
- 1【Linux】从零开始认识进程间通信 —— 管道
- 2树状数组(笔记)_给定一个 nn 个数的数组, mm 次操作,每次操作为下列操作之一。求最后的数组。 操
- 3安装WSL2和Ubuntu22.04版本_wsl2 ubuntu22.04
- 4[1143]Flink的Checkpoint和Savepoint_flink checkpoint和savepoint
- 5人体姿态估计在AI去衣技术中的关键作用
- 6QoS 服务质量
- 7彻底解决charles抓包https乱码的问题_charles抓包是乱码的是什么情况呀
- 8PubMedQA生物医学研究问题解答数据集(2019)下载
- 9python 读取doc 和 docx_python中解析doc文件
- 10使用MMDetection训练自己的数据集(COCO)
文本匹配(语义相似度/行为相关性)技术综述_根据语义文本相似度匹配
赞
踩
NLP 中,文本匹配技术,不像 MT、MRC、QA 等属于 end-to-end 型任务,通常以文本相似度计算、文本相关性计算的形式,在某应用系统中起核心支撑作用,比如搜索引擎、智能问答、知识检索、信息流推荐等。本篇将纵览文本匹配的技术发展,并重点介绍文本语义相似度计算技术,以及多轮对话场景中的文本语义相似度计算技术。
1、文本匹配任务
在真实场景中,如搜索引擎、智能问答、知识检索、信息流推荐等系统中的召回、排序环节,通常面临的是如下任务:
从大量存储的 doc 中,选取与用户输入 query 最匹配的那个 doc。
- 在搜索引擎中,“doc”对应索引网页的相关信息,如 title、content 等,“query”对应用户的检索请求,“最匹配”对应(点击行为)相关度最高。
- 在智能问答中,“doc”对应 FAQ 中的 question,“query”对应用户的问题,“最匹配”对应语义相似度最高。
- 在信息流推荐中,“doc”对应待推荐的 feed 流,“query”对应用户的画像,“最匹配”对应用户最感兴趣等众多度量标准。
解决这些任务,无监督和有监督学习都提供了一些具体方法,我们这里先谈论有监督学习。通常,这些任务的训练样本具有同样的结构:
共 N 组数据,每组数据结构相同:1 个 query,对应的 M 个 doc,对应的 M 个标签。
- 在搜索引擎中,query 会被表征为包含文本语义和用户信息的 embedding,doc 会被表征为包含索引网页各项信息的 embedding
- 在智能问答中,query 会被表征为以文本语义为主的 embedding,doc 同样表征为以文本语义为主的 embedding
- 在信息流推荐中,query 会被表征为包含文本特征各项信息的 embedding,doc 会被表征为包含用户历史、爱好等信息的 embedding
可见,query 和 doc 的表征形式较固定,至于具体 embedding 包含的信息根据具体任务、场景、目标变化极大,按需设计。
但至于训练样本中的标签,形式则区别甚大。可以分成下述三种形式:
- pointwise,M 通常为 1,标签形式为 0 或 1,标签 0 表示 query 与该 doc 不匹配,标签 1 表示匹配。M 也可大于 1 ,此时,一组数据中只有一个 1 其余全为 0,表示这 M 个 doc 中只有这一个与 query 匹配,其余全都不匹配。
- pairwise,M 通常为 2,标签形式为 0 或 1 ,标签 0 表示 query 与第一个 doc 比与第二个 doc 更匹配,标签 1 表示 query 与第二个 doc 比与第一个 doc 更匹配,当然也可以反之。
- listwise,M 通常大于等于 2,标签形式为 1 到 M 的正整数,标签 m 表示 query 与该 doc 的匹配度在该组里位列第 m 位。
