
- 1微信小程序 uniapp+vue城市公交线路查询系统dtjl3
- 2小程序和公众号三级分销模式的设计和实现_三级分销小程序
- 3代码自动生成工具------阿里 imgcook(图像大厨)体验版发布!_imgcook官网
- 4这么理解TLS协议,以及TLS协议的握手过程
- 5华为OD 技术综合面,手撕代码真题整理(六):最短超级序列 | 数组中的逆序对_华为od面试有手撕代码吗
- 6一文带你了解深度学习与PyTorch_pytorch和深度学习的关系
- 7互联网,大数据和人工智能对我们的生活带来的影响_简述互联网/大数据/人工智能技术对日常生活的影响
- 8集合的嵌套遍历
- 9实操Hadoop大数据高可用集群搭建(hadoop3.1.3+zookeeper3.5.7+hbase3.1.3+kafka2.12)_hadoop3.1.3 高可用部署
- 10MySQL及MySQLworkbench安装教程_安装mysql和mysql workbench
一文搞懂“布隆过滤器“原理(附Java代码实战)_布谷鸟过滤器 ts代码
赞
踩
引言
最近在学习隐私计算时了解到布谷鸟过滤器的概念(后面会专门写篇博客介绍),自然也就联系到了本文的主角—布隆过滤器。关于布隆过滤器的名号我很久之前就听说过了,但是一直没有深入了解,今天就系统性学习一下并通过这篇博客记录下来。废话不多说,开始吧!
布隆过滤器(Bloom Filter)是1970年由布隆(虽然我搜遍全网也没找到老先生的照片)提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
布隆过滤器,在合理的使用场景中具有四两拨千斤的作用,由于使用场景是在大量数据的场景下,所以这东西类似于秒杀,虽然没有真的落地用过,但是也要说的头头是道。
常见于面试环节:比如大集合中重复数据的判断、缓存穿透问题等。
布隆过滤器的原理
首先,布隆过滤器作为一个"过滤器"而不是数据库,它并不存储数据本身,而是告诉我们某个元素是否存在而已。
当然也许有人会说,我们使用传统的数据库MySQL也能告诉我们某个元素是否存在,SELECT查一下就好了啊,但数据库需要存储所有的数据元素,成本又高效率又低。
而我们的布隆过滤器只需要一个比特bit数组和三个哈希函数,这自然就会让我们的空间效率和查询时间都优于一般的算法。
对于布隆过滤器,有一个重中之重的概念:
布隆过滤器说存在的元素,真实不一定存在;而布隆过滤器说不存在的,真实一定不存在。
下面来看一下布隆过滤器的数据结构,其实很简单:
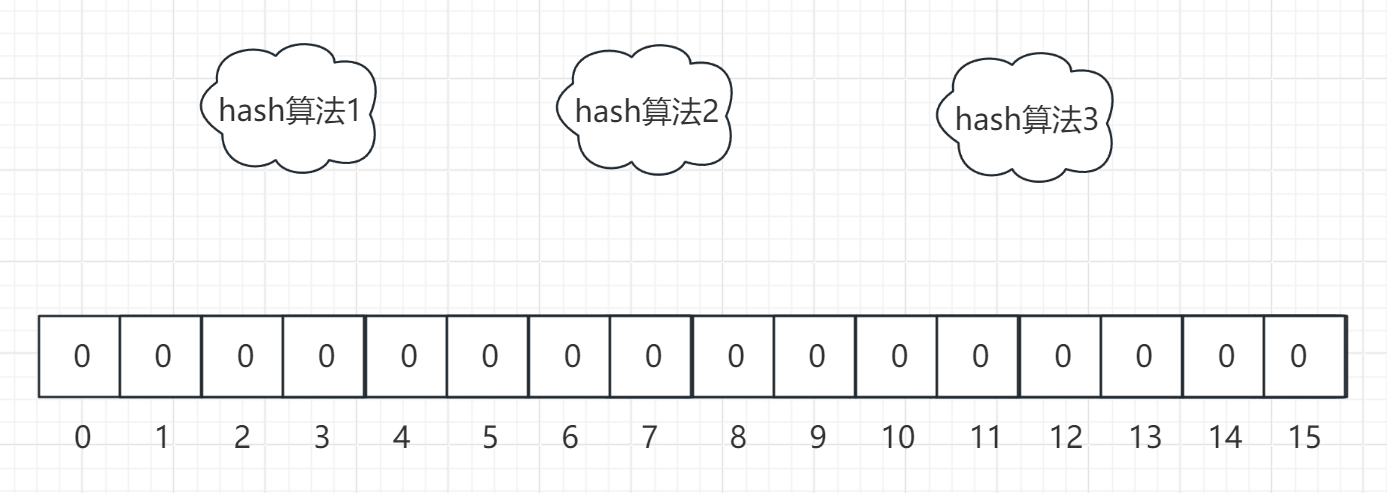
