
- 1如何自己的医疗图像分割数据集 使用NNunet进行训练_nnunet处理nii图像
- 2llama.cpp部署通义千问Qwen-14B_llama.cpp qwen
- 3轻松实现微信、QQ防撤回、多开工具_微信防撤回github
- 4napi系列学习基础篇——NAPI数据类型转换与同步调用
- 5用五一最简单的板做一个智能循迹小车_制作一个智能小车,前期有哪些检查工作
- 6干货:用好VSCode这13款插件,工作效率提升10倍_vscode design
- 7Sentence-Transformer的使用及fine-tune教程_distiluse-base-multilingual-cased
- 8一招解决从GItHub下载文件过慢问题_python下载github慢
- 9宇信科技:强势行业加速融入AIGC,同时做深做细
- 10用云手机运营TikTok有什么好处?
进击大数据系列(十五)Hadoop 图形化管理系统 Hue
赞
踩
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 Hadoop 数据仓库 Hive、计算引擎 Spark、实时计算流计算引擎Flink、数据库 Hbase、任务调度器 Oozie、数据同步工具 Sqoop、分布式采集系统 Flume、数据分析引擎 Apache Pig 等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 图形化管理系统 Hue 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
Hue 概述
HUE=Hadoop User Experience Hue 是一个开源的 Apache Hadoop UI 系统,最早是由 Cloudera Desktop 演化而来,由 Cloudera 贡献给开源社区,它是基于 Python Web 框架 Django 实现的。
Hue 是一个开源的 Apache Hadoop UI 系统,最早是由 Cloudera Desktop 演化而来,由 Cloudera 贡献给开源社区,它是基于 Python Web 框架 Django 实现的。
通过使用 Hue 我们可以在浏览器端的 Web 控制台上与 Hadoop 集群进行交互来分析处理数据,例如操作 HDFS 上的数据,运行 MapReduce Job,执行 Hive 的 SQL 语句,浏览 HBase 数据库等等。
HUE 链接
Site: http://gethue.com/
