
- 1探究Hugging Face Pipeline类:一站式自然语言处理工具_huggingfacepipeline
- 2spring整合mybatis(实现数据的增删改查)_spring mybatis增删改查
- 3Python中的模块化编程与软件架构设计_python系统软件架构设计
- 4【误码率仿真】多径信道下OFDM通信系统误码率仿真【含Matlab源码 2078期】_matlab实现ofdm误码率仿真
- 5循环、使用dict和set
- 6github新建项目_github创建新项目
- 7node.js安装与环境配置以及npm、cnpm下载_下载cnpm
- 8Python - Flask 无脑学习实践 (三)Flask Blueprint 使用和运行的简单说明_python blueprint
- 9uniapp使用request下载图片,并且显示出来_uni.request获取本地图片
- 10m基于FPGA的8FSK调制解调系统verilog实现,包含testbench测试文件_fpga实现fsk
【深度学习基础(2)】深度学习之前:机器学习简史
赞
踩
可以这样说,当前工业界所使用的大部分机器学习算法不是深度学习算法。深度学习不一定总是解决问题的正确工具:有时没有足够的数据,深度学习不适用;有时用其他算法可以更好地解决问题。
如果第一次接触的机器学习就是深度学习,那么你可能会发现手中只有一把深度学习“锤子”,而所有机器学习问题看起来都像是“钉子”。为了避免陷入这个误区,唯一的方法就是熟悉其他机器学习方法并在适当的时候进行实践。
这里我们将简要回顾这些方法,并了解这些方法发展的历史背景。这样一来,我们便可以将深度学习放入机器学习的大背景中,更好地理解深度学习的起源和重要性。
一. 深度学习的起源
1. 概率建模–机器学习分类器
概率建模(probabilistic modeling)是统计学原理在数据分析中的应用。它是最早的机器学习形式之一,至今仍在广泛使用。在概率建模中,最著名的算法之一就是朴素贝叶斯算法。
