被正确授予必要的资源
-
最小权限的测试,以确保测试基础设施只具有其所需的访问权限
最小权限的测试
在最小权限的背景下,您需要能够测试明确定义的用户配置文件(例如,数据分析师、客户支持、SRE)是否具有足够的权限来执行其角色,但不会过多。
您的基础设施应该让您做到以下几点:
-
描述特定用户配置文件在其工作角色中需要能够做什么。这定义了他们在角色中所需的最小访问权限(API 和数据)以及访问类型(读或写,永久或临时)。
-
描述一组场景,在这些场景中,用户配置文件尝试在您的系统上执行操作(例如读取、批量读取、写入、删除、批量删除、管理),并描述对您的系统的预期结果/影响。
-
运行这些场景,并将实际结果/影响与预期结果/影响进行比较。
理想情况下,为了防止对生产系统产生不利影响,这些测试应该在代码或 ACL 更改之前运行。如果测试覆盖不完整,您可以通过监控访问和警报系统来减轻过于广泛的访问。
最小权限的测试
测试应该允许您验证预期的读/写行为,而不会危及服务的可靠性、敏感数据或其他关键资产。但是,如果您没有适当的测试基础设施,即考虑到各种环境、客户端、凭证、数据集等的基础设施,那么需要读/写数据或改变服务状态的测试可能会带来风险。
考虑将配置文件推送到生产环境的示例,我们将在下一节中返回到这个示例。在为此配置推送设计测试策略的第一步是提供一个使用自己凭证的单独环境。这样的设置可以确保在编写或执行测试时出现错误不会影响生产环境,例如覆盖生产数据或使生产服务崩溃。
或者,假设您正在开发一个键盘应用程序,允许用户一键发布表情包。您希望分析用户的行为和历史,以便自动推荐表情包。如果缺乏适当的测试基础设施,您需要在生产环境中给数据分析师读/写访问权限,以执行分析和测试。
适当的测试方法应考虑限制用户访问和降低风险的方式,但仍允许数据分析师执行他们需要完成工作的测试。他们需要写入权限吗?您可以使用匿名化的数据集来执行他们需要执行的任务吗?您可以使用测试账户吗?您可以在具有匿名化数据的测试环境中操作吗?如果此访问受到威胁,哪些数据会被暴露?
您可以通过从小处开始来处理测试基础设施——不要让完美成为良好的敌人。首先考虑您最容易实现的方式
-
分离环境和凭证
-
限制访问类型
-
限制数据的暴露
最初,也许您可以在云平台上快速进行短暂的测试,而不是构建整个测试基础设施堆栈。一些员工可能只需要读取或临时访问。在某些情况下,您还可以使用代表性或匿名化的数据集。
虽然这些测试最佳实践在理论上听起来很棒,但在这一点上,您可能会被构建适当的测试基础设施的潜在成本所压倒。做对这件事并不便宜。然而,请考虑没有适当的测试基础设施的成本:您能确定每次关键操作的测试不会导致生产中断吗?您能接受数据分析师具有本来可以避免的访问敏感数据的特权吗?您是否依赖于完美的人类和完美执行的完美测试?
