
热门标签
热门文章
- 1Java实现excel导出功能的几种方法——poi、easyExcel、easypoi、jxl_java导出excel的三种方法
- 2ChatGPT AIGC人工智能助力职场,办公人员的福音来了 WPS AI
- 3flutter vscode+第三方安卓模拟器
- 4【数据结构】排序:插入排序与希尔排序详解_数据结构输入一组数据使用直接插入算法进行排序,输出排序结果
- 5计算机科学与技术万金油专业,盘点工学大类里的“万金油”专业
- 6LSS 和 BEVDepth算法解读_bev自底向上和自顶向下
- 7深入解析 JWT(JSON Web Tokens):原理、应用场景与安全实践_jwt 适用场景
- 8mysql 数据丢失更新的解决方法
- 9python爬虫获取的网页数据为什么要加[0-python3爬虫爬取网页思路及常见问题(原创)...
- 10HBase无法启动HRegionServer_hbase没有hquorumpeer进程
当前位置: article > 正文
Hadoop3:MapReduce源码解读之Map阶段的CombineFileInputFormat切片机制(4)
作者:Cpp五条 | 2024-06-11 05:53:00
赞
踩
Hadoop3:MapReduce源码解读之Map阶段的CombineFileInputFormat切片机制(4)
Job那块的断点代码截图省略,直接进入切片逻辑
参考:Hadoop3:MapReduce源码解读之Map阶段的Job任务提交流程(1)
6、CombineFileInputFormat原理解析
类的继承关系
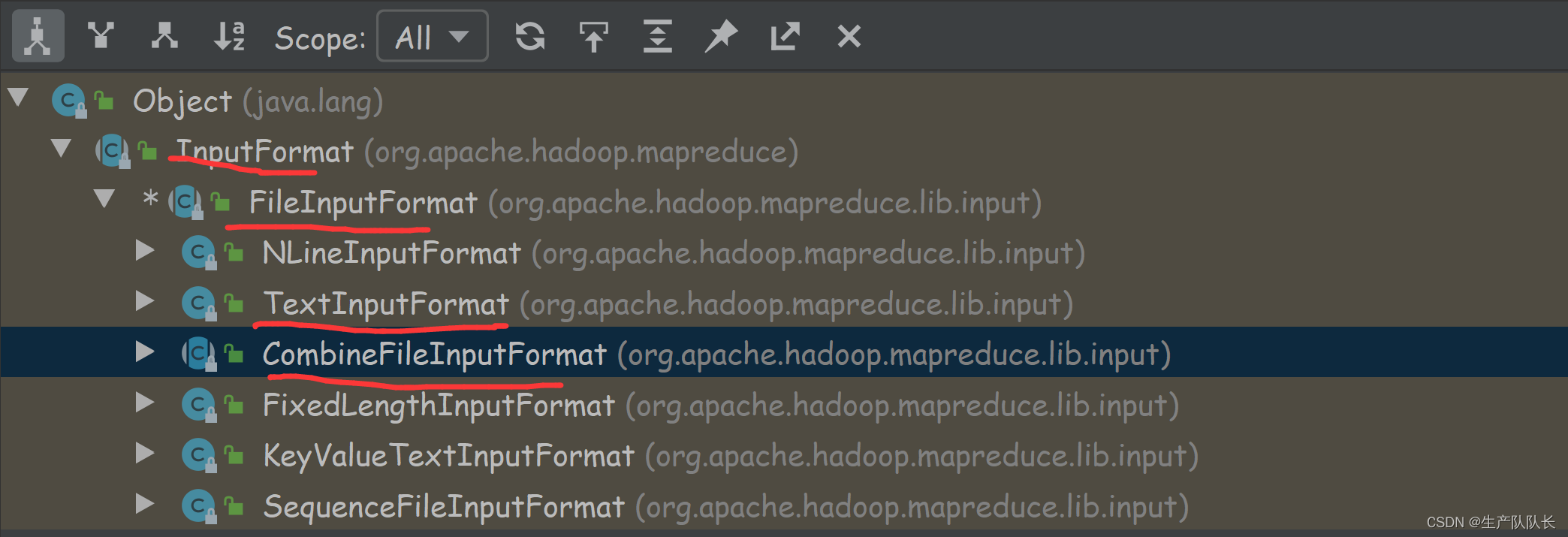
与TextInputFormat切片机制的区别
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
所以,这个切片机制是针对处理大量小文件的,效率比TextInputFormat更高。
切片过程说明
生成切片过程包括:虚拟存储过程和切片过程二部分。

