
- 1仓储搬运机器人_AI+仓储:物流机器人自主决策,“国外公司开始抄我们”
- 2通付盾APP尽职调查报告:守护移动应用安全新篇章
- 3Android studio开发app设计登录界面、注册账号界面、查询用户信息数据库_(二)自主设计一个具有简单风格的 app 注册界面。 1. 创建程序。 打开 android stu
- 4环境安装--多个版本的nodejs安装_nodejs安装多版本
- 5mac idea破解
- 6Calendar.DAY_OF_MONTH_calendar.day of month
- 7带你了解软件版本号的命名规则_版本号命名规则
- 8递归与回溯4:一文彻底理解回溯_递归和回溯
- 9Android自定义日历控件_android calendar日历控件窗口大小和字体大小设置
- 10Idea设置代理后无法clone git项目_idea git 挂代理
将数据从 SQL Server 数据库复制到 Azure Blob 存储_sql备份到azure storage
赞
踩
先决条件:创建数据库,存储帐户的名称和密钥
流程:创建 adftutorial 容器 ->创建数据工厂->创建管道->创建数据集->创建链接服务->创建触发器
获取存储帐户名称和帐户密钥
-
使用 Azure 用户名和密码登录到 Azure 门户。
-
在左窗格中,选择“所有服务”。 使用“存储”关键字进行筛选,然后选择“存储帐户”。

-
在存储帐户列表中,根据需要通过筛选找出你的存储帐户, 然后选择存储帐户。
-
在“存储帐户”窗口中选择“访问密钥” 。
-
复制“存储帐户名称”和“key1”框中的值,然后将其粘贴到记事本或其他编辑器
创建 adftutorial 容器
此部分在 Blob 存储中创建名为 adftutorial 的 Blob 容器。
-
在“存储帐户”窗口中,转到“概览”,然后选择“容器”。

-
在“容器”窗口中,选择“+ 容器”来新建容器。
-
在“新建容器”窗口的“名称”下,输入 adftutorial。 然后选择“创建”。
-
在容器列表中,选择你刚才创建的 adftutorial。
-