对于您特定的情况,进行适当的成本效益分析非常重要。最初构建“理想”解决方案可能并不合理。但是,请确保您构建的框架会被人们使用。人们需要进行测试。如果您没有提供足够的测试框架,他们将在生产环境中进行测试,绕过您制定的控制措施。
诊断访问拒绝
在一个复杂的系统中,最小权限被强制执行,客户必须通过第三方因素、多方授权或其他机制(见“高级控制”)来赢得信任,策略在多个级别和细粒度上被执行。因此,策略拒绝也可能以复杂的方式发生。
考虑一个理智的安全策略正在执行的情况,您的授权系统拒绝访问。可能会出现三种可能的结果之一:
-
客户被正确拒绝,您的系统行为正确。最小权限已被执行,一切都很好。
-
客户被正确拒绝,但可以使用高级控制(如多方授权)来获得临时访问。
-
客户认为他们被错误拒绝了,并可能向您的安全策略团队提交支持工单。例如,如果客户最近被从授权组中移除,或者策略以微妙或可能不正确的方式发生了变化,这可能会发生。
在所有情况下,呼叫者对拒绝的原因一无所知。但系统是否可以向客户提供更多信息?根据呼叫者的权限级别,它可以。
如果客户端没有或权限非常有限,拒绝应该保持盲目 - 您可能不希望暴露 403 访问被拒绝错误代码(或其等效),因为有关拒绝原因的详细信息可能被利用以获取有关系统的信息,甚至找到获得访问权限的方法。但是,如果调用者具有某些最低权限,您可以提供与拒绝相关联的令牌。调用者可以使用该令牌调用高级控件以获取临时访问权限,或通过支持渠道将令牌提供给安全策略团队,以便他们用于诊断问题。对于更具特权的调用者,您可以提供与拒绝相关联的令牌和一些纠正信息。然后,调用者可以尝试自行纠正,然后再调用支持渠道。例如,调用者可能会得知访问被拒绝是因为他们需要成为特定组的成员,然后他们可以请求访问该组。
在公开多少纠正信息和安全策略团队可以处理多少支持负载之间总会存在紧张关系。但是,如果您公开了太多信息,客户端可能能够从拒绝信息中重新设计策略,从而使恶意行为者更容易制定使用策略的请求的方式。考虑到这一点,我们建议在实现零信任模型的早期阶段,您使用令牌,并要求所有客户端调用支持渠道。
优雅的失败和破玻璃机制
理想情况下,您总是在处理一个实现合理策略的工作授权系统。但实际上,您可能会遇到导致大规模访问拒绝的场景(可能是由于糟糕的系统更新)。作为回应,您需要能够通过破玻璃机制绕过授权系统,以便您可以修复它。
在使用破玻璃机制时,请考虑以下准则:
-
使用破玻璃机制的能力应受到严格限制。通常情况下,它应仅对负责系统运行 SLA 的 SRE 团队可用。
-
零信任网络的破玻璃机制应仅在特定位置可用。这些位置是您的恐慌室,具有额外物理访问控制的特定位置,以抵消其连接性所放置的增加信任。 (细心的读者会注意到,零信任网络的备用机制是不信任网络位置的策略,实际上是信任网络位置,但具有额外的物理访问控制。)
-
所有使用破玻璃机制的情况都应受到密切监控。
-
破玻璃机制应该由负责生产服务的团队定期测试,以确保在需要时它能正常运行。
当成功利用破玻璃机制使用户恢复访问权限时,您的 SREs 和安全策略团队可以进一步诊断和解决潜在问题。第八章和第九章讨论了相关策略。
工作示例:配置分发
让我们来看一个现实世界的例子。将配置文件分发给一组 Web 服务器是一个有趣的设计问题,可以通过一个小型的功能 API 实际实现。管理配置文件的最佳实践是:
-
将配置文件存储在版本控制系统中。
-
对文件进行代码审查更改。
-
首先自动将配置文件分发给一组金丝雀,对金丝雀进行健康检查,然后在逐渐将文件推送到 Web 服务器群中继续对所有主机进行健康检查。这一步需要授予自动化访问权限以远程更新配置文件。
有许多方法可以公开一个小型 API,每种方法都针对更新 Web 服务器配置的功能进行了定制。表 5-2 总结了您可能考虑的一些 API 及其权衡。接下来的部分将更深入地解释每种策略。
表 5-2. 更新 Web 服务器配置的 API 及其权衡
| 通过 OpenSSH 的 POSIX API | 软件更新 API | 自定义 OpenSSH ForceCommand | 自定义 HTTP 接收器 | |
