
- 1bootstrap 搜索框样式 带放大镜_bootstrap放大镜
- 2MongoDB分片_mongodb分片算法
- 3k均值聚类算法案例 r语言iris_R语言做K均值聚类的一个简单小例子
- 4区块链第四次作业跨链原子交换交易_怎么创建bcy testnet 密钥
- 5WebService是什么?他究竟和WebSocket有什么关系?_webservice和websocket的区别
- 6贪心算法:55.跳跃游戏(C++)_跳跃游戏c++程序代码
- 7Python中的Tkinter是什么?Python的Tkinter库怎么用_python tkinter库
- 8Cannot mix incompatible Qt library (5.14.2) with this library (5.15.3)
- 9Android 上传图片到服务器_android选择图片上传到服务器
- 10图像分类模型总结
进阶数据库系列(八):PostgreSQL 锁机制
赞
踩
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 PostgreSQL 常用管理命令、访问控制与认证、语法、数据类型和运算符、常用函数相关的知识点,今天我将详细的为大家介绍 PostgreSQL 锁操作相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
锁存在的意义
在了解 PostgreSQL 锁之前,我们需要了解锁存在的意义是啥?
当多个会话同时访问数据库的同一数据时,理想状态是为所有会话提供高效的访问,同时还要维护严格的数据一致性。那数据一致性通过什么来维护呢,就是通过 MVCC(多版本并发控制) 。
MVCC(多版本并发控制):每个SQL语句看到的都只是当前事务开始的数据快照,而不管底层数据的当前状态。
这样可以保护语句不会看到在相同数据上由其他连接执行更新的并发事务造成的不一致数据,为每一个数据库会话提供事务隔离。MVCC 避免了传统的数据库系统的锁定方法,将通过锁争夺最小化的方法来达到多会话并发访问时的性能最大化目的。
PostgreSQL 锁机制浅析
锁机制在 PostgreSQL 里非常重要 (对于其他现代的 RDBMS 也是如此)。对于数据库应用程序开发者(特别是那些涉及到高并发代码的程序员),需要对锁非常熟悉。对于某些问题,锁需要被重点关注与检查。大部分情况,这些问题跟死锁或者数据不一致有关系,基本上都是由于对 Postgres 的锁机制不太了解导致的。虽然锁机制在 Postgres 内部很重要,但是文档缺非常缺乏,有时甚至还是错误的,与文档所指出的结果不一致。我会告诉你精通 Postgres 的锁机制需要知道的一切,要知道对锁了解的越多,解决与锁相关的问题就会越快。
PostgreSQL 提供了多种锁模式用于控制对表中数据的并发访问,其中最主要的是表级锁与行级锁,除此之外还有页级锁、咨询锁等等,接下来主要介绍表级锁与行级锁。
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
表级锁
表级锁通常会在执行各种命令执行时自动获取,或者通过在事务中使用LOCK语句显示获取。
每种锁都有自己的冲突集合。
表级锁:两个事务在同一时刻不能在同一个表上持有互相冲突的锁,但是可以同时持有不冲突的锁。
表级锁共有八种模式,其存在于PG的共享内存中,可以通过 pg_locks 系统视图查阅。
ACCESS SHARE 访问共享
SELECT 命令在被引用的表上会获得一个这种模式的锁。通常,任何只读取表而不修改它的查询都将获取这种表模式。
ROW SHARE 行共享
SELECT FOR UPDATE 和 SELECT FOR SHARE 命令在目标表上会获得一个这种模式的锁。(加上在被引用但没有选择 FOR UPDATE / FOR SHARE 的任何其他表上的 ACCESS SHARE 锁。)
ROW EXCLUSIVE 行独占
UPDATE、DELETE 和 INSERT 命令在目标表上会获得一个这种模式的锁。(加上在任何其他被引用表上的 ACCESS SHARE锁。)通常,这种锁模式将被任何修改表中数据的命令取得。
SHARE UPDATE EXCLUSIVE 共享更新独占
VACUUM(不带FULL)、ANALYZE、CREATE INDEX CONCURRENTLY、REINDEX CONCURRENTLY、CREATE STATISTICS 命令以及某些 ALTER INDEX 和 ALTER TABLE 命令的变体会获得。这种模式保护一个表不受并发模式改变和 VACUUM 运行的影响。
SHARE 共享
CREATE INDEX(不带CONCURRENTLY) 命令会获得。
这种模式保护一个表不受并发数据改变的影响。
SHARE ROW EXCLUSIVE 共享行独占
CREATE TRIGGER 命令和某些形式的 ALTER TABLE 命令会获得。
这种模式保护一个表不受并发数据修改所影响,并且是自排他的,这样在同一个时刻只能有一个会话持有它。
EXCLUSIVE 排他
REFRESH METERIALIZED VIEW CONCURRENTLY 命令会获得。
这种模式只允许并发的ACCESS SHARE锁,即只有来自于表的读操作可以与一个持有该锁模式的事务并行处理。
ACCESS EXCLUSIVE 访问独占
