
热门标签
热门文章
- 1LeetCode 114. 二叉树展开为链表_public static void flatten(treenode root){
- 2Spring Boot进阶(06):【超详细】Windows10搭建RabbitMQ Server服务端,让你轻松实现消息队列管理!_rabbitmq服务开启windows10
- 3结合实际案例谈谈项目管理经验_项目管理案例草船借箭
- 4第十四章 Vision Transformer网络详解_vit-b/32
- 5STM32学习和实践笔记(15):STM32中断系统
- 6安卓逆向-加固后的APK包_libnesec.so
- 7网络安全等级保护是什么_网络平台安全等级保护
- 8java序列化和反序列化
- 9nacos配置注册中心时指定命名空间不起作用_nacos namespace不生效
- 10极客公园对话 Zilliz 星爵:大模型时代,需要新的「存储基建」
当前位置: article > 正文
HBase完全分布式配置(上)hadoop篇 保姆级教程(近乎零基础跟着配也能配对)_完全分布式免密设置
作者:Cpp五条 | 2024-04-25 02:54:57
赞
踩
完全分布式免密设置
本文从安装好新虚拟机开始介绍
1.基础环境配置
1.1静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO="static"- IPADDR="192.168.88.11"
- GATEWAY="192.168.88.2"
- NETMASK="255.255.255.0"
- DNS="192.168.88.2"

1.2配置hosts
vim /etc/hosts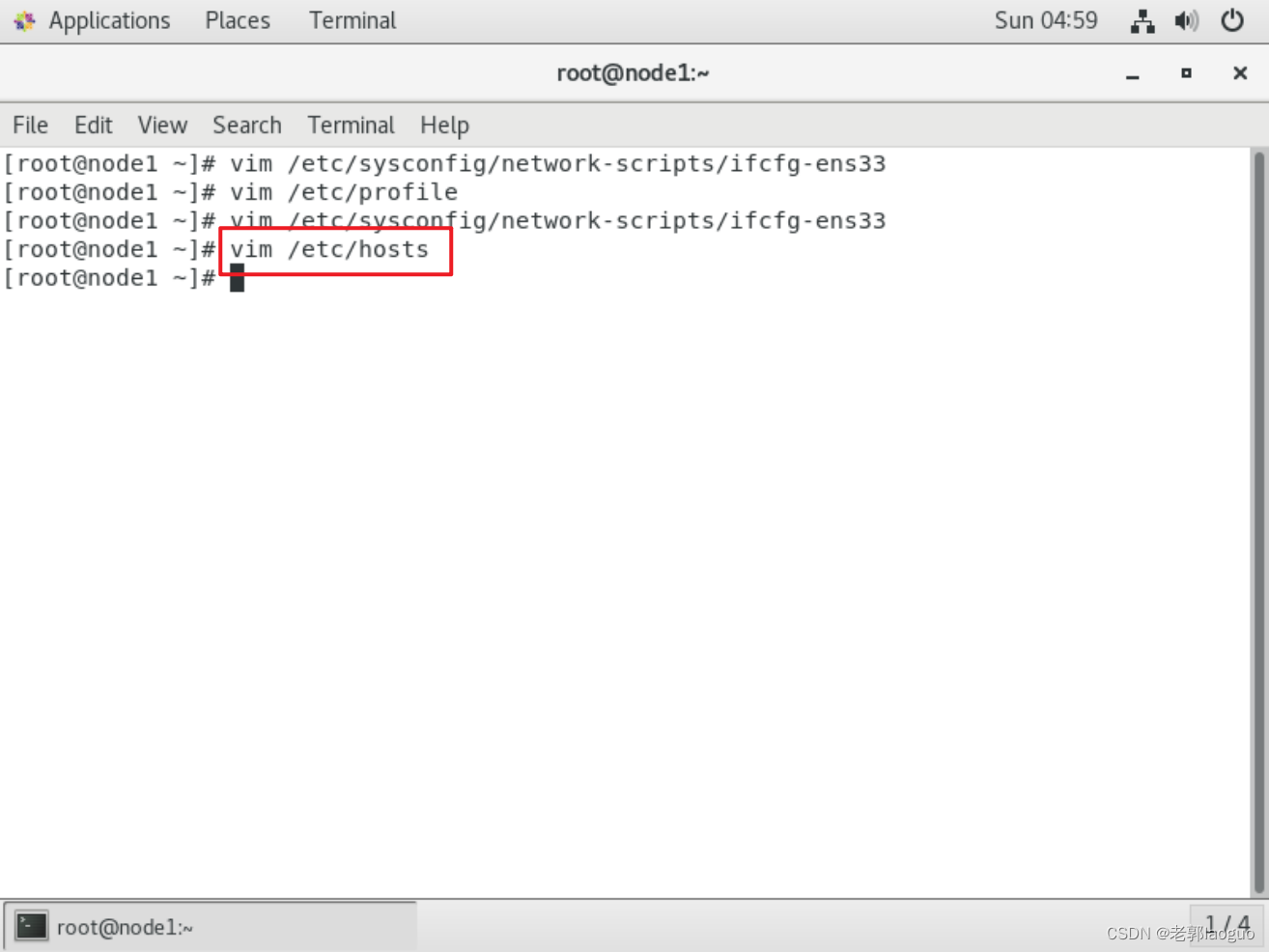
- 192.168.88.11 node1
- 192.168.88.12 node2
- 192.168.88.13 node3

1.3配置主机名
hostnamectl set-hostname node11.4关闭防火墙
systemctl stop firewalldsystemctl disable firewalld1.5关闭selinux
setenforce 0vim /etc/sysconfig/selinux改成
SELINUX=disabled1.6配置ssh免密登录
ssh-keygen -t rsacp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys基础配置详细(带截图)可以看我的Hadoop和hbase伪分布式模式配置一文。这里不再详细展开,接下来转到tabby连接上并上传jdk、hadoop和hbase,同样不再赘述。解压、改名,详见上一篇文章,这里只截取环境变量配置好的图片。
