
- 1Docker 之 入门使用_容器 apk 无法安装groupadd
- 2Virtex-6中的BRAM(Block RAM)模块、DSP 模块XtremeDSP_带符号的25位输入、18位输入进行相乘的乘法器
- 3tcpdump速查表
- 4【工具使用】几款优秀的SSH连接客户端软件工具推荐FinalShell、Xshell、MobaXterm、OpenSSH、PUTTY、Terminus、mRemoteNG、Terminals等_ssh工具
- 55G承载网丨5G前传网络中的4种WDM技术_11、 5g承载网网络分片采用的技术是()
- 6【综述】DSP处理器芯片
- 7idea快捷键设置_idea设置快捷键为idea
- 8Yolov3原理原理分析_yolov3是什么
- 9android 监听网络状态的变化及实战,安卓开发入门教程
- 10黑客攻击入侵流程及常见攻击工具_wtmpclean
关联规则——Apriori算法_简述ap rio n算法中生成关联规则的步骤
赞
踩
实 验 目 的:
1、理解关联规则中Apriori算法实现原理
2、掌握项集和频繁项集的定义。
3.掌握如何从低阶频繁项生成高阶候选项。
4.掌握如何进行连接和剪枝。
5.掌握如何利用频繁项生成所有的强关联规则
实 验 环 境:
Anaconda
实 验 内 容 及 过 程:
关联规则发现是数据挖掘中重要的算法之一,有许多版本变种和应用场景。关联规则发现算法的基础算法之一是Apriori算法,要求针对某种格式数据和给定的阈值,代码实现Apriori算法,最终能够产生所有的强关联规则。其中数据格式不限,数据源任选。
步骤一:选取数据集(图1),代码如图2,设定最小支持度s和最小置信度c;
步骤二:获取数据集(图3),并获取数据集中的的子集,利用最小支持数选出满足的子集。(图4)


图1 图2

图3

图4
步骤三:根据频繁(k-1)项集自身连接产生候选K项集Ck,并剪去不符合条件的候选。(图5)
步骤四:根据数据集获取频繁项集。(图6)
步骤五:定义获取关联规则(图7)
 图5
图5
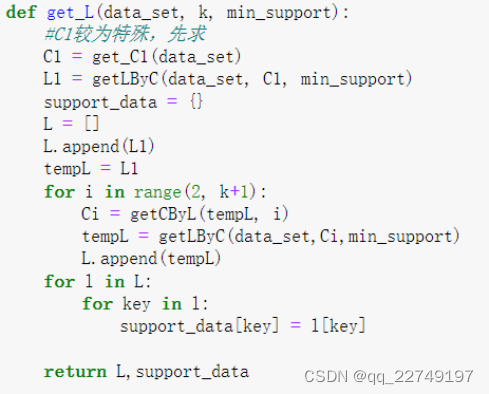
图6
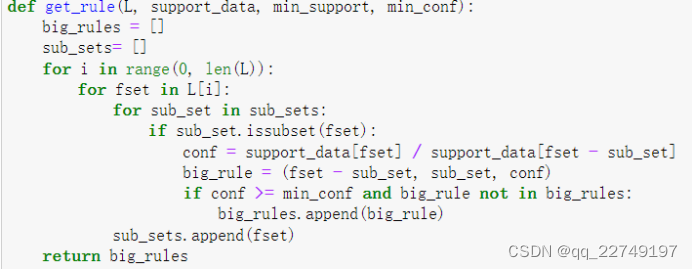 图7
图7
由于规则是由频繁项集产生,因此每个规则都自动地满足最小支持度。频繁项集和它们的最小支持度可以预先存放在散列表中。
 结果展示
结果展示
实 验 心 得:
通过这次的实验我明白,Apriori关联规则挖掘一般可分成两个步骤:第一步找出所有支持度大于等于最小支持度阈值的频繁项集。第二步由频繁模式生成满足可信度阈值的关联规则。
那什么时候算法结束呢?细看代码,我们可以发现如果⾃连接得到的已经不再是频繁集,那么取最后⼀次得到的频繁集作为结果。
需要值得注意的是:Apriori算法为了进⼀步缩⼩需要计算⽀持度的候选集⼤⼩,减⼩计算量,所以在取得候选集时就进⾏了它的⼦集必须也是频繁集的判断。