ALTER TABLE、DROP TABLE、TRUNCATE、REINDEX、CLUSTER、VACUUM FULL 和 REFRESH MATERIALIZED VIEW(不带CONCURRENTLY)命令会获得。很多形式的 ALTER INDEX 和 ALTER TABLE 也在这个层面上获得锁。这也是未显式指定模式的 LOCK TABLE 命令的默认锁模式。
这种模式与所有模式的锁冲突。这种模式保持者是访问该表的唯一事务。
表级锁模式冲突表
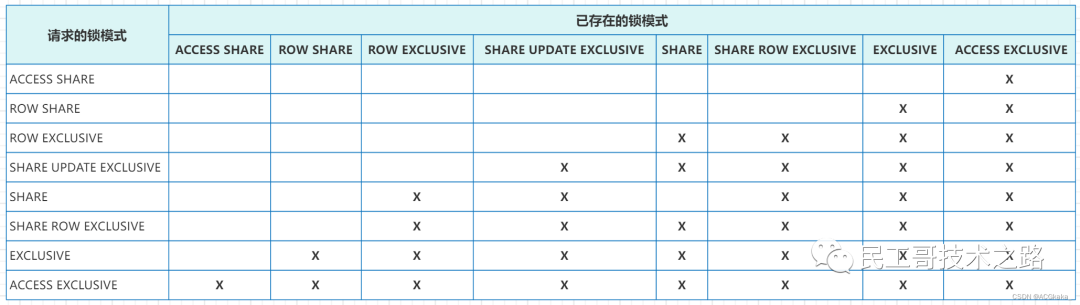 (注:X表示冲突。)
(注:X表示冲突。)
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。怎么去看上面这个图呢?我们下面举两个例子说明一下:
示例一
当一个会话运行了 update 语句,此时会话表上的锁模式为 ROW EXCLUSIVE,从上图我们可以看出 ROW EXCLUSIVE 与 SHARE、SHARE ROW、ROW EXCLUSIVE、EXCLUSIVE 和 ACCESS EXCLUSIVE 锁模式冲突。
也就是说在这个会话未提交事务释放锁之前,我们不能做申请 SHARE、SHARE ROW、ROW EXCLUSIVE、EXCLUSIVE 和 ACCESS EXCLUSIVE 锁模式相关的操作,例如 CREATE INDEX(不带CONCURRENTLY)、ALTER TABLE、DROP TABLE、TRUNCATE、REINDEX、CLUSTER、VACUUM FULL 和 REFRESH MATERIALIZED VIEW(不带CONCURRENTLY)等。
我们先创建一个测试数据库:
- # 创建测试用户
- create user root password 'root';
- # 创建测试数据库
- create database mydb owner root encoding UTF8;
- # 创建和测试用户同名Schema
- create schema AUTHORIZATION CURRENT_USER;
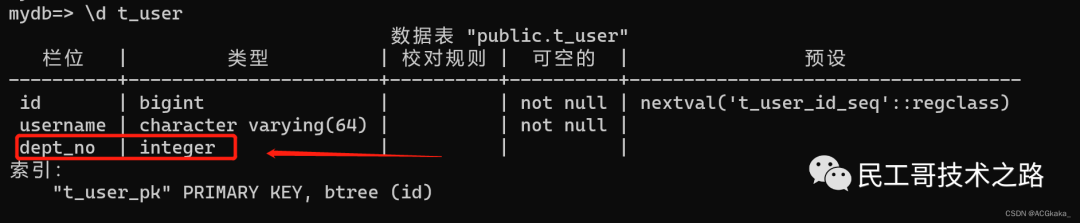
我们创建一张测试表 t_user,并插入一条测试数据:
- create table "t_user" (
- "id" bigserial not null,
- "username" varchar (64) not null,
- constraint t_user_pk primary key (id)
- );
- insert into t_user values(1, 'ACGkaka');
会话一: 执行 update 语句。
- begin;
- update t_user set username='ACGkaka1' where id=1;
 会话二: 执行
会话二: 执行 alter table 语句,这时会处于等待状态。
alter table t_user add dept_no int; 执行SQL,查看锁等待情况:(SQL参考
执行SQL,查看锁等待情况:(SQL参考附录一)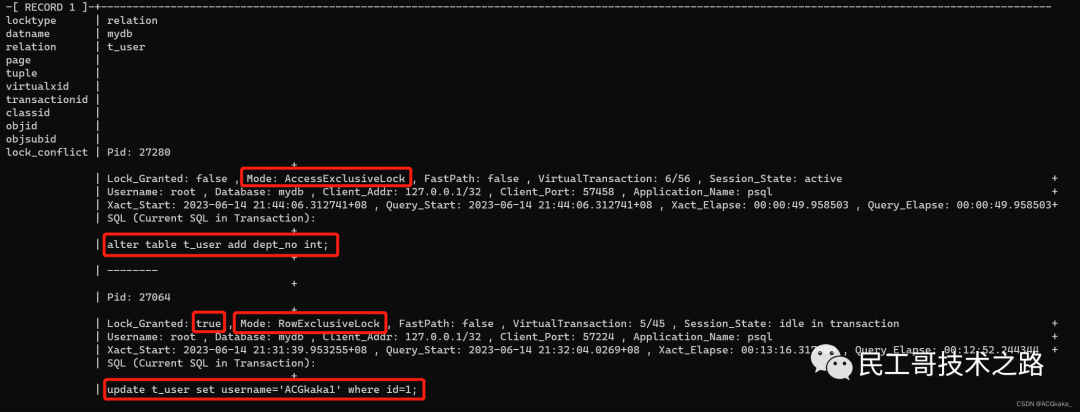 注:
注:Lock_Granted: true即为堵塞源。
直到“会话一”结束,“会话二”语句才执行成功。

示例二
当一个会话运行了 truncate 语句,此时会话表上的锁模式为 ACCESS EXCLUSIVE,从图上我们可以看到这种模式和所有的锁模式都冲突。这意味着在当前会话未结束之前,这个表上的其他操作都做不了。
会话一: 执行 truncate 语句。 会话二: 执行
会话二: 执行 select 语句时处于等待状态。 执行SQL,查看锁等待情况:(SQL参考
执行SQL,查看锁等待情况:(SQL参考附录一)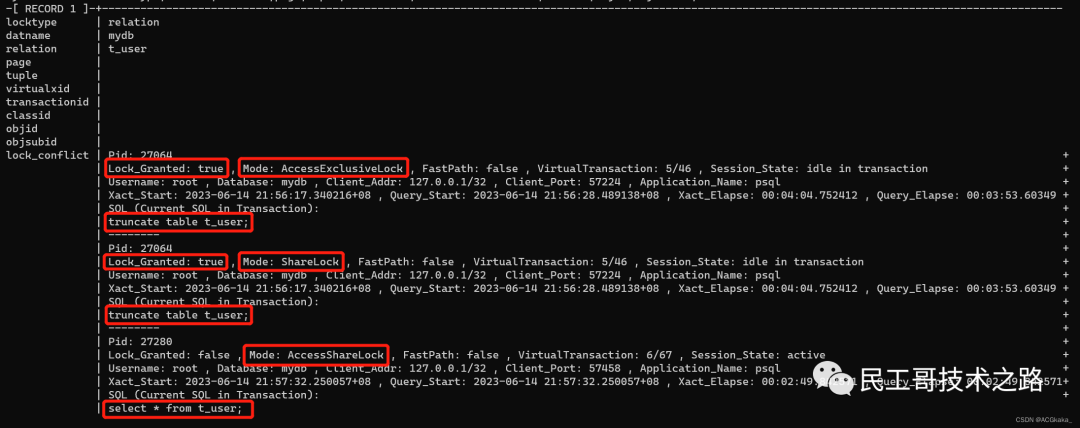 注:
注:Lock_Granted: true即为堵塞源。
直到“会话一”结束,“会话二”语句才执行成功。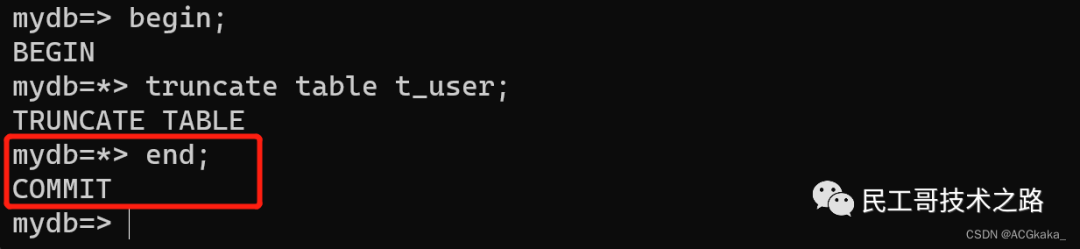
 通过上面2个示例,应该都比较了解各种锁模式冲突的情况了,接下来我们介绍行级锁。
通过上面2个示例,应该都比较了解各种锁模式冲突的情况了,接下来我们介绍行级锁。
行级锁
行级锁:同一个事务可能会在相同的行上保持冲突的锁,甚至是在不同的子事务中。但是除此之外,两个事务永远不可能在相同的行上持有冲突的锁。
行级锁不影响数据查询,它们只阻塞对同一行的写入者和加锁者。行级锁在事务结束时或保存点回滚的时候释放,就像表级锁一样。下面是常用的行级锁模式:
FOR UPDATE 更新
FOR UPDATE 会导致由 SELECT 语句检索到的行被锁定,就好像它们要被更新。这可以阻止它们被其他事务锁定、修改或者删除,直到当前事务结束。
也就是说其他尝试 UPDATE、DELETE、SELECT FOR UPDATE、SELECT FOR NO KEY UPDATE、SELECT FOR SHARE 或者 SELECT FOR KEY SHARE 这些行的事务将被阻塞,直到当前事务结束。
反过来,SELECT FOR UPDATE 将等待已经在相同行上运行以上这些命令的并发事务,并且接着锁定并且返回被更新的行(或者没有行,因为行可能已被删除)。
FOR NO KEY UPDATE 无键更新
行为与 FOR UPDATE 类似,不过获得的锁较弱,这种锁将不会阻塞尝试在相同行上获得锁的 SELECT FOR KEY SHARE 命令。任何不获取 FOR UPDATE 锁的 UPDATE 也会获得这种锁模式。
FOR SHARE 共享
