
热门标签
热门文章
- 1SQL语句_在dbms中建立“学生-课程”数据库,其关系逻辑模式如下:student(学生表):stude
- 2ZedBoard教程PS篇(5):XADC测量输入电压_zedboard的ps端如何学习?
- 3码云 Gitee 的 WebHooks 实现代码自动化部署_gitee 自动部署至iis
- 4通用的预训练模型:All NLP Tasks Are Generation Tasks: A General Pre-training Framework_all nlp tasks are generation tasks: a general pret
- 5i茅台app逆向分析frida反调试_frida process terminated
- 6c语言题目求π近似值_从键盘输入一个较小的实数,用下面的公式求π的近似值
- 7sql在线模拟器_力荐一款在线SQL模拟器
- 8stable diffusion 参数说明_stable diffusion no half vae
- 9一文梳理大数据四大方面十五大关键技术
- 10全面解析Web3社交:深层次的链上社交将成为可能_web3网络用户行为
当前位置: article > 正文
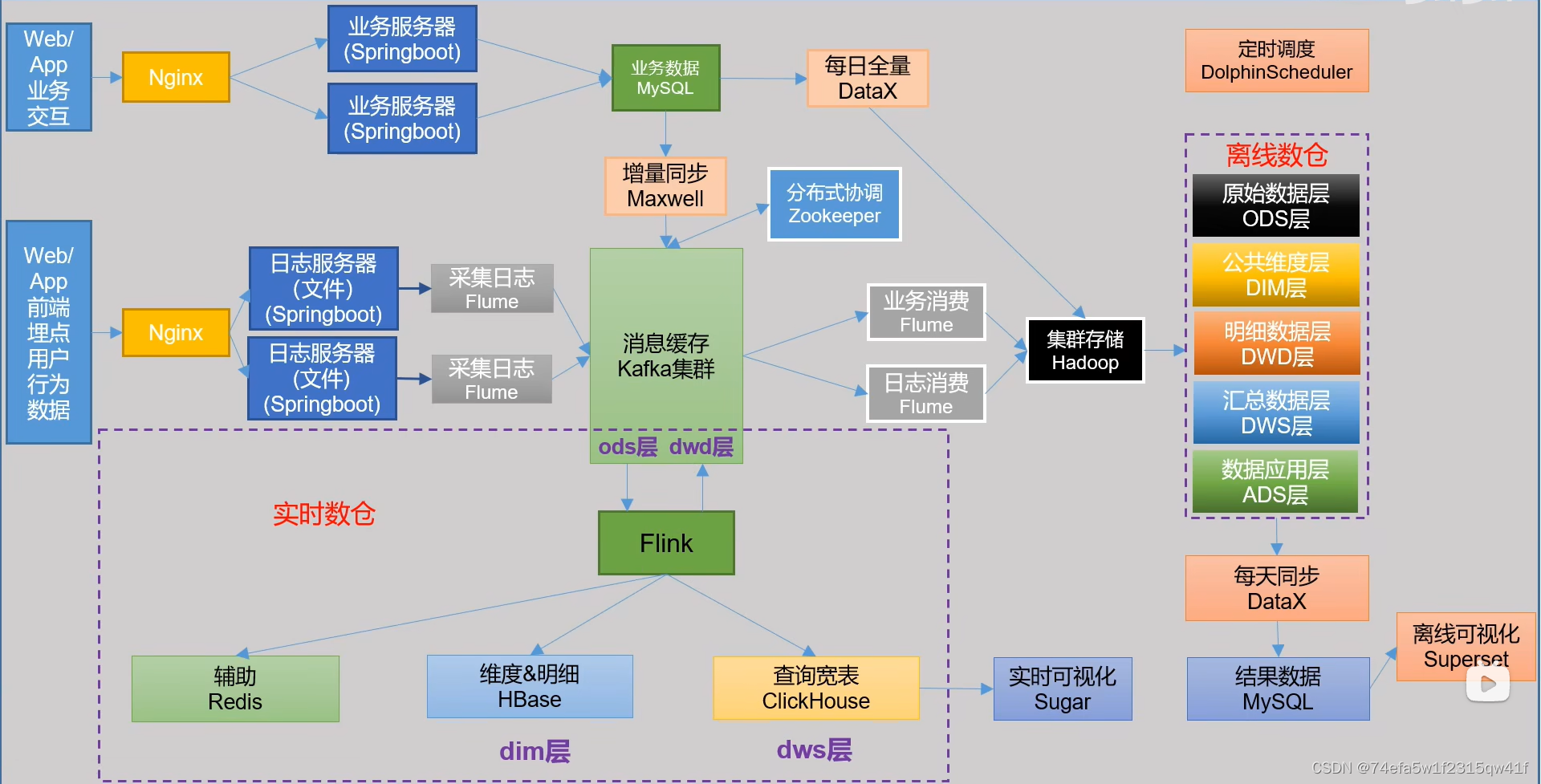
实时数仓选型
作者:Cpp五条 | 2024-04-24 02:33:39
赞
踩
实时数仓选型
实时数仓选型第一版
实时数仓分层:
计算框架:Flink;存储框架:消息队列(可以实时读取&可以实时写入)
- 1
ODS:Kafka
使用场景:每过来一条数据,读取到并加工处理
- 1
DIM: HBase
使用场景:事实表会根据主键获取一行维表数据(1.永久存储、2.根据主键查询)
HBase:海量数据永久存储,根据主键快速查询 √
Redis:用户表数据量大,内存数据库 x
ClickHouse:并发不行,列存 x
ES:默认给所有字段创建索引 x
Mysql本身:压力太大,实在要用就使用从库 (mysql 要主从读写分离)v
- 1
- 2
- 3
- 4
- 5
- 6
DWD:Kafka
使用场景:每过来―条数据,读取到并分组累加处理
- 1
DWS:ClickHouse
Kafka 使用场景:每过来一条数据,实时读取到并重新分组、累加处理(聚合计算)(列存计算)(再次加工数据时,更有优势)
- 1
为什么不用 kafka flink?
DWS:用户、省份、商品 GMV (商品交易总和)
到
ADS:用户 GMV
省份 GMV
商品 GMV
省份、商品 GMV(重复聚合计算)
用kafak就要用flink计算,每计多算一个指标,就多一个实时任务(耗资源)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
ADS:不落盘,不存储。实质上时接口模块,查询ClickHouse的SQL语句(SQL查ClickHouse)
使用场景:读取最终结果直接给大屏,进行数据展示
- 1