让 adftutorial 的“容器”窗口保持打开状态。 在教程结束时使用它来验证输出。 数据工厂自动在该容器中创建输出文件夹,因此不需要你来创建。
创建数据工厂
创建管道
-
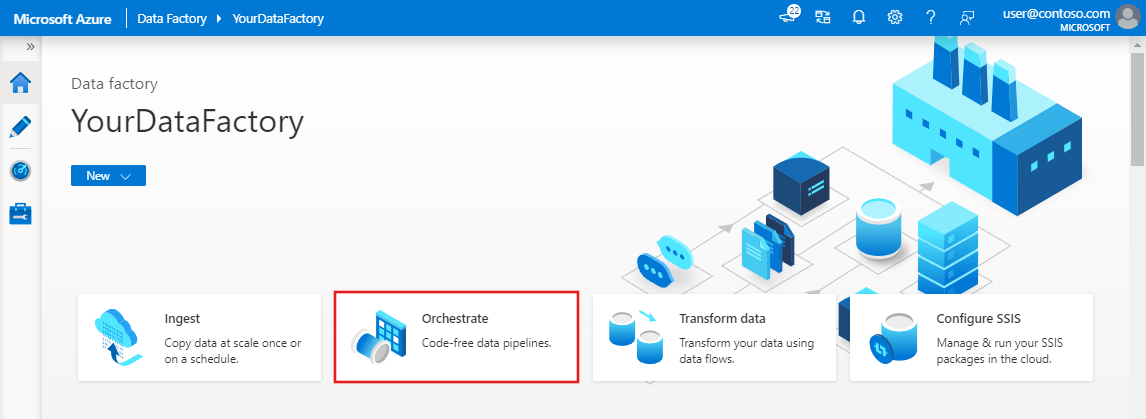
在 Azure 数据工厂主页上,选择“协调”。 系统会自动创建一个管道。 可以在树状视图中看到该管道,并且其编辑器已打开。
-
在“常规”面板的“属性”中,将“名称”指定为 SQLServerToBlobPipeline 。 然后通过单击右上角的“属性”图标来折叠面板。
-
在“活动”工具箱中,展开“移动和转换”。 将“复制”活动拖放到管道设计图面。 将活动的名称设置为 CopySqlServerToAzureBlobActivity。
-
在“属性”窗口中转到“源”选项卡,然后选择“+ 新建”。
-
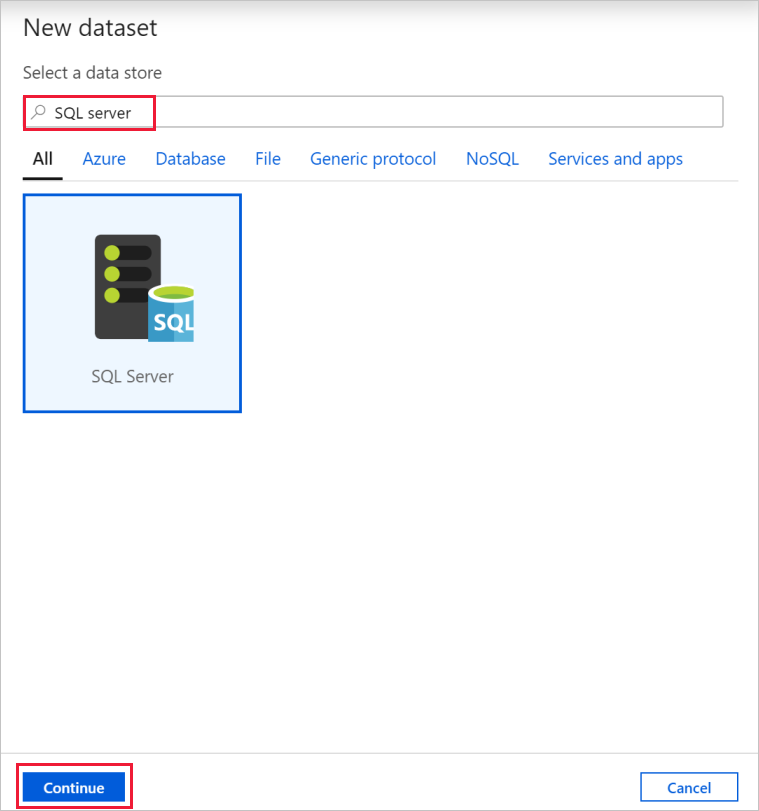
在“新建数据集”对话框中搜索“SQL Server”。 选择“SQL Server”,然后选择“继续”。
-
在“设置属性”对话框中的“名称”下,输入 SqlServerDataset。 在“链接服务”下,选择“+新建”。 执行此步骤来与源数据存储(SQL Server 数据库)建立连接。
-
在“新建链接服务”对话框中,添加 SqlServerLinkedService 作为名称。 在“通过集成运行时连接”下选择“+新建”。 在本部分,请创建一个自承载 Integration Runtime,然后将其与安装了 SQL Server 数据库的本地计算机相关联。 自承载 Integration Runtime 是一个组件,用于将数据从计算机上的 SQL Server 数据库复制到 Blob 存储。
-
在“集成运行时安装”对话框中选择“自承载”,然后选择“继续”。
-
在“名称”下,输入 TutorialIntegrationRuntime。 然后选择“创建”。
-
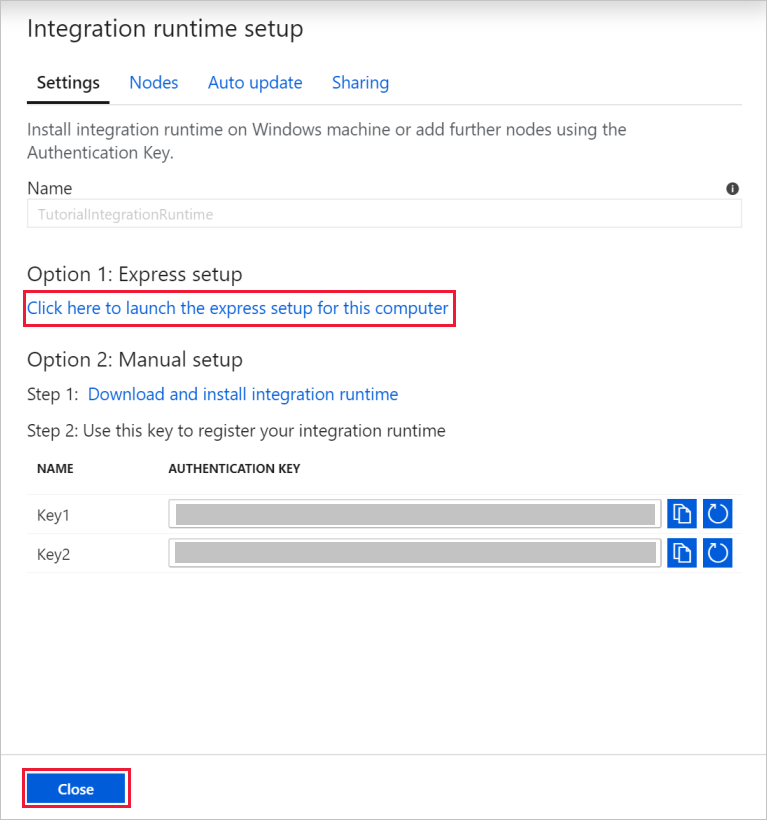
对于“设置”,选择“单击此处对此计算机启动快速安装”。 此操作在计算机上安装集成运行时,并将其注册到数据工厂。 或者,可以使用手动安装选项来下载安装文件、运行该文件,并使用密钥来注册集成运行时。