朴素贝叶斯是一类机器学习分类器,基于对贝叶斯定理的应用。它假设输入数据的特征都是独立的(这是一个很强的假设,或者说是“朴素”的假设,其名称正来源于此)。贝叶斯定理和统计学基础可以追溯到18世纪,只要学会这两点,就可以开始使用朴素贝叶斯分类器了。
另一个密切相关的模型是logistic回归(logistic regression,简称logreg),它有时被认为是现代机器学习的“Hello World”。不要被它的名称所误导——logreg是一种分类算法,而不是回归算法。与朴素贝叶斯类似,logreg的出现也比计算机早很长时间,但由于它既简单又通用,因此至今仍然很有用。面对一项分类任务,数据科学家通常首先会在数据集上尝试使用这种算法,以便初步熟悉该分类任务。
2. 早期神经网络–反向传播算法的转折
虽然人们早在20世纪50年代就开始研究神经网络及其核心思想,但这一方法在数十年后才被人们所使用。在很长一段时间里,一直没有训练大型神经网络的有效方法。这种情况在20世纪80年代中期发生了变化,当时有多人独立地重新发现了反向传播算法——一种利用梯度下降优化来训练一系列参数化运算链的方法,并开始将其应用于神经网络。
神经网络的第一个成功的实际应用来自于1989年的贝尔实验室,当时YannLeCun将卷积神经网络的早期思想与反向传播算法相结合,并将其应用于手写数字分类问题。由此得名的LeNet,在20世纪90年代被美国邮政署采用,用于自动读取信封上的邮政编码。
3. 核方法 – 忽略神经网络
神经网络取得了第一次成功,并从20世纪90年代开始在研究人员中受到一定重视,但一种新的机器学习方法在这时声名鹊起,很快就使人们将神经网络抛诸脑后。这种方法就是核方法。核方法(kernel method)是一组分类算法,其中最有名的就是支持向量机(support vector machine,SVM)。
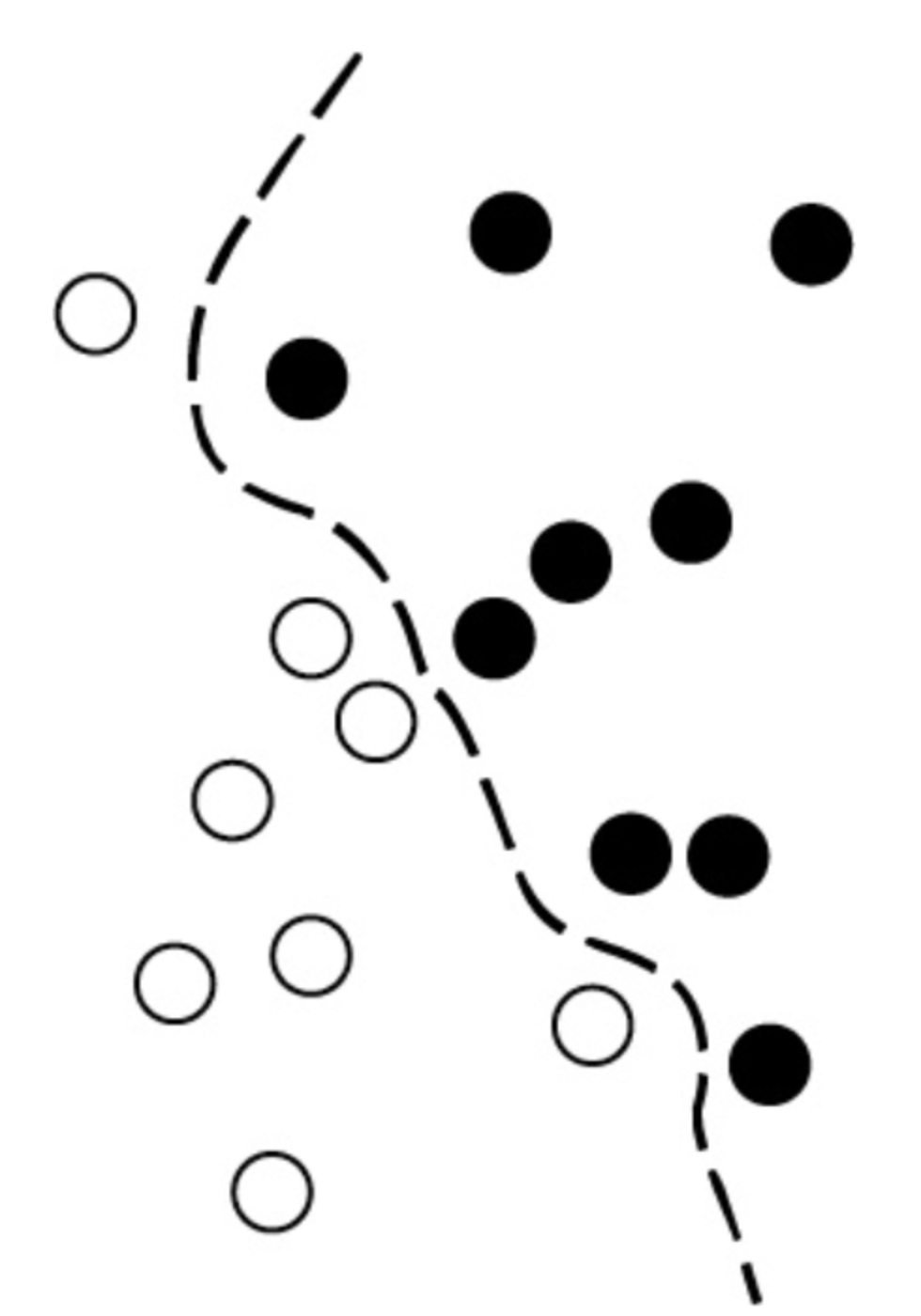
SVM是一种分类算法,其原理是寻找划分两个类别的“决策边界”,如下图所示。
SVM通过以下两步来寻找决策边界。
- (1)将数据映射到新的高维表示,此时决策边界可以用一个超平面来表示(如果数据像图那样是二维的,那么超平面就是一条直线)。