注意
当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
案例
准备4个文件
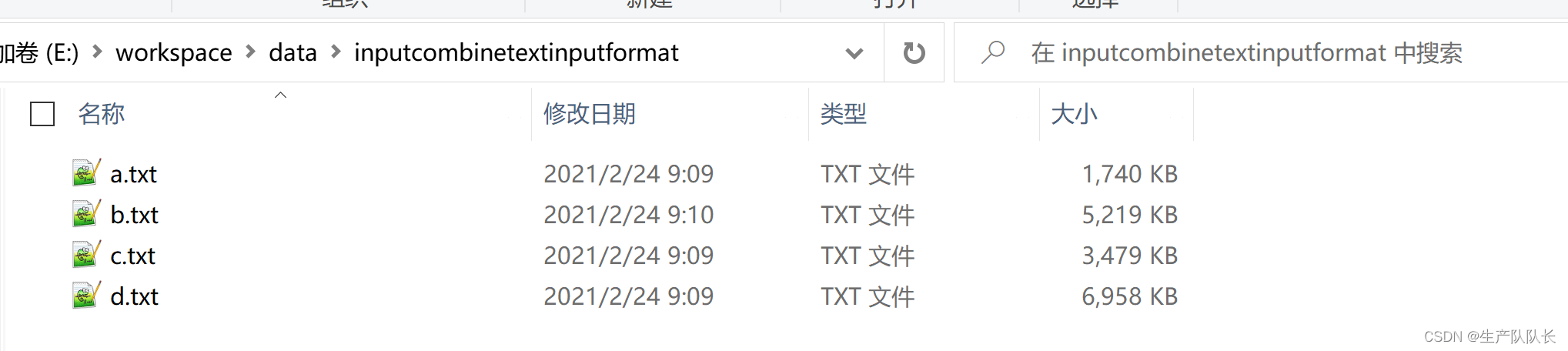
依然用wordcount案例进行演练
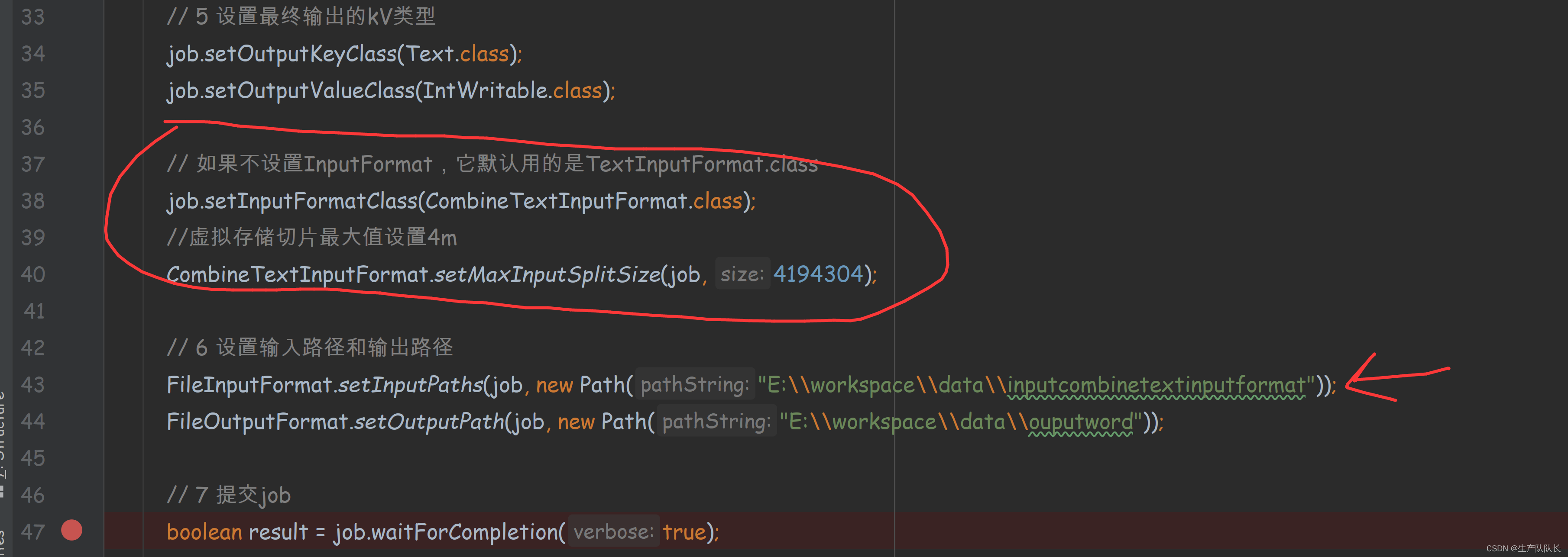
指定文件路径和切片类CombineFileInputFormat
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
- 1
- 2
- 3
- 4
查看执行日志:
number of splits:3
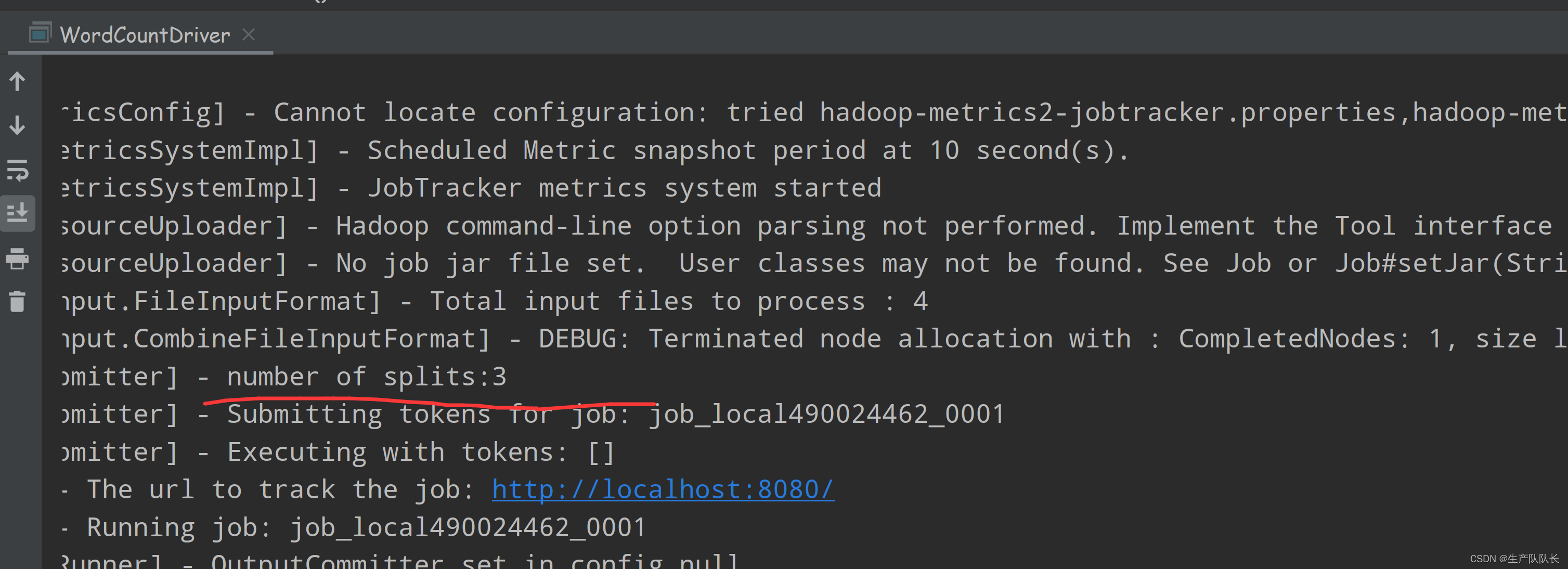
所以,对应的MapTask线程数量就是3个,Reducer线程数是1个。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/701982
推荐阅读
相关标签

