
- 1在vue和 js 、ts 数据中使用 vue-i18n,切换语言环境时,标签文本实时变化_vue-i18n $t
- 2MongoDB安装配置_mongodb配置
- 3Android 模拟器启动失败 解决方案_android 模拟器 qt library not found at
- 4【Machine Learning系列】带你快速学习十大机器学习算法_机器学习 优化 oee 算法
- 5【error】error: field * has incomplete type_error: field has incomplete type
- 6git merge 和 git rebese的区别
- 7JS-29-Promise对象
- 8【数据结构】链表经典练习题_链表的习题
- 9[docker]nvidia的cuda镜像列表
- 10使用python的selenium库进行对url进行批量访问和截图_python 批量打开网页并截图
大数据面试高频题目 - 深度解析 Kafka:探索实时数据流处理的关键技术
赞
踩
Kafka是实时数据流处理中的关键技术,被广泛应用于消息队列系统。透过高频面试题解析,我们将深入研究 Kafka 在数据传输和处理中的作用。无论你是初学者还是渴望加深对实时数据处理技术的了解,本文都将为你提供实用的面试准备。
一、生产者消息发送流程
1、获得要发送的数据,创建main线程
2、main线程创建producer对象,调用send()方法发送数据
3、判断是否有拦截器,拦截器是可插拔的,要用就添加,不用就不加,一般不进行使用
4、通过序列化器,会根据key和value的序列化配置进行序列化消息内容,生产者和消费者都必须使用相同的key-value方式
5、接下来是经过分区器,分区器决定数据发往什么分区,一个分区对应一个双端队列
6、数据保存在recordaccumulator中,默认大小为32M
7、一批数据producerbatch默认是16k
8、等producerbatch满了或数据等待时间超过linger.ms才发送
9、开辟sender线程负责具体数据的发送过程
10、sender线程利用sender对象读取内存的数据,由networkclient发送数据
11、在没有确定应答的情况下,网络客服端可以连续发送最多5个请求
12、selector主要负责打通发送端到kafka集群的通道
13、发送成功,先清除网络客服端中的请求数据,再清除内存中的一批数据producerbatch
14、发送失败,进行重试,重试次数为integer的最大值
二、kafka broker总体工作流程
1、服务器启动,在zookeeper中进行注册
2、谁先注册,哪一台服务器的controller说了算
3、由选举出来的controller监听broker节点的变化
4、controller决定选举机制
选举规则:在isr中存活为前提,按照ar中排在前面的优先
5、controller将节点信息同步给zookeeper
6、其他服务器的controller从zookeeper中同步相关信息
7、假设leader突然挂掉
8、controller监听到节点变化,从zookeeper中获取isr
9、选举新的leader
10、更新leader和isr
三、消费者组初始化流程
1、coordinator:辅助实现消费者的初始化和分区的分配
2、每个consumer都向coordinator发送加入消费者组的请求
3、coordinator选出一个consumer作为leader
4、coordinator把消费的topic情况发送给leader
5、leader负责制定消费方案
6、leader将消费方案发送给coordniator
7、coordinator将消费方案下发给每一个consumer
8、每个消费者都会和coordinator保持心跳,一旦超时,该消费者就会被移除,并触发再平衡,或者消费者处理消息的时间过长,也会触发再平衡
四、消费者组详细消费流程

五、kafka生产端分区分配策略
1、defaultpartitioner默认分区器
(1)指明partition的情况下,直接将指明的值作为partition值
(2)为指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