|---|---|---|---|---|
| API 表面 | 大 | 各种 | 小 | 小 |
| 现有的ᵃ | 可能 | 是 | 不太可能 | 不太可能 |
| 复杂性 | 高 | 高 | 低 | 中等 |
| 可扩展性 | 中等 | 中等,但可重复使用 | 困难 | 中等 |
| 可审计性 | 差 | 好 | 好 | 好 |
| 可以表达最小特权 | 差 | 各种 | 好 | 好 |
| ᵃ 这表明您已经拥有或不太可能拥有这种类型的 API 作为现有 Web 服务器部署的一部分。 |
通过 OpenSSH 的 POSIX API
您可以允许自动化通过 OpenSSH 连接到 Web 服务器主机,通常以 Web 服务器运行的本地用户身份连接。然后,自动化可以编写配置文件并重新启动 Web 服务器进程。这种模式简单且常见。它利用了可能已经存在的管理 API,因此需要很少的额外代码。不幸的是,利用大型现有的管理 API 会引入一些风险:
-
运行自动化的角色可以永久停止 Web 服务器,启动另一个二进制文件代替它,读取其访问权限下的任何数据等。
-
自动化中的错误隐含地具有足够的访问权限,可以导致所有 Web 服务器的协调停机。
-
自动化凭据的妥协等同于所有 Web 服务器的妥协。
软件更新 API
您可以将配置作为打包的软件更新分发,使用与更新 Web 服务器二进制相同的机制。有许多打包和触发二进制更新的方法,使用不同大小的 API。一个简单的例子是从中央仓库拉取的 Debian 软件包(.deb),由cron调用的周期性apt-get。您可以构建一个更复杂的示例,使用以下部分讨论的模式之一来触发更新(而不是使用cron),然后可以重用该更新来更新配置和二进制文件。随着您不断完善二进制分发机制以增加安全性和安全性,这些好处也会应用到配置上,因为两者使用相同的基础设施。为了集中协调金丝雀流程、协调健康检查或提供签名/来源/审计等工作同样对这两种工件都有好处。
有时,二进制和配置更新系统的需求不一致。例如,您可能在配置中分发一个 IP 拒绝列表,需要尽快收敛,同时将 Web 服务器二进制构建到容器中。在这种情况下,以您希望分发配置更新的速度建立、启动和关闭一个新的容器可能太昂贵或具有破坏性。这种类型的冲突要求可能需要两种分发机制:一种用于二进制文件,另一种用于配置更新。
有关此模式的更多想法,请参见第九章。
自定义 OpenSSH ForceCommand
您可以编写一个简短的脚本来执行这些步骤:
-
从
STDIN接收配置。 -
对配置进行合理性检查。
-
重新启动 Web 服务器以更新配置。
然后,您可以通过在authorized_keys文件中绑定特定条目与ForceCommand选项来通过 OpenSSH 公开此命令。¹² 这种策略向调用者呈现了一个非常小的 API,可以通过经过严格测试的 OpenSSH 协议连接,其中唯一可用的操作是提供配置文件的副本。记录文件(或其哈希值^(13))合理地捕获了会话的整个操作,以供以后审计。
您可以实现尽可能多的这些唯一的密钥/ForceCommand组合,但是这种模式很难扩展到许多唯一的管理操作。虽然您可以在 OpenSSH API 的基础上构建基于文本的协议(例如git-shell),但这样做将开始构建自己的 RPC 机制。您可能最好直接跳到该道路的尽头,构建在现有框架(如gRPC或Thrift)之上。
自定义 HTTP 接收器(边车)
您可以编写一个小的边车守护程序——非常类似于ForceCommand解决方案,但使用另一个 AAA 机制(例如,带 SSL 的 gRPC,SPIFFE或类似机制)——来接受配置。这种方法不需要修改服务二进制文件,非常灵活,但需要引入更多的代码和另一个守护程序来管理。
自定义 HTTP 接收器(进程内)
您还可以修改 Web 服务器以直接公开 API 来更新其配置,接收配置并将其写入磁盘。这是最灵活的方法之一,与我们在 Google 管理配置的方式非常相似,但需要将代码合并到服务二进制文件中。
权衡