上述三种不同监督形式,形成了不同的学习方式,彼此之间优劣异同就涉及到 Learning2Rank 技术了,具体可参考之前的博文,这里不再赘述。虽然越靠后的形式得到的模型越符合我们预期,但其对训练样本形式的严苛性和算法设计的复杂性使得工业应用难以开展,通常,解决我们遇到的任务,多采用 pointwise 或者 pairwise 方式。
再回顾下 “从大量存储的 doc 中,选取与用户输入 query 最匹配的那个 doc” 这个经典问题,doc 与 query 的具体指代的改变使之可以推广到多个具体任务中,监督信息则可以从两个维度拓展:
- 监督信号的含义,决定了 doc 与 query 匹配的准则。如在智能问答、知识检索中,doc 与 query 形式基本一致,标注时,如果根据文本语义相似度对 doc 与 query 打标签,那自然最终学习到的模型就是语义相似度模型,如果根据检索后点击行为对 doc 与 query 打标签,那自然最终学习到的模型就是行为相关性模型。
- 监督信号的标注形式,决定了其可采纳的学习形式。通常,按 listwise、pairwise、pointwise 顺序,形式可以退化,即由 listwise 形式的数据构造出 pointwise 形式的数据,也可以引入其他信息后,按逆序进行升格,即由 pointwise 形式的数据构造出 listwise 形式的数据。
这一节,我们尽量将问题泛化,将多个相关任务进行了关联。那么,下面将就具体的任务 —— 文本语义相似度计算 —— 进行介绍。
2、文本语义相似度计算
PI、SSEI、STS、IR-QA、Ad-hoc retrieval
谈起相似度计算,经常会出现几个关联的 NLP 任务,彼此存在微妙的区别:
- paraphrase identification,即 PI,是判断一文本是否另一文本的复述
- semantic text similarity,即 STS,是计算两文本在语义层面的相似性
- sentence semantic equivalent identification,即 SSEI,是判断两文本在语义层面是否一致
- IR-QA,是给定一个 query,直接从一堆 answer 中寻找最匹配的,省略了 FAQ 中 question-answer pair 的 question 中转
- Ad-hoc retrieval,属于典型的相关匹配问题
当然,如何定义“相似”也是个开放问题。
Quora 曾尝试从更实用的角度给出定义,如果多个 query 所反映的意图一致,或者说可以用同一个 answer 回答,则可以认为语义一致,即 SSEI。这也更符合 FAQ 问答系统中文本语义相似度计算的诉求。
此外,需要注意的是,虽然定义有区别,但几个任务基于神经网络提出的很多模型,是彼此通用的。许多经典模型在一个任务上被提出,评估时都会在其他几个任务的数据上跑一下。当然,一个模型迁移到其他任务时,也会进行针对性的微调,后面也会介绍到。总之,应该多关注这几个相关任务上的技术发展,借鉴引用。
常用数据集
- PI、SSEI、STS 英文:MSRP、SICK、SNLI、STS、Quora QP、MultiNLI
- PI、SSEI、STS 中文:LCQMC、BQ corpus
- IR-QA 英文:wikiQA、insuranceQA
无监督技术
不少经典的无监督 STS 技术,虽然简朴,但也能取得不错的效果:
- 基于词汇重合度:TFIDF、VSM、LD、LCS、BM25、Jaccord、SimHash 等
- 基于浅层语义的主题模型:LSA、pLSA、LDA 等
- 基于浅层语义的 encoding 模型:embedding centroid、WMD、InferSent、pretrained encoder 等
虽然无监督技术较粗糙,但能有效解决冷启动问题。如 Solr 全文检索引擎就在用基于 Ngram LD 的相似度召回技术,FAQ 问答引擎中使用 BOW+LD 也能取得不错的效果。主题模型和基于词向量的模型,本质上都是基于词共现信息的,虽然引入了词义信息,但实际使用中,并无法替代基于词汇重合度的经典算法,效果相差不大。
