
- 1Ubuntu 根目录扩容
- 2以面向对象的思想,编写自定义类描述图书信息。设定属性包括:书名,作者,出版社名,价格;设置属性的私有访问权限,通过公有的get,set方法实现对属性的访问_创建一个图书类,类中的属性有:书名 作者 出版社;方法有:设置书籍状态 查看书籍状态。其中书籍状态有
- 3我丢,去面试初级Java开发岗位,被问到泛型?_什么级别会问泛型问题
- 4OceanBase开发者大会震撼来袭
- 5HarmonyOS实战开发-拼图、如何实现获取图片,以及图片裁剪分割的功能。_鸿蒙 分割图片
- 6Python实现树的遍历以及恢复_python 遍历树
- 7【介绍下如何使用CocoaPods】
- 8测试开发 | 相比 Selenium,Web 自动化测试框架 Playwright 有哪些强大的优势?
- 9详解C语言中的自定义类型(结构体,枚举,联合)_c语言结构变量 枚举变量 联合变量
- 10C#之冒泡排序_c#冒泡排序
RAG应用程序的12种调优策略:使用“超参数”和策略优化来提高检索性能_rag向量检索有什么优化方法
赞
踩
本文从数据科学家的角度来研究检索增强生成(retrieve - augmented Generation, RAG)管道。讨论潜在的“超参数”,这些参数都可以通过实验来提高RAG管道的性能。与本文还将介绍可以应用的不同策略,这些策略虽然不是超参数,但对性能也会产生很大的影响。
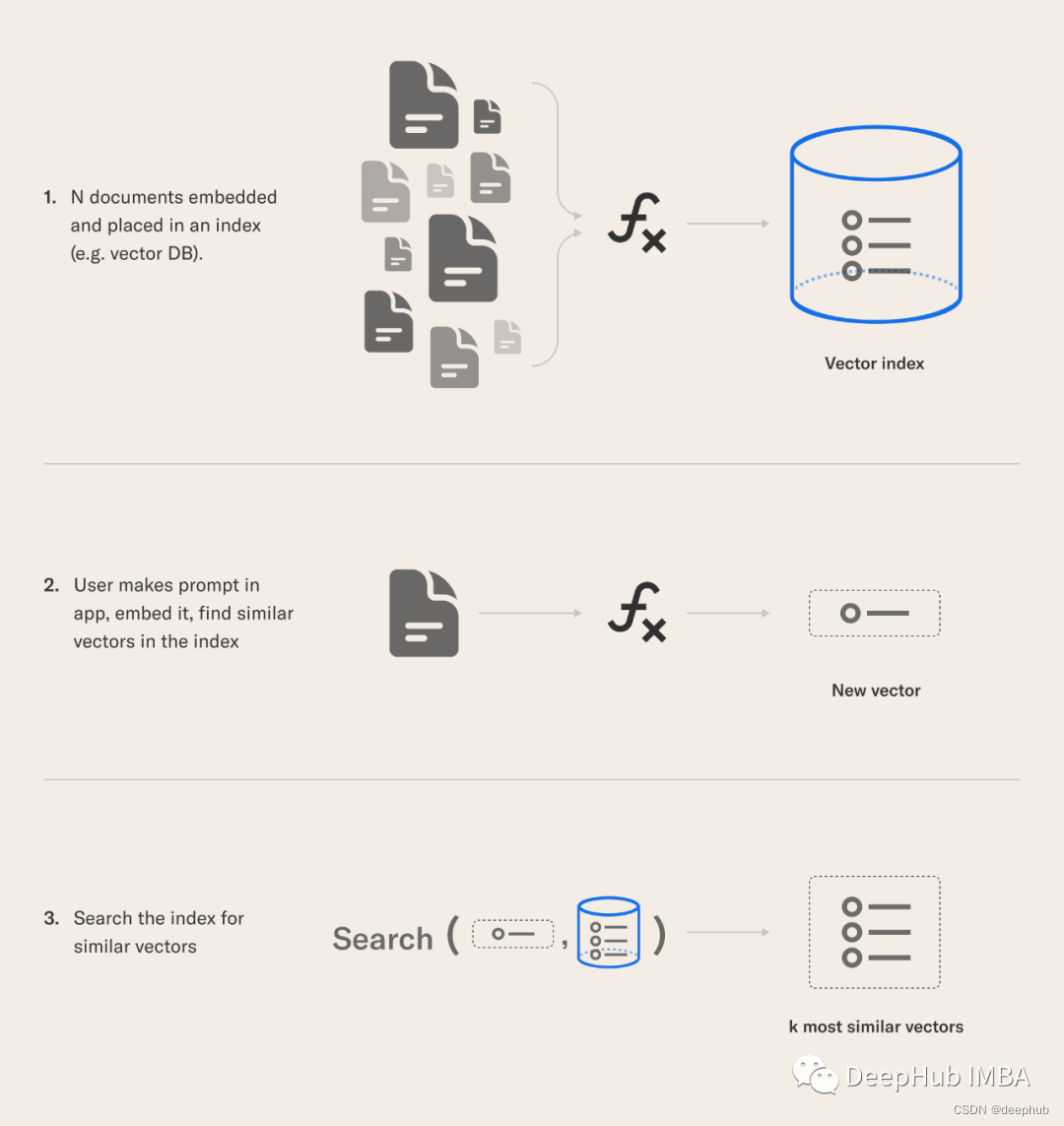
本文将介绍以下索引阶段的“超参数”。
- 数据清理
- 分块
- 嵌入模型
- 元数据
- 多索引
- 索引算法
在推理阶段(检索和生成),可以通过一下策略进行调优:
- 查询转换
- 检索参数
- 高级检索策略
- 评估模型
- llm
- 提示工程
注意,本文涵盖了RAG的文本用例。对于多模式RAG应用程序,可能需要考虑不同的因素。
数据索引
数据的索引摄取阶段是构建RAG管道的准备步骤,类似于ML管道中的数据清理和预处理步骤。通常,摄入阶段包括以下步骤:
- 收集数据
- 数据分块
- 生成块的矢量嵌入
- 在矢量数据库中存储矢量嵌入和块
本节讨论可以应用和调优的有效技术和超参数,以便在推理阶段提高检索上下文的相关性。
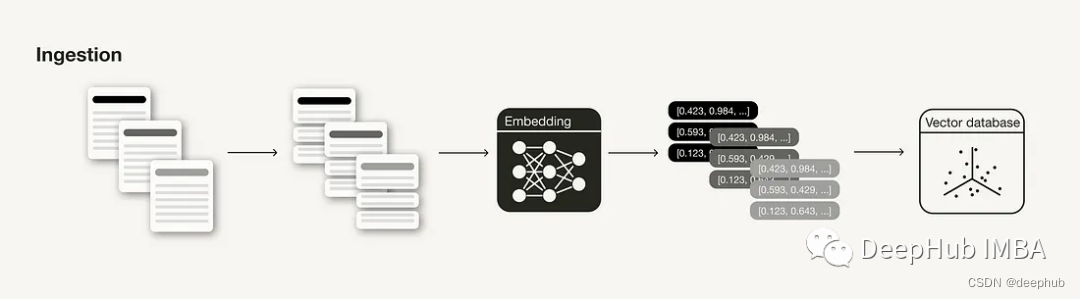
1、数据清理
与任何数据科学管道一样,数据的质量严重影响RAG管道中的结果[8,9]。
应用一些自然语言处理中常用的基本数据清理技术,例如确保所有特殊字符都被正确编码。确保信息是一致和准确的,以避免相互矛盾的信息混淆你的LLM。
2、文本分块
对的文档进行分块处理是在RAG管道中的外部知识来源的必要准备步骤,这可能会影响性能[1,8,9]。它通常通过将长文档分解成更小的部分(但它也可以将更小的片段组合成连贯的段落)。
需要考虑的一个问题是分块技术的选择。例如,在LangChain中,不同的文本分割器通过不同的逻辑(如字符、标记等)来分割文档。这取决于拥有的数据类型。例如,如果输入数据是代码而不是Markdown文件,则需要使用不同的分块技术。