Github: https://github.com/cloudera/hue
Reviews: https://review.cloudera.org
Hue 架构
从总体上来讲,Hue应用采用的是B/S架构,该web应用的后台采用python编程语言别写的。大体上可以分为三层,分别是前端view层、Web服务层和Backend服务层。Web服务层和Backend服务层之间使用RPC的方式调用。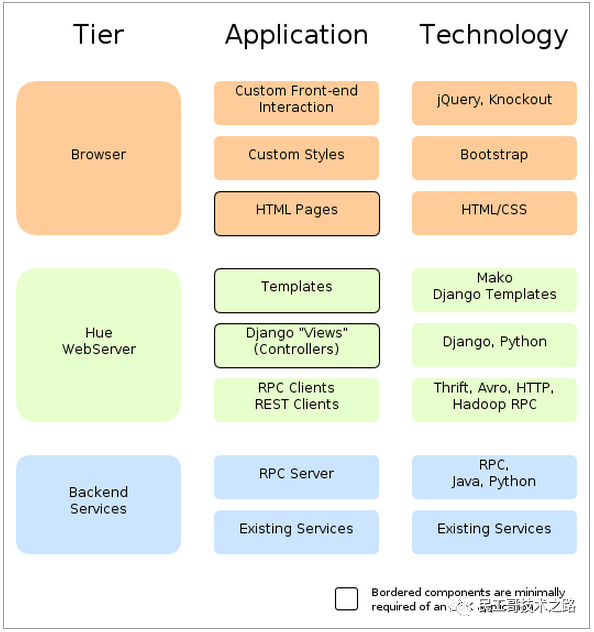
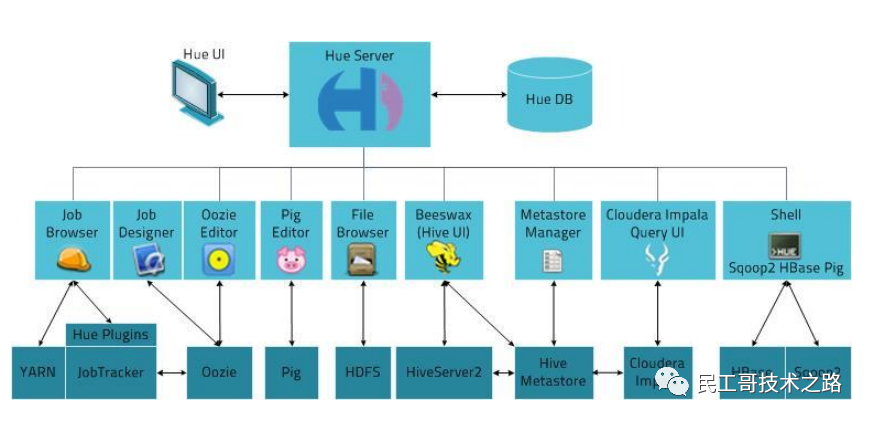
Hue 核心功能
SQL 编辑器,支持 Hive, Impala, MySQL, Oracle, PostgreSQL, SparkSQL, Solr SQL, Phoenix…
搜索引擎 Solr 的各种图表
Spark 和 Hadoop 的友好界面支持
支持调度系统 Apache Oozie,可进行 workflow 的编辑、查看
HUE 提供的这些功能相比 Hadoop 生态各组件提供的界面更加友好,但是一些需要 debug 的场景可能还是需要使用原生系统才能更加深入的找到错误的原因。
HUE 中查看 Oozie workflow 时,也可以很方便的看到整个 workflow 的 DAG 图,不过在最新版本中已经将 DAG 图去掉了,只能看到 workflow 中的 action 列表和他们之间的跳转关系,想要看 DAG 图的仍然可以使用 oozie 原生的界面系统查看。
1,访问 HDFS 和文件浏览
2,通过 web 调试和开发 hive 以及数据结果展示
3,查询 solr 和结果展示,报表生成
4,通过 web 调试和开发 impala 交互式 SQL Query
5,spark 调试和开发
7,oozie 任务的开发,监控,和工作流协调调度
8,Hbase 数据查询和修改,数据展示
9,Hive 的元数据(metastore)查询
10,MapReduce 任务进度查看,日志追踪
11,创建和提交 MapReduce,Streaming,Java job 任务
12,Sqoop2 的开发和调试
13,Zookeeper 的浏览和编辑
14,数据库(MySQL,PostGres,SQlite,Oracle)的查询和展示
一句话总结:Hue 是一个友好的界面集成框架,可以集成我们各种学习过的以及将要学习的框架,一个界面就可以做到查看以及执行所有的框架。
更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