-
在过程完成时,在“Integration Runtime (自承载)快速安装”窗口中,选择“关闭”。
-
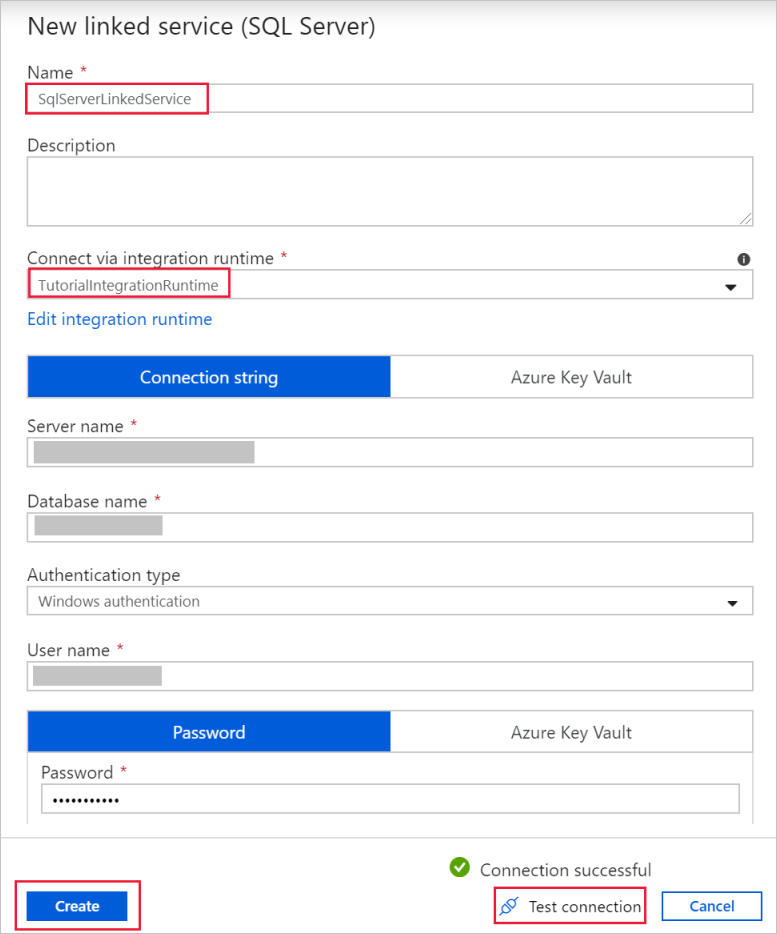
在“新建链接服务(SQL Server)”对话框中,确认在“通过集成运行时连接”下选择了 TutorialIntegrationRuntime。 然后执行以下步骤:
a. 在“名称”下输入 SqlServerLinkedService。
b. 在“服务器名称”下,输入 SQL Server 实例的名称。
c. 在“数据库名称”下,输入包含 emp 表的数据库的名称。
d. 在“身份验证类型”下,选择数据工厂在连接到 SQL Server 数据库时会使用的相应身份验证类型。
e. 在“用户名”和“密码”下,输入用户名和密码。 如果需要,请使用 mydomain\myuser 作为用户名。
f. 选择“测试连接”。 执行此步骤是为了确认数据工厂是否可以使用已创建的自承载集成运行时连接到 SQL Server 数据库。
g. 若要保存链接服务,请选择“创建”。
-
创建链接服务后,将会返回到 SqlServerDataset 的“设置属性”页。 执行以下步骤:
a. 在“链接服务”中,确认显示了“SqlServerLinkedService”。
b. 在“表名称”下,选择 [dbo].[emp] 。
c. 选择“确定”。
-
转到包含 SQLServerToBlobPipeline 的选项卡,或在树状视图中选择“SQLServerToBlobPipeline”。
-
转到“属性”窗口底部的“接收器”选项卡,选择“+ 新建”。
-
在“新建数据集”对话框中,选择“Azure Blob 存储”, 然后选择“继续”。
-
在“选择格式”对话框中,选择数据的格式类型。 然后选择“继续”。

-
在“设置属性”对话框中,输入 AzureBlobDataset 作为名称。 在“链接服务”文本框旁边,选择“+ 新建”。
-