行为与 FOR NO KEY UPDATE 类似,不过它在每个检索到的杭上获得一个共享锁而不是排他锁。
一个共享锁会阻塞其他食物在这些行上执行 UPDATE、DELETE、SELECT FOR UPDATE 或者 SELECT FOR NO KEY UPDATE,但是它不会阻止它们执行 SELECT FOR SHARE 或者 SELECT FRO KEY SHARE。
FOR KEY SHARE 键共享
行为与 FOR SHARE 类似,不过锁较弱,SELECT FOR UPDATE 会被阻塞,但是 SELECT FOR NO KEY UPDATE 不会被阻塞,一个键共享锁会阻塞其他事务执行修改键值的 DELETE 或者 UPDATE,但不会阻塞其他 UPDATE,也不会阻止 SELECT FOR NO KEY UPDATE、SELECT FOR SHARE 或者 SELECT FOR KEY SHARE。
表级锁模式冲突表
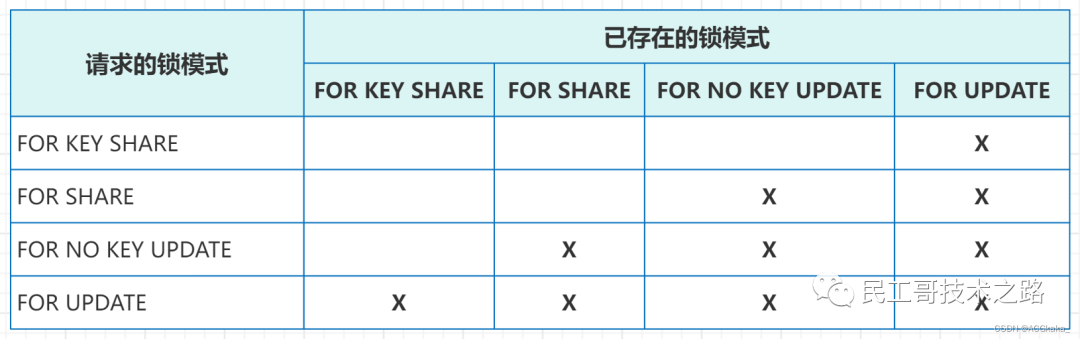 (注:X表示冲突。)更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
(注:X表示冲突。)更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
4 个执行语句 timeout 参数
lock_timeout
lock_timeout:获取一个表,索引,行上的锁超过这个时间,直接报错,不等待,0为禁用。
statement_timeout
statement_timeout:当SQL语句的执行时间超过这个设置时间,终止执行SQL,0为禁用。
idle_in_transaction_session_timeout
idle_in_transaction_session_timeout:在一个空闲的事务中,空闲时间超过这个值,将视为超时,0为禁用。
deadlock_timeout
dealdlock_timeout:死锁时间超过这个值将直接报错,不会等待,默认设置为1s。
页级锁
除了表级别和行级别的锁以外,页面级别的共享/排他锁被用来控制对共享缓冲池中表页面的读/写。 这些锁在行被抓取或者更新后马上被释放。应用开发者通常不需要关心页级锁,我们在这里提到它们只是为了完整。
劝告锁
Postgres提供创建具有应用定义的锁的方法,这些被称为劝告锁(advisory locks),因为系统并不支持其使用,其取决于应用对锁的正确使用。
Postgres 中有两种途径可以获得一个劝告锁:会话层级或事务层级。一旦在会话层级获得劝告锁,会一直保持到被显式释放或会话结束。不同于标准的锁请求,会话层级的劝告锁请求并不遵守事务语义:事务被回滚后锁也会随着回滚保持着,同样地即使调用锁的事务之后失败了,解锁请求仍然是有效的。一个锁可以被拥有它的进程多次获取;对于每个完成的锁请求,在锁被真正释放前一定要有一个对应的解锁请求。
另一方面,事务层级的锁请求表现得更像普通的锁请求:它们在事务结束时会自动释放,并且没有显式的解锁操作。对于短暂地使用劝告锁,这种特性通常比会话层级更方便。可以想见,会话层级与事务层级请求同一个劝告锁标识符会互相阻塞。如果一个会话已经有了一个劝告锁,它再请求时总会成功的,即使其他会话在等待此锁;不论保持现有的锁和新的请求是会话层级还是事务层级,都是这样。文档中可以找到操作劝告锁的完整函数列表。
这里有几个获取事务层级劝告锁的例子(pg_locks是系统视图,文章之后会说明。它存有事务保持的表级锁和劝告锁的信息):
启动第一个psql会话,开始一个事务并获取一个劝告锁:
- -- Transaction 1
- BEGIN; SELECT pg_advisory_xact_lock(1);
- -- Some work here
现在启动第二个psql会话并在同一个劝告锁上执行一个新的事务:
- -- Transaction 2
- BEGIN; SELECT pg_advisory_xact_lock(1);
- -- This transaction is now blocked
在第三个psql会话里我们可以看下这个锁现在的情况:
- SELECT * FROM pg_locks;-- Only relevant parts of output
- locktype | database | relation | page | tuple | virtualxid | transactionid | classid | objid | objsubid | virtualtransaction | pid | mode | granted |fastpath---------------+----------+----------+------+-------+------------+---------------+---------+-------+----------+--------------------+-------+---------------------+---------+----------
- advisory | 16393 | | | | | | 0 | 1 | 1 | 4/36 | 1360 | ExclusiveLock | f | f
- advisory | 16393 | | | | | | 0 | 1 | 1 | 3/186 | 14340 | ExclusiveLock | t | f
- -- Transaction 1
- COMMIT;