1.7jdk解压、改名
mkdir -p /export/server解压jdk:
tar -zxvf /usr/local/jdk-8u401-linux-x64.tar.gz -C /export/server/改名jdk:
mv /export/server/jdk1.8.0_401 /export/server/jdk1.8配置并应用环境变量
vim /etc/profile- export JAVA_HOME=/export/server/jdk
- export PATH=$PATH:$JAVA_HOME/bin

source /etc/profile到此为止可以把这台虚拟机克隆两份了,分别叫node2和node3,注意要放到不同的文件夹下。
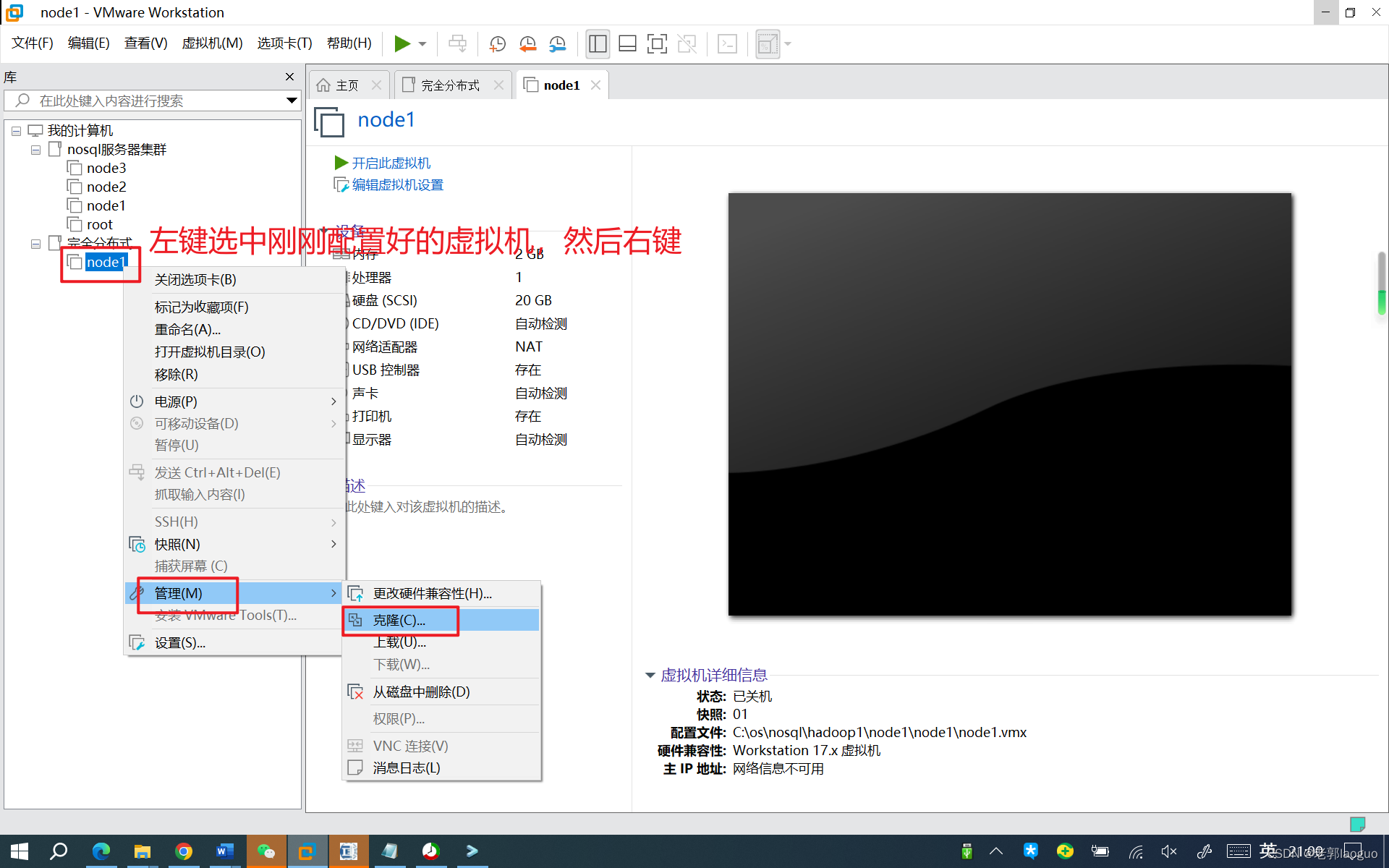

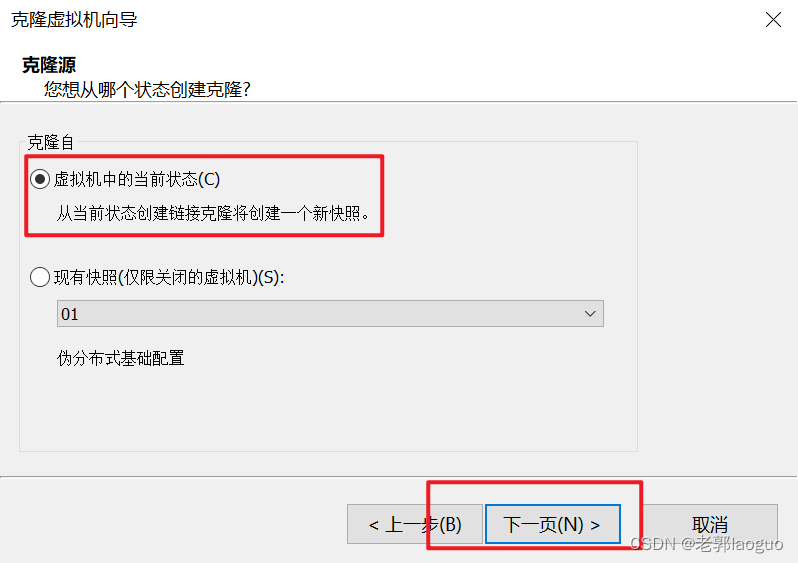
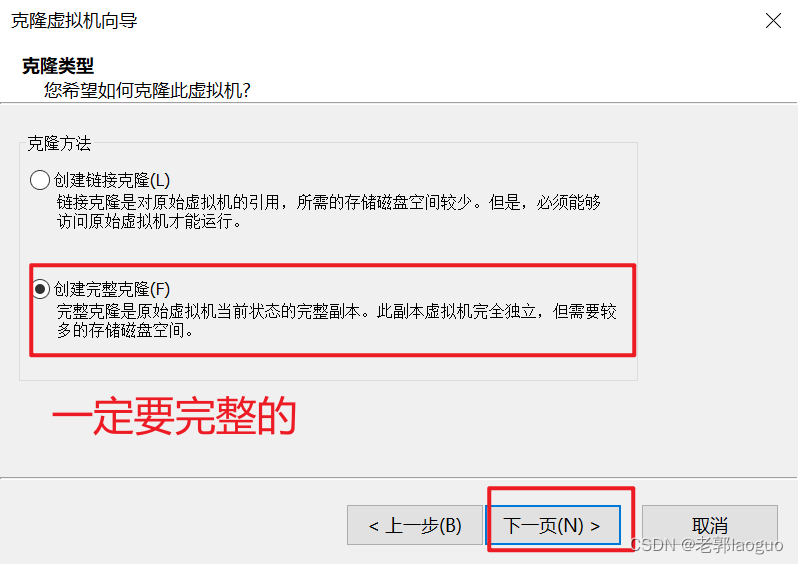
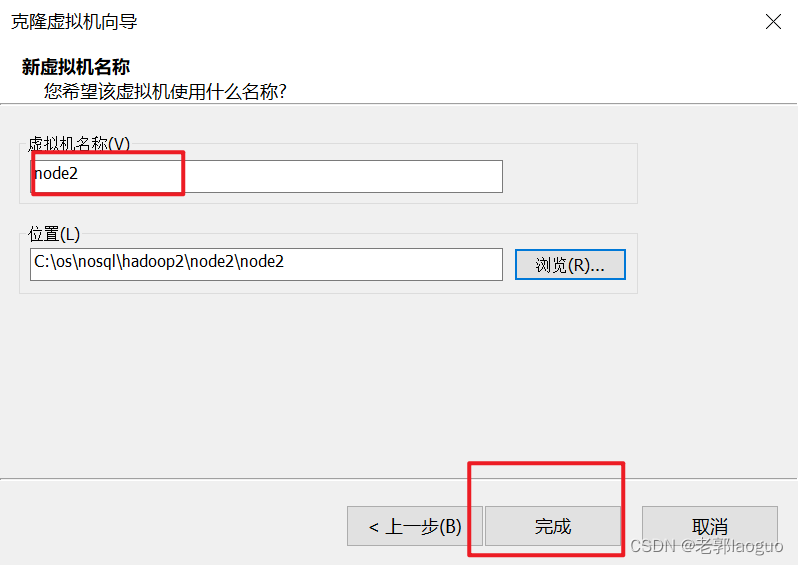