在“新建链接服务(Azure Blob 存储)”对话框中,输入 AzureStorageLinkedService 作为名称,从“存储帐户名称”列表中选择你的存储帐户。 测试连接,然后选择“创建”以部署该链接服务。
-
创建链接服务后,将返回到“设置属性”页。 选择“确定”。
-
打开接收器数据集。 在“连接”选项卡中执行以下步骤:
a. 在“链接服务”中,确认选择了“AzureStorageLinkedService”。
b. 在文件路径中,输入 adfTutorial/fromonprem 作为“容器/目录”部分。 如果 adftutorial 容器中不包含 output 文件夹,数据工厂会自动创建 output 文件夹。
c. 对于“文件”部分,选择“添加动态内容”。
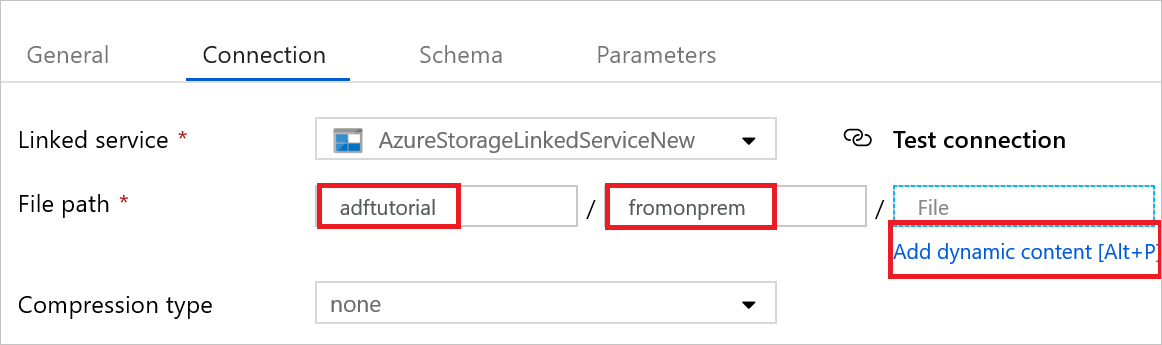
d. 添加
@CONCAT(pipeline().RunId, '.txt'),然后选择“完成”。 此操作会将文件重命名为 PipelineRunID.txt。 -
转到已打开该管道的选项卡,或者在树状视图中选择该管道。 在“接收器数据集”中,确认选择了“AzureBlobDataset”。
-
若要验证管道设置,请在工具栏中选择该管道对应的“验证”。 若要关闭管道验证输出,请选择 >> 图标。

-
若要将创建的实体发布到数据工厂,请选择“全部发布”。
-
等到“发布完成”弹出消息出现。 若要检查发布状态,请选择窗口顶部的“显示通知”链接。 若要关闭通知窗口,请选择“关闭”。
触发管道运行
在管道的工具栏上选择“添加触发器”,然后选择“立即触发”。
监视管道运行
-
转到“监视”选项卡。此时会看到在上一步手动触发的管道。
-
若要查看与管道运行关联的活动运行,请选择“管道名称”下的“SQLServerToBlobPipeline”链接。

-
在“活动运行”页面上,选择“详细信息”(眼镜图像)链接来查看有关复制操作的详细信息。 若要回到“管道运行”视图,请选择顶部的“所有管道运行”。
验证输出
该管道自动在 adftutorial Blob 容器中创建名为 fromonprem 的输出文件夹。 确认在输出文件夹中看到了 [pipeline().RunId].txt 文件。