除了表 5-2 中的大选项外,其他选项都提供了向自动化添加安全性和安全性的机会。攻击者仍然可能通过推送任意配置来破坏 Web 服务器的角色;但是,选择较小的 API 意味着推送机制不会隐含允许这种妥协。
您可能还可以通过独立于推送它的自动化对配置进行签名来进一步设计最小特权。这种策略将信任分割为角色之间的信任,保证如果推送配置的自动化角色受到破坏,自动化也不能通过发送恶意配置来破坏 Web 服务器。回想麦克罗伊、平森和塔格的建议,设计系统的每个部分执行一个任务并且执行得很好,可以让您隔离信任。
狭窄 API 呈现的更精细的控制界面还允许您添加对自动化中的错误的保护。除了需要签名来验证配置之外,您还可以要求从中央速率限制器获取持有者令牌¹⁴,该速率限制器独立于您的自动化创建,并针对推出的每个主机。您可以非常小心地对这个通用速率限制器进行单元测试;如果速率限制器是独立实现的,那么可能不会同时影响推出自动化的错误也不会影响它。独立的速率限制器也可以方便地重复使用,因为它可以对 Web 服务器的配置推出进行速率限制,对相同服务器的二进制推出进行速率限制,对服务器的重新启动进行速率限制,或者对您希望添加安全检查的任何其他任务进行速率限制。
用于认证和授权决策的策略框架
认证 [名词]:验证用户或进程的身份
授权 [名词]:评估特定经过身份验证的一方的请求是否应该被允许
前一节提倡为您的服务设计一个狭窄的管理 API,这样您可以授予尽可能少的特权来实现给定的操作。一旦存在该 API,您必须决定如何控制对其的访问。访问控制涉及两个重要但不同的步骤。
首先,您必须验证谁在连接。认证机制的复杂程度可以不同:
简单:接受通过 URL 参数传递的用户名
示例:/service?username=admin
更复杂:呈现预共享密钥
示例:WPA2-PSK,HTTP cookie
更复杂:复杂的混合加密和证书方案
示例:TLS 1.3,OAuth
一般来说,您应该更倾向于重用现有的强大的加密身份验证机制来识别 API 的调用者。这个身份验证决定的结果通常表示为用户名、常用名称、“主体”、“角色”等。在本节中,我们使用角色来描述身份验证的可互换结果。
接下来,您的代码必须做出决定:这个角色是否被授权执行所请求的操作?您的代码可能会考虑请求的许多属性,例如以下内容:
所请求的具体操作
示例:URL,正在运行的命令,gRPC 方法
请求的操作参数
示例:URL 参数,argv,gRPC 请求
请求的来源
示例:IP 地址,客户端证书元数据
经过身份验证的角色的元数据
示例:地理位置,法律管辖区,风险的机器学习评估
服务器端上下文
示例:类似请求的速率,可用容量
本节的其余部分讨论了谷歌发现有用的几种技术,以改进和扩展身份验证和授权决策的基本要求。
使用高级授权控制
给定资源的访问控制列表是实现授权决策的一种熟悉方式。最简单的 ACL 是与经过身份验证的角色匹配的字符串,通常与某种分组概念结合在一起,例如一组角色,例如“管理员”,它扩展为更大的角色列表,例如用户名。当服务评估传入请求时,它会检查经过身份验证的角色是否是 ACL 的成员。
更复杂的授权要求,例如多因素授权(MFA)或多方授权(MPA),需要更复杂的授权代码(有关三因素授权和 MPA 的更多信息,请参见“高级控制”)。此外,一些组织在设计授权策略时可能需要考虑其特定的监管或合同要求。
这段代码很难正确实现,如果许多服务都实现了自己的授权逻辑,其复杂性可能会迅速增加。根据我们的经验,使用像AWS或GCP身份和访问管理(IAM)等框架可以将授权决策的复杂性与核心 API 设计和业务逻辑分离。在谷歌,我们还广泛使用 GCP 授权框架的变体来内部服务。¹⁵
安全策略框架允许我们的代码进行简单的检查(例如“X 是否可以访问资源 Y?”),并将这些检查与外部提供的策略进行评估。如果我们需要向特定操作添加更多的授权控制,我们可以简单地更改相关的策略配置文件。这种低开销具有巨大的功能和速度优势。
投资于广泛使用的授权框架
您可以通过使用共享库实现授权决策,并尽可能广泛地使用一致的接口来实现规模化的身份验证和授权更改。在安全领域应用这一经典的模块化软件设计建议会产生意想不到的好处。例如:
-
您可以通过单个库更改为所有服务端点添加对 MFA 或 MPA 的支持。
-
然后,您可以通过单个配置更改在所有服务中的少量操作或资源上实现此支持。
-
通过要求所有允许潜在不安全操作的操作都需要 MPA,您可以提高可靠性,类似于代码审查系统。这种流程改进可以提高对内部风险威胁的安全性(有关对手类型的更多信息,请参见第二章),通过促进快速事件响应(绕过修订控制系统和代码审查依赖)而不允许广泛的单方面访问。
随着组织的发展,标准化是您的朋友。统一的授权框架有助于团队流动性,因为更多的人知道如何使用共同的框架编写代码并实现访问控制。
避免潜在陷阱
设计复杂的授权策略语言是困难的。如果策略语言过于简单,它将无法实现其目标,并且您最终将授权决策分散在框架策略和主要代码库中。如果策略语言过于一般化,它将非常难以理解。为了减轻这些问题,您可以应用标准的软件 API 设计实践,特别是迭代设计方法,但我们建议谨慎进行,以避免这两个极端。
仔细考虑授权策略是如何与二进制文件一起交付的。您可能希望更新授权策略,这可能会成为配置中最敏感的部分之一,独立于二进制文件。有关配置分发的更多讨论,请参见本书的上一节中的示例,第九章和第十四章,SRE 书中的第八章,以及SRE 工作手册中的第十四章和第十五章。
应用程序开发人员将需要协助制定将编码在此语言中的策略决策。即使您避免了这里描述的陷阱,并创建了一种富有表现力和易于理解的策略语言,往往仍需要应用程序开发人员实现管理 API 和具有关于生产环境的特定领域知识的安全工程师和 SRE 之间的合作,以在安全性和功能性之间找到合适的平衡。
深入探讨:高级控制
虽然许多授权决策是二进制的是/否,但在某些情况下更灵活性是有用的。与其要求严格的是/否,不如配备一个“可能”的逃生阀,再加上额外的检查,可以极大地减轻系统的压力。这里描述的许多控制可以单独使用或组合使用。适当的使用取决于数据的敏感性,行动的风险以及现有的业务流程。
多方授权(MPA)
引入另一个人是确保正确访问决策的一种经典方式,培养安全和可靠性文化(参见第二十一章)。这种策略提供了几个好处:
-
防止错误或意外违反可能导致安全或隐私问题的策略。
-
阻止恶意行为者尝试进行恶意更改。这包括员工,他们面临纪律行动的风险,以及外部攻击者,他们面临被发现的风险。
-
通过要求至少牵涉到另一个人的妥协或经过仔细构建的更改经过同行审查,可以增加攻击的成本。
-
审计过去的行动,以进行事件响应或事后分析,假设审查是永久记录并以防篡改的方式记录的。
-
提供客户舒适感。您的客户可能更愿意使用您的服务,因为他们知道没有单个人可以独自进行更改。
MPA 通常用于广泛的访问级别,例如要求批准加入一个授予对生产资源访问权限的组,或者扮演特定角色或凭证的能力。广泛的 MPA 可以作为一个有价值的紧急机制,以启用非常不寻常的操作,对于这些操作你可能没有特定的工作流程。在可能的情况下,你应该尽量提供更细粒度的授权,这可以提供更强的可靠性和安全性保证。如果第二方批准针对小型功能 API 的操作(见[“小型功能 API”]),他们可以更加确信他们正在授权的内容。
关于批准的社会压力也可能导致糟糕的决定。例如,如果一个工程师不愿意拒绝一个可疑请求,因为它是由经理、高级工程师或者站在他们办公桌旁的人发出的。为了减轻这些压力,你可以提供将批准事后升级给安全或调查团队的选项。或者,你可以制定一个政策,要求某种类型的批准全部(或一部分)独立审计。
在构建多方授权系统之前,确保技术和社会动态允许某人说不。否则,系统就没有多少价值。
三因素授权(3FA)
在大型组织中,MPA 通常存在一个关键弱点,可以被决心和坚持的攻击者利用:所有的“多方”使用同一台中央管理的工作站。工作站车队越同质化,攻击者就越有可能攻击一台工作站就能攻击几台甚至全部工作站。
一种经典的方法是为了加固工作站车队免受攻击,用户需要维护两个完全独立的工作站:一个用于一般用途,比如浏览网页和发送/接收电子邮件,另一个更可信的工作站用于与生产环境通信。根据我们的经验,用户最终希望这些工作站具有类似的功能和能力,为了维护这些需要更高级别保护的有限用户集的两套工作站基础设施,既昂贵又难以长期维持。一旦这个问题不再是管理层关注的焦点,人们就没有动力去维护这些基础设施。