- -- This transaction now released lock, so Transaction 2 can continue
我们同样可以调用获取锁的非阻塞方法,这些方法会尝试去获取锁,并返回true(如果成功了)或者false(如果无法获取锁)。
- -- Transaction 1
- BEGIN;
- SELECT pg_advisory_xact_lock(1);
- -- Some work here
- -- Transaction 2
- BEGIN;
- SELECT pg_try_advisory_xact_lock(1) INTO vLockAcquired;
- IF vLockAcquired THEN
- -- Some work
- ELSE
- -- Lock not acquired
- END IF;
- -- Transaction 1
- COMMIT;
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
监控锁
所有活动事务持有的监控锁的基本配置即为系统视图 pg_locks。这个视图为每个可加锁的对象、已请求的锁模式和相关事务包含一行记录。非常重要的一点是,pg_locks 持有内存中被跟踪的锁的信息,所以它不显示行级锁!(译注:据查以前的文档,有关行级锁的信息是存在磁盘上,而非内存)这个视图显示表级锁和劝告锁。如果一个事务在等待一个行级锁,它通常在视图中显示为在等待该行级锁的当前所有者的固定事务 ID。这使得调试行级锁更为困难。事实上,在任何地方你都看不到行级锁,直到有人阻塞了持有此锁的事务(然后你在 pg_locks 表里可以看到一个被上锁的元组)。pg_locks 是可读性欠佳的视图(不是很人性化),所以我们来让显示锁定信息的视图更好接受些:
- -- View with readable locks info and filtered out locks on system tables
- CREATE VIEW active_locks AS
- SELECT clock_timestamp(), pg_class.relname, pg_locks.locktype, pg_locks.database,
- pg_locks.relation, pg_locks.page, pg_locks.tuple, pg_locks.virtualtransaction,
- pg_locks.pid, pg_locks.mode, pg_locks.granted
- FROM pg_locks JOIN pg_class ON pg_locks.relation = pg_class.oid
- WHERE relname !~ '^pg_' and relname <> 'active_locks';
- -- Now when we want to see locks just type
- SELECT * FROM active_locks;
- --查看会话session
- select pg_backend_pid();
-
- --查看会话持有的锁
- select * from pg_locks where pid=3797;
-
- --1,查看数据库
- select pg_database.datname, pg_database_size(pg_database.datname) AS size from pg_database; //查询所有数据库,及其所占空间大小
-
- --2. 查询存在锁的数据表
- select a.locktype,a.database,a.pid,a.mode,a.relation,b.relname -- ,sa.*
- from pg_locks a
- join pg_class b on a.relation = b.oid
- inner join pg_stat_activity sa on a.pid=sa.procpid
-
- --3.查询某个表内,状态为lock的锁及关联的查询语句
- select a.locktype,a.database,a.pid,a.mode,a.relation,b.relname -- ,sa.*
- from pg_locks a
- join pg_class b on a.relation = b.oid
- inner join pg_stat_activity sa on a.pid=sa.procpid
- where a.database=382790774 and sa.waiting_reason='lock'
- order by sa.query_start
-
- --4.查看数据库表大小
- select pg_database_size('playboy');

- --查看会话被谁阻塞
- select pg_blocking_pids(3386);
死锁
显式锁定的使用可能会增加死锁的可能性,死锁是指两个(或多个)事务相互持有对方想要的锁。
例如,如果事务 1 在表 A 上获得一个排他锁,同时试图获取一个在表 B 上的排他锁, 而事务 2 已经持有表 B 的排他锁,同时却正在请求表 A 上的一个排他锁,那么两个事务就都不能进行下去。PostgreSQL能够自动检测到死锁情况 并且会通过中断其中一个事务从而允许其它事务完成来解决这个问题(具体哪个事务会被中 断是很难预测的,而且也不应该依靠这样的预测)。