node3同理
2.克隆之后的修改(两台同时修改,不要弄混)
2.1改主机名(是几改几)
hostnamectl set-hostname node2hostnamectl set-hostname node32.2修改静态ip
三台虚拟机的ip不能相同,最后一位改下就行,别忘了出来重启下网卡
vim /etc/sysconfig/network-scripts/ifcfg-ens33systemctl restart network3.hadoop完全分布式配置
3.1解压、改名和配置、应用环境变量
解压hadoop:
tar -zxvf /usr/local/hadoop-2.7.7.tar.gz -C /usr/local/改名hadoop:
mv /usr/local/hadoop-2.7.7 /usr/local/hadoopvim /etc/profile- export HADOOP_HOME=/usr/local/hadoop
- export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile别忘了把另外两台从机配置一下环境变量再应用一下,否则会出现命令不存在的问题
3.2配置hadoop-env.sh
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh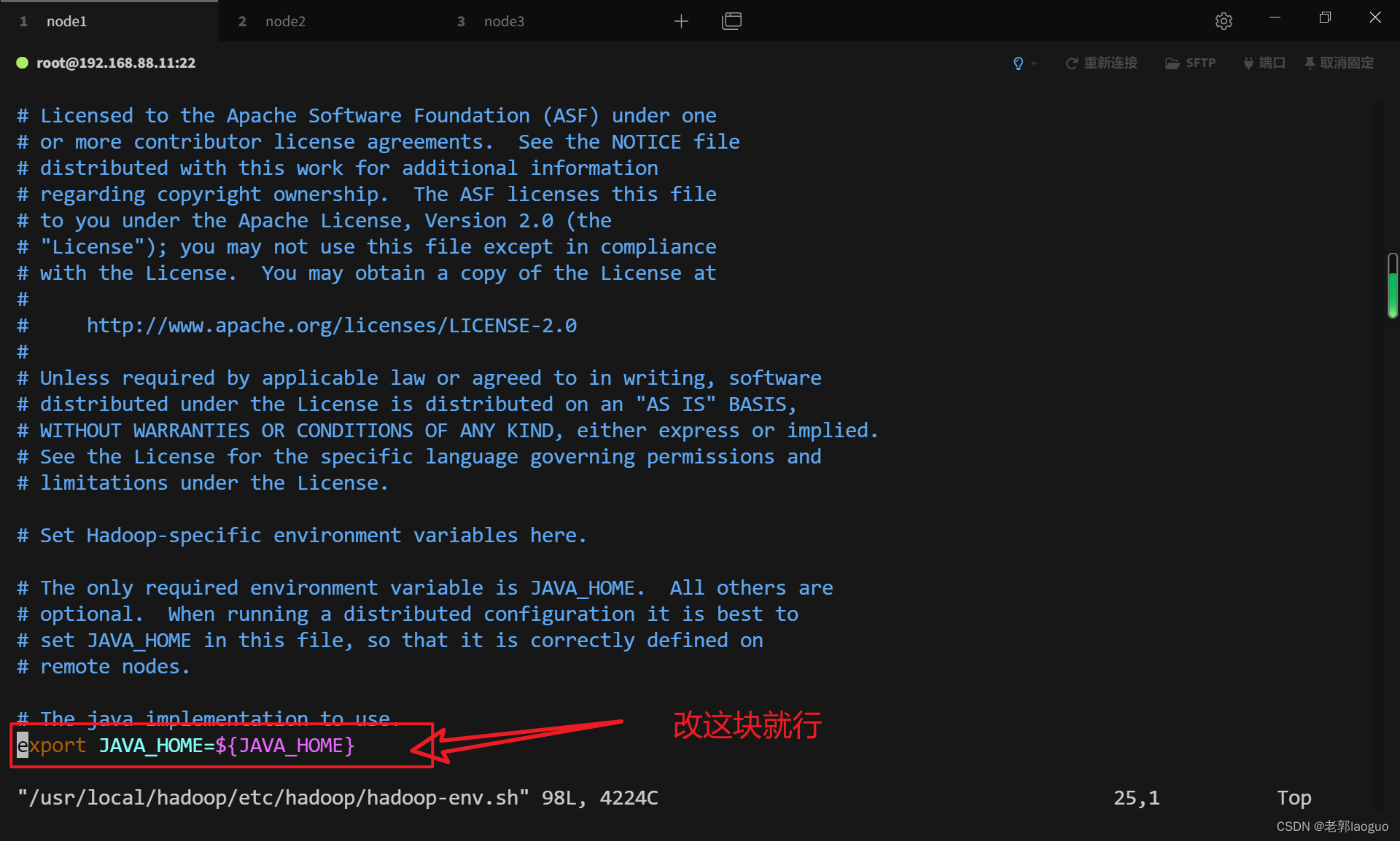
export JAVA_HOME=/export/server/jdk3.3配置core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml
- <property>
- <!--主机映射名-->
- <name>fs.defaultFS</name>
- <value>hdfs://node1:9000</value>
- </property>
-
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/usr/local/hadoop/tmp</value>
- </property>
3.4配置hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
-
- <property>
- <!--主机映射名-->
- <name>dfs.namenode.secondary.http-address</name>
- <value>node3:50090</value>
- </property>
3.5配置mapred-env.sh