减轻单个受损平台可能破坏所有授权的风险需要以下措施:
-
至少维护两个平台
-
在两个平台上批准请求的能力
-
(最好)至少有一个平台具有硬化能力
考虑到这些要求,另一个选择是要求从一个硬化的移动平台对某些非常危险的操作进行授权。为了简单和方便起见,你只允许 RPCs 从完全管理的桌面工作站发起,然后要求移动平台进行三因素授权。当一个生产服务接收到一个敏感的 RPC 时,策略框架(在[“用于认证和授权决策的策略框架”]中描述)要求从独立的 3FA 服务获得加密签名的批准。然后该服务指示它将 RPC 发送到移动设备,显示给发起用户,并且他们确认了请求。
硬化移动平台比硬化通用工作站要容易一些。我们发现用户通常更容忍移动设备上的某些安全限制,比如额外的网络监控,只允许一部分应用程序,并且只能连接有限数量的 HTTP 端点。这些策略在现代移动平台上也很容易实现。
一旦您有了一个坚固的移动平台来显示拟议的生产变更,您必须将请求发送到该平台并显示给用户。在谷歌,我们重用了将通知传递到安卓手机的基础设施,以授权和报告我们用户的谷歌登录尝试。如果您有类似的坚固基础设施,那么将其扩展以支持此用例可能是有用的,但如果没有,基本的基于网络的解决方案相对容易创建。3FA 系统的核心是一个简单的 RPC 服务,它接收要授权的请求,并通过受信任的客户端公开请求以进行授权。请求 3FA 受保护的 RPC 的用户会从其移动设备访问 3FA 服务的网络 URL,并收到授权请求。
重要的是要区分 MPA 和 3FA 保护的威胁,以便您可以决定何时应用一致的策略。MPA 不仅保护免受单方面内部风险的威胁,还保护免受个人工作站的妥协(通过需要第二次内部批准)。3FA 保护免受内部工作站的广泛妥协,但在单独使用时不提供任何对内部威胁的保护。要求发起者进行 3FA,并要求第二方进行简单的基于网络的 MPA,可以提供对大多数这些威胁的组合的非常强大的防御,而组织开销相对较小。
业务理由
如“选择审计员”中所述,您可以通过将访问权限与结构化的业务理由(例如错误、事件、工单、案例 ID 或分配的帐户)联系起来来强制执行授权。但是构建验证逻辑可能需要额外的工作,也可能需要对值班或客户服务人员进行流程更改。
例如,考虑客户服务工作流程。在一些小型或不成熟组织中有时会发现的反模式中,基本和初期的系统可能会给客户服务代表访问所有客户记录,要么是出于效率原因,要么是因为不存在控制。更好的选择是默认情况下阻止访问,并且只有在您可以验证业务需求时才允许访问特定数据。这种方法可能是随时间实现的控制梯度。例如,它可能从仅允许分配了一个开放工单的客户服务代表开始。随着时间的推移,您可以改进系统,仅允许访问特定客户以及这些客户的特定数据,并且在经过一段时间后需要客户批准。
当正确配置时,这种策略可以提供强大的授权保证,以确保访问是适当的并且范围适当。结构化的理由允许自动化要求 Ticket #12345 不是随意输入的随机数字,以满足简单的正则表达式检查。相反,理由满足一组平衡运营业务需求和系统能力的访问策略。
临时访问
您可以通过向资源授予临时访问来限制授权决策的风险。当没有针对每个操作的细粒度控制时,这种策略通常是有用的,但您仍希望尽可能使用可用的工具授予最低特权。
您可以以结构化和计划的方式(例如,在值班轮换期间或通过过期的组成员资格)或按需方式授予临时访问(用户明确请求访问)来授予临时访问。您还可以将临时访问与多方授权请求、业务理由或其他授权控制结合使用。临时访问还创建了一个逻辑点进行审计,因为您可以清楚地记录任何给定时间具有访问权限的用户。它还提供了关于临时访问发生位置的数据,因此您可以随时间优先处理并减少这些请求。
临时访问还会减少环境权限。这是管理员更喜欢使用sudo或“以管理员身份运行”而不是作为 Unix 用户root或 Windows 管理员帐户操作的一个原因——当您意外地发出删除所有数据的命令时,您拥有的权限越少,越好!