- (2)尽量让超平面与每个类别最近的数据点之间的距离最大化,从而计算出良好的决策边界(分离超平面)。这一步叫作间隔最大化(maximizing themargin)。这样一来,决策边界便可以很好地推广到训练数据集之外的新样本。
将数据映射到高维表示从而使分类问题简化,这一方法可能听起来很不错,但实际上计算起来很棘手。这时就需要用到核技巧(kernel trick,核方法正是因这一核心思想而得名)。
核技巧的基本思想是:要在新的表示空间中找到良好的决策超平面,不需要直接计算点在新空间中的坐标,只需要计算在新空间中点与点之间的距离,而利用核函数可以高效地完成这种计算。核函数(kernel function)是一个在计算上容易实现的运算,它将初始空间中的任意两点映射为这两点在目标表示空间中的距离,从而完全避免了直接计算新的表示。
SVM刚刚出现时,在简单的分类问题上表现出非常好的性能。当时只有少数机器学习方法得到大量的理论支持,并且经得起严谨的数学分析,因此非常易于理解和解释,SVM就是其中之一。由于SVM具有这些有用的性质,因此它在很长一段时间里非常流行。
但事实证明,SVM很难扩展到大型数据集,并且在图像分类等感知问题上的效果也不好。SVM是一种浅层方法,因此要将其应用于感知问题,首先需要手动提取出有用的表示(这一步骤叫作特征工程)。这一步骤很难,而且不稳定。如果想用SVM来进行手写数字分类,那么你不能从原始像素开始,而应该首先手动找到有用的表示(比如前面提到的像素直方图),使问题变得更易于处理。
4. 决策树、随机森林和梯度提升机
决策树(decision tree)是类似于流程图的结构,可以对输入数据进行分类或根据输入预测输出值,如下图所示。决策树的可视化和解释都很简单。
在21世纪前10年,从数据中进行学习的决策树开始引起研究人员的浓厚兴趣。到了2010年,决策树往往比核方法更受欢迎。
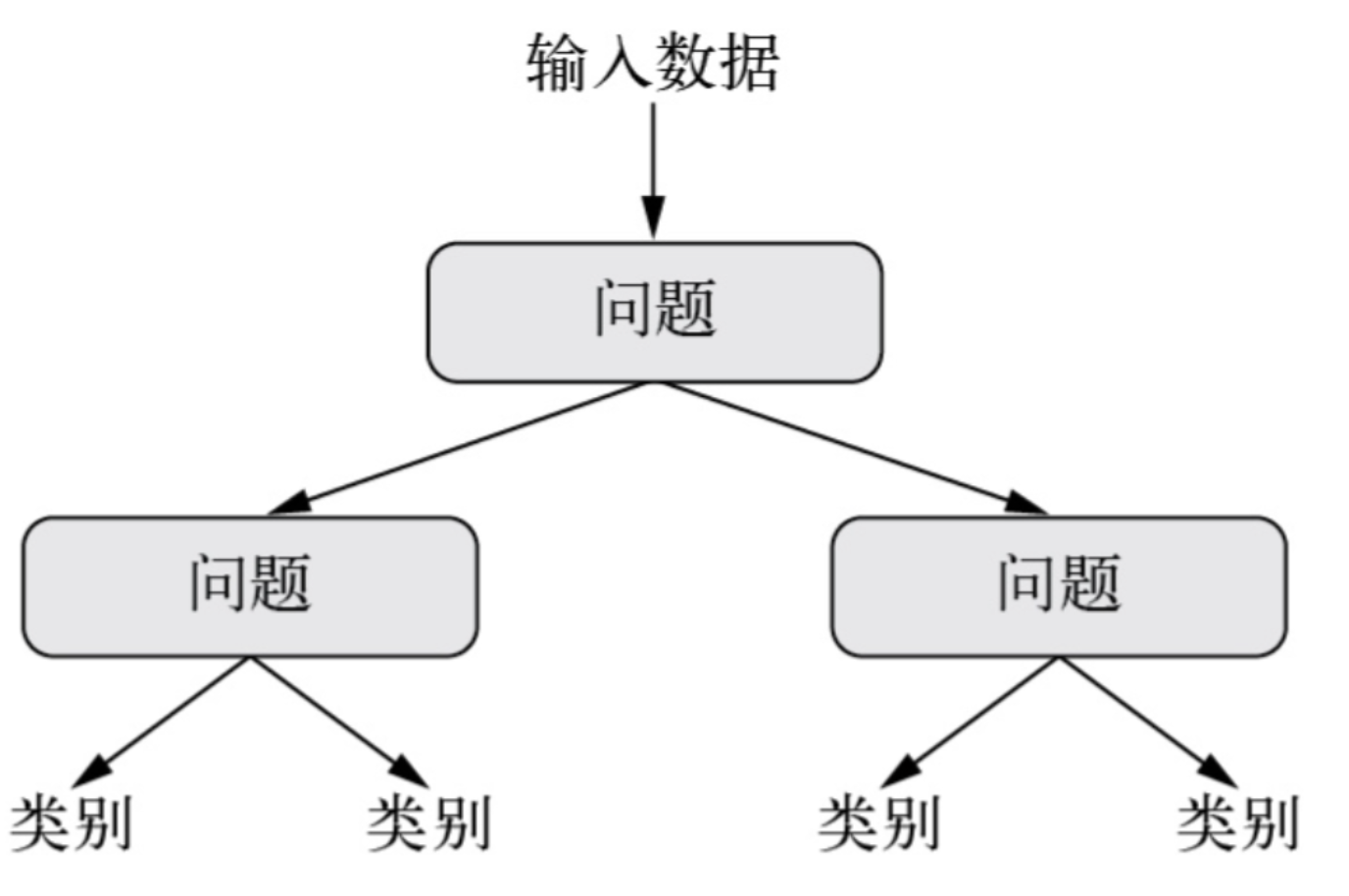
决策树:需要学习的参数是关于数据的问题。举个例子,问题可能是:“数据中第2个系数是否大于3.5?”
