
- 18、Qt—Log4Qt使用小记2(每日产生文件)
- 2微信小程序uniapp+django洗脚按摩足浴城消费系统springboot
- 3Flask框架九:Flask-SQLAlchemy插件_flask-sqlachemy作用
- 4复旦大学软件工程电子信息考研信息_软件开发专业研究生是几年制
- 5web测试用例_点击当前用例显示子用例
- 6Kafka与RabbitMQ的区别_kafaka和rabitmq的区别
- 7sql的四种连接——左外连接、右外连接、内连接、全连接_全外连接
- 82020清华深圳国际研究院 计算机线上夏令营总结_清华深研院计算机保研夏令营
- 9Postman报错提示 Could not get any response怎么解决_postman could not get any response
- 10排序算法——快速排序(图解+代码)_快速排序算法
Linux学习笔记4—Linux环境的基础开发工具(yum、vim、GCC、gdb、make、git)的初步学习与使用_git的怎么使用sudo yum install -y tree
赞
踩
文章目录
1 Linux软件包管理器yum
Linux下安装卸载软件的三种解决方案:
- 源码安装
- 由于源码安装可能存在不同的环境的兼容问题,所以有人在不同的环境下都已经编译好了源码放到了包里,这种方式称为rpm安装
- 因为Linux的环境主要用于开发,所以Linux下可能存在大量的软件之间的依赖关系,安装一个库可能需要别的库,写一个代码可能依赖于某个库,前两种方案安装起来就非常麻烦,我要一步一步的根据报错信息把第三方库都安装好了,才能装这个程序,非常麻烦。可以使用yum,yum本身会考虑软件的依赖关系,而不需要我们自己处理。
yum就好像手机上的应用市场(Appstore),对一个软件,我们还没下载是,这个软件在哪呢?在应用市场的服务器或在软件厂商的服务器中,yum就像应用市场一样,是一个客户端程序。

yum三板斧:yum list、yum install、yum remove
yum中使用sudo list列出所有可以安装的软件。

如果要关键字搜索,可以sudo yum list | grep 'sl'
考虑到架构,可以这样关键字搜索sudo yum list | grep 'sl.x86_64'

sl.x86_64 5.02-1.el7 @epel
名称.架构 版本 属于红帽的centos7 开发公司
- 1
- 2
之前装过了,就会这样显示:

sudo yum remove sl.x86_64卸载这个程序,加上-y就不会有什么是否要卸载的提示。
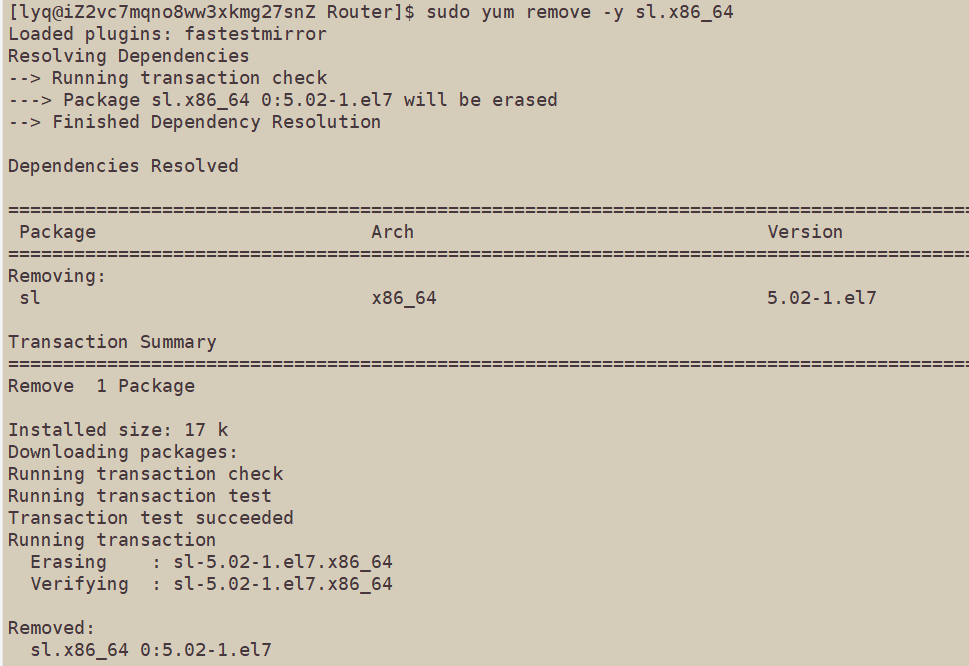
卸了以后又能重新安装了:



可以搜索一下Linux Centos7必装的软件/好玩的命令。
yum源:


这个CentOS-Base.repo是官方的,稳定的,是一些比较老的稳定的文件,非官方比较新的软件,放在扩展源里:sudo yum install -y epel-release.

注意:
- yum要工作,必须联网。
- centos里面,只能有一个yum在运行,否则会报错。
2 CentOS 7.6云服务器软件举例
I lrzsz——本地文件上传下载软件
lrzsz,安装后可以使windows和linux云服务器之间文件拖拽上传,安装命令:sudo yum install -y lrzsz。

它还可以使用指令上传下载文件。
rz:本地windows文件上传Linux服务器

sz 文件名:服务器文件上传windows

II htop——交互式进程查看器
htop是Linux下的一款交互式进程浏览器,可以用来替换Linux中的top指令
如果直接安装失败,首先更新安装包:sudo yum -y install epel-release.noarch
然后安装sudo yum -y install htop.