Hue 部署与配置
环境说明
Hue的安,官方并没有编译好的软件包,需要从github上或者Hue官网上下载源码、安装依赖、编译安装。
- 官方网站:https://gethue.com/
- 源码下载:https://docs.gethue.com/releases/
- (这里用的是4.8.0版本:https://cdn.gethue.com/downloads/hue-4.8.0.tgz)
- 依赖环境:https://docs.gethue.com/administrator/installation/dependencies/
- 开发向导:https://docs.gethue.com/developer/development/#dependencies
Hue官网说明: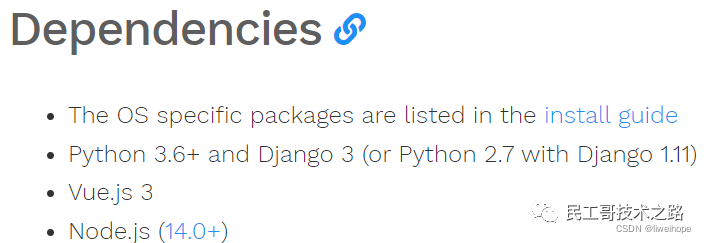 已经有的环境:
已经有的环境:
- 操作系统:CentOS Linux release 7.2.1511 (Core)
- Git:1.8.3.1
- JDK:jdk1.8.0_45
- Maven:apache-maven-3.8.4-bin
- MySQL:mysql-5.6.23-linux-glibc2.5-x86_64
- Python:2.7.5
安装依赖
下载Hue源码包:
wget https://cdn.gethue.com/downloads/hue-4.8.0.tgz安装必要的依赖
(需要sudo权限,或者root用户先执行):
yum -y install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-develNode.js 安装
之前用node-v16.13.0-linux-x64.tar.xz这个版本,编译Hue一直报错,没有编译成功,换成v14.16.0版本的编译成功了,可能V16版本有不支持。
- wget https://nodejs.org/dist/v14.16.0/node-v14.16.0-linux-x64.tar.gz
- #然后解压配置环境变量即可(我再root用户下安装的Node.js)。
编译 Hue
解压Hue源码包,进入hue源码目录,进行编译。使用 PREFIX 指定安装 Hue 的路径。
- tar -zxvf hue-4.8.0.tgz -C ~/sourcecode/
- cd ~/sourcecode/hue-4.8.0/
- #然后执行命令,进行编译:
- [ruoze@hadoop001 hue-4.8.0]$ PREFIX=/home/ruoze/app/hue make install
结果: 编译结果并不顺利,如果出现了什么错误需要根据具体的错误进行调整,比如缺少什么依赖,需要去安装缺少的依赖等。
编译结果并不顺利,如果出现了什么错误需要根据具体的错误进行调整,比如缺少什么依赖,需要去安装缺少的依赖等。
通过Docker快速安装
很多安装方式,可以参考GitHub上的说明,还有快速安装数据源的方式:https://docs.gethue.com/quickstart/
docker run -it -p 8888:8888 gethue/hue:latestKubernetes:
- helm repo add gethue https://helm.gethue.com
- helm repo update
- helm install hue gethue/hue
查看安装是否成功
- $ docker ps|grep hue
- $ netstat -tnlp|grep 8888
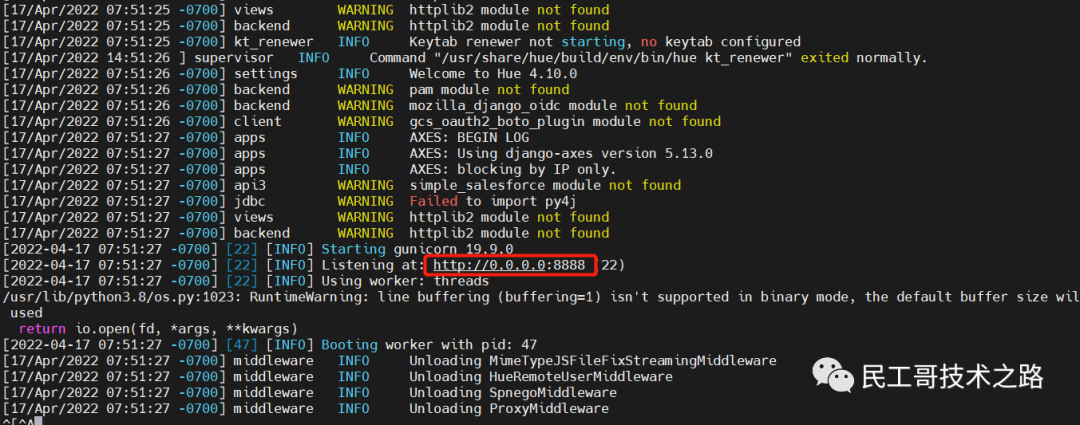 通过 http://server_ip:8888
通过 http://server_ip:8888 创建超级用户
创建超级用户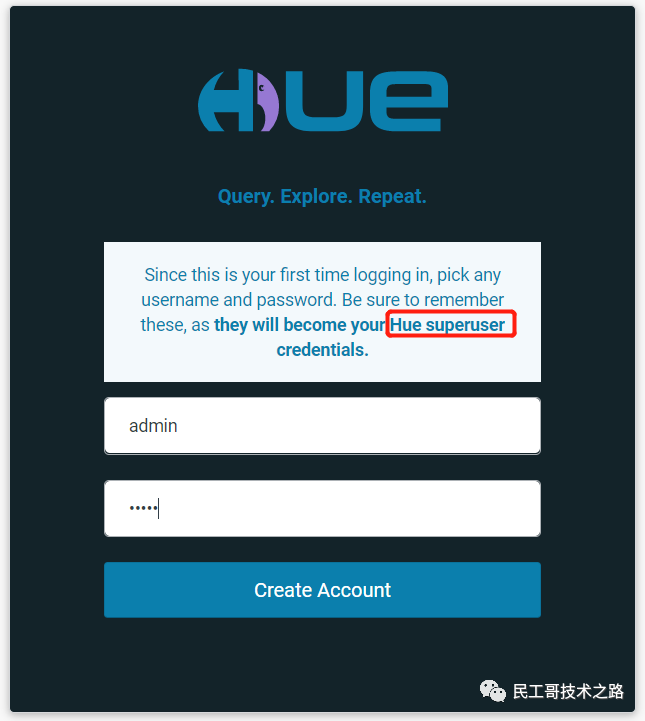 登录之后
登录之后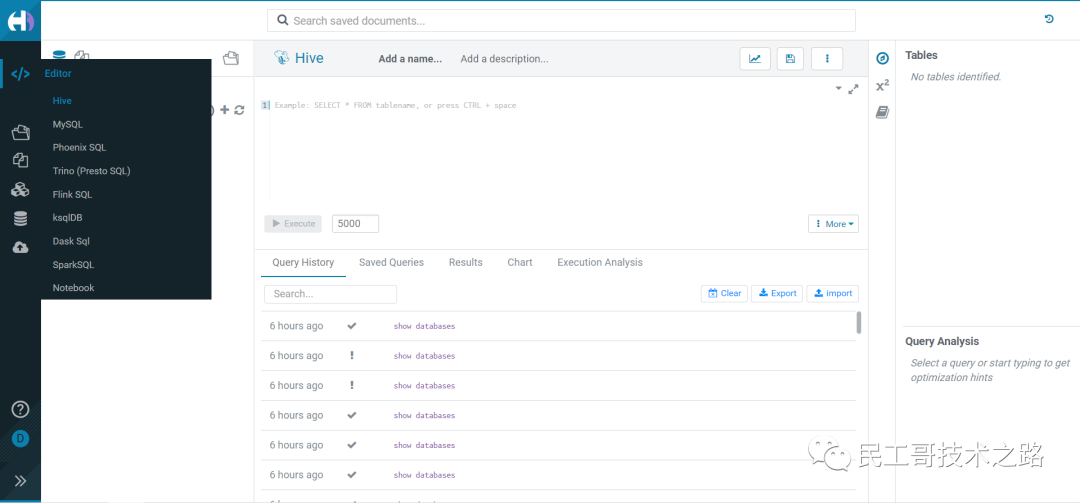
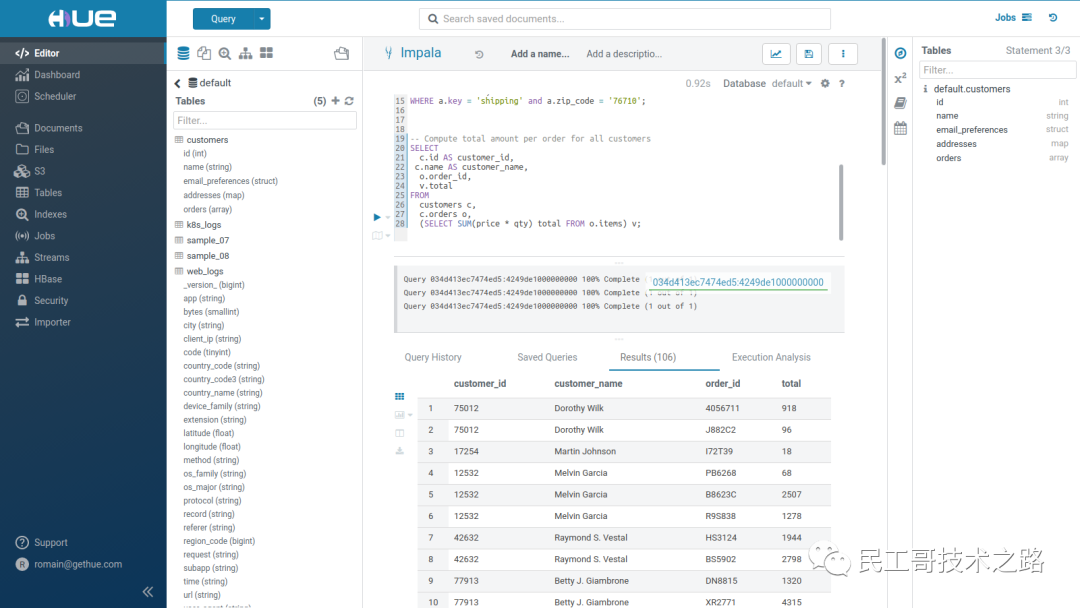 更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
Hue部署以及集成HDFS、YARN、HIVE及MYSQL
HUE与Hadoop集成(hdfs、yarn)
在 hdfs-site.xml 中增加配置:
- <!-- HUE -->
- <property>
- <!-- HDFS Web服务 -->
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
- <property>
- <name>dfs.permissions.enabled</name>
- <value>false</value>
- </property>
在core-site.xml中增加配置:
- <!-- #设置Hadoop集群的代理用户 -->
- <!-- HUE -->
- <property>