随机森林(random forest)算法引入了一种稳健且实用的决策树学习方法,即首先构建许多专门的决策树,然后将它们的输出集成在一起。
与随机森林类似,梯度提升机也是将弱预测模型(通常是决策树)进行集成的机器学习技术。它使用了梯度提升(gradient boosting)方法,这种方法通过
迭代地训练新模型来专门弥补原有模型的弱点,从而可以提升任何机器学习模型的效果。将梯度提升技术应用于决策树时,得到的模型与随机森林具有相似的性质,但在绝大多数情况下效果更好。它可能是目前处理非感知数据最好的算法之一(如果非要加“之一”的话)。
5. 神经网络替代svm与决策树
自2012年以来,深度卷积神经网络(convnet)已成为所有计算机视觉任务的首选算法。更一般地说,它适用于所有感知任务。在2015年之后的主要计算机视觉会议上,绝大多数演讲或多或少与convnet有关。与此同时,深度学习也在许多其他类型的问题上得到应用,比如自然语言处理。它已经在大量应用中完全取代了SVM与决策树。
举个例子,欧洲核子研究中心(CERN)多年来一直使用基于决策树的方法来分析来自大型强子对撞机(LHC)ATLAS探测器的粒子数据,但CERN最终转向基于Keras的深度神经网络,因为后者的性能更好,而且在大型数据集上易于训练。
二. 深度学习与机器学习有何不同
主要不同
- 深度学习让解决问题变得更加简单,因为它
将特征工程完全自动化,而这曾经是机器学习工作流程中最关键的一步。- 先前的机器学习技术(浅层学习)仅涉及将输入数据变换到一两个连续的表示空间,通常使用简单的变换,比如高维非线性投影(SVM)或决策树。但这些技术通常无法得到复杂问题所需要的精确表示。因此,人们不得不
竭尽所能让初始输入数据更适合于用这些方法处理,不得不手动为数据设计良好的表示层。这一步叫作特征工程(feature engineering)。- 与此相对,深度学习将这一步完全自动化:利用深度学习,可以一次性学习所有特征,而无须自己手动设计。这极大地简化了机器学习工作流程,通常用一个简单、端到端的深度学习模型取代复杂的多级流程。
<连续应用浅层学习方法的问题>
- 你可能会问,如果问题的关键在于有多个连续表示层,那么能否重复应用浅层方法,以实现与深度学习类似的效果呢?在实践中,如果连续应用浅层学习方法,那么其收益会随着层数增加而迅速降低,因为三层模型中最优的第一表示层并不是单层模型或双层模型中最优的第一表示层。
- 深度学习的变革之处在于,模型可以在
同一时间共同学习所有表示层,而不是依次连续学习(这被称为贪婪学习)。通过共同的特征学习,每当模型修改某个内部特征时,所有依赖于该特征的其他特征都会相应地自动调节适应,无须人为干预。一切都由单一反馈信号来监督:模型中的每一处变化都是为最终目标服务。这种方法比贪婪地叠加浅层模型更强大,因为它可以通过将复杂、抽象的表示拆解为多个中间空间(层)来学习这些表示,每个中间空间仅仅是前一个空间的简单变换。
深度学习从数据中进行学习时有两个基本特征:
- 通过逐层渐进的方式形成越来越复杂的表示;
- 对中间这些渐进的表示共同进行学习,每一层的修改都需要同时考虑上下两层。
这两个特征叠加在一起,使得深度学习比先前的机器学习方法更成功。
参考:
《Python深度学习(第二版)》–弗朗索瓦·肖莱