要注意死锁也可能会作为行级锁的结果而发生(并且因此,它们即使在没有使用显式锁定的情况下也会发生)。考虑如下情况,两个并发事务在修改一个表。第一个事务执行:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 11111;这样就在指定帐号的行上获得了一个行级锁。然后,第二个事务执行:
- UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 22222;
- UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 11111;
第一个UPDATE语句成功地在指定行上获得了一个行级锁,因此它成功更新了该行。 但是第
二个UPDATE语句发现它试图更新的行已经被锁住了,因此它等待持有该锁的事务结束。事
务二现在就在等待事务一结束,然后再继续执行。现在,事务一执行:
UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 22222;事务一试图在指定行上获得一个行级锁,但是它得不到:事务二已经持有了这样的锁。所以
它要等待事务二完成。因此,事务一被事务二阻塞,而事务二也被事务一阻塞:一个死锁。
PostgreSQL将检测这样的情况并中断其中一个事务。
防止死锁的最好方法通常是保证所有使用一个数据库的应用都以一致的顺序在多个对象上获得锁。在上面的例子里,如果两个事务以同样的顺序更新那些行,那么就不会发生死锁。 我们也应该保证一个事务中在一个对象上获得的第一个锁是该对象需要的最严格的锁模式。如果我们无法提前验证这些,那么可以通过重试因死锁而中断的事务来即时处理死锁。
只要没有检测到死锁情况,寻求一个表级或行级锁的事务将无限等待冲突锁被释放。这意味着一个应用长时间保持事务开启不是什么好事(例如等待用户输入)。
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
附录
附录一:查看锁等待情况SQL
- with
- t_wait as
- (
- select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted,
- a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath,
- b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name
- from pg_locks a,pg_stat_activity b where a.pid=b.pid and not a.granted
- ),
- t_run as
- (
- select a.mode,a.locktype,a.database,a.relation,a.page,a.tuple,a.classid,a.granted,
- a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,a.transactionid,a.fastpath,
- b.state,b.query,b.xact_start,b.query_start,b.usename,b.datname,b.client_addr,b.client_port,b.application_name
- from pg_locks a,pg_stat_activity b where a.pid=b.pid and a.granted
- ),
- t_overlap as
- (
- select r.* from t_wait w join t_run r on
- (
- r.locktype is not distinct from w.locktype and
- r.database is not distinct from w.database and
- r.relation is not distinct from w.relation and
- r.page is not distinct from w.page and
- r.tuple is not distinct from w.tuple and
- r.virtualxid is not distinct from w.virtualxid and
- r.transactionid is not distinct from w.transactionid and
- r.classid is not distinct from w.classid and
- r.objid is not distinct from w.objid and
- r.objsubid is not distinct from w.objsubid and
- r.pid <> w.pid
- )
- ),
- t_unionall as
- (
- select r.* from t_overlap r
- union all
- select w.* from t_wait w
- )
- select locktype,datname,relation::regclass,page,tuple,virtualxid,transactionid::text,classid::regclass,objid,objsubid,
- string_agg(
- 'Pid: '||case when pid is null then 'NULL' else pid::text end||chr(10)||