- <name>hadoop.proxyuser.ruoze.hosts</name>
- <value>*</value>
- </property>
- <!-- #设置Hadoop集群的代理用户组 -->
- <property>
- <name>hadoop.proxyuser.ruoze.groups</name>
- <value>*</value>
- </property>
增加 httpfs-site.xml 文件,加入配置
- <!-- HUE -->
- <property>
- <name>httpfs.proxyuser.ruoze.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>httpfs.proxyuser.ruoze.groups</name>
- <value>*</value>
- </property>
修改完,需要重启hdfs服务。
Hue配置
- #进入hue配置目录 修改HUE配置文件hue.ini
- cd desktop/conf
- #编辑 hue.ini 文件,修改如下:
- vi hue.ini
-
- #配置desktop
- #hue主机地址
- http_host=hadoop001
- #端口号
- http_port=8000
- #时区
- time_zone=Asia/Shanghai
- dev=true
- #服务器用户
- server_user=ruoze
- #服务器用户组
- server_group=ruoze
- #默认用户
- default_user=ruoze
- #默认HDFS超级用户
- default_hdfs_superuser=ruoze
- #app黑名单,禁用solr,规避报错
- app_blacklist=search,impala,hbase,oozie
-
- app_blacklist=impala,security,filebrowser,jobbrowser,rdbms,jobsub,pig,hbase,sqoop,zookeeper,metastore,spark,oozie,indexer
-
- [[database]]
- engine=mysql
- host=hadoop001
- port=3306
- user=root
- password=password
- name=hue
-
- #如下是 HUE与Hadoop集成(hdfs、yarn)
- #配置HDFS
- #默认文件系统 8020? 9000?