III GNOME+VNC——Linux服务器的远程桌面系统
如果实在是想要一个GUI桌面,Linux也是有提供开源的桌面的。
首先,运行:sudo yum groupinstall "GNOME Desktop" -y,然后等待出现complete就可以了。
如果要卸载,运行sudo yum groupremove "GNOME Desktop" -y就可以了

然后我们其实就已经安装好了图形化界面,接下来需要一个工具远程链接我们的服务器以显示图形化界面,我们安装vnc:
sudo yum -y install tigervnc-server
卸载 sudo yum -y remove tigervnc-server
- 1
- 2
然后通过以下命令启动VNC服务:
vncserver :3
- 1
3的意思就是将VNC服务绑定到5903端口,2就是5902。第一次输入的时候被要求设置登录密码,后来就不需要了。

如果要修改密码,使用
vncpasswd :3
- 1

如果要关掉vnc服务,使用(前面开的多少这里就写多少的数字)
vncserver -kill :3
- 1
然后我们去阿里云控制台防火墙中把新增的5903端口放开,这样就可以通过这个端口链接服务器了。

然后输入端口号5903,点击确定。

接下来需要在我们的电脑上安装VNC Viewer客户端,VNC® Connect consists of VNC® Viewer and VNC® Server下载并安装即可。
然后在上面输入你的服务器的ip地址:3(之前写的3这里就输入3)。

然后输入之前的密码就进来了:

关于这个GUI的使用可以上网搜GNOME对应操作怎么使用。
参考文档:
3 vim

IDE:集成开发环境,把编写、编译、调试、发布代码、运行、代码关系的维护等开发功能都继承到一起的软件就成为IDE,如VS2019.
Linux中也可以直接安装集成开发环境,不过Linux下也可以把这些功能分开使用,其中文本编辑器即为vi、vim(vi是比较早的vim).
确认vim:直接输入vim,然后会打开一个界面,退出shift + ;(也就是冒号),输入q回车即可退出。

vim + 文件名:进入编辑界面。
vim是一种多模式编辑器,主要常见的有4种模式,这里介绍三种模式:命令模式、底行模式、插入模式。
默认打开vim时就是命令模式。
命令模式下按i进入插入(Insert)模式。
然后按Esc从插入模式回退到命令模式,退出vim,从命令模式到底行模式shift :,底行模式输入w保存刚刚写入的内容,然后再退出。
有时候不让写,w!强制写;有时候不让退出,q!强制退出,强制保存并退出wq!,普通保存并退出:wq.
I 命令模式
vim打开文件后,默认处于命令模式。
1 光标相关
可以按小键盘的上下左右移动或使用h(左移一个字符),j(下移动一行),k(上移一行),l(右移一个字符)。

原因是早些年的键盘没有上下左右,使用hjsk充当上下左右,记忆技巧:h在最左边,所以是←,l在最右边,所以是→,j是jump,跳下,所以是↓,k是king,高高在“上”,所以是↑。
光标位置锚点:shift + ^:快速定位到行首;shilf + $:快速定位到行尾。
gg:定位到起始行,shift + g(也就是大写G):定位到结束行,n + shift + g;跳转到第n行。
w/b:按照单词为单位进行前后移动。w是向后移动,b是向前回退。这里符号连在一起会被视为一个单词。
2 文本操作
复制:
yy复制当前行,n + yy复制当前行及其之后的n - 1行, p在当前行下一行粘贴,n + p一次粘贴n行。

撤销:
u:撤销上一次操作。
ctrl + r:撤销最近一次的撤销。
粘贴:
yy, 10000 + p就能一瞬间粘贴一万次,这体现了vim的强大。

删除:
dd:删除当前光标所在行,支持n + dd
剪切:
dd完了用p,就是剪切后粘贴,100 p剪切后粘贴100次,支持n + p.
字母大小写切换:
shift + ~快速大小写切换。
x:删除当前光标指向的一个字符,支持nx;X或shift + x:删除光标之前的一个字符,支持nX.
r:替换当前光标的字符,支持nr,同时替换当前光标及之后n - 1个 字符;shift + r(或R):进入替换模式,之后输入的字符自动替换后续字符,Esc退出替换模式回到命令模式。
II 插入模式
命令模式下使用i或a都可以进入插入模式,a进入插入模式光标会往后移动一个字符,命令模式下o也可以进入插入模式,会新起一行,如下:

使用↑ ↓ ← →移动光标进行对应位置插入删除,和普通文本编辑器一样,不过能用命令模式做的删除复制等还是用命令模式做比较好,因为vim不支持鼠标,你用插入模式会很慢。
III 底行模式
命令模式下输入ctrl ;进入底行模式。
1 行号
set nu调出行号;set nonu关闭行号。

2 多个文件分屏
进入底行模式后输入vs 文件名即可。

当然还可以继续分屏。

底行模式wq保存并关闭当前分屏,光标在哪就关的哪个。
ctrl ww光标在不同分屏跳转。
这样就可以利用命令模式在不同文件之间剪切或复制粘贴:

底行模式下输入help vim-modes查看更多关于vim模式的知识。
IV vim的配置
vim的配置修改后,只会对自己用户的vim进行改变,root也不会例外。
首先在工作目录下创建一个.vimrc文件。
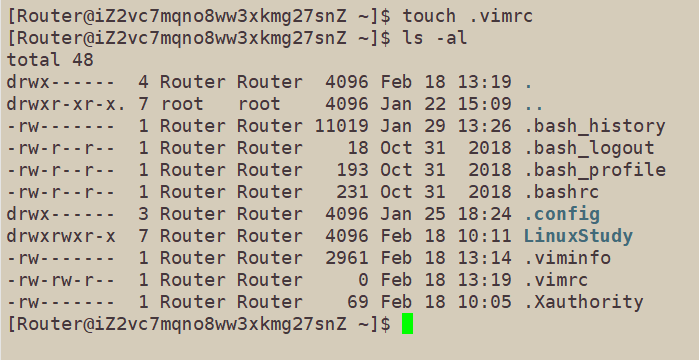
自己普通用户vim的基础配置都会写在.vimrc文件中,往其中增加命令就可以配置vim,如增加行号set nu.

打开后默认带了行号:

百度一下vim常见配置选项就可以查到很多vim的配置选项。
root用户的vim配置在/root目录下的vimrc文件中。
由于本人的主力语言是C/C++,所以直接使用gitee上的VimForCpp项目配置vim,配置后打开如下:
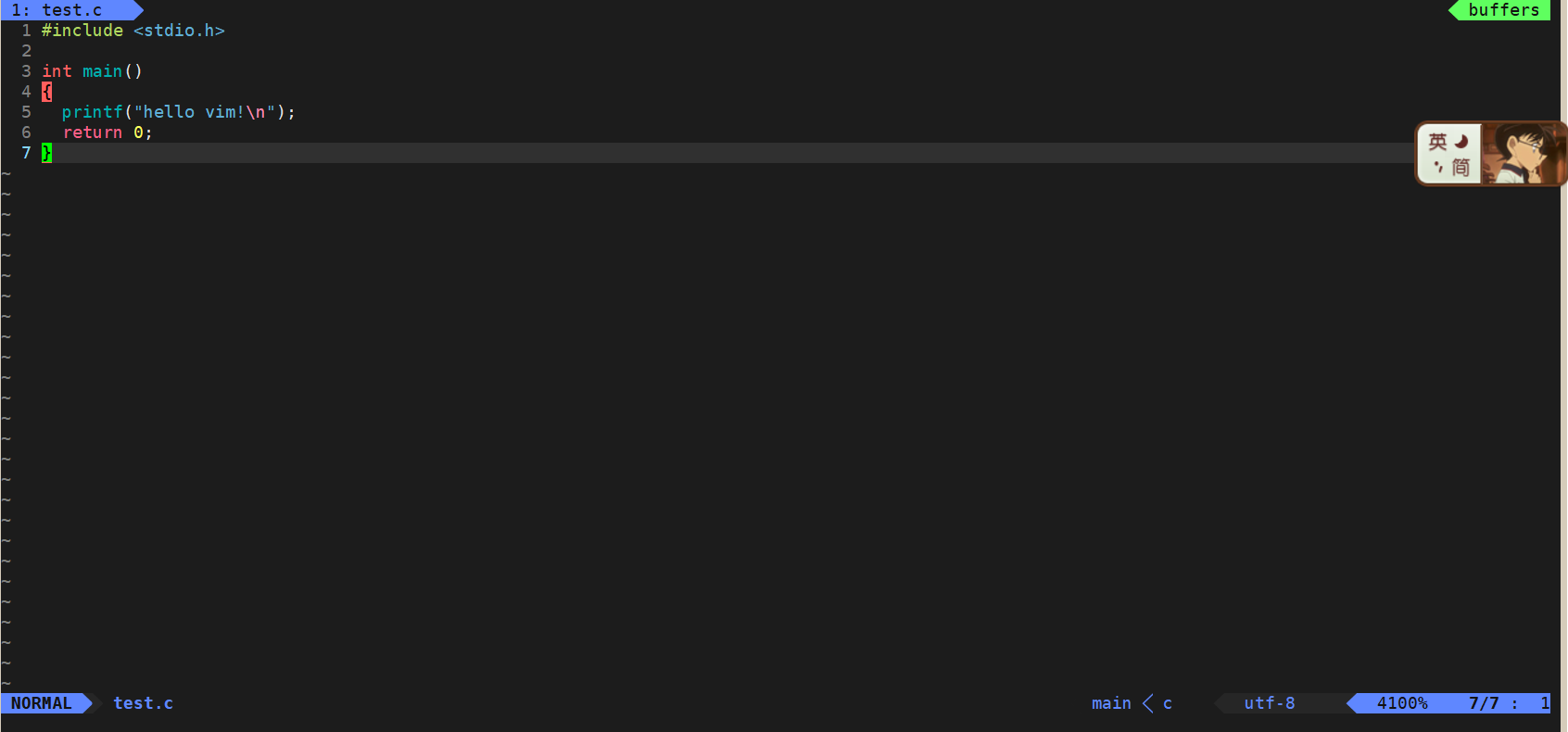
这个配置有缩进、有自动补全,非常好用。
vim学习参考资料:Vim从入门到牛逼
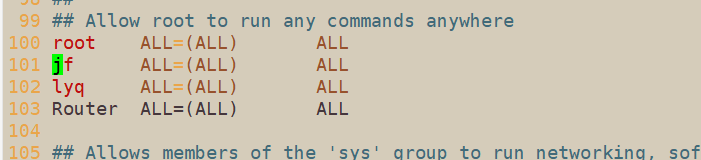
使用vim配置信任组:切换root用户,然后使用vim /etc/sudoers,然后在100行左右的allow any …那里yy复制root那一行,然后p,然后修改名字为你的用户名,然后切换底行模式wq!退出即可。
V vim的奇淫巧技
1 gg=G 瞬间全部正确缩进格式。


2 vim批量注释
ctrl + v进入某模式,然后利用hjkl作为上下左右选中需要加//的区域,然后I输入//,然后ESC退出即可。

批量取消注释:ctrl + v进入某模式,然后选中要删除区域,然后d即可。


4 Linux上的编译器—gcc/g++

直接gcc 文件名,不加任何选项生成的程序默认名字为a.out.
I -E
gcc -E 文件名
// 把“翻译”进行完预处理后停下
- 1
- 2
如果不指定生成什么文件 会把预处理后的文件直接打印到屏幕上。

加上-o 文件名.i就可以把预处理后的临时文件放到文件名.i中,预处理后的文件名字后缀一般是.i
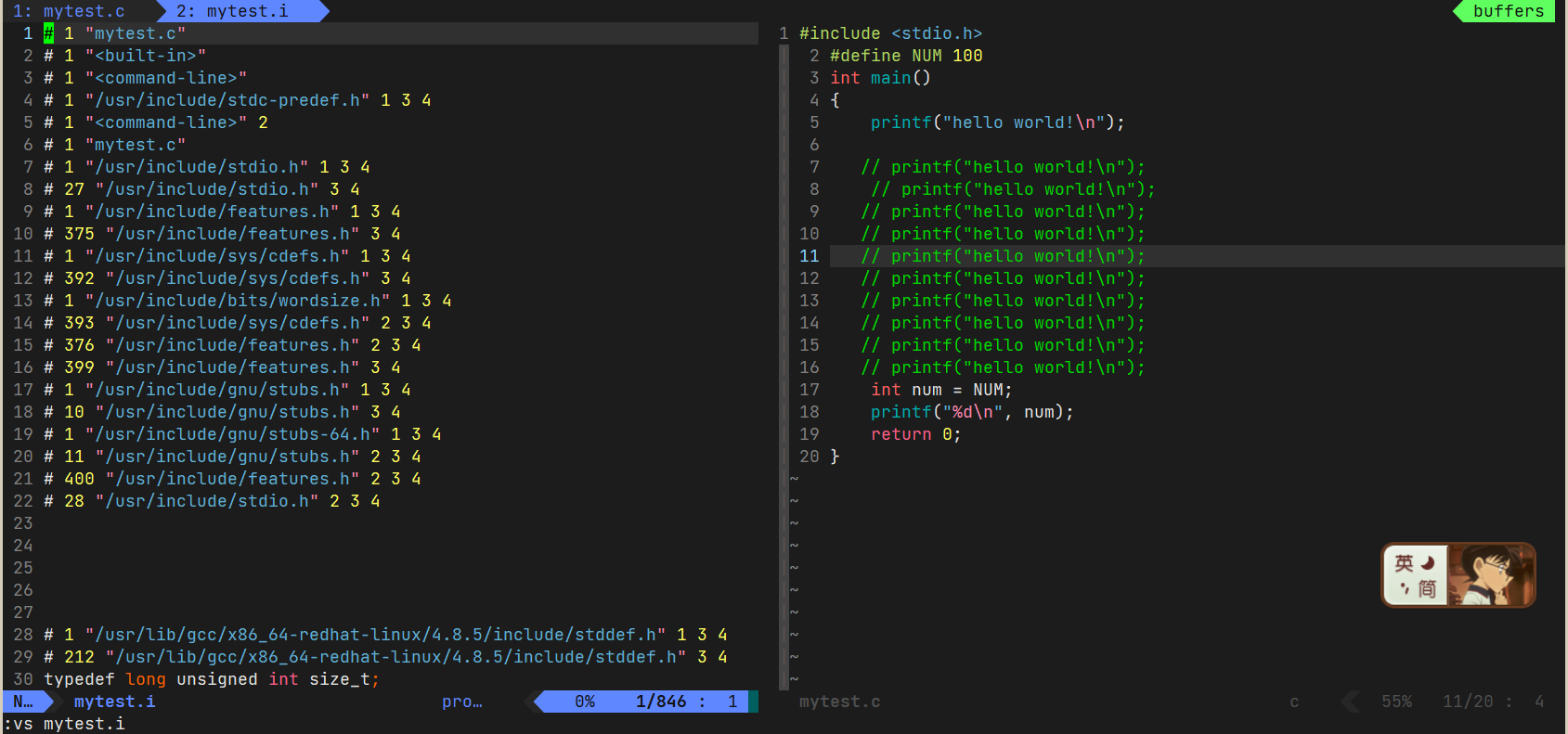
发现头文件展开了,并且完成了宏替换