vim /usr/local/hadoop/etc/hadoop/mapred-env.sh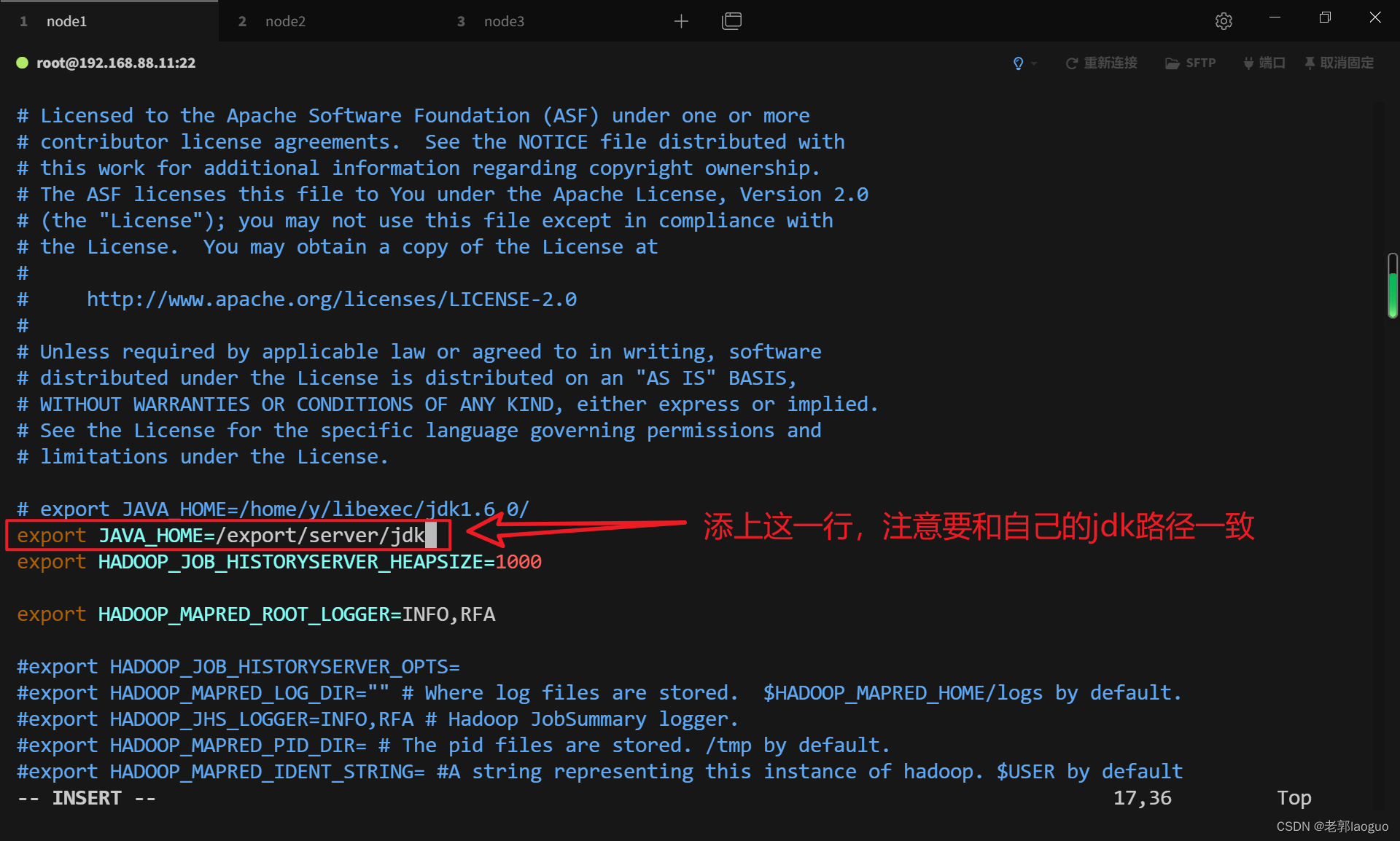
export JAVA_HOME=/export/server/jdk3.6配置mapred-site.xml
配置前先复制一份(因为没有)
cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xmlvim /usr/local/hadoop/etc/hadoop/mapred-site.xml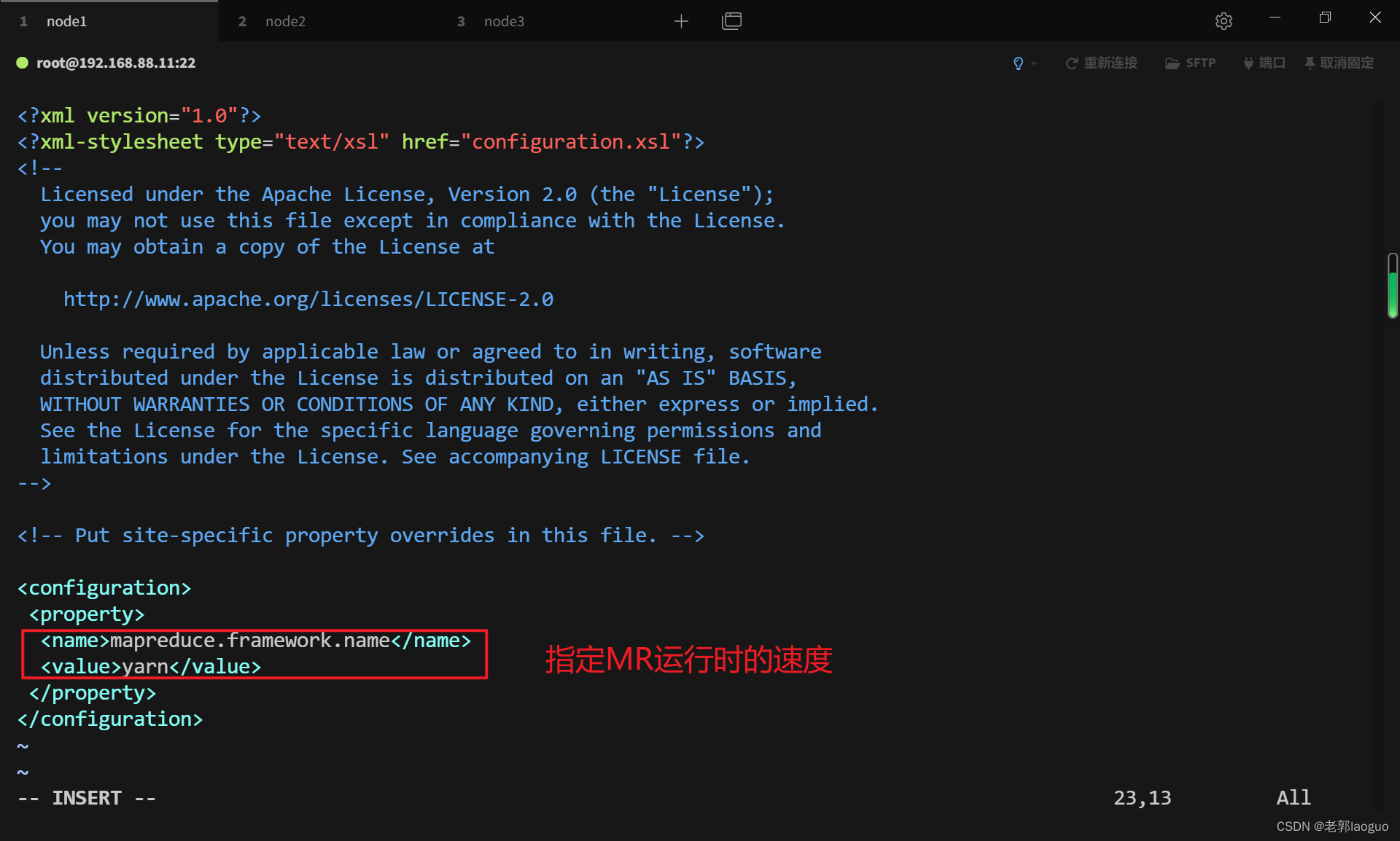
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
3.7配置yarn-env.sh
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
export JAVA_HOME=/export/server/jdk3.8配置yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml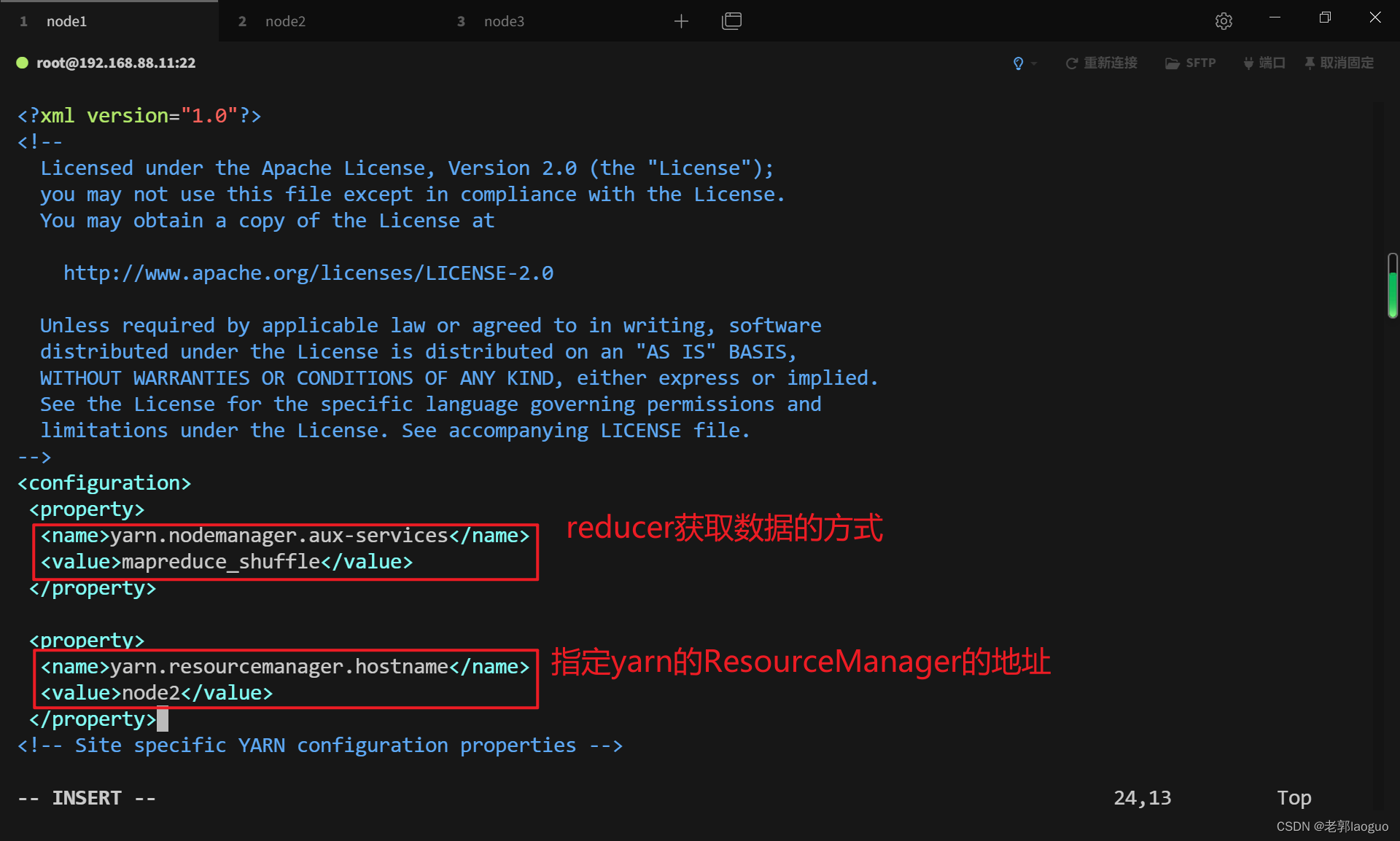
