
- 1超级简单的Python爬虫入门教程(非常详细),通俗易懂,看一遍就会了_爬虫python入门
- 2【Doris】Doris 最佳实践-Compaction调优(3)_doris中如何查看哪个表的版本有堆积?
- 3⑩② 【MySQL索引】详解MySQL`索引`:结构、分类、性能分析、设计及使用规则。_mysql 索引名带`
- 4CentOS 7.6 防火墙打开、关闭,端口开启、关闭_centos7.6开放端口命令
- 5李宏毅-2023春机器学习 ML2023 SPRING-学习笔记:2/24 正确认识chatGPT_李宏毅2023gpt
- 6yaw(pan)/pitch(tilt)/roll计算_yaw pitch roll计算
- 7Vivado PLL锁相环 IP核的使用
- 8雪花id如何保证连续且不重复
- 9解决ssh:connect to host github.com port 22: Connection timed out与kex_exchange_identification_cloning into 'gonganzichan'... ssh: connect to hos
- 10循环队列的初始化,入队,出队,求队长,取队头元素_循环队列初始化
bert训练初入门实例,情感分类任务_chinese_l-12_
赞
踩
跑了个小的情感分类demo,记录一下步骤
首先去bert的github下载框架 https://github.com/google-research/bert
然后拉到下面下载他们训练好的语料库
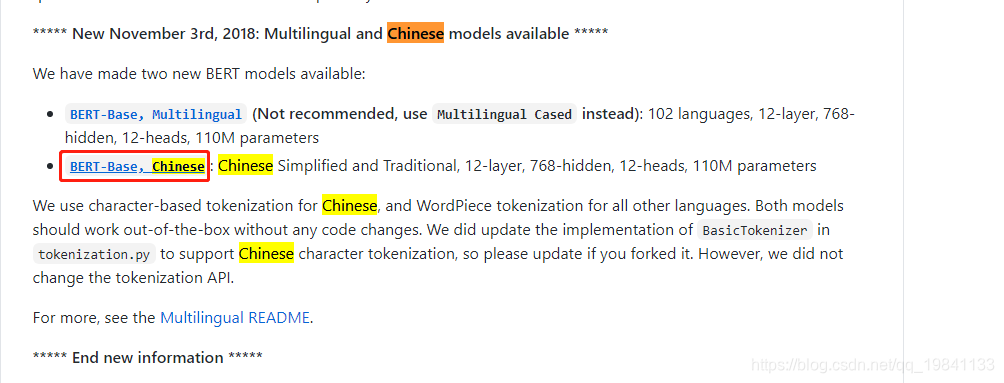
我用的是这个chinese_L-12_H-768_A-12.zip

这个预训练的模型的下载地址:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
下载好后打开bert的框架里面的run_classifier.py
找到class DataProcessor(object),这个数据处理的基类,复制一份,把类名改成自己的类名,我这里改成了MyProcessor,参数把DataProcessor传进去
class MyProcessor(DataProcessor): """Base class for data converters for sequence classification data sets.""" def get_train_examples(self, data_dir): """Gets a collection of `InputExample`s for the train set.""" raise NotImplementedError() def get_dev_examples(self, data_dir): """Gets a collection of `InputExample`s for the dev set.""" raise NotImplementedError() def get_test_examples(self, data_dir): """Gets a collection of `InputExample`s for prediction.""" raise NotImplementedError() def get_labels(self): """Gets the list of labels for this data set.""" raise NotImplementedError() @classmethod def _read_tsv(cls, input_file, quotechar=None): """Reads a tab separated value file.""" with tf.gfile.Open(input_file, "r") as f: reader = csv.reader(f, delimiter="\t", quotechar=quotechar) lines = [] for line in reader: lines.append(line) return lines

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
然后get_train_examples,get_dev_examples,get_test_examples这三个方法是处理数据集的,具体根据具体的训练任务来,我这里在网上找了个今日头条中文新闻(文本)分类的数据集,下载地址:https://github.com/skdjfla/toutiao-text-classfication-dataset
它的数据格式:6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,之后她的两个行为给自己加分_!_佟丽娅,网络谣言,快乐大本营,李浩菲,谢娜,观众们
用_!_分割,从前往后分别是 新闻ID,分类code,分类名称,新闻字符串(仅含标题),新闻关键词,下载出来是一个toutiao_cat_data.txt文本,然后我新建个.py来把这个文本切分成三分分别做train,test,dev
切分的代码:
具体思路是先把数据集切个8:2,8份给train,再从2份里面对半切给test和dev
import numpy as np f = open('data/toutiao_cat_data.txt', 'r', encoding='utf-8') train_list = [] for line in f.readlines(): print(line) if line == '': continue train_list.append(line) train_list = np.array(train_list) f.close() def split_train(data, test_ratio): np.random.seed(43) shuffled_indices = np.random.permutation(len(data)) test_set_size = int(len(data) * test_ratio) test_indices = shuffled_indices[:test_set_size] train_indices = shuffled_indices[test_set_size:] return data[train_indices], data[test_indices] train_data, tdev_data = split_train(train_list, 0.2) test_data, dev_data = split_train(tdev_data, 0.5) print(len(train_data), len(test_data), len(dev_data)) # 写入train file_train = open('data/toutiao_cat_data.train.txt', 'w', encoding='utf-8') for i in train_data: file_train.write(i) file_train.close() # 写入test file_test = open('data/toutiao_cat_data.test.txt', 'w', encoding='utf-8') for i in test_data: file_test.write(i) file_test.close() # 写入dev file_dev = open('data/toutiao_cat_data.dev.txt', 'w', encoding='utf-8') for i in dev_data: file_dev.write(i) file_dev.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
处理好后生成三个toutiao_cat_data.train.txt,toutiao_cat_data.test.txt,toutiao_cat_data.dev.txt文本
回到run_classifier.py的MyProcessor类,现在就可以写传入数据的方法
我是这么写的,具体思路是读文件,读取每一行,用split切分,再用InputExample方面把数据传进去,train,dev,test三个方法都做法都是类似的,最后一个是设置label的方法,这个看具体的数据label是啥,这里的数据集label是从100到116(105和111没有),其实等同于15分类任务
class MyProcessor(DataProcessor): """Base class for data converters for sequence classification data sets.""" def get_train_examples(self, data_dir): """Gets a collection of `InputExample`s for the train set.""" file_path = os.path.join(data_dir, 'toutiao_cat_data.train.txt') f = open(file_path, 'r', encoding='utf-8') train_data = [] index = 0 for line in f.readlines(): guid = "tarin-%d" % (index) line = line.replace('\n', '').split('_!_') print('text_a: ', line[3]) text_a = tokenization.convert_to_unicode(str(line[3])) print('label: ', line[1]) label = str(line[1]) train_data.append( InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) index += 1 return train_data def get_dev_examples(self, data_dir): """Gets a collection of `InputExample`s for the dev set.""" file_path = os.path.join(data_dir, 'toutiao_cat_data.dev.txt') f = open(file_path, 'r', encoding='utf-8') dev_data = [] index = 0 for line in f.readlines(): guid = "dev-%d" % (index) line = line.replace('\n', '').split('_!_') print('text_a: ', line[3]) text_a = tokenization.convert_to_unicode(str(line[3])) print('label: ', line[1]) label = str(line[1]) dev_data.append( InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) index += 1 return dev_data def get_test_examples(self, data_dir): """Gets a collection of `InputExample`s for prediction.""" file_path = os.path.join(data_dir, 'toutiao_cat_data.test.txt') f = open(file_path, 'r', encoding='utf-8') test_data = [] index = 0 for line in f.readlines(): guid = "dev-%d" % (index) line = line.replace('\n', '').split('_!_') print('text_a: ', line[3]) text_a = tokenization.convert_to_unicode(str(line[3])) print('label: ', line[1]) label = str(line[1]) test_data.append( InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) index += 1 return test_data def get_labels(self): """Gets the list of labels for this data set.""" return ["100", "101", "102", "103", "104", "106", "107", "108", "109", "110", "112", "113", "114", "115", "116"] @classmethod def _read_tsv(cls, input_file, quotechar=None): """Reads a tab separated value file.""" with tf.gfile.Open(input_file, "r") as f: reader = csv.reader(f, delimiter="\t", quotechar=quotechar) lines = [] for line in reader: lines.append(line) return lines