- fs_defaultfs=http://hadoop001:9000
- #web hdfs的路径
- webhdfs_url=http://hadoop001:9870/webhdfs/v1
- #Hadoop配置文件目录
- hadoop_conf_dir=$HADOOP_HOME/etc/hadoop
-
- #配置YARN
- #YARN的主机地址
- resourcemanager_host=hadoop001
- #YARN API的地址 8088改过的
- resourcemanager_api_url=http://hadoop001:8123
- #代理API的地址 8088改过的
- proxy_api_url=http://hadoop001:8123
- #历史服务器的API地址
- history_server_api_url=http://hadoop001:19888
- resourcemanager_port=8032
- submit_to=True

HUE与Hive集成
集成Hive,在启动hue之前,需要启动 Hiveserver2 服务。启动命令:
- hive --service metastore &
- #或者nohup hive --service metastore 2>&1 &
-
- hive --service hiveserver2 &
配置 $HIVE_HOM/conf/hive-site.xml
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10000</value>
- </property>
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>hadoop001</value>
- </property>
- <property>
- <name>hive.server2.long.polling.timeout</name>
- <value>5000</value>
- </property>
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://hadoop001:9083</value>
- </property>
然后修改:$HUE_HOME/desktop/conf/hue.ini
- #[beeswax]
- #Hive主机地址