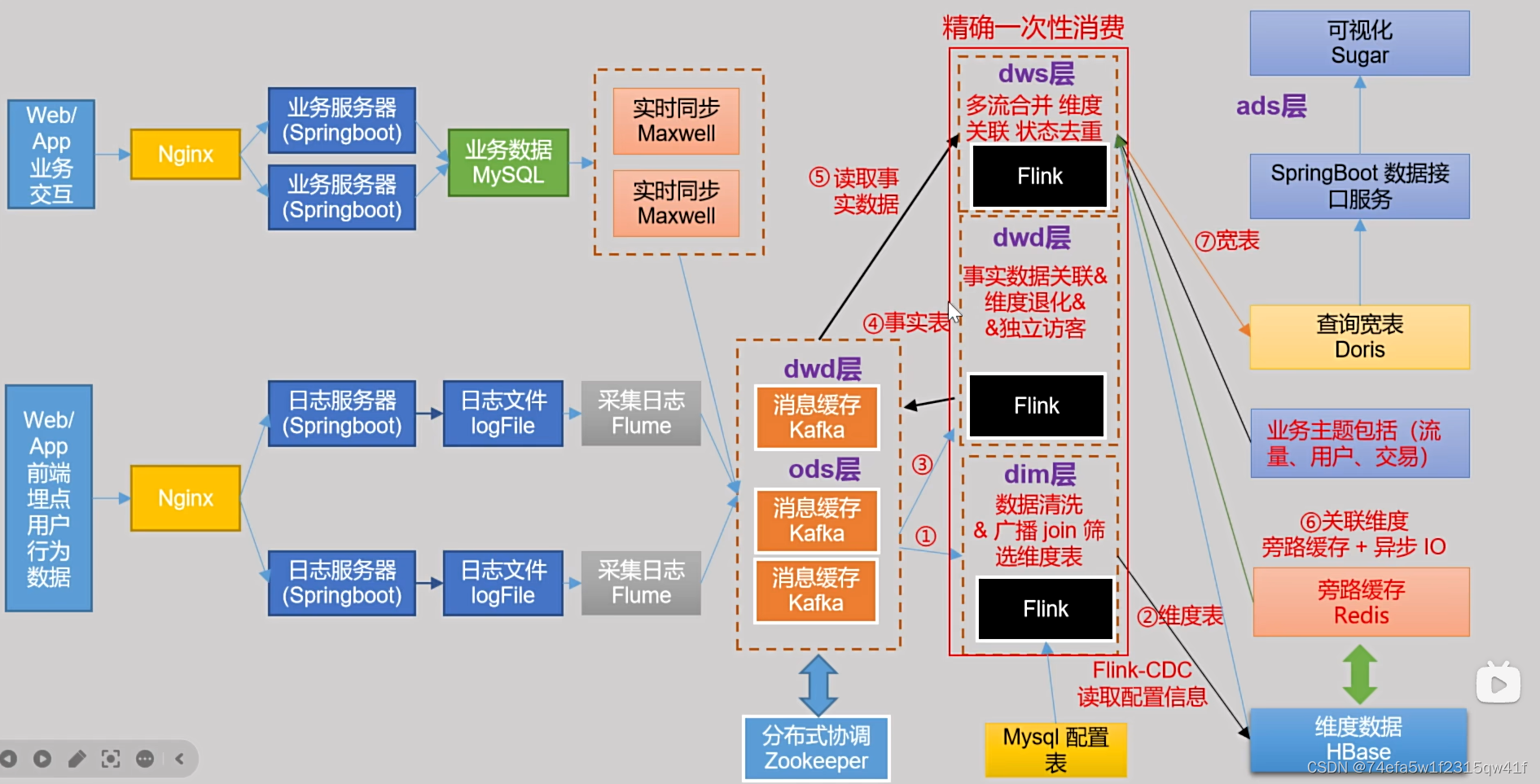
实时数仓选型第二版
ods:
kafka对应的主题topic_db topic_log
- 1
dwd:
保持数据流的形式进行下一步的聚合
存储到kafka ->主题名称对应不同的事实表
- 1
- 2
dim:
存储维度表等待数据聚合之后来进行维度关联join操作
- 1
-mysql:快 不适合海量数据的存储
-redis:更快 数据不是永久化存储的
hbase:一般 数据键值对存储 getKey()速度快一些 适合海量的数据 (最合适)
-doris:快 适合海量数据 使用成本较高 尽量不要将原始数据大量存储到doris(现在不需要,适合查询时使用)
-clickHouse: 列式存储 **列式数据聚合操作**(dim维度表里面不会进行列式数据的计算,但dwd dws 会) 速度非常快
- 1
- 2
- 3
- 4
- 5
hbase(数据存储 契合后续的数据使用 getKey读取) + redis(旁路缓存 提升速度)
- 1
dws:
读取dwd数据进行聚合->开窗聚合(10s)再进行维度关联
后续进行灵活的数据接口编写同时能够实现即席查询的功能
doris最适合(之前存储到clickHouse)
- 1
- 2
- 3
ads:
spring boot编写数据接口读取doris数据
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/477197
推荐阅读
相关标签

