
- 1超详细Django+vue+vscode前后端分离搭建_vue django
- 2如何利用美国多IP站群服务器进行网站SEO优化的有效策略?
- 3测试环境csv文件数据导入parquet存储文件后用limit查询报错问题解决_oracle 数据导入 parquet
- 4软考 软件设计师基础笔记二:程序设计语言_软考正则表达式
- 5LibreTranslate
- 6[蓝桥杯物联网从0开始]15届蓝桥杯省赛备赛,串口与ADC的使用方法,简单代码例程,代码详解_蓝桥杯物联网adc
- 7无人机+三维建模:倾斜摄影技术详解
- 8Linux调度策略及线程优先级设置_linux 一个任务经常调度另一个线程偶尔调度该如何配置线程的调度方式和优先级
- 9【C++知识树】Vector.h&Geometry3D----三维空间向量计算几何算法汇总【ZENO、Blender、game-physics-cookbook、UE5、Godot】_c++三维向量
- 10promethus监控mysql指标_基于prometheus+grafana体系实时监控mysql数据库,值得收藏
协同过滤的进化--矩阵分解算法(MF)_mf(矩阵分解)计算公式
赞
踩
一: MF基础知识
线性代数,机器学习,梯度下降等内容需要各位看官在了解本文之前进行一定基础学习。MF解决的主要问题在两点,这两点也是协同过滤的主要缺点,第一是协同过滤处理稀疏矩阵的能力较弱(共现矩阵稀疏,繁华能力弱)(),第二是协同过滤中相似度矩阵维护难度大(维度高)。矩阵分解的解决思路就是将一个矩阵分解为两个矩阵相乘(MXN = MK X KN,其中K是隐向量),就可以解决这两个问题。例如:

在实际应用中,矩阵是稀疏的,隐向量特征是不可解释的,需要模型自己去学习,同时K值的大小决定了隐向量的表征能力的强弱(K值越大,用户的兴趣和物品的分类就越详细)。最后,我们通过用户矩阵和物品矩阵,可以预测评分计算公式:
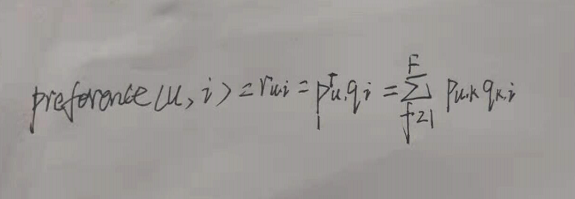
Pu是用户u在用户矩阵U中对应的行向量,qi是物品i在物品矩阵V中对应的列向量。
二:矩阵分解算法(MF)的几种方式
1,特征值和特征向量
我们首先回顾下特征值和特征向量的定义如下:
Ax=λx
其中A是一个n×n的实对称矩阵,x是一个n维向量,则我们说λ是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量。
求出特征值和特征向量有什么好处呢? 就是我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值λ1≤λ2≤…≤λn,以及这n个特征值所对应的特征向量{w1,w2,…wn},,如果这n个特征向量线性无关,那么矩阵A就可以用下式的特征分解表示:
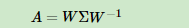
其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵。
一般我们会把W的这n个特征向量标准化,即满足||wi||2=1, 或者说wTiwi=1,此时W的n个特征向量为标准正交基,满足WTW=I,即WT=W−1, 也就是说W为酉矩阵。
这样我们的特征分解表达式可以写成
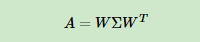
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
2,奇异值分解(svd)
一:定义:
将一个非零的MXN阶矩阵A,表示为以下三个矩阵的乘积,即进行矩阵的因子分解:

一张图,一目了然,详细定义可参考李航老师《统计学习方法(第二版)》271页。在定理中,需要注意的是,给定任意一个实矩阵,其奇异值分解一定存在,在奇异值分解中,奇异值是唯一的,而矩阵U和矩阵V是不唯一的。
二:奇异值分解计算步骤
1,构造n阶实对称矩阵W = A(AT), AT为实矩阵A的转置矩阵
证明:ATA是一个实对称矩阵
一个矩阵和自己的转置矩阵相等,则该矩阵为实对称矩阵,即AT = A
(ATA)T = WT,则有:(ATA) T= AT(AT)T = ATA = W,所以,ATA必为一个实对称矩阵
2,计算W的特征值和特征向量,将特征值降序排列。
求解:(W-ƛI)x = 0,得到特征值ƛ 然后将ƛ带入特征方程求得特征向量,基础知识不用在重复了
3,将上述特征向量单位化,求得n阶正交矩阵V

4,将上述特征值开更号,得到奇异值,则求得mxn阶对角矩阵∑.
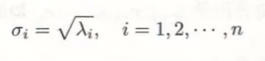
5,求M阶正交矩阵U:
1,求u1 :对前R个(非零奇异值)正奇异值,利用A乘以前面的单位特征向量v再除以每一个正奇异值,得到U1集合 = (u1,u2,u3)

2,求U2:求AT零空间的一组标准正交基

3,U = [U1,U2]
简单的例子:

三:传统的奇异值分解Traditional SVD的缺点:
1,奇异值分解要求原矩阵是稠密的,而在实际应用中矩阵通常是稀疏的,如果要用奇异值分解,就必然要进行矩阵填充,这是一个问题,传统SVD采用的方法是对评分矩阵中的缺失值进行简单的补全,比如用全局平均值或者用用户物品平均值补全,得到补全后的矩阵。接着可以用SVD分解并降维。一旦填充,矩阵的空间复杂度就会很高,而且我们填充的数据不一定对。
2,svd的计算复杂度很高,而我们本来的用户-物品矩阵维度就很高,计算复杂度就会进一步增加,因此,svd基本无法使用。
总结:svd并不适合于解决大规模稀疏矩阵的矩阵分解问题。
3, FunkSVD算法(LFM)
FunkSVD是在传统SVD面临计算效率问题时提出来的,既然将一个矩阵做SVD分解成3个矩阵很耗时,同时还面临稀疏的问题,那么我们能不能避开稀疏问题,同时只分解成两个矩阵呢?也就是说,现在期望我们的矩阵R这样进行分解:
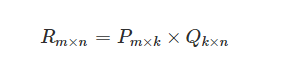
这种简化的矩阵分解不再是分解为三个矩阵,而是分解为两个低秩的用户和物品矩阵,其实就是把用户和物品都映射到一个 k 维空间中,这个 k 维空间对应着 k 个隐因子,我们认为用户对物品的评分主要是由这些隐因子影响的,所以这些隐因子代表了用户和物品一部分共有的特征,在物品身上表现为属性特征,在用户身上表现为偏好特征。
我们知道SVD分解已经很成熟了,但是FunkSVD如何将矩阵R分解为P和Q呢?这里采用了线性回归的思想。我们的目标是让用户的评分和用矩阵乘积得到的评分残差尽可能的小,也就是说,可以用均方差作为损失函数,来寻找最终的P和Q。即通过 User-Item 评分信息来学习到的用户特征矩阵 P 和物品特征矩阵 Q,通过重构的低维矩阵预测用户对物品的评分。
核心思想:将矩阵分解问题转化为最优化问题,并通过梯度下降进行优化。
预测函数:
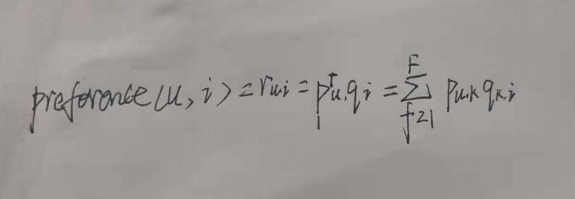
损失函数:误差平方和(sse):

