
- 1docker错误 download failed after attempts=6 :net/http :tls handshake timeout_docker: error pulling image configuration: downloa
- 2[附源码]java+ssm计算机毕业设计医院药品进销存系统【源码+数据库+LW+部署】_公立医院的进销存数据需要本地部署吗?
- 3Netbeans的编译和打包ant脚本----英文版_netbeans ant
- 4操作系统内核概念
- 5关于计算机如何区分有符号数与无符号数_有符号数和无符号数的区别
- 6mybatis动态SQL对数据库执行增删改查学习笔记_getusercountbyroleid为根据角色id查询该角色下是否有用户信息。返回该角色id下的
- 7西南科技大学数字电子技术实验一(数字信号基本参数与逻辑门电路功能测试及FPGA 实现)FPGA部分_大学数电实验
- 8SAP HR 工资核算异常的一些处理方式_sap 重新入职人员工资核算 报错期间开始 2023.10.01 早于最早可能的 ra 运行日期
- 9Windows 源码编译 MariaDB_mariadb odbc 驱动源码 windows 下 如何编译
- 10报错:The installer has encountered an unexpected error installing this package 使用超管运行安装文件
基于多向量检索器的多模态 RAG 实现_rag实现
赞
踩
长话短说
下面三个 LangChain 示例代码,展示了如何使用 LangChain 多向量检索器(Multi-Vector Retriever)对多内容类型的文档实现更好的 RAG 效果。后面两个示例还涵盖了一些配合多模态 LLM 的多矢量检索器用法,以实现针对图像的 RAG。
详细内容
一般来讲,一个 LLM 应用可以通过两种方式获取新信息
-
权重更新(如微调)
-
RAG(检索增强生成)
后者通过 Prompt 将相关上下文传递给 LLM。它将 LLM 的推理能力与外部数据源的内容结合起来,所提特别适用于事实提取。

多向量检索器可以从多种数据类型(文本、表格、图像)中检索相关的内容,并将其作为上下文传递给 LLM 用于生成答案。

其核心思想是将文档(用于答案合成)和引用(用于检索)分离,这样可以针对不同的数据类型生成适合自然语言检索的摘要,同时保留原始的数据内容。它可以与多模态 LLM 结合,实现跨模态的 RAG。
当然,如果要使用多向量检索器,我们首先需要把一个文档分割成不同的信息类型。这里要提一下Unstructured,一个非常不错的针对非结构化数据的预处理开源工具,可以从多种文件类型中提取表格、图像、文本等信息类型。例如,如果需要分割一个 PDF 文件,Unstructured 会首先移除所有嵌入的图像块。然后,用 YOLOX 布局模型来获取边界框(表格)和 titles,即文档的子章节(如导言等)。然后进行后处理,汇总每个 title 下的文本,并根据用户特定的标记(如最小块大小等)进一步分块成文本块,以便进行下游处理。
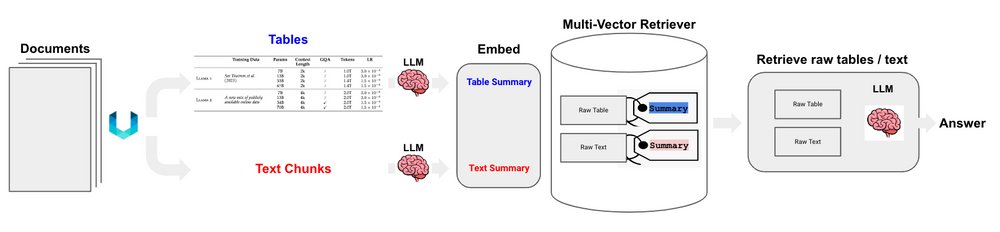
Unstructured 文件解析结合多向量检索器可以很好地支持针对半结构化数据的 RAG,因为所生成的表元素 summaries 更适合自然语言检索。简单来讲,就是先通过对用户的问题进行语义相似性检索,找到表格摘要,然后把 原表格 传递给 LLM 进行答案合成,如图所示:
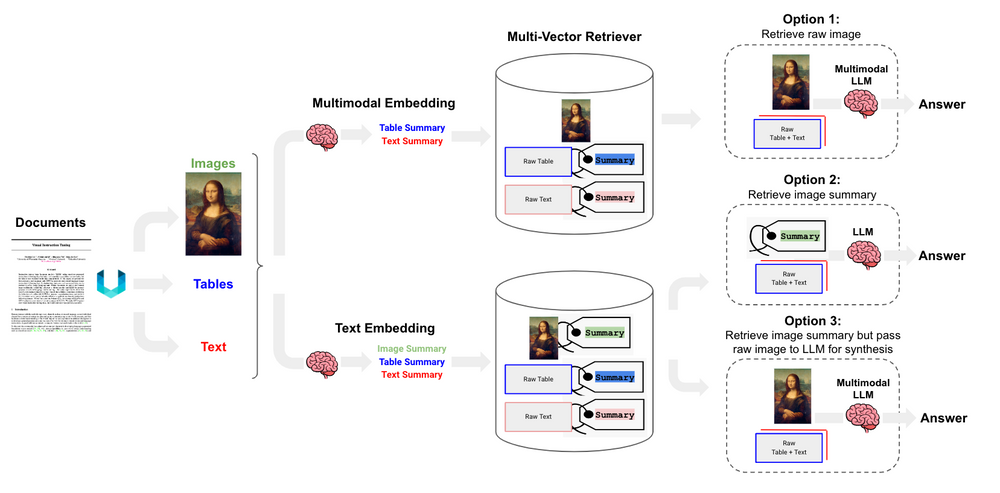
因为诸如 GPT4-V、LLaVA(开源)、Fuyu-8b(开源)等多模态 LLM 的发布,我们不仅可以处理表格,还可以进一步处理图像。下面列举了 3 种利用多向量检索器来达到这个效果的方法:
-
使用多模态 embeddings(如 CLIP)将图像和文本嵌入在一起。然后,对于其中一个进行相似性检索,并在 docstore 中链接到原始图像。最后,将原始图像和文本块传递给多模态 LLM 进行合成。
-
使用多模态 LLM(如 GPT4-V、LLaVA 或 FUYU-8b)从图像中生成文本摘要。然后,使用文本模型 embed 文本摘要。同上,需要在 docstore 中连接至原始文本或图像,以便 LLM 进行答案合成。
(原文中的方法 2 和 3 实际上可以看作是一种方法,这里合并了。)
LangChain 团队使用 LLaVA-7b 模型做了一个测试(这个模型最近被添加到了 llama.cpp,可以在消费级笔记本 Mac M2 Max 上运行)。
首先,生成图像的文本总结。比如下面这个图,总结就很准确地抓住了重点:
图片是一个装满各种炸鸡块的托盘。鸡块的摆放方式类似于世界地图,有些鸡块摆成大陆的形状,有些则摆成国家的形状。鸡块的排列方式创造了一个具有视觉吸引力和趣味性的世界。

然后就可以将这些内容结合表格和文本摘要一起存储在多向量检索器中。
如果担心数据隐私问题,可以在本地使用开源项目在消费级笔记本电脑上运行这个 RAG 管道,包括用于图像摘要的 LLaVA 7b、Chroma vectorstore、开源 embedding(Nomic 的 GPT4All)、多向量检索器,以及 LLaMA2-13b-chat 并通过 Ollama.ai 生成答案 。