如上图所示,一共有三个hash算法,以及一个带有初始长度 m 的数组,数组的各位上存放的是bit,要么0要么1,默认全为0。在这种情况下,就算我们申请一个 m=100万的数组,其占用空间也就 1000000bit/8/1024 ≈ 122KB。
增加元素
当我们要将一个元素插入到布隆过滤器时,会执行如下操作:
- 各个hash函数对元素进行计算求得hash值(此hash值被限定在数组长度m以内);
- 将数组对应位置的bit置为 1;
下图形象展示了这个过程:
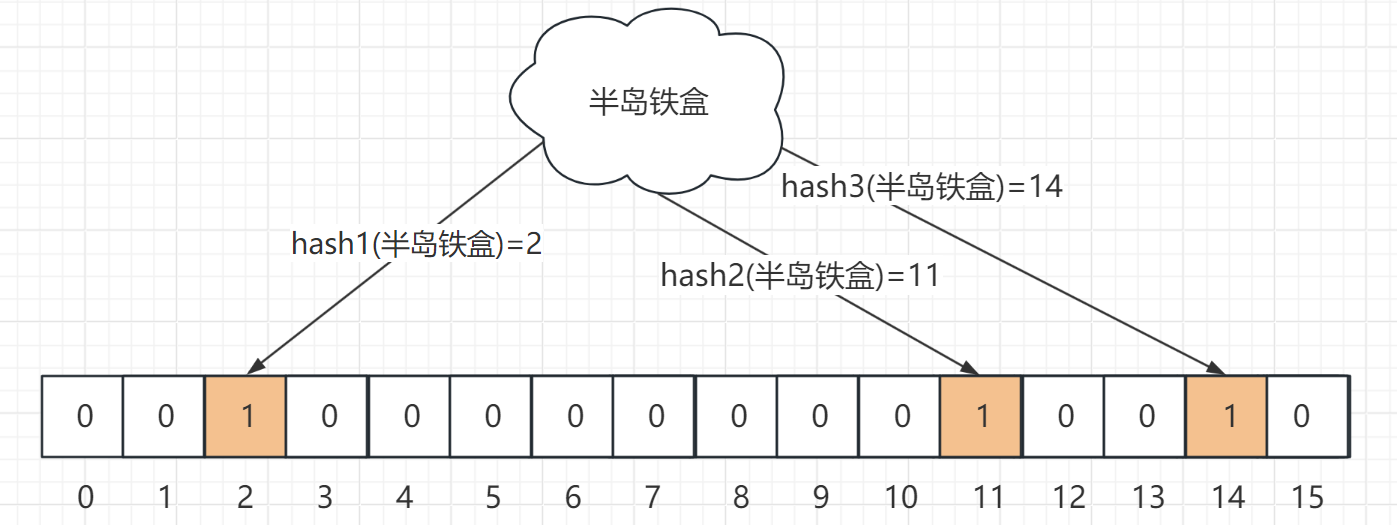
这样,如果再来一个元素"半岛铁盒",那么三个hash函数算到的还是下标为2、11、14三个同样的位置。
我们再模拟插入一个元素:
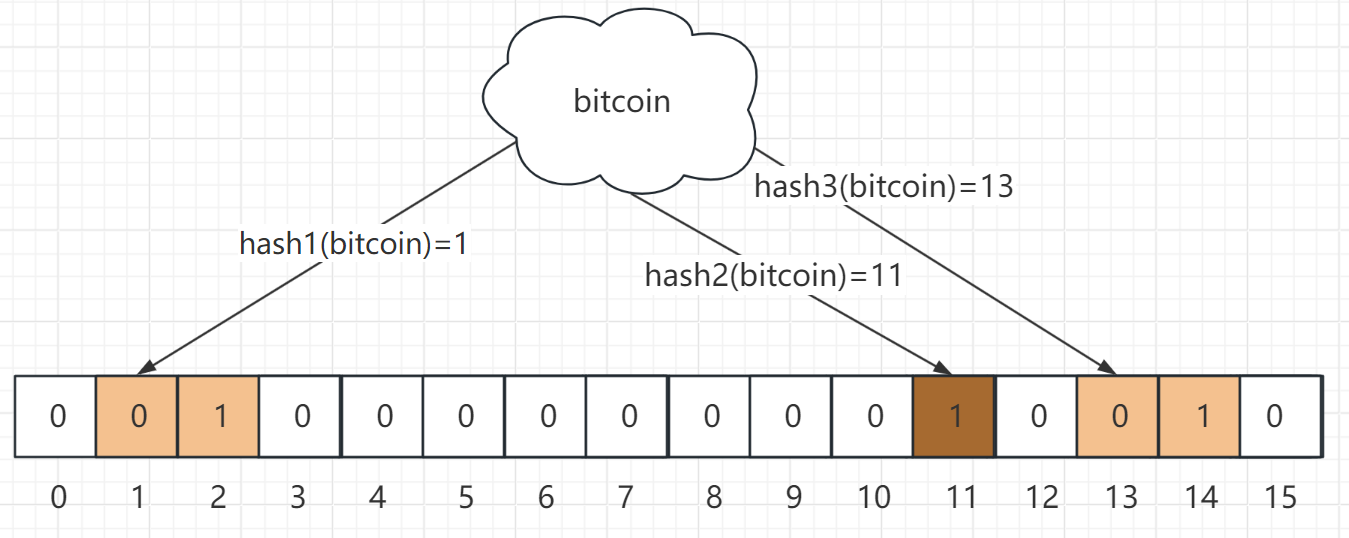
此时我们插入元素"bitcoin",经过hash计算得到的三个数组下标为1、11、13,我们会发现,对于"半岛铁盒"和"bitcoin",在hash2上计算结果都是11,也就是说有两个元素指向了下标11,也就是常说的哈希碰撞。
OK,此时我们的比特数组是这样的:

只看这个数组,我们能直接在里面找到元素"半岛铁盒"和"bitcoin"吗?
很显然不能,所以接下来就要讲布隆过滤器的查询。
查询元素
我们应该怎么知道元素"bitcoin"有没有经过此布隆过滤器呢?
很简单,对于要查询的元素"bitcoin",只需要用三个hash函数计算它的hash:
hash1(“bitcoin”) = 1
hash2(“bitcoin”) = 11
hash3(“bitcoin”) = 13
接下来我们去下标1、11、13找,如果对应的比特值全为1,就说明元素"bitcoin"有可能来过。注意,这里是有可能,因为我们之前说过:布隆过滤器说存在的元素,真实不一定存在。
比如对于元素"可口可乐",假设我们通过hash函数算出来的三个hash值为:2、13、14。观察数组,我们会发现这三个下标处的比特位是1,那么我们就说,元素"可口可乐"是可能存在的。然而我们知道,在之前我们并没有插入过这个元素,这就说明布隆过滤器是存在一定的误报率的。
产生误报率的原因就显而易见了,我们的hash函数会发生碰撞:
- case 1:元素"可口可乐"和元素"德芙巧克力"经过三个hash函数,得到的运算结果是一样的;
- case 2:元素"可口可乐"运算后得到的三个下标上的比特位,已经被之前的多个元素在"共同努力"下全部覆盖到并设置为1了。
而对于我们之前说过的后半句:布隆过滤器说不存在的,真实一定不存在。大家想必也能想清楚了,举个例子:对于元素"拿铁咖啡",假设我们经hash计算后得到的三个值为:1、2、6,哪怕其中的1、2处的比特为1,但是在index=6处的比特位是0,那么我们就可以笃定"拿铁咖啡"一定没有经过布隆过滤器。
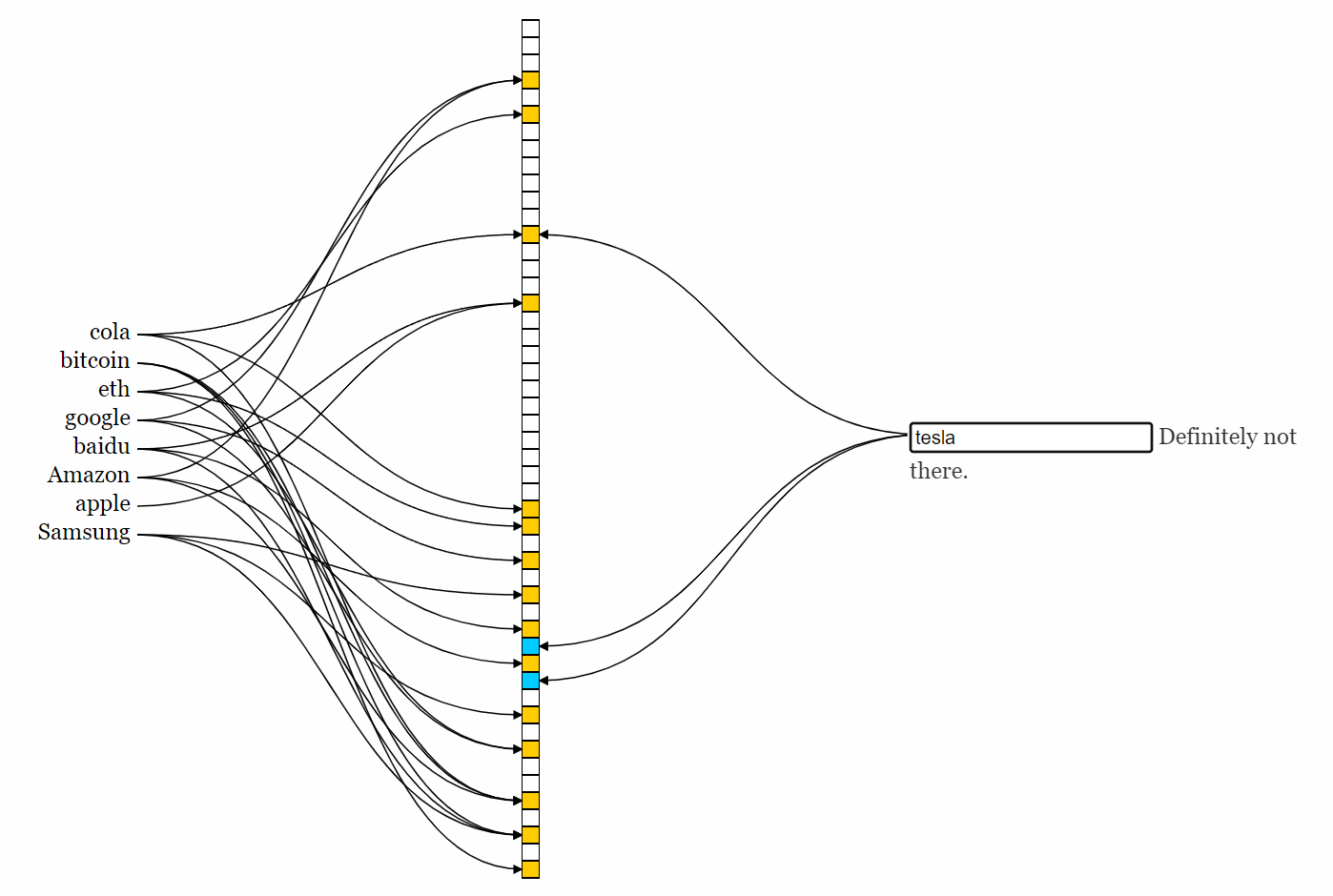
这里给出一个网站,可以直接上手玩一下布隆过滤器。
删除元素
布隆过滤器对元素的删除,肯定不可以,会出现问题,比如上面添加元素的 bit 位 11被两个变量的哈希值共同覆盖的情况下,一旦我们删除其中一个值。例如“半岛铁盒”而将其置位 0,那么下次判断另一个值例如“bitcoin”是否存在的话,会直接返回 false,而实际上我们并没有删除它,这就导致了误判的问题。
优缺点分析
布隆过滤器的优点:
- 支持海量数据场景下高效判断元素是否存在;
- 布隆过滤器存储空间小,并且节省空间,不存储数据本身,仅存储hash结果取模运算后的位标记;
- 不存储数据本身,比较适合某些保密场景;
缺点:
- 不存储数据本身,所以只能添加但不可删除,因为删掉元素会导致误判率增加;
- 由于存在hash碰撞,匹配结果如果是“存在于过滤器中”,实际不一定存在;
- 当容量快满时,hash碰撞的概率变大,插入、查询的错误率也就随之增加了;
应用场景
下面给出了一些布隆过滤器的应用场景:
- 区块链中使用布隆过滤器来加快钱包同步;以太坊使用布隆过滤器用于快速查询以太坊区块链的日志
- 数据库防止穿库,Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能
- 判断用户是否阅读过某一个视频或者文章,类似抖音,刷过的视频往下滑动不再刷到,可能会导致一定的误判,但不会让用户看到重复的内容
- 网页爬虫对URL去重,采用布隆过滤器来对已经爬取过的URL进行存储,这样在进行下一次爬取的时候就可以判断出这个URL是否爬取过了
- 使用布隆过滤器来做黑名单过滤,针对不同的用户是否存入白名单或者黑名单,虽然有一定的误判,但是在一定程度上还是很好的解决问题
- 缓存击穿场景,一般判断用户是否在缓存中,如果存在则直接返回结果,不存在则查询数据库,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到则穿透到数据库查询。如果不在布隆过滤器中,则直接返回,会造成一定程度的误判
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
没有想到布隆过滤器的应用这么广泛吧,在场景容忍误判的情况下,布隆过滤器是大有可为的。
布隆过滤器的实现
Guava实现