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>node2</value>
- </property>
3.9配置slaves
vim /usr/local/hadoop/etc/hadoop/slaves
- node1
- node2
- node3
3.10把主机上配好的内容分发到从机上
scp -r /usr/local/hadoop root@node2:/usr/localscp -r /usr/local/hadoop root@node3:/usr/local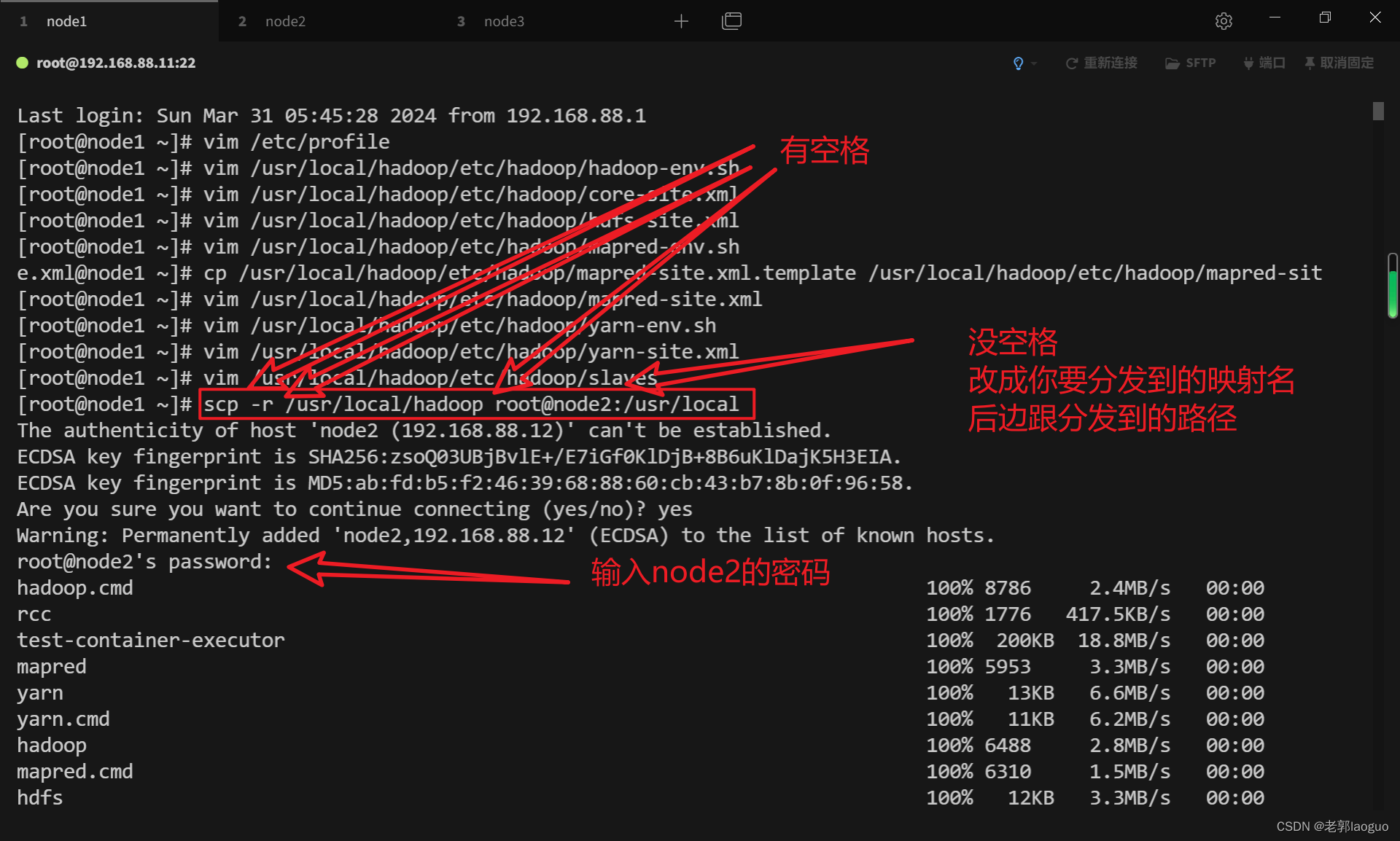
3.11格式化主机
只格式化主机node1,从机node2和node3不用格式化,格式化前可以打个快照保存一下,防止前面有地方配错了没查出来。
显示没有命令错误的问题在于环境变量没有配置好,要么去配置环境变量并应用,要么去hadoop下的bin目录下执行,前面加上(./)代表命令在当前目录下
hadoop namenode -format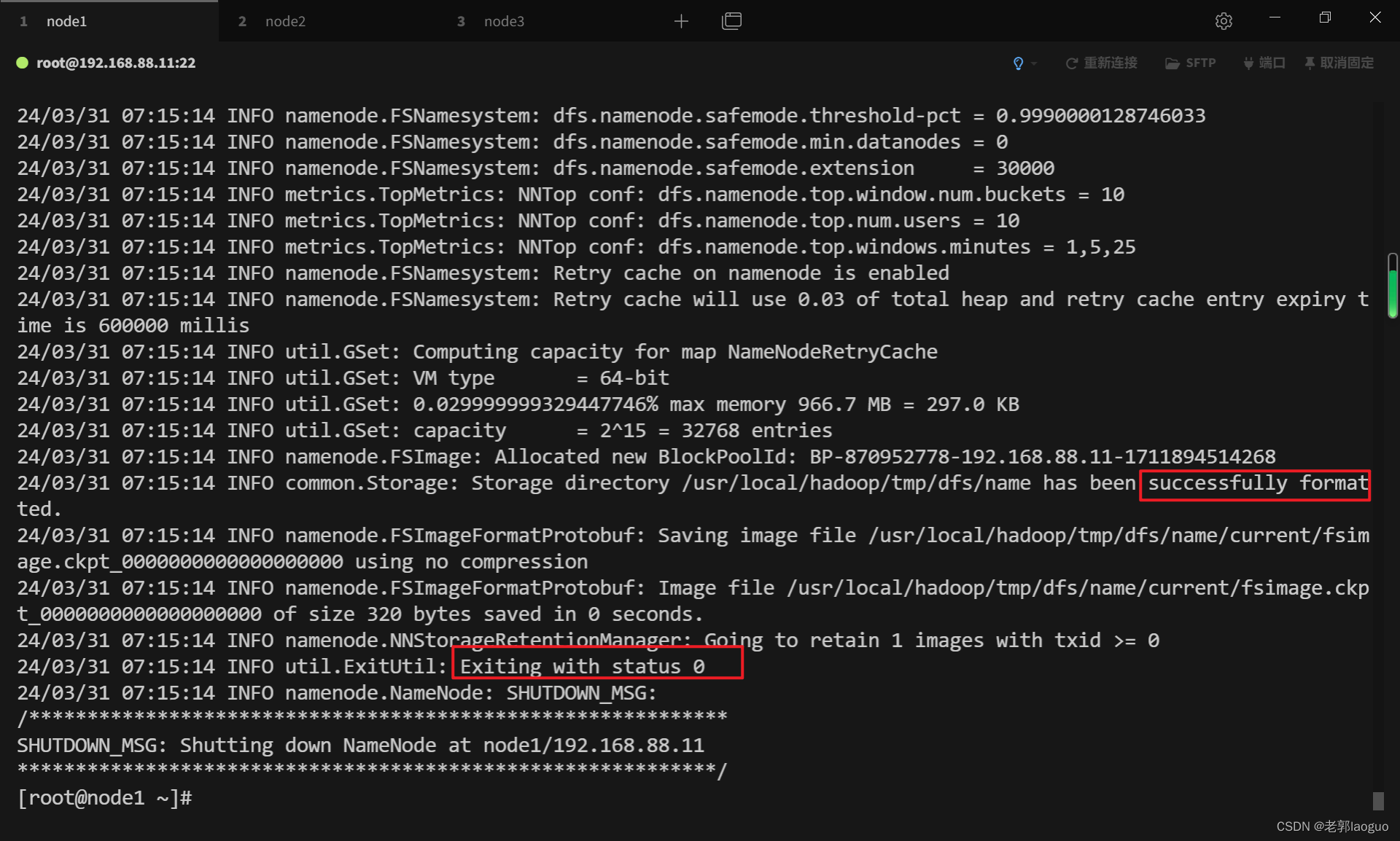
3.12设置免密钥并授权给三台虚拟机
三台都要把下面的代码输一遍(从rsa到node3都要输一遍)