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
在main方法把我们自己的类添加进去 "qgfl": MyProcessor
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"qgfl": MyProcessor,
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编辑配置文件
--data_dir=../data \ --task_name=qgfl \ --vocab_file=../chinese_L-12_H-768_A-12/vocab.txt \ --bert_config=../chinese_L-12_H-768_A-12/bert_config.json \ --output_dir=qgfl_model \ --do_train=true \ --do_eval=true \ --init_checkpoint=../chinese_L-12_H-768_A-12/bert_model.ckpt \ --max_seq_length=150 \ --train_batch_size=32 \ --learning_rate=5e-5 \ --num_train_epochs=1 \
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
可以保存一个.sh来保存训练的命令
参考代码
export BERT_BASE_DIR=./chinese_L-12_H-768_A-12#这里是存放中文模型的路径 export DATA_DIR=../data #这里是存放数据的路径 python3 run_classifier.py \ --task_name=my \ #这里是processor的名字 --do_train=true \ #是否训练 --do_eval=true \ #是否验证 --do_predict=false \ #是否预测(对应test) --data_dir=$DATA_DIR \ --vocab_file=$BERT_BASE_DIR/vocab.txt \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ --max_seq_length=512 \#最大文本程度,最大512 --train_batch_size=4 \ --learning_rate=2e-5 \ --num_train_epochs=15 \ --output_dir=./mymodel #输出目录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
预测命令参考代码
export BERT_BASE_DIR=./chinese_L-12_H-768_A-12
export DATA_DIR=./mymodel
export ./mymodel
# TRAINED_CLASSIFIER为刚刚训练的输出目录,无需在进一步指定模型名称,否则分类结果会不对
python3 run_classifier.py \
--task_name=chi \
--do_predict=true \
--data_dir=$DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$TRAINED_CLASSIFIER \
--max_seq_length=512 \
--output_dir=./mymodel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
预测完后将会得到test_results.tsv,每一列表示这一行的样本是这一类的概率,结果不能是概率,而是类别, 所以我们写一个脚本进行转化
get_results.py
参考代码
import os import pandas as pd import numpy as np if __name__ == '__main__': path = "qgfl_model" pd_all = pd.read_csv(os.path.join(path, "test_results.tsv"), sep='\t', header=None) data = pd.DataFrame(columns=['result']) print(pd_all.shape) labels = ["100 民生 故事 news_story", "101 文化 文化 news_culture", "102 娱乐 娱乐 news_entertainment", "103 体育 体育 news_sports", "104 财经 财经 news_finance", "106 房产 房产 news_house", "107 汽车 汽车 news_car", "108 教育 教育 news_edu ", "109 科技 科技 news_tech", "110 军事 军事 news_military", "112 旅游 旅游 news_travel", "113 国际 国际 news_world", "114 证券 股票 stock", "115 农业 三农 news_agriculture", "116 电竞 游戏 news_game"] for index in pd_all.index: arr = np.array(pd_all.loc[index].values) max_index = int(np.argmax(arr)) print(max_index) data.loc[index + 1] = labels[max_index] data.to_csv(os.path.join(path, "pre_sample.tsv"), sep='\t') # print(data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33