- 'Lock_Granted: '||case when granted is null then 'NULL' else granted::text end||' , Mode: '||case when mode is null then 'NULL' else mode::text end||' , FastPath: '||case when fastpath is null then 'NULL' else fastpath::text end||' , VirtualTransaction: '||case when virtualtransaction is null then 'NULL' else virtualtransaction::text end||' , Session_State: '||case when state is null then 'NULL' else state::text end||chr(10)||
- 'Username: '||case when usename is null then 'NULL' else usename::text end||' , Database: '||case when datname is null then 'NULL' else datname::text end||' , Client_Addr: '||case when client_addr is null then 'NULL' else client_addr::text end||' , Client_Port: '||case when client_port is null then 'NULL' else client_port::text end||' , Application_Name: '||case when application_name is null then 'NULL' else application_name::text end||chr(10)||
- 'Xact_Start: '||case when xact_start is null then 'NULL' else xact_start::text end||' , Query_Start: '||case when query_start is null then 'NULL' else query_start::text end||' , Xact_Elapse: '||case when (now()-xact_start) is null then 'NULL' else (now()-xact_start)::text end||' , Query_Elapse: '||case when (now()-query_start) is null then 'NULL' else (now()-query_start)::text end||chr(10)||
- 'SQL (Current SQL in Transaction): '||chr(10)||
- case when query is null then 'NULL' else query::text end,
- chr(10)||'--------'||chr(10)
- order by
- ( case mode
- when 'INVALID' then 0
- when 'AccessShareLock' then 1
- when 'RowShareLock' then 2
- when 'RowExclusiveLock' then 3
- when 'ShareUpdateExclusiveLock' then 4
- when 'ShareLock' then 5
- when 'ShareRowExclusiveLock' then 6
- when 'ExclusiveLock' then 7
- when 'AccessExclusiveLock' then 8
- else 0
- end ) desc,
- (case when granted then 0 else 1 end)
- ) as lock_conflict
- from t_unionall
- group by
- locktype,datname,relation,page,tuple,virtualxid,transactionid::text,classid,objid,objsubid ;
输出结果格式如下: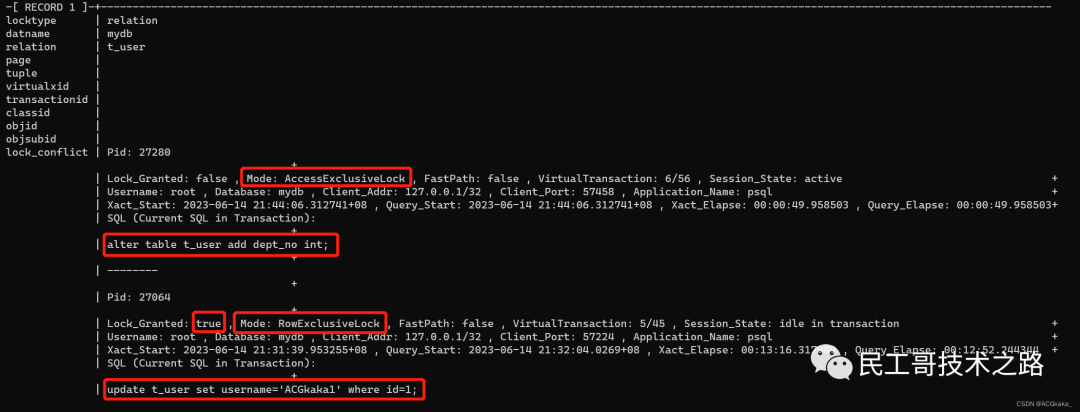
附录二:查看阻塞会话,并生成kill sql
- SELECT pg_cancel_backend(pid); – session还在,事物回退;
- SELECT pg_terminate_backend(pid); --session消失,事物回退
- with recursive
- tmp_lock as (
- select distinct
- --w.mode w_mode,w.page w_page,
- --w.tuple w_tuple,w.xact_start w_xact_start,w.query_start w_query_start,
- --now()-w.query_start w_locktime,w.query w_query
- w.pid as id,--w_pid,
- r.pid as parentid--r_pid,
- --r.locktype,r.mode r_mode,r.usename r_user,r.datname r_db,