块的理想长度(chunk_size)取决于用例:如果用例是回答问题,可能需要更短的特定块,但是如果用例是总结,则可能需要更长的块。此外如果一个块太短,它可能没有包含足够的上下文,如果一个块太长,它可能包含太多不相关的信息。
初上面基本要求外,还需要考虑块之间的“滚动窗口”(重叠),以引入一些额外的上下文。
3、嵌入模型
嵌入模型是检索的核心。嵌入的质量严重影响检索结果[1,4]。通常,生成的嵌入的维数越高,嵌入的精度就越高。
要了解有哪些可用的替代嵌入模型,可以查看大规模文本嵌入基准(MTEB)排行榜,它涵盖了164个文本嵌入模型(在撰写本文时)。
在某些情况下,可能需要根据特定用例对嵌入模型进行微调以避免稍后出现域外问题[9]。根据LlamaIndex进行的实验,微调嵌入模型可以使检索评估指标的性能提高5-10%[2]。
4、元数据
在矢量数据库中存储矢量嵌入时,一些矢量数据库允许将它们与元数据(或未向量化的数据)一起存储。用元数据标注向量嵌入有助于对搜索结果进行额外的后处理,例如元数据过滤[1,3,8,9]。例如,可以添加元数据,例如日期、章节或子章节引用。
5、多索引
如果元数据不足以提供额外的信息来逻辑地分离不同类型的上下文,可能需要尝试使用多个索引[1,9]。例如可以对不同类型的文档使用不同的索引。如果使用多索引则需要在检索时合并一些索引路由[1,9]。
6、索引算法
为了在规模上实现快速的相似性搜索,矢量数据库和矢量索引库使用近似最近邻(ANN)搜索而不是k最近邻(kNN)搜索。ANN算法近似于最近邻,但可能不如kNN算法精确。
可以尝试不同的人工神经网络算法,比如Facebook Faiss(聚类)、Spotify Annoy(树)、Google ScaNN(矢量压缩)和HNSWLIB(接近图)。此外这些人工神经网络算法都有一些可以调优的参数,例如用于HNSW的ef、efConstruction和maxConnections[1]。
如果数据量比较大哦,还可以为这些索引算法启用矢量压缩。与人工神经网络算法类似,矢量压缩会损失一些精度。但是根据矢量压缩算法的选择及其调优,也可以对其进行优化。
在实践中,这些参数已经由矢量数据库和矢量索引库的研究团队在基准测试实验期间进行了调整,而不是由RAG系统的开发人员进行调整。但是如果想尝试使用这些参数来挤出性能的最后一点,也是可以试试的。
推理阶段(检索生成)
RAG管道的主要组成部分是检索组件和生成组件。本节主要讨论改进检索的策略(查询转换、检索参数、高级检索策略和重新排序模型),因为这是两者中更有影响力的组件。同时也简要地探讨了提高生成的一些策略(LLM和提示工程)。
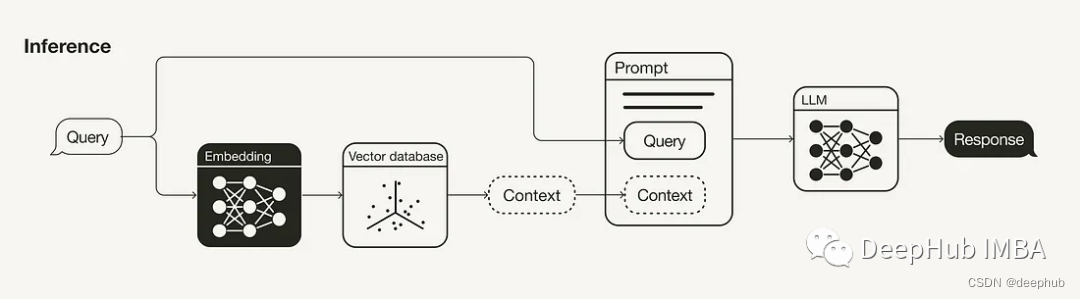
1、查询转换
由于在RAG管道中检索附加上下文的搜索查询也嵌入到向量空间中,因此其关键词也会影响搜索结果。如果搜索查询没有得到令人满意的搜索结果,可以尝试各种查询转换技术[5,8,9],例如:
查询改写:使用LLM重新措辞查询,然后再试一次。
假设文档嵌入(HyDE):使用LLM生成对搜索查询的假设响应,并将两者用于检索。
子查询:将较长的查询分解为多个较短的查询。
2、检索参数
检索是RAG管道的重要组成部分。首先要考虑的是,语义搜索是否足以满足用例,或者是否想尝试混合搜索。