- hive_server_host=hadoop001
- #Hive主机端口
- hive_server_port=10000
- #Hive配置文件目录
- hive_conf_dir=$HIVE_HOME/conf
-
- # 注意到注释上说,11是hive3.0的
- thrift_version=11
HUE与MySQL集成
修改:$HUE_HOME/desktop/conf/hue.ini
- # [librdbms] -- [[databases]] -- [[[mysql]]];1639行
- # 注意: ##[[mysql]] => [[mysql]];两个##要去掉!
- # name是database_name
- [[[mysql]]]
- nice_name="My SQL DB"
- name=hue
- engine=mysql
- host=hadoop001
- port=3306
- user=root
- password=password
初始化Hue的MySQL元数据
- #去mysql所在的机器上
- #在mysql中创建数据库hue,用来存放元数据
- mysql -uroot -ppassword
- mysql> create database hue;
然后去Hue家目录
- #新建数据库并初始化
- cd hue/build/env/bin
- ./hue syncdb
- ./hue migrate
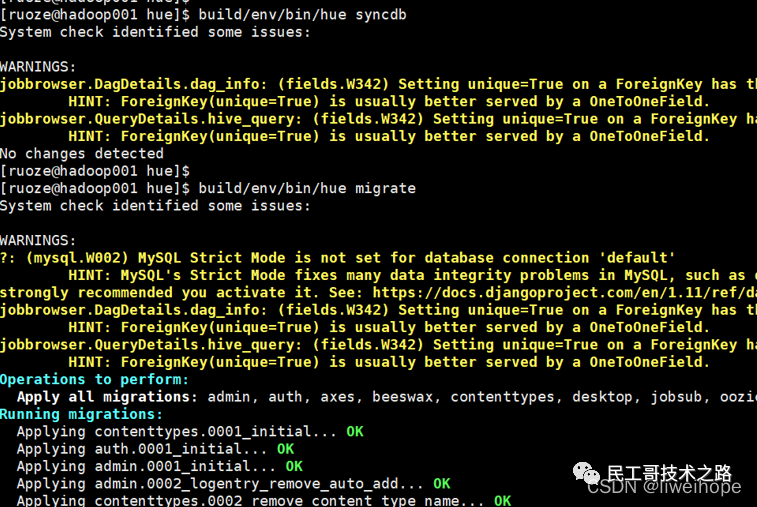 执行完之后,可以去mysql的hue数据库里看到对应的hue元数据。
执行完之后,可以去mysql的hue数据库里看到对应的hue元数据。
启动hue
- # 在hue安装路径下执行
- build/env/bin/supervisor
如下: 然后在浏览器中输入:http://hadoop001:8000/可以看到hue的界面,第一次登陆需要创建hue的用户名和密码,如下:
然后在浏览器中输入:http://hadoop001:8000/可以看到hue的界面,第一次登陆需要创建hue的用户名和密码,如下: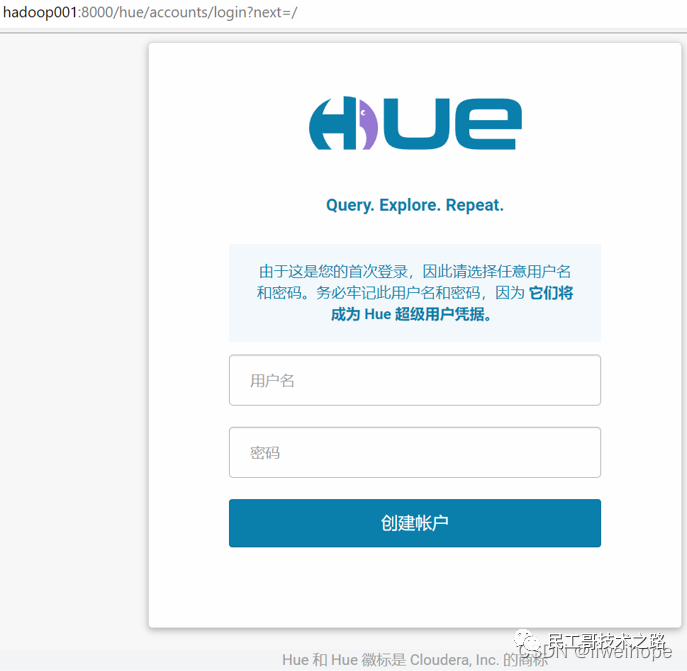
Hue界面验证
验证hdfs
如下,可以看到hdfs上的文件: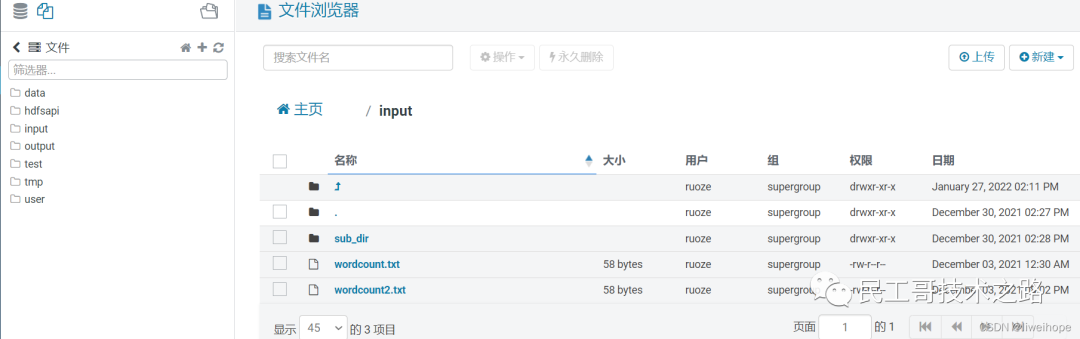
验证Hive