基于有监督的相似度计算,我们这边主要介绍基于神经网络的,基本可以分为两大类,sentence encoding (sentence representation) 类、sentence interaction 类。下面将分别介绍。
SE 网络
SE 网络结构如下:
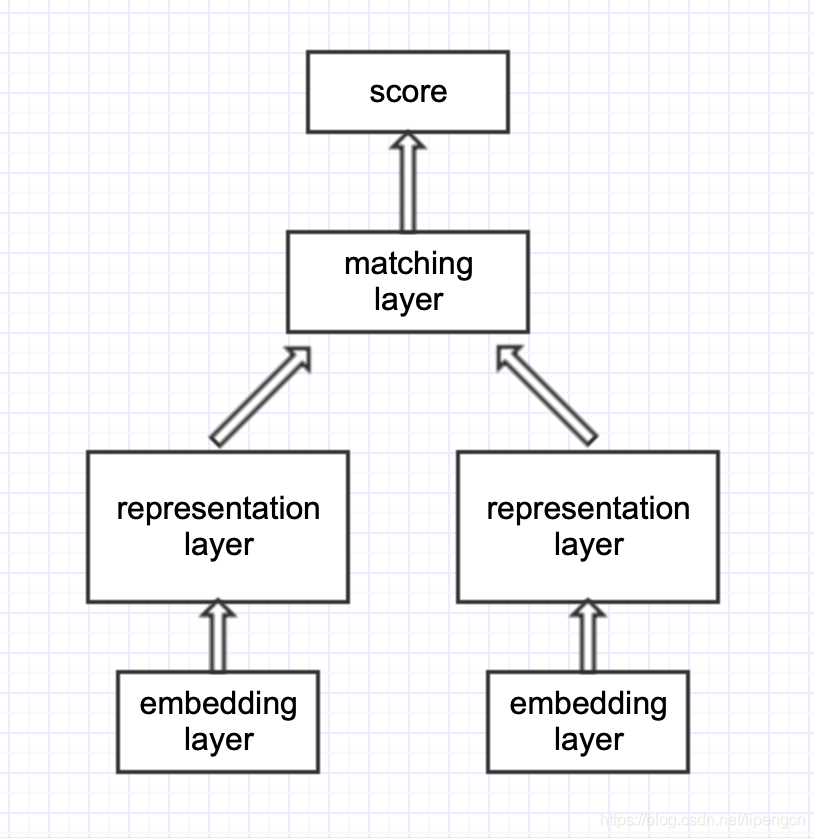
- representation-based 类模型,思路是基于 Siamese 网络,提取文本整体语义再进行匹配
- 典型的 Siamese 结构,双塔共享参数,将两文本映射到同一空间,才具有匹配意义
- 表征层进行编码,使用 MLP、CNN、RNN、Self-attention、Transformer encoder、BERT 均可
- 匹配层进行交互计算,采用点积、余弦、高斯距离、MLP、相似度矩阵均可
- 经典模型有:DSSM、CDSSM、MV-LSTM、ARC-I、CNTN、CA-RNN、MultiGranCNN 等
- 优点是可以对文本预处理,构建索引,大幅降低在线计算耗时
- 缺点是失去语义焦点,易语义漂移,难以衡量词的上下文重要性
SI 网络
SI 网络结构如下:

- interaction-based 类模型,思路是捕捉直接的匹配信号(模式),将词间的匹配信号作为灰度图,再进行后续建模抽象
- 交互层,由两文本词与词构成交互矩阵,交互运算类似于 attention,加性乘性都可以
- 表征层,负责对交互矩阵进行抽象表征,CNN、S-RNN 均可
- 经典模型有:ARC-II、MatchPyramid、Match-SRNN、K-NRM、DRMM、DeepRank、DUET、IR-Transformer、DeepMatch、ESIM、ABCNN、BIMPM 等
- 优点是更好地把握了语义焦点,能对上下文重要性进行更好的建模
- 缺点是忽视了句法、句间对照等全局性信息,无法由局部匹配信息刻画全局匹配信息
深度语义
为了更好实现语义匹配、逻辑推理,需要 model 深度信息,可以从如下角度改进上述基础 SE、SI 网络:
- 结合 SE 与 SI 网络:两者的作用并非谁是谁子集的关系,是相互补充的关系,简单加权组合即可。
- 考虑词语的多粒度语义信息:即在基础模型基础上分别对 unigram、bigram、trigram 进行建模,从而 model 文本的word、term、phrase 层面的语义信息,融合的方式不唯一,在输入层、表示层、匹配层都可以尝试,通常来说越早融合越好提升效果,因为更早发挥了多粒度间的互补性。可参考腾讯的 MIX。
- 引入词语的多层次结构信息:即引入 term weight、pos、word position、NER 等层面的 element-wise 信息到语义信息中。可参考腾讯的 MIX。
- 引入高频 bigram 和 collocation 片段:主要为了加入先验,降低学习难度。Ngram 表义更精确但也更稀疏,可借助统计度量,只挑选少量对匹配任务有很好信息量的高频共现 term 组合作为 bigram 加入词典。Collocation 即关注跨词的一些 term 组合,如借助依存分析或者频繁项集挖掘获得 collocation 片段。
- 参考 CTR 中 FM,处理业务特征:如美团的排序算法演进中,参考了 CTR 中的 wide&deep 模型来添加业务特征,即,有的业务特征不做变换直接连接到最外层,有的业务特征做非线性变化后不够充分,会再进行多项式非线性变换。
- 对两文本中的差异部分单独建模:即在基础模型基础上,再使用一个单独模型处理两文本差异部分,强化负样本的识别能力。可参考 HIT 的 GSD 模型。
- 引入混合学习策略:如迁移学习,可参考 MT-hCNN;如多任务学习;以及两者多种方式的组合,具体比较可参考 HIT 的 DFAN,如引入多任务学习和基于 Seq2Seq 的迁移学习的混合策略效果可能最好。
- 使用复杂 Learning2Rank 学习方式:详见下节。
学习形式
前面,提过可以按 pointwise、pairwise、listwise 顺序升格进行学习,在权衡标签获取难度和效果后,通常选用 DSSM 结构,即形式上的 listwise,loss 上的 pairwise 结构。
提供一种最佳实践方案:基于 DSSM 结构分别训练 SE 和 SI 网络,训练好的 SE 网络结合 faiss 作为预召回模块,训练好的 SI 网络作为匹配模块。
针对性调整
值得注意的是,前面虽然说 PI、SSEI、STS、IR-QA、Ad-hoc retrieval 等任务基于神经网络提出的很多模型是彼此通用的,但彼此借鉴时,还是有不少细节需要调整的。
IR-based QA 中提出的模型虽然也通用于相似度计算,但细节需要调整。如,Siamese 网络最后 matching layer 采用 cos 的话,对于 paraphrase 任务自然是没问题,两文本 encoding 后向量相同则得分高,但对 QA 任务则不尽然,此时 answer 未必是最优的。因此,基于 SE 结构的 QA 任务通常会加各种 attention,而 paraphrase 任务加 attention 基本没有增益。在 QA 任务上, attention 起到将 Q 中信息线性映射到 A 中信息的空间的作用,而 paraphrase 没这个必要。
语义匹配任务和相关匹配任务,很多模型也是通用的,但两个任务强调的有效信息是截然不同的,因此在基础模型上也会进行不少调整。如,需要格外关注 query 与 doc 完全匹配的 term,强调 query 中 term 的重要性,有时不必将 doc 作为整体和 query 进行匹配,等等。计算所提出了一系列相关匹配模型,如 DRMM、aNMM 等,可以参考 MatchZoo。
可见,看起来很相似的任务,也会导致很不同的解决方案,再次验证了 no-free-lunch 定理。
多轮对话场景
下面简单介绍几个经典的 IR-based 多轮对话的 QA 模型:
- 百度在 EMNLP2016 提出的 Multi-view 模型:联合考虑了 word-level matching 和 utterance-level matching,只是方式粗糙了些,均基于 SE 结构,类似于层次化结构。
- MSRA 在 ACL2017 提出的 SMN 模型:将 SE 改进到 SI, 联合考虑 word-level interaction 和 segment-level interaction。不过其 representation 过程用的两个 DRU,过于繁琐,可以参考阿里小蜜在2018的 MT-hCNN,进行了改进。
- 上交在 COLING2018 提出的 DUA 模型:采用了 Self-attention 对 utterance 进行了 deep encoding。
- 百度在 ACL2018 提出的 DAM 模型:算是最新技术的集大成者,摒弃之前建模 utterance embedding sequence 的思路,先使用 Transformer encoder 得到文本多粒度的表征,然后借助 attention 设计了两种交互方式得到了 self-attention-match 和 cross-attention-match 两种对齐矩阵,再采用 3D-conv 进行聚合分类预测,实现了 SOTA,干净利落。
核心内容就介绍到这里吧,记得之前 HIT-SCIR 的刘挺老师在梳理中文信息处理前沿技术进展时,列了 NLP 中四个主流任务,包括解析、分类、匹配和生成。可见,文本匹配任务的重要性,后续这个方向有好的进展,也会及时更新在文章里,欢迎大家讨论。