- --r.relation::regclass,
- --r.page r_page,r.tuple r_tuple,r.xact_start r_xact_start,
- --r.query_start r_query_start,
- --now()-r.query_start r_locktime,r.query r_query,
- from (
- select a.mode,a.locktype,a.database,
- a.relation,a.page,a.tuple,a.classid,
- a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,
- a.transactionid,
- b.query as query,
- b.xact_start,b.query_start,b.usename,b.datname
- from pg_locks a,
- pg_stat_activity b
- where a.pid=b.pid
- and not a.granted
- ) w,
- (
- select a.mode,a.locktype,a.database,
- a.relation,a.page,a.tuple,a.classid,
- a.objid,a.objsubid,a.pid,a.virtualtransaction,a.virtualxid,
- a.transactionid,
- b.query as query,
- b.xact_start,b.query_start,b.usename,b.datname
- from pg_locks a,
- pg_stat_activity b -- select pg_typeof(pid) from pg_stat_activity
- where a.pid=b.pid
- and a.granted
- ) r
- where 1=1
- and r.locktype is not distinct from w.locktype
- and r.database is not distinct from w.database
- and r.relation is not distinct from w.relation
- and r.page is not distinct from w.page
- and r.tuple is not distinct from w.tuple
- and r.classid is not distinct from w.classid
- and r.objid is not distinct from w.objid
- and r.objsubid is not distinct from w.objsubid
- and r.transactionid is not distinct from w.transactionid
- and r.pid <> w.pid
- ),
- tmp0 as (
- select *
- from tmp_lock tl
- union all
- select t1.parentid,0::int4
- from tmp_lock t1
- where 1=1
- and t1.parentid not in (select id from tmp_lock)
- ),
- tmp3 (pathid,depth,id,parentid) as (
- SELECT array[id]::text[] as pathid,1 as depth,id,parentid
- FROM tmp0
- where 1=1 and parentid=0
- union
- SELECT t0.pathid||array[t1.id]::text[] as pathid,t0.depth+1 as depth,t1.id,t1.parentid
- FROM tmp0 t1, tmp3 t0
- where 1=1 and t1.parentid=t0.id
- )
- select distinct
- '/'||array_to_string(a0.pathid,'/') as pathid,
- a0.depth,
- a0.id,a0.parentid,lpad(a0.id::text, 2*a0.depth-1+length(a0.id::text),' ') as tree_id,
- --'select pg_cancel_backend('||a0.id|| ');' as cancel_pid,
- --'select pg_terminate_backend('||a0.id|| ');' as term_pid,
- case when a0.depth =1 then 'select pg_terminate_backend('|| a0.id || ');' else null end as term_pid,
- case when a0.depth =1 then 'select cancel_backend('|| a0.id || ');' else null end as cancel_pid
- ,a2.datname,a2.usename,a2.application_name,a2.client_addr,a2.wait_event_type,a2.wait_event,a2.state
- --,a2.backend_start,a2.xact_start,a2.query_start