预处理的行为就是把注释去掉,头文件展开,宏替换,条件编译等等。
II -S
gcc -S mytest.i -o mytest.s
// 开始执行程序编译 完成编译工作后停下把汇编语言代码存到后面的文件中
- 1
- 2
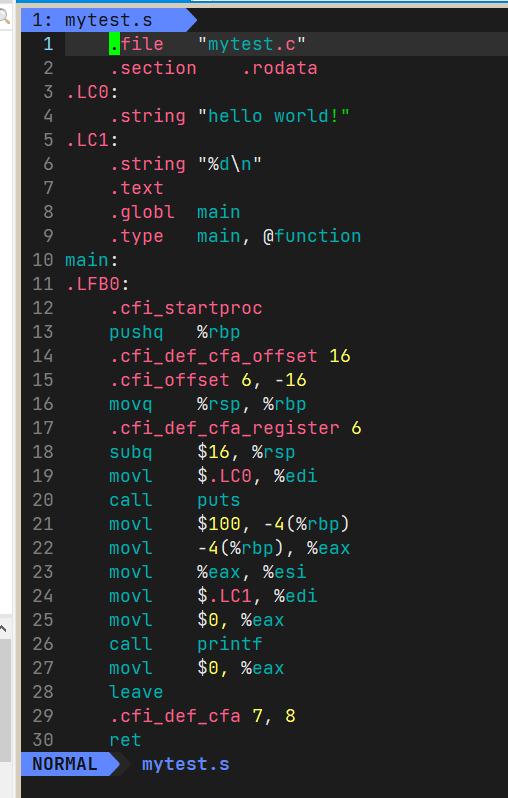
汇编语言计算机也不能直接执行,需要汇编器从汇编语言搞成二进制。
III -c

-c的含义是开始翻译工作,完成汇编过程后停下,汇编语言会变成二进制。
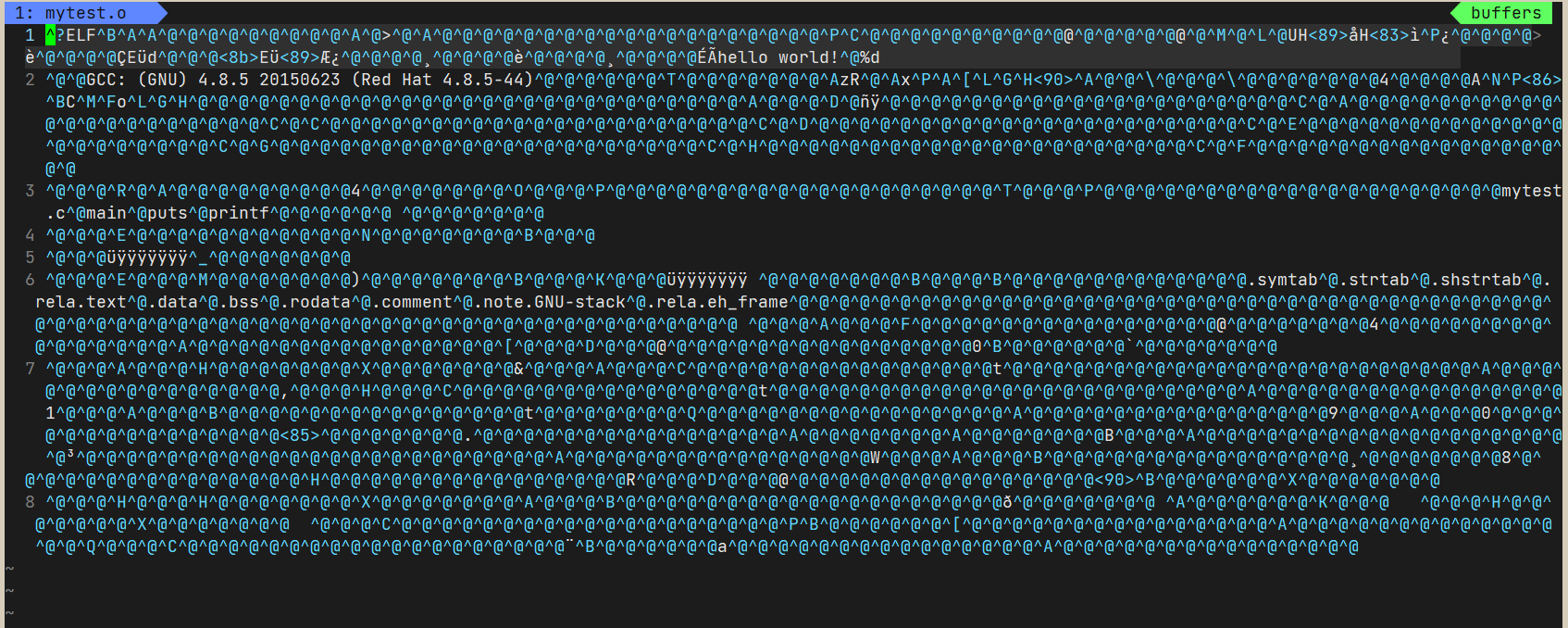
汇编形成的机器码文件不能直接执行,学术名称是可重定向二进制文件,等价于VS中的.obj文件.
下面的测试表明就算加上了可执行权限也无法执行。

