
热门标签
热门文章
- 1Vue 登录权限配置_vue3登录游客登录和管理员登录
- 2STM32_PWM呼吸灯_stm32pwm的呼吸灯设计总结
- 3python网球比赛模拟_2019-05-12 Python之模拟体育竞赛
- 4如何理解期权的保证金和权利金的区别?
- 5python做应用程序错误_pythonw.exe应用程序错误
- 6Python+Selenium详解(超全)_selenium,python
- 7云服务器搭载zookeeper集群遇到的坑,java.net.BindExxeption和java.net.SoketTimeoutException_quorumlistenonallips=true
- 8提取数据_python pdf文件提取表格数据
- 9【联邦学习+区块链】TORR: A Lightweight Blockchain for Decentralized Federated Learning_federated learning blockchain call for paper
- 10【编程入门题--二维数组的转置】
当前位置: article > 正文
深度学习系列56:使用whisper进行语音转文字
作者:Cpp五条 | 2024-02-07 21:10:25
赞
踩
深度学习系列56:使用whisper进行语音转文字
1. openai-whisper
这应该是最快的使用方式了。安装pip install -U openai-whisper,接着安装ffmpeg,随后就可以使用了。模型清单如下:

第一种方式,使用命令行:
whisper japanese.wav --language Japanese --model medium
- 1
另一种方式,使用python调用:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3",initial_prompt='以下是普通话的句子。')
print(result["text"])
- 1
- 2
- 3
- 4
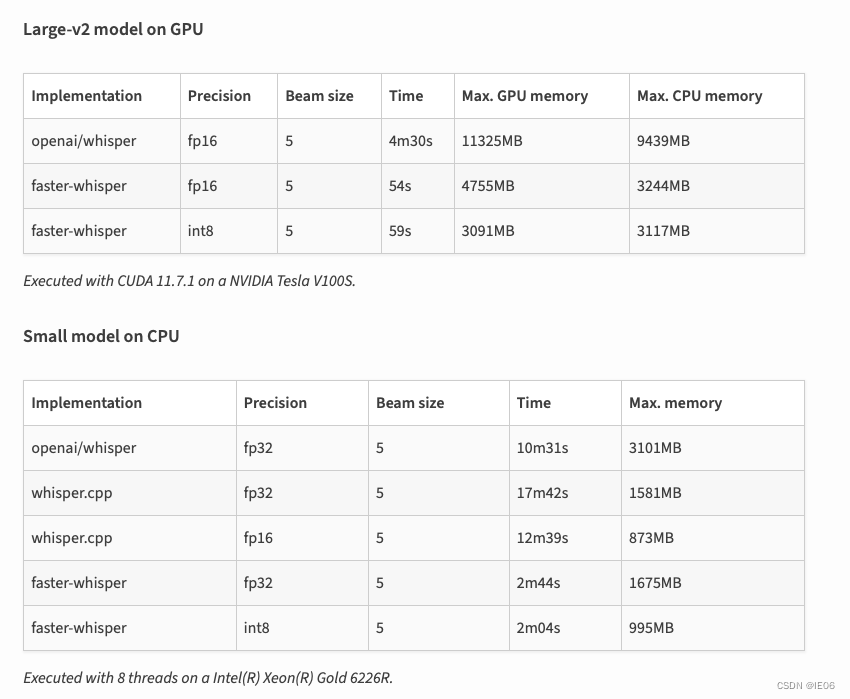
2. faster-whisper
安装也一样:pip install -U faster-whisper,速度对比:
3. whisper-jax
在GPU上的加速版本
首先安装库:
pip install jax jaxlib git+https://github.com/sanchit-gandhi/whisper-jax.git datasets soundfile librosa
调用代码为:
from whisper_jax import FlaxWhisperPipline
import jax.numpy as jnp
pipeline = FlaxWhisperPipline("openai/whisper-tiny", dtype=jnp.bfloat16, batch_size=16)
%time text = pipeline('test.mp3')
- 1
- 2
- 3
- 4
4. whisper-openvino
在intel系列的cpu上加速的版本:
安装库:pip install git+https://github.com/zhuzilin/whisper-openvino.git
调用方法:whisper carmack.mp3 --model tiny.en --beam_size 3
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/67349
推荐阅读

相关标签

