
- 1大数据技术原理与应用-林子雨版-课后习题答案_大数据技术原理与应用第三版林子雨课后答案
- 2cyclone v hwlib使用问题_altera hwlib
- 3Java-API:javax.servlet.http.HttpServletResponse
- 4Pytorch-01 框架简介
- 5redis_exporter部署记录_redis-exporter
- 6自动化测试selenium(一)
- 7【算法题】动态规划基础阶段之买卖股票的最佳时机、比特位计数、判断子序列_股票买卖算法题
- 82024年最新! CleanMyMac X v4.15.0 中文破解版 Mac优化清理工具_cleanmymacx
- 9大学生职业生涯发展与规划_决策目标体验单
- 10golang游戏服务器项目,基于Golang的游戏服务器框架nucleus开发日记(一)
利用AI开源引擎:实现在消费者投诉处理中的智能分析|可本地化部署_ai驱动的实时情绪识别 客户投诉
赞
踩
随着消费者投诉渠道逐渐多样化,电话、网络等途径使得消费者的声音能够更加迅速地被职能部门所接收。然而,大量的投诉信息也给职能部门带来了巨大的处理压力。如何高效地从消费者投诉中抽取关键信息,并对这些信息进行分类和统计,成为了提升处理效率和服务质量的关键。 本文将探讨如何利用智能文本分析技术,对消费者投诉意见进行自动化处理,实现对投诉类型、投诉分类、二级投诉分类、涉案地址、涉案金额、涉案企业/单位等多个字段的自动抽取和分类,并最终实现统计分类的结果展示。
开源项目介绍(可本地部署,支持国产化)
思通数科研发了一款多模态AI能力引擎,专注于提供自然语言处理(NLP)、情感分析、实体识别、图像识别与分类、OCR识别和语音识别等接口服务。该平台功能强大,支持本地化部署,并鼓励用户体验和开发者共同完善,以实现开源共享。

开源项目地址
AI多模态能力平台: 免费的自然语言处理、情感分析、实体识别、图像识别与分类、OCR识别、语音识别接口,功能强大,欢迎体验。
https://gitee.com/stonedtx/free-nlp-api![]() https://gitee.com/stonedtx/free-nlp-api