- from tmp3 a0
- left outer join (select distinct '/'||id||'/' as prefix_id,id
- from tmp0
- where 1=1 ) a1
- on position( a1.prefix_id in '/'||array_to_string(a0.pathid,'/')||'/' ) >0
- left outer join pg_stat_activity a2 -- select * from pg_stat_activity
- on a0.id = a2.pid
- order by '/'||array_to_string(a0.pathid,'/'),a0.depth;
输出结果格式如下: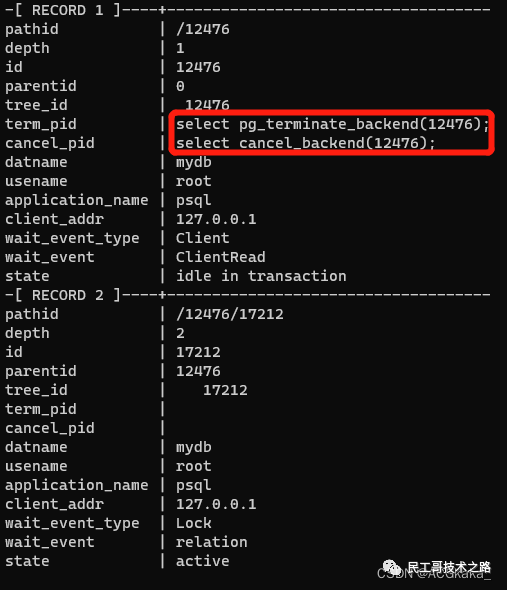
附录三:查询当前执行时间超过60s的sql
- select
- pg_stat_activity.datname,
- pg_stat_activity.pid,
- pg_stat_activity.query,
- pg_stat_activity.client_addr,
- clock_timestamp() - pg_stat_activity.query_start
- from
- pg_stat_activity pg_stat_activity
- where
- (pg_stat_activity.state = any (array['active'::text,
- 'idle in transaction'::text]))
- and (clock_timestamp() - pg_stat_activity.query_start) > '00:00:60'::interval
- order by
- (clock_timestamp() - pg_stat_activity.query_start) desc;
输出结果格式如下: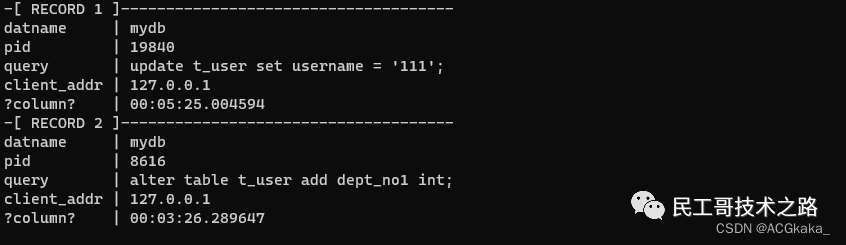
附录四:查询所有已经获取锁的SQL
- SELECT pid, state, usename, query, query_start
- from pg_stat_activity
- where pid in (
- select pid from pg_locks l join pg_class t on l.relation = t.oid
- and t.relkind = 'r'
- );
输出结果格式如下: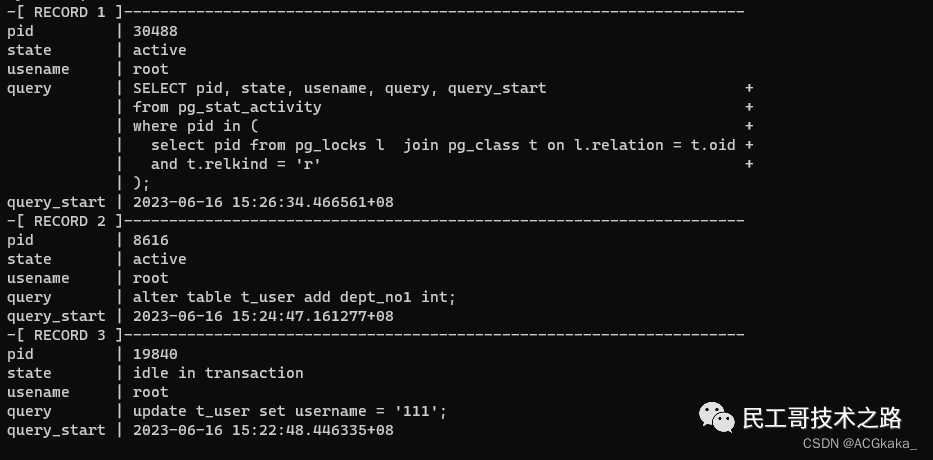 更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
MySQL与PostgreSQL之间的对比
postgresql数据库锁的分类详细,他不会出现锁升级的情况,但也带来用法的繁琐。
mysql数据库当行锁不是所在主键上时会升级成表锁。
mysql和postgresql总体不同基本对比如下:
PostgreSQL的优势
PGSQL没有CPU核心数限制,MySQL能用128核CPU。
PG主表采用堆表存放,MySQL采用索引组织表,能够支持比MySQL更大的数据量。
PG的主备复制属于物理复制(完胜逻辑复制,维护简单),相对于MySQL基于binlog的逻辑复制(
sql_log_bin、binlog_format等参数设置不正确都会导致主从不一致),数据的一致性更加可靠,复制性能更高,对主机性能的影响也更小。MySQL的存储引擎插件化机制,存在锁机制复杂影响并发的问题,而PG不存在这个机制。
PGSQL支持 JIT 执行计划即时编译,使用LLVM编译器,MySQL不支持执行计划即时编译。
PGSQL一共有255个参数,用到的大概是80个,参数比较稳定,用上个大版本配置文件也可以启动当前大版本数据库(版本兼容性好),而MySQL一共有707个参数,用到的大概是180个,参数不断增加,就算小版本也会增加参数,大版本之间会有部分参数不兼容情况。参数多引起维护成本加大。比如:PGSQL系统自动设置从库默认只读,不需要人工添加配置,维护简单,MySQL从库需要手动设置参数
super_read_only=on,让从库设置为只读。
MySQL的优势
MySQL数据库查看sql的执行计划更直观易懂。
MySQL采用索引组织表,这种存储方式非常适合基于主键匹配的查询、删改操作,但是对表结构设计存在约束。
MySQL的优化器较简单,系统表、运算符、数据类型的实现都很精简,非常适合简单的查询操作。
MySQL分区表的实现要优于PG的基于继承表的分区实现,主要体现在分区个数达到上千上万后的处理性能差异较大。
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
参考文章:https://cnblogs.com/VicLiu/p/11865481.html https://blog.csdn.net/qq_33204709/article/details
/131248554
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位,已在技术交流群的请勿重复添加)。主要以技术交流、内推、行业探讨为主,请文明发言。广告人士勿入,切勿轻信私聊,防止被骗。
扫码加我好友,拉你进群

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