ssh-keygen -t rsa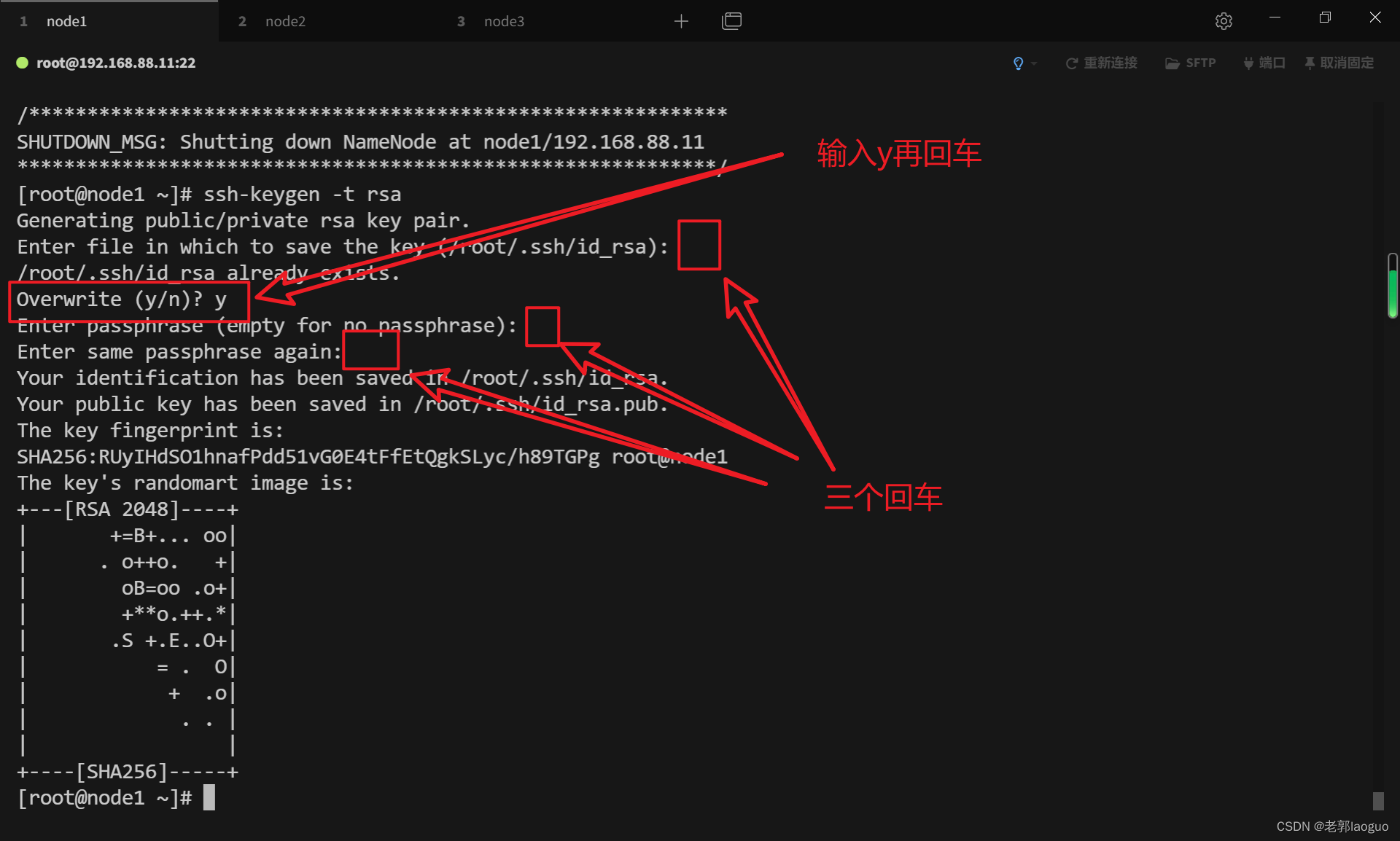
ssh-copy-id -i ~/.ssh/id_rsa.pub node1ssh-copy-id -i ~/.ssh/id_rsa.pub node2ssh-copy-id -i ~/.ssh/id_rsa.pub node3只展示其中一个

3.13开启主机和从机验证
只在主机(node1)和其中一个从机(例如node2)输入命令,从机之二只开启不输命令,先启动主机再启动从机。
显示没有命令错误的问题在于环境变量没有配置好,要么去配置环境变量并应用,要么去hadoop下的sbin目录下执行,前面加上(./)代表命令在当前目录下
主机:
start-dfs.sh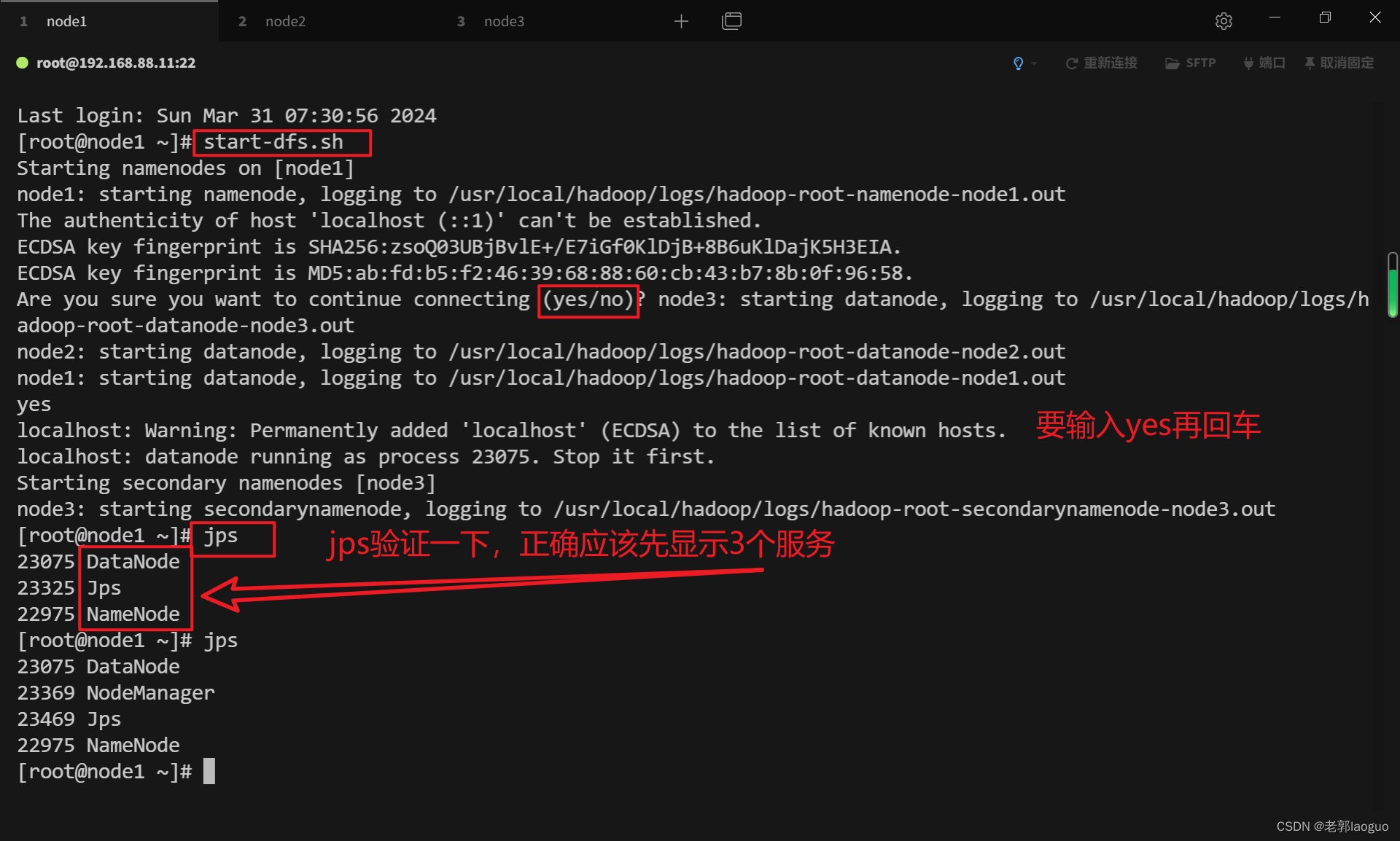

从机:
start-yarn.sh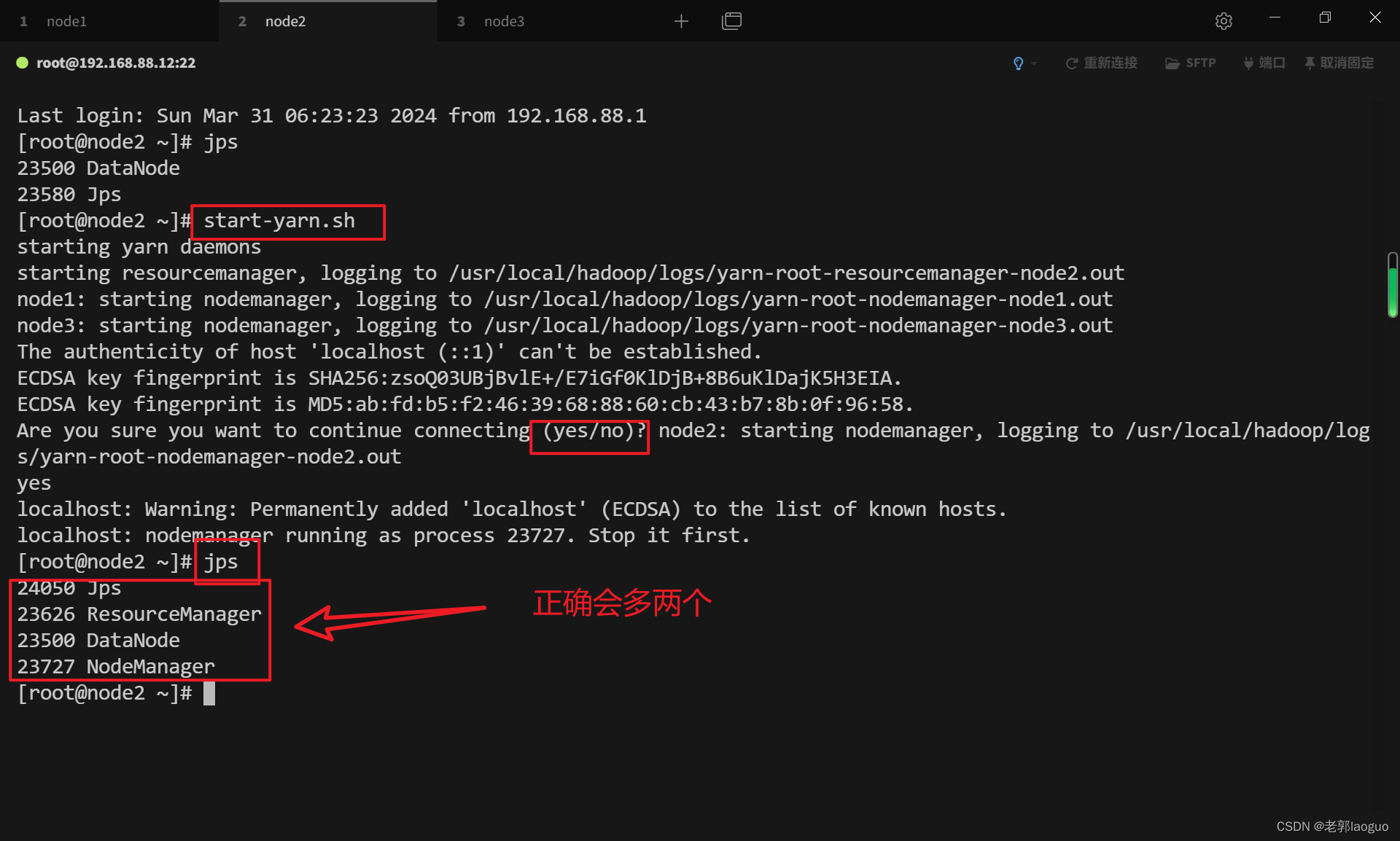

关闭同样是先关从机再关主机
从机:
stop-yarn.sh

主机:
stop-dfs.sh

至此,hadoop完全分布式配置完毕,别忘了打个快照保存一下
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/482880
推荐阅读
相关标签