这里不能执行是因为我们用到了printf函数,但是没有去链接printf具体函数实现所在的库,#include <stdio.h>中仅有函数定义,这里需要链接操作将代码中的函数调用,外部数据和库链接起来。
IV 链接
这步链接通常不需要加上任何选项,直接写gcc mytest.o -o mytest链接上库,编译器会自己帮我们找需要链接的C标准库。

V -o
如果不想一步一步的进行翻译的过程,可以gcc -o mytest mytest.c或gcc mytest.c -o mytest直接生成名为mytest的可执行文件。
记忆技巧ESc,预处理、编译、汇编,iso预处理后临时文件、编译后临时汇编代码文件、编译后临时重定向二进制文件。
VI 优化选项
-O0 -O1 -O2 -O3:编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高.
VII 为什么C语言程序的“翻译”是这个过程
最早的时候,编程的只能直接写二进制机器码,写二进制代码的过程就是“打孔编程“

由于效率太低了,因此诞生了一门称为汇编语言的语言。
汇编语言的主要主体是助记符,因为人类不太好记忆二进制符号,但是记忆助记符相对容易一些,并且同时诞生了编译器,将汇编语言编译成二进制机器码。
后来发现汇编语言开发效率还是太低了,因此贝尔实验室开发了C语言。
那么开发过程中,是直接把C语言编译成机器语言还是先编译成汇编语言呢?
显然是应该先编译成汇编语言,首先比起直接编译成机器码,编译成汇编语言相对更加简单;另外,先编译成汇编可以兼容汇编的生态。
C语言中有很多需要被提前处理而不需要汇编去处理的过程,如注释等,因此有了预处理阶段。
为什么有链接过程呢?因为链接可以使得大家同时开发然后链接到一起共同形成程序,或直接链接前人的库,可以提高开发效率。
后来有了面向对象的语言后,为了提高跨平台性,就有了很多不是上述类型的语言,语言运行在一个虚拟机软件上,跨平台性较好。
5 初识静态链接和动态链接
ldd mytest可以查看本可执行文件依赖的库。

libc.so.6去掉lib和后缀,此库的名字就是c,即C标准库。

Linux中的静态库.a,动态库.so.
总结:不管是静态库还是动态库,都和程序成功运行有关,链接的作用就是把自己写的C程序和语言或第三方提供的库关联起来。
那么什么是静态链接,什么是动态链接呢?
所谓的动态链接的含义就是程序获得链接的第三方库的位置后,然后在我们运行到对应库函数后,会直接去第三方库里找这个函数的实现,执行对应函数后再回到我们本来写的程序继续执行,这就是动态链接的直观理解。
所谓的静态链接就是直接把库中的有关代码拷贝到我们的可执行程序中,这就是一种静态链接。
所以静态链接后程序就不再需要对应的库了,因为库中的代码已经被拷贝在可执行程序中了。
gcc默认采取的链接方式是动态链接,可以通过ldd和file来看:

如果需要静态链接,需要加上-static选项。
出现了这个报错则说明云服务器未安装C标准库的静态库:

安装C标准库的静态库的方法如下:
sudo yum install glibc-static
- 1
然后就能静态链接成功了!链接成功后,发现确实大小有区别。

查看对应的静态库:

安装C++标准库的静态库的方法如下:
sudo yum -y install glibc-static libstdc++-static
- 1

发现C++的标准库大很多。
g++编译cpp,用法和gcc基本一样。
选项与gcc的选项都相同。
6 Linux上的调试器——gdb的使用
I 启动gdb
gdb 可执行文件名进入gbd,quit退出。

进入gdb后,我们加上l应该能看到什么东西才对,但是却显示没有信息被加载。
这是因为如果一个程序是可以被调试的,那么该程序的二进制文件一定加入了一些debug信息,如果不需要调试,则该程序的二进制文件就不加debug信息。
这就对应debug版本和release版本。
在Centos7中,默认生成的程序是release版本,没有调试信息,不可被调试.
如果要生成可调式的debug版本,那么就要加入-g选项。
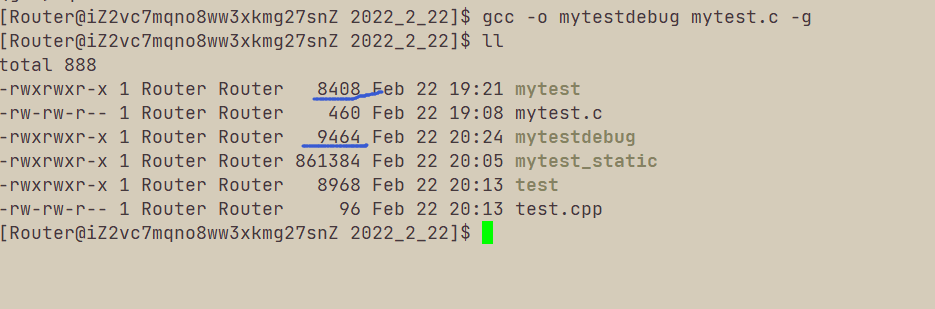
首先观察到可执行文件变大了,通过readelf -S mytestdebug | grep -i debug可以查看二进制文件中里头有关debug的行:

readelf可以查看可执行文件的段信息。
进入gdb后,直接输入run就是直接运行起来,类似vs中的ctrl + F5;
II l 行号 gdb中查看代码
我们先学习l,l + 行号,显示指定的行号后的代码,同时也会显示其周围的代码:

l 函数名:显示函数名附近的代码:

III b 行号 加断点
b 行号在对应行号打断点,这里的b也可以写为break。

b 函数名在函数入口处打断点。
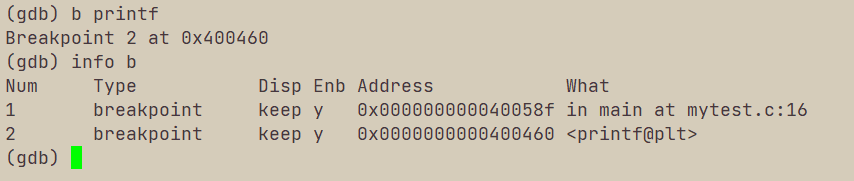
info b 或info breakpoints:查看打过的所有断点信息。

IV s(逐语句调试)和n(逐过程调试)
run:执行程序,一下子就会跑到断点那里,类似VS调试中的F5;
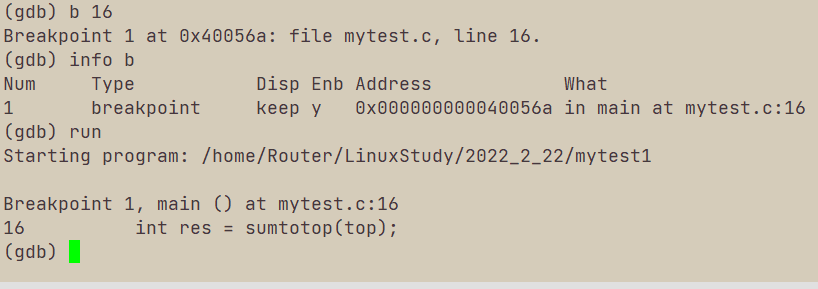
按vs的流程,接下来应该需要了解的是逐语句调试F11和逐过程调试F10.
逐语句调试:s 就是 step

逐过程调试:n 就是 next
V 监视有关
常显示变量:display 变量名
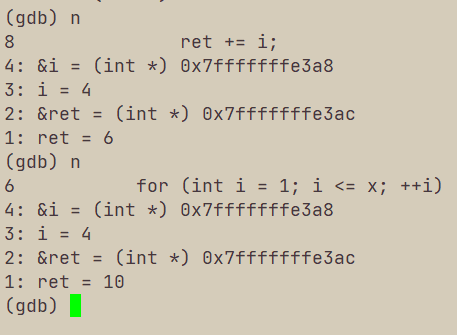
p 变量名,仅显示一次变量值,p 表达式,可以把变量的值更改。
undisplay 显示符号:去掉常显示。

VI 程序调试起来后的直接运行finish continue until
finish直接运行完当前函数。
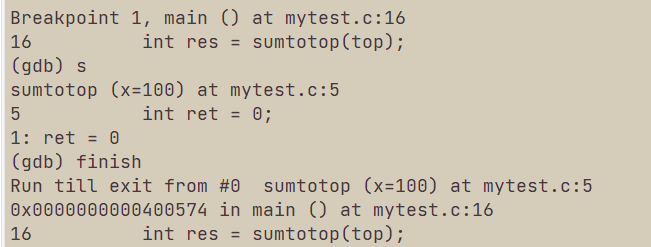
continue直接运行到下一个断点。

until 行号:直接运行到某一行。

如果一个程序出现了段错误,第一种方法是进入每个函数,然后用finish,如果没报错,那么这个函数就没错误,这样可以晒出哪个函数有错误,这个过程也可以给每个函数都打上端点,然后用continue,找到错误函数。
然后我们再用until在有错误的函数中不断找哪一行有错误即可。
VII 删除断点和使断点无效
d 断点编号:删除编号对应断点:

disable 断点编号:不删除断点但使断点失效:

enable 断点编号:启动断点。
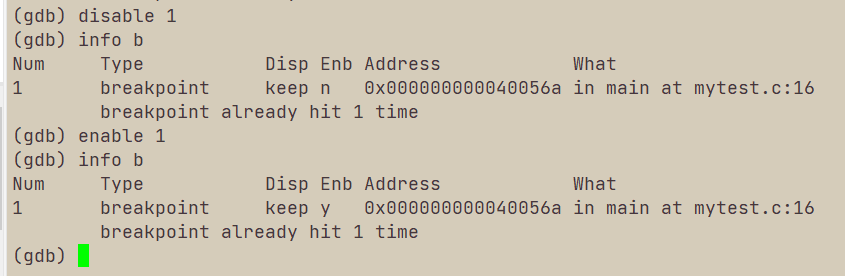
VIII 其他
bt 显示堆栈:

set var 变量名=值,设定变量值,比较少用。

print p:打印表达式p的值,这里的表达式也可以改变变量的值。

7 Linux项目自动化构建工具—make和Makefile
I 什么是make和Makefile
make是一条命令,Makefile是一个文件。
make和Makefile主要来处理文件之间的依赖关系。
在VS中我们VS会帮我们维护好文件之间的依赖关系,Linux下,我们需要写Makefile来确定文件之间的依赖关系。
Makefile中主要构建了依赖关系和依赖方法。
当项目的文件很多的时候,如果直接使用gcc编译会非常麻烦,如果我们写好Makefile文件,可以直接快速的编译。
什么叫依赖关系和依赖方法呢?给我妈打电话说:“妈,我是你儿子“,这个就是表述了一个依赖关系,你依赖于你妈妈,但是这个依赖关系并没有什么用,你妈妈并不知道你打这个电话表明依赖关系干嘛,如果说:”妈,我是你儿子,到月底了,打钱“,打钱就是一个依赖方法。
这也表明了依赖关系和依赖方法必须成对出现才有用。
II 一个简单的Makefile
mytest由mytest.c形成,所以mytest依赖于mytest.c,第一行写上mytest:mytest.c.
仅表明依赖关系是没用的,我们还得交待依赖方法:
在第二行先以tab健开头,然后加上gcc -std=c99 -o mytest mytest.c.
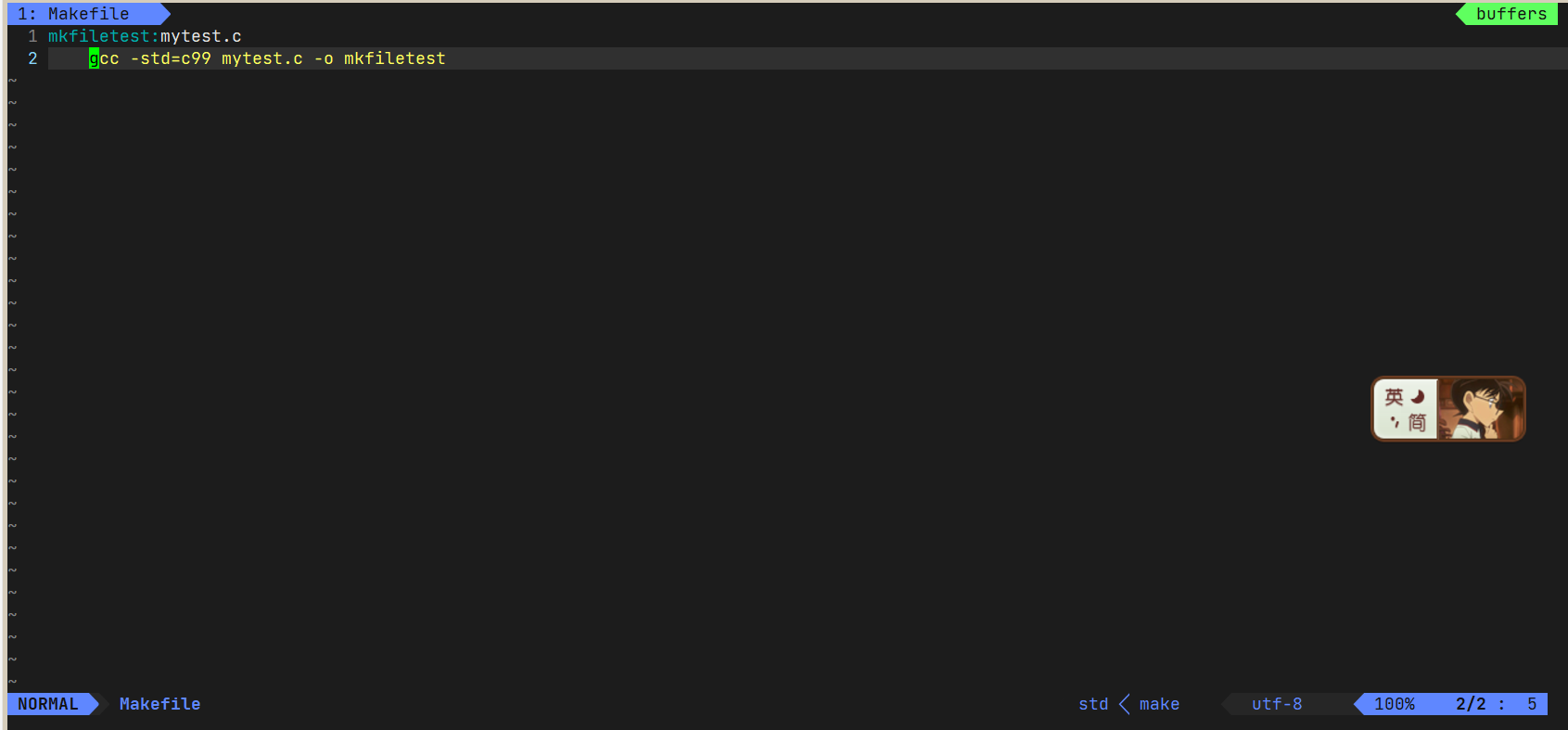
然后直接执行make命令即可,也可以make 目标名,直接make默认执行第一个目标。

make的作用就好像VS中的自动生成解决方案,因为VS把文件之间的依赖关系都已经写好了,这里Makefile要求我们自己写好文件之间的依赖关系以生成解决方案。
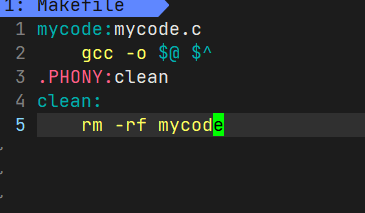
VS中还有自动清理解决方案,在Makefile中,我们利用.PHONY:符号名,它的作用是修饰符号名,使得符号名变成一个伪目标,并且可以无限执行。
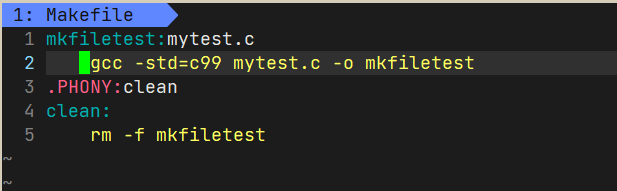
我们的普通目标,在生成后,如果检查到已经是最新的了,系统不会允许我们更新:

但是make clean却可以一直执行。

III 一个稍微复杂一点的Makefile
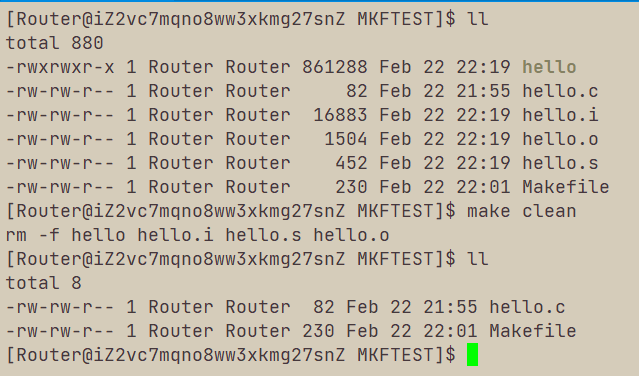
我们维护一个项目,通过一个源文件hello.c生成hello.i,通过hello.i生成hello.s,通过hello.s生成hello.o,通过hello.o生成hello可执行文件。
我们最终的目标是hello,它由hello.o生成,所以它依赖于hello.o,hello.o依赖于hello.s,hello.s依赖于hello.i,hello.i依赖于hello.c,因此,Makefile文件可以这样写:

执行make:

执行清理项目文件:
一个管理堆的oj的debug版本和release版本的代码:

IV make的特殊符号
$@和$^:$@的含义是替换为本条命令的目标,$^的含义是默认替换成本目标所依赖的文件列表。
用$@和$^显示所有编译细节:

8 Linux上的第一个小程序—进度条
I 回车和换行与缓冲区
回车和换行其实是一个分开的概念:
回车的含义是回到本行的起始位置,换行的含义是列位置不变,新起一行。
下面一个代码,先打印一个字符串,然后等待5s:
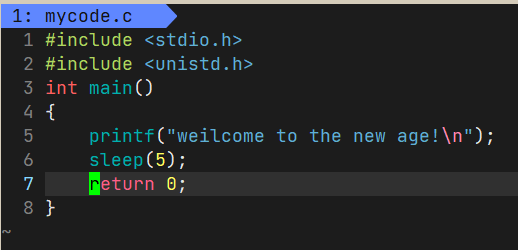

但是如果我们的字符串里头没有’\n’就会变成先等待五秒然后输出这个字符串:



我们知道根据c语言循环语句的特性,sleep一定是比printf运行晚的,也就是说printf肯定已经执行,但是数据没有立刻刷新到显示器上,所以结论就是没有’\n’,字符串会暂时保存起来,而不会直接刷新到显示器上。
这个保存起来的区域就是用户C语言级别的缓冲区,显示器设备的刷新策略就是行刷新,即缓冲区遇到\n才刷新。
那我们如果就是想直接刷新呢,我们可以用fflush接口。
C程序默认会打开三个输入输出流:stdin、stdout、stderr,分别对应标准输入(键盘)、标准输出(显示器)、错误.