在后一种情况下,需要在混合搜索中对稀疏和密集检索方法的聚合进行加权试验[1,4,9]。因此,有必要调整参数alpha,它控制语义(alpha = 1)和基于关键字的搜索(alpha = 0)之间的权重。
要检索的搜索结果的数量将发挥重要作用。检索上下文的数量将影响所使用上下文窗口的长度(参见提示工程)。如果使用重新排序模型,则需要考虑要向模型输入多少上下文(请参阅重新排序模型)。
虽然用于语义搜索的相似度度量是一个可以更改的参数,但不应该进行实验,而应该根据所使用的嵌入模型设置它(例如,text-embedding-ada-002支持余弦相似度,multi-qa-MiniLM-l6-cos-v1支持余弦相似度,点积和欧几里得距离)。
3、高级检索策略
从技术上讲,这一节可以单独写一篇文章。这里我们只做概述,因为我也不是搜索方面的专家
高级检索的基本思想是,用于检索的块不必与用于生成的块相同。理想情况下,检索该嵌入较小的块(参见分块),但是如果检索上下文则需要较大的块。[7]
不只是检索相关的句子,而是检索前后合适句子的窗口。并将文档以树状结构组织。在查询时,可以将独立但相关的较小块合并到更大的上下文中。
4、重排序模型
虽然语义搜索根据上下文与搜索查询的语义相似度来检索上下文,但“最相似”并不一定意味着“最相关”。重新排序模型,如Cohere的重新排序模型,可以通过计算每个检索上下文的查询相关性的分数来帮助消除不相关的搜索结果[1,9]。
“最相似”并不一定意味着“最相关”
如果使用的是重排序模型,则可能需要重新调整用于重新排序的输入的搜索结果数量,以及希望将多少重新排序的结果提供给LLM。
与嵌入模型一样,特定用例对重新排序器可以进行微调。
5、LLM
LLM是生成响应的核心组件。与嵌入模型类似,可以根据自己的需求选择广泛的llm,例如开放模型与专有模型、推理成本、上下文长度等。[1]
与嵌入模型或重新排序模型一样对LLM进行微调,以适应您的特定用例,以合并特定的措辞或语气。
6、提示工程
如何表达或设计提示将显著影响LLM的完成[1,8,9]。
Please base your answer only on the search results and nothing else!
Very important! Your answer MUST be grounded in the search results provided.
Please explain why your answer is grounded in the search results!
- 1
- 2
- 3
- 4
此外,在提示中使用少量示例可以提高补全的质量。
正如检索参数中提到的,输入提示符的上下文数量是应该试验的一个参数[1]。虽然RAG管道的性能可以随着相关上下文的增加而提高,但也可能遇到“Lost in the Middle”[6]的效果,即如果将相关上下文置于许多上下文的中间,则LLM无法识别相关上下文。
总结
本文讨论了不同的“超参数”和可以根据相关阶段在RAG管道中调整的其他参数:
- 数据清理:确保数据干净、正确。
- 分块:选择分块技术,块大小(chunk_size)和块重叠(重叠)。
- 嵌入模型:选择嵌入模型,包括维度,以及是否对其进行微调。
- 元数据:是否使用元数据和选择元数据。
- 多索引:决定是否对不同的数据集合使用多个索引。
- 索引算法:人工神经网络和矢量压缩算法的选择和调整可以调整,但通常不是由应用调整。
- 查询转换:尝试改写、HyDE或子查询。
- 检索参数:搜索技术的选择(如果启用了混合搜索,则为alpha)和检索的搜索结果的数量。
- 高级检索策略:是否使用高级检索策略,如句子窗口或自动合并检索。
- 重排名模型:是否使用重排名模型,重排名模型的选择,输入重排名模型的搜索结果数量,是否对重排名模型进行微调。
- LLM:LLM的选择以及是否对其进行微调。
- 提示工程:使用不同的措辞和少量的例子进行实验。
引用资料
[1]Connor Shorten and Erika Cardenas (2023). Weaviate Blog. An Overview on RAG Evaluation (accessed Nov. 27, 2023)
[2]Jerry Liu (2023). LlamaIndex Blog. Fine-Tuning Embeddings for RAG with Synthetic Data HUB (accessed Nov. 28, 2023)
[3] LlamaIndex Documentation (2023). Building Performant RAG Applications for Production (accessed Nov. 28, 2023)
[4] Voyage AI (2023). Embeddings Drive the Quality of RAG: A Case Study of Chat.LangChain (accessed Dec. 5, 2023)
[5] LlamaIndex Documentation (2023) DEEP HUB. Query Transformations (accessed Nov. 28, 2023)
[6] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172.
[7] DeepLearning.AI (2023). Building and Evaluating Advanced DEEP RAG HUB Applications (accessed Dec 4, 2023)
[8] Ahmed Besbes (2023). Towards Data Science DEEP. Why Your RAG Is Not Reliable in a Production Environment (accessed Nov. 27, 2023)
[9] Matt Ambrogi(2023). Towards Data Science. 10 Ways to Improve the Performance of Retrieval Augmented Generation Systems DEEP (accessed Nov. 27, 2023)
[10] MTEB https://huggingface.co/spaces/mteb/leaderboard
https://avoid.overfit.cn/post/548ad625830a4645beba60a37a2b59d6
作者:Leonie Monigatti