(3)既没有partition值也没有key的情况下,kafka采用粘性分区器,会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或已完成,会再选择一个分区进行使用
2、uniformstickypartitioner纯粹的粘性分区器
(1)如果在消息中指定了分区,则会按照指定的分区好进行分配
(2)如果未指定分区,则使用粘性分区器
3、roundrobinpartitioner轮询分区器
(1)如果在消息中指定了分区则使用指定分区
(2)如果未指定分区,都会将消息轮询每个分区,将数据平均分配到每个分区中
六、kafka丢不丢数据
1、producer角度
ack=0:生产者发送数据过来就不管了,可靠性差,效率高
ack=1:生产者发送过来数据leader应答,可靠性中等,效率中等
ack=-1:生产者发送过来数据leader和isr队列里面所有的follower应答,可靠性高,效率低
2、broker角度
副本数大于等于2
min.insync.replica大于等于2
七、数据完全可靠条件
ack级别设置为-1+分区副本数大于等于2+isr里应答的最小副本数大于等于2
八、幂等性
1、producer不论向broker发送多少次重复数据,broker端都只会持久化一条,保证了不重复
2、精确一次=幂等性+至少一次(ack级别设置为-1+分区副本数大于等于2+isr里应答的最小副本数大于等于2)
3、重复数据的判定标准:具有相同主键(<PID,Partition,SeqNumber>)的消息提交时,broker只会持久化一条。PID每次重启都会分配一个新的,partition代表分区号,seqnumber是单调递增的,所以幂等性只能保证的是单分区单会话内不重复
九、kafka如何保证数据有序
1、kafka最多只能保证单分区内的消息是有序的,所以如果要保证业务全局严格有序,就要设置topic为单分区
2、如何保证单分区内数据有序
(1)禁止重试,可能会导致数据丢失
(2)启用幂等,设置缓存的请求数小于等于5,设置重试次数大于0,设置acks=-1
十、kafka为什么能够高效读写数据
1、kafka本身是分布式集群,可以采用分区技术,并行度高
2、顺序写磁盘,省去了大量磁头寻址的时间
3、读数据采用稀疏索引,可以快速定位要消费的数据
4、页缓存+零拷贝
(1)零拷贝:kafka的数据加工处理都交由kafka生产者和kafka消费者处理,kafka broker应用层不关心数据,所以不用走应用层,传输效率高
(2)页缓存:kafka底层重度依赖pagecache。当上层有写操作时,操作系统只是将数据写入pagecache。当读操作发生时,先从pagecache中查找,如果找不到,再去磁盘中读取。实际上pagecache是把尽可能多的空闲内存当作磁盘缓存来使用
十一、kafka消费端分区分配策略
1、range—对于每个topic而言

2、roundrobin—对于集群中所有topic而言
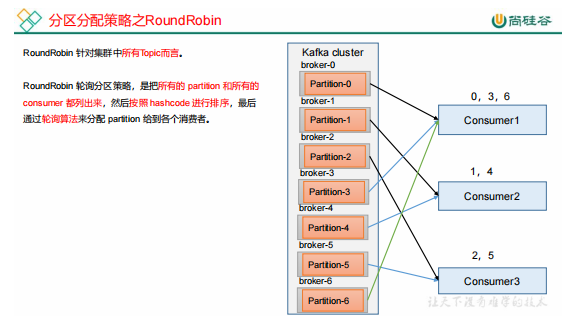
十二、消费者再平衡的条件
1、consumer group组成员发生变化
2、订阅主题的数量或者分区发生变化
3、消费者故障下线
4、在现有集中增加消费者
十三、如何解决数据积压的问题
1、消费者消费能力不足
(1)可以考虑增加topic的分区数,同时增加消费者组的消费者数量
(2)提高每批次拉取的数量,提高单个消费者消费的能力
fetch.max.bytes:消费者获取服务端一批消息最大的字节数
max.poll.records:一次poll拉取数据返回消息的最大条数,默认是500条
2、消费者处理能力不行—提高下下面两个参数
fetch.max.bytes:消费者获取服务端一批消息最大的字节数
max.poll.records:一次poll拉取数据返回消息的最大条数,默认是500条
3、消息积压后如何处理
(1)优先查看日志是否有大量的消费错误
(2)此时如果日志没有错误的话,可以通过打印堆栈信息,看一下消费线程卡在哪里
十四、kafka如何提升吞吐量
1、提高生产吞吐量
提高发送消息的缓冲区大小
提高batchsize大小
设置linger.ms
采用压缩
2、增加分区
3、消费者提高吞吐量
思考:kafka分区数可以增加或减少吗?为什么