Guava是google开源的工具包,含有这些常用的模块:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等。在github上有39.9k的stars,可见其受欢迎程度。
下面我们来看个Guava自带的布隆过滤器的实战demo:
public class MyTest { private static int size = 100000; // 预期数据量 private static double fpp = 0.01; // 期望的误报率 private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size,fpp); public static void main(String[] args) { for (int i = 0; i < 100000; i++) { bloomFilter.put(i); } long start = System.nanoTime(); int count = 0; for (int i = size; i < size+100000; i++) { if(bloomFilter.mightContain(i)){ count++; System.out.println(i+"被误报了"); } } System.out.println("总耗时:"+(System.nanoTime()-start)/1_000_000+" ms"); System.out.println("总误报率次数"+count); System.out.println("总误报率:"+count*100/100000+"%"); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
output:
...
...
...
199172被误报了
199240被误报了
199243被误报了
199273被误报了
199336被误报了
199700被误报了
199919被误报了
总耗时:23 ms
总误报率次数1018
总误报率:1%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
多试几次,我们可以发现误报率是符合我们最开始设定的预期fpp的。
那么期望误报率fpp是不是越小越好呢?
显然不是的,越小的fpp需要的存储空间越大,需要的哈希函数也越多。
自己实现
public class BloomFilter { // 位数组,用于存储布隆过滤器的状态 private BitSet bitSet; // 位数组的长度 private int bitSetSize; private int expectedNumberOfElements; // hash函数数量 private int hashFunctions; private Random random = new Random(); //public BloomFilter(){} public BloomFilter(int bitSetSize,int expectedNumberOfElements) { this.bitSetSize = bitSetSize; this.expectedNumberOfElements = expectedNumberOfElements; this.hashFunctions = (int) Math.round(Math.log(2.0) * bitSetSize / expectedNumberOfElements); this.bitSet = new BitSet(bitSetSize); } public void add(Object element){ for (int i = 0; i < hashFunctions; i++) { long hash = calcHash(element.toString(),i); int index = getIndex(hash); bitSet.set(index,true); } } public boolean mightContains(Object element){ for (int i = 0; i < hashFunctions; i++) { long hash = calcHash(element.toString(),i); int index = getIndex(hash); if(!bitSet.get(index)){ return false; } } return true; } private int getIndex(long hash) { return Math.abs((int)(hash%bitSetSize)); } private long calcHash(String element, int seed) { random.setSeed(seed); byte[] bytes = element.getBytes(); long hash = 0x7f52bed27117b5efL; for(byte b:bytes){ hash^=random.nextInt(); hash*=0xcbf29ce484222325L; hash^=b; } return hash; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55