在Hive数据库中执行查询语句如下: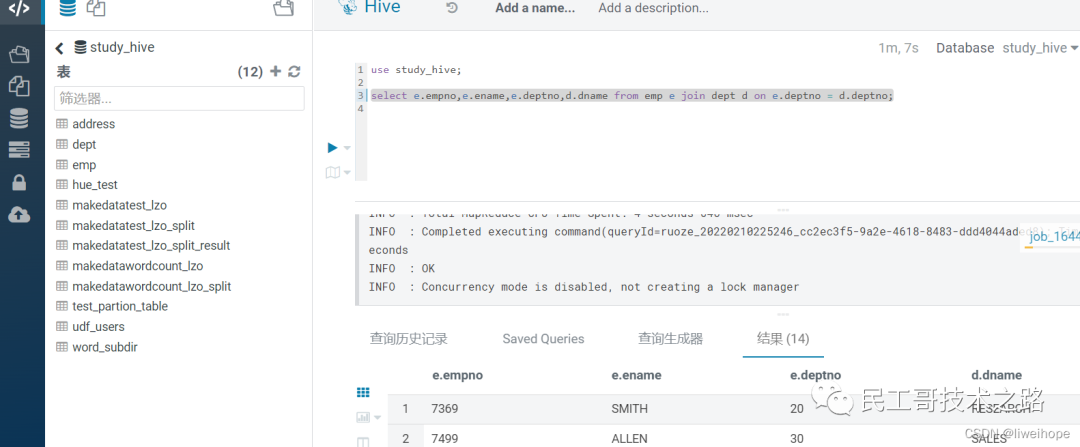
验证MySQL
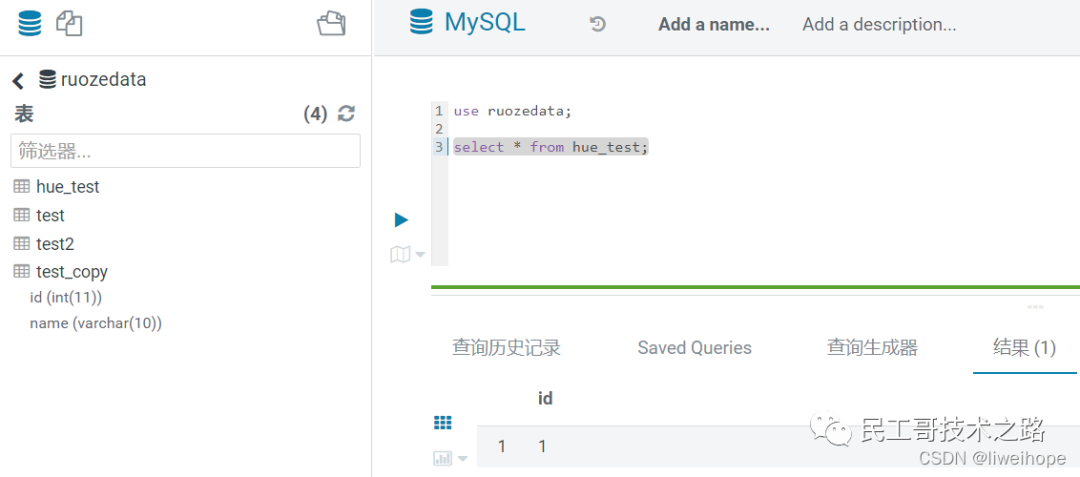
注意事项
1.Hue集成RDBMS数据库需要在librdbms和notebook两个部分都需要添加相应的配置,否则在Hue界面上无法显示。
2.notebook配置部分需要注意,添加新的配置后覆盖默认的,导致Hive、Impala等不能再Hue上显示,配置时需要将需要的服务都添加上。
3.[[databases]]下可添加多个[[[mysql]]]或其他数据库,如果有多个mysql,分别命名为[[[mysql1]]],[[[mysql2]]]或其他名字区分,除此之外,还要添加notebook。
4.启动hue之前需要:启动Hive metastore、启动hiveserver2。
5.core-site.xml配置中的ruoze用户需要和hue.ini中的用户一致,hue.ini默认为hue用户和组,这里修改成了ruoze用户,也是和Linux用户保持一致。
- [desktop]
- #服务器用户
- server_user=ruoze
- #服务器用户组
- server_group=ruoze
- #默认用户
- default_user=ruoze
- #默认HDFS超级用户
- default_hdfs_superuser=ruoze
6.保证Hive metastore、hiveserver2的端口好不要被占用。
7.中间会出现一些错误,包括依赖、编译、hiveserver2启动、Hue启动、Hue界面都有可能出现报错等,报错的话需要耐心去排查定位错误。
更多关于大数据 Hadoop系列的学习文章,请参阅:大数据 Hadoop 系列,本系列持续更新中。
来源:https://cnblogs.com/MrChenShao/p/11061312.html https://blog.csdn.net/liweihope/article/details/122869416
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位),相互帮助,一起进步!请文明发言,主要以技术交流、内推、行业探讨为主。
广告人士勿入,切勿轻信私聊,防止被骗

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