代理
当后端服务的细粒度控制不可用时,您可以退而使用受到严格监控和限制的代理机器(或堡垒)。只有来自这些指定代理的请求才被允许访问敏感服务。该代理可以限制危险操作,限制操作速度,并执行更高级的日志记录。
例如,您可能需要执行紧急回滚以撤销错误的更改。鉴于错误更改可能发生的无限方式,以及解决错误更改可能的无限方式,执行回滚所需的步骤可能不会在预定义的 API 或工具中提供。您可以给系统管理员灵活性来解决紧急情况,但引入限制或额外的控制以减轻风险。例如:
-
每个命令可能需要同行批准。
-
管理员可能只连接到相关的机器。
-
管理员使用的计算机可能无法访问互联网。
-
您可以启用更彻底的日志记录。
与此同时,实现任何这些控制都会带来集成和运营成本,如下一节所讨论的。
权衡和紧张关系
采用最小权限访问模型肯定会改善您组织的安全姿态。然而,您必须权衡前面部分中概述的好处与实现该姿态的潜在成本。本节考虑了其中一些成本。
增加安全复杂性
高度细粒度的安全姿态是一个非常强大的工具,但也很复杂,因此难以管理。拥有一套全面的工具和基础设施来帮助您定义、管理、分析、推送和调试安全策略非常重要。否则,这种复杂性可能变得令人不堪重负。您应该始终力求能够回答这些基本问题:“给定用户是否有权访问给定服务/数据?”和“对于给定服务/数据,谁有权限访问?”
对协作和公司文化的影响
虽然最小权限模型可能适用于敏感数据和服务,但在其他领域采取更宽松的方法可以提供切实的好处。
例如,为软件工程师提供对源代码的广泛访问权带来一定的风险。然而,这可以通过工程师能够根据自己的好奇心在工作中学习,并在能够借用他们的注意力和专业知识时在正常角色之外贡献功能和错误修复来平衡。更不明显的是,这种透明度也使工程师更难以编写不合适的代码而不被注意到。
在您的数据分类工作中包括源代码和相关工件可以帮助您形成一个有原则的方法来保护敏感资产,同时又能从对不太敏感资产的可见性中受益,您可以在第二十一章中了解更多。
影响安全的高质量数据和系统
在零信任环境中,最小特权的基础上,每个细粒度的安全决策都取决于两件事:正在执行的策略和请求的上下文。上下文受到大量数据的影响,其中一些可能是动态的,这些数据可能会影响决策。例如,数据可能包括用户的角色、用户所属的组、发出请求的客户端的属性、输入到机器学习模型的训练集,或者被访问的 API 的敏感性。您应该审查产生这些数据的系统,以确保安全影响数据的质量尽可能高。低质量的数据将导致不正确的安全决策。
对用户生产力的影响
您的用户需要尽可能高效地完成其工作流程。最佳的安全姿态是您的最终用户不会注意到的。然而,引入新的三因素和多方授权步骤可能会影响用户的生产力,特别是如果用户必须等待获得授权。您可以通过确保新步骤易于导航来减轻用户的痛苦。同样,最终用户需要一种简单的方式来理解访问拒绝,可以通过自助诊断或快速访问支持渠道。
对开发人员复杂性的影响
随着最小特权模型在您的组织中得到采用,开发人员必须遵守它。这些概念和政策必须易于被不太懂安全的开发人员消化,因此您应该提供培训材料并充分记录您的 API。在他们应对新要求时,为开发人员提供便捷快速地访问安全工程师进行安全审查和一般咨询。在这种环境中部署第三方软件需要特别小心,因为您可能需要将软件包装在一个可以执行安全策略的层中。
结论
在设计复杂系统时,最小特权模型是确保客户能够完成所需工作,但不多的最安全方式。这是一种强大的设计范式,可以保护您的系统和数据免受已知或未知用户造成的恶意或意外损害。谷歌已经花费了大量时间和精力来实现这个模型。以下是关键组件:
-
对系统功能的全面了解,以便根据每个部分的安全风险水平对其进行分类。
-
基于这种分类,对系统和数据进行尽可能细致的分区。最小特权需要小型功能 API。
-
用于验证用户凭据的身份验证系统,当他们尝试访问您的系统时。
-
强制执行明确定义的安全策略的授权系统,可以轻松附加到您的精细分区系统上。
-
一套用于微妙授权的高级控制。例如,这些控制可以提供临时、多因素和多方批准。
-
系统支持这些关键概念的操作要求。至少,您的系统需要以下内容:
-
审计所有访问并生成信号,以便您可以识别威胁并进行历史取证分析。
-
推理、定义、测试和调试安全策略的手段,并为此策略提供最终用户支持
-
当您的系统表现不如预期时,提供一个紧急访问机制
使所有这些组件以对用户和开发人员易于采用的方式工作,并且不会对其生产力产生显着影响,还需要组织承诺尽可能无缝地采用最低特权。这一承诺包括一个专注的安全功能,通过安全咨询、策略定义、威胁检测和安全相关问题的支持,拥有您的安全姿态并与用户和开发人员进行接口。
虽然这可能是一项艰巨的任务,但我们坚信这是对安全姿态执行现有方法的重大改进。
McIlroy, M.D., E.N. Pinson, and B.A. Tague. 1978. “UNIX Time-Sharing System: Foreword.” The Bell System Technical Journal 57(6): 1899–1904. doi:10.1002/j.1538-7305.1978.tb02135.x。
POSIX 代表可移植操作系统接口,是由大多数 Unix 变体提供的 IEEE 标准化接口。有关概述,请参阅Wikipedia。
Windows API 包括熟悉的图形元素,以及编程接口,如DirectX、COM等。
Memcached是一个高性能的分布式内存对象缓存系统。
NATS是一个基于文本协议构建的基本 API 的示例,而不是像 gRPC 这样的复杂 RPC 接口。
TinyURL.com API 文档不够完善,但它本质上是一个返回缩短 URL 作为响应主体的单个 GET URL。这是一个具有微小 API 的可变服务的罕见示例。
Fonts API只是列出当前可用的字体。它只有一个端点。
一个很好的起点是 Gamma, Erich et al. 1994. Design Patterns: Elements of Reusable Object-Oriented Software. Boston, MA: Addison-Wesley. 另请参阅 Bloch, Joshua. 2006. “How to Design a Good API and Why It Matters.” Companion to the 21st ACM SIGPLAN Symposium on Object-Oriented Programming Systems, Languages, and Applications: 506–507. doi:10.1145/1176617.1176622。
尽管我们以 Unix 主机为例,但这种模式并不局限于 Unix。传统的 Windows 主机设置和管理遵循类似的模型,其中 Windows API 的交互暴露通常是通过 RDP 而不是 OpenSSH。
流行的选项包括以非特权用户身份运行,然后通过sudo对允许的命令进行编码,仅授予必要的capabilities(7),或者使用类似 SELinux 的框架。
Canarying是指将更改慢慢地推出到生产环境,从一小部分生产端点开始。就像煤矿中的金丝雀一样,它会在出现问题时提供警告信号。有关更多信息,请参阅SRE 书中的第 27 章。
ForceCommand是一种配置选项,用于限制特定授权身份仅运行单个命令。有关更多详细信息,请参阅sshd_config manpage。
¹³ 在规模上,记录和存储许多重复文件副本可能是不切实际的。记录哈希值可以让您将配置关联回修订控制系统,并在审计日志中检测未知或意外的配置。作为额外的保险,如果空间允许,您可能希望存储被拒绝的配置,以帮助进行后续调查。理想情况下,所有配置应该被签名,表明它们来自具有已知哈希值的修订控制系统,或者被拒绝。
¹⁴ 持票令牌只是一个由速率限制器签名的加密签名,可以呈现给任何人,该人具有速率限制器的公钥。他们可以使用该公钥验证速率限制器在令牌的有效期内批准了此操作。
¹⁵ 我们的内部变体支持我们的内部身份验证原语,避免了一些循环依赖的问题等。
¹⁶ 参见“用于身份验证和授权决策的策略框架”。