优化目标:最小化每一个sse。即真实值和预测值差值平方最小化。

当然,在实际应用中,我们为了防止过拟合,会加入一个L2的正则化项,因此正式的FunkSVD的优化目标函数J(p,q)是这样的:
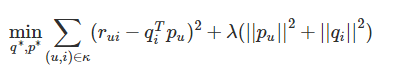
例子:

优化方法:梯度下降。
求梯度:
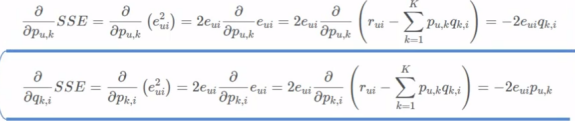
梯度更新:
实现步骤:
1,矩阵分解,初始化矩阵U(Pu)和矩阵V(Qi)
2,根据两个隐向量矩阵相乘,得到预测值pred。
3,根据label和pred来计算损失
4,通过梯度下降来更新两个隐向量矩阵的值
5,利用该用户的隐向量与所有物品的隐向量进行逐一内积运算,得到该用户对所有物品的评分预测,然后排序,得到推荐列表。
6,进行推荐。
4,BaisSVD:
核心思想: 在FunkSVD算法火爆之后,出现了很多FunkSVD的改进版算法。其中BiasSVD算是改进的比较成功的一种算法。BiasSVD假设评分系统包括三部分的偏置因素:一些和用户物品无关的评分因素,用户有一些和物品无关的评分因素,称为用户偏置项。而物品也有一些和用户无关的评分因素,称为物品偏置项。这其实很好理解。比如一个垃圾山寨货评分不可能高,自带这种烂属性的物品由于这个因素会直接导致用户评分低,与用户无关。
所以预测评分加上偏置部分后为:

假设评分系统平均分为μ,第i个用户的用户偏置项为bi,而第j个物品的物品偏置项为bj,则加入了偏置项以后的优化目标函数J(p,q)是这样的

这个优化目标也可以采用梯度下降法求解。和FunkSVD不同的是,此时我们多了两个偏执项bi,bj,,pi,qj的迭代公式和FunkSVD类似,只是每一步的梯度导数稍有不同而已,这里就不给出了。而bi,bj一般可以初始设置为0,然后参与迭代。这里给出bi,bj的迭代方法:
通过迭代我们最终可以得到P和Q,进而用于推荐。BiasSVD增加了一些额外因素的考虑,因此在某些场景会比FunkSVD表现好。
5,svd++
核心思想: :
1,引入了被评分的历史物品
2,模型考虑物品与物品之间的联系对物品评分的影响
预测函数:

这里有个预测函数的推演过程,有兴趣的可以推一下

优化目标:最小化每一个sse。即真实值和预测值差值平方最小化。
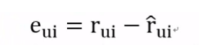
优化方法:梯度下降(略),梯度更新

三:MF算法和协同过滤的比较
相对优势:
1,与协同过滤相比,MF算法泛化能力强,在一定程度上解决了数据稀疏的问题
首先,协同过滤中,用户矩阵和物品矩阵中,由于数据稀疏性,导致相似度无法计算的情况是常事,而在矩阵分解中,例如basicSVD、rsvd和svd++.,由于使用梯度下降对目标函数进行优化。我们就只需要根据已知的评分来对拟合两个矩阵,然后通过这两个矩阵去预测缺失值。其次,在svd++中,充分考虑了物品与物品之间的联系对评分的影响,用户和物品的画像都得到了丰富,提高了泛化能力。
2,空间复杂度更低。
ucf: MXM
ICF:nxn
MF: MXK 、NXK
3,更高的灵活度和扩展性
隐向量的产生,模型的表征能力更强。灵活度和扩展性也就更强
共同劣势:
1,无法利用用户特征,物品特征,上下文特征
2,缺乏用户历史行为时,无法进行推荐
4,更多矩阵分解可参考该文章