https://gitee.com/stonedtx/free-nlp-api
在线体验地址
微信扫码,即可体验产品![]() https://nlp.stonedt.com/
https://nlp.stonedt.com/
1. 智能文本分析技术概述
智能文本分析技术是指利用自然语言处理(NLP)、机器学习(ML)等方法,对文本数据进行分析和理解的技术。通过该技术,可以从非结构化的文本数据中提取出结构化的信息,进而进行有效的数据挖掘和知识发现。
2. 消费者投诉文本的特点
消费者投诉文本通常包含丰富的情感色彩和个性化表达,同时涉及多个领域的专业术语。这些特点为文本分析带来了挑战,但也提供了丰富的语义信息,有助于提高分析的准确性。
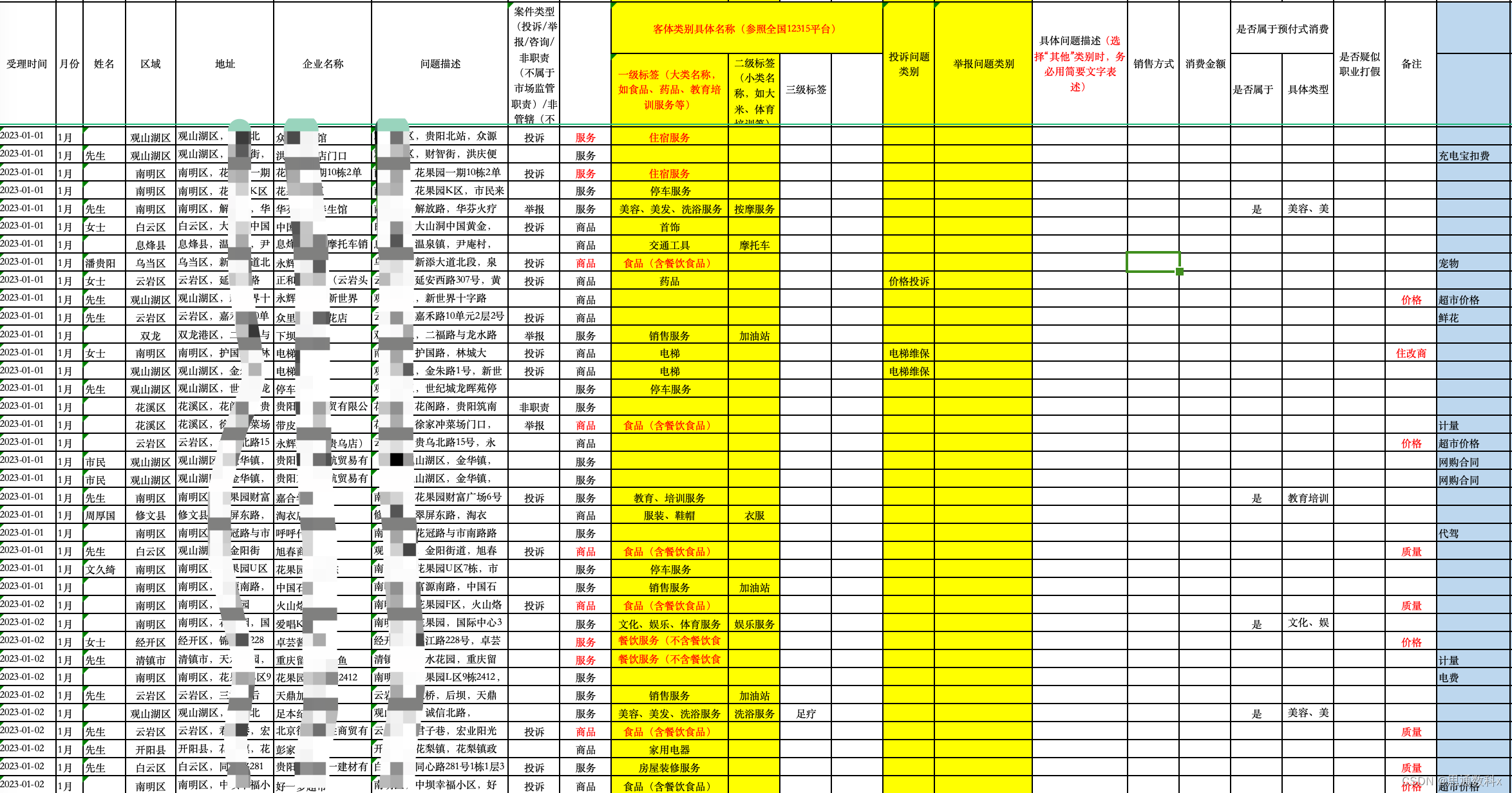
3. 自动抽取与分类流程
3.1 数据预处理
首先对投诉文本进行预处理,包括去除噪声、分词、词性标注等步骤,为后续的信息抽取打下基础。
3.2 关键信息抽取
利用命名实体识别(NER)技术,从文本中抽取关键信息,如涉案地址、涉案金额、涉案企业/单位等。同时,通过依存句法分析(Dependency Parsing)等技术,识别文本中的语义关系,为信息分类提供依据。
3.3 投诉分类
根据抽取出的关键信息和文本内容,利用文本分类算法对投诉进行分类。可以采用支持向量机(SVM)、随机森林(Random Forest)或深度学习(Deep Learning)等方法,根据预先定义的类别体系进行分类。
3.4 结果展示与统计
将分类结果以直观的形式展示出来,如图表、报表等,便于职能部门进行决策和监督。同时,对分类结果进行统计分析,发现投诉的热点问题和趋势,为优化服务提供参考。
4. 实际案例分析
以提供的投诉文本为例,通过智能文本分析技术,我们能够自动抽取出以下信息:
- 投诉类型:退款问题
- 投诉分类:教育培训服务
- 二级投诉分类:服务合同问题
- 涉案地址:观S湖区,世纪J源国际商务中心300号楼1206层
- 涉案金额:438元
- 涉案企业/单位:贵州xx教育咨询有限公司
- 时间:2022年6月20日至9月13日