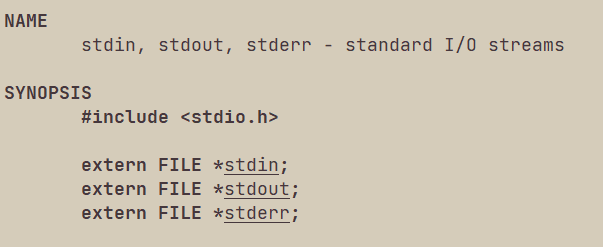
因为我们写程序的目的就是读取数据进行计算与显示,所以C程序默认打开stdin和stdout,又因为写代码很可能会写出一些错误,所以需要打开stderr,可以用perr等来把错误信息打印出来。
所以加上fflush即可直接把字符串刷新在标准输出(显示器)上:
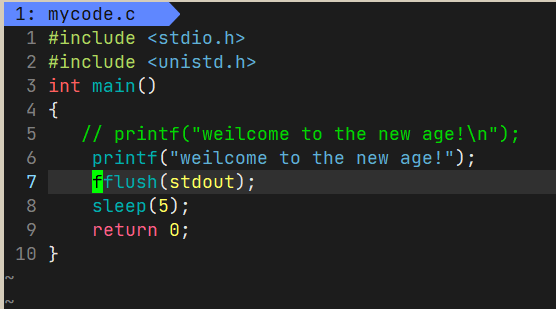

如果要对第一个位置的数不停的刷新覆盖,可以打印一个数,然后回车回到开头第一个位置而不换行,即我们不换行而只想回车,反复打印数即可,在C语言中,\r就是只回车不换行,据此,我们就实现了一个简易的倒计时:


如果想完成10到0的倒计时,由于10会占两个字符,所以我们需要给它预留空间:



II 进度条的实现
所以进度条也可以打印1个#,然后回车打印两个#,重复。。。如果想打印两个#,只要让h后一个字符也变成#,然后回车但不换行输出h即可


那如果想形成以下模样呢?

首先考虑用一个[]来装载#,但是因为右边还要有一个方块来承载数字,因为右边同时还有一个方框来承载一个数字,所以我们需要给100个#预留空间,可以用C语言中的格式化字符串中的%-100来实现,至于右边的百分比,同样可以先是用%-3d向右预留出3个空位,打印数字加%
我们还可以实现一个光标来表明当前进度条正在加载,可以利用一个组成为label = "|/-\\";的字符串(这里\是转义),然后利用i%4不断输出变化的字符。
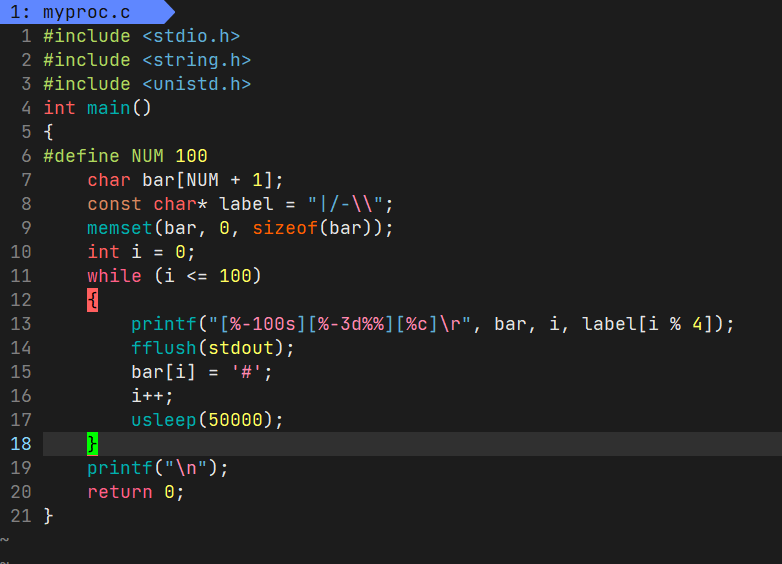

另外,我们还可以通过printf调整字体的配色方案,百度printf的配色方案即可,这里总结了xiao zhou的博客:

我们修改后的输出样式如图:

#include <stdio.h> #include <string.h> #include <unistd.h> int main() { #define NUM 100 char bar[NUM + 1]; const char* label = "|/-\\"; memset(bar, 0, sizeof(bar)); int i = 0; while (i <= 100) { printf("[\033[1;40;37m%-100s\033[0m][\033[1;44;32m%-3d%%\033[0m]\033[1;43;34m%c\033[0m\r", bar, i, label[i % 4]); fflush(stdout); bar[i] = '#'; i++; usleep(50000); } printf("\n"); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
9 命令行git的使用
I 下载git
使用git --version检查git版本,若未安装git,则sudo yum -y install git安装git。
II 在gitee创建仓库
然后在Gitee新建仓库,注意事项:设置模板最好设置上,后续的两个东西对我们学习入门级别的git使用不需要设置,分治模型也不需要设置。


创建好后修改代码仓库为开源的



III 本地git操作
克隆到本地:

记得要把提交邮箱改为公开,或者使用在这个网址中对应的加密邮箱地址。

然后一样是add commit push三板斧
git add 文件名:搞上你要提交的文件
git commit -m "提交日志":提交改动到本地,
一般git commit之前需要设置你是谁,设置方式为如下,这样设置这会使得提交信息同步到日志之中:

git push:把你的提交同步到远端服务器上,然后需要输入你的gitee账号和密码。

git log可以查看git提交的日志:


