
- 1Docker在windows下使用教程,通过Dockerfile创建镜像/容器,以YOLO系列为例_怎么在windous环境下用vscode制作vue的docker镜像
- 2MySQL高可用解决方案演进:从主从复制到InnoDB Cluster架构
- 3MVC模式
- 4推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
- 5BERT实践详解_bert_base_chinese
- 6docker基本使用_部署docker的硬件环境要求
- 7KALI--入门教程--kali下载(vm),更新国内源,更换中文界面_kali环境下载
- 8【GPT】如何拥有离线版本的GPT以及部署过程中的问题_离线部署gpt3
- 9jquery重写自定义鼠标右键弹出菜单列表_icon fa-plus
- 10linux下部署php页面
Python(下)_python 在类可变数量属性
赞
踩
函数
函数的定义与调用
函数就是执行特定任务以完成特定功能的一段代码
为什么需要函数:复用代码;隐藏实现细节;提高可维护性;提高可读性便于调试
函数的创建
def 函数名([形式参数]):
函数体
[return 返回值]
- 1
- 2
- 3
函数的调用
函数名([实际参数])
- 1
函数的参数传递
函数调用的参数传递
1、位置实参:根据形参对应的位置进行实参传递
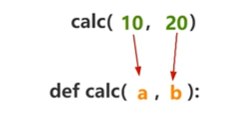
2、关键字实参:根据形参名称进行实参传递

函数参数传递的内存分析
在函数调用过程中,进行参数的传递
如果是不可变对象,在函数体的修改不会影响实参的值
如果是可变对象,在函数体的修改会影响到实参的值
函数的返回值
1、如果函数没有返回值【函数执行完毕之后,不需要给调用处提供数据】,return可以省略不写
2、函数的返回值如果是1个,直接返回原类型
3、函数返回多个值时,结果为元组
函数参数定义
默认值参数
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参
个数可变的位置参数
定义函数时,可能无法事先确定传递的位置实参个数时,使用可变的位置参数
使用*定义个数可变的位置形参
结果为一个元组
只能是一个可变的位置参数
个数可变的关键字形参
定义函数时,无法实现确定传递的关键字实参的个数时,使用可变的关键字形参
使用**定义个数可变的关键字形参
结果为一个字典
只能是一个可变的关键字参数
在一个函数定义过程中,既有个数可变的关键字形参,也有个数可变的位置形参时,要求个数可变的位置形参放在个数可变的关键字形参之前
函数的参数总结
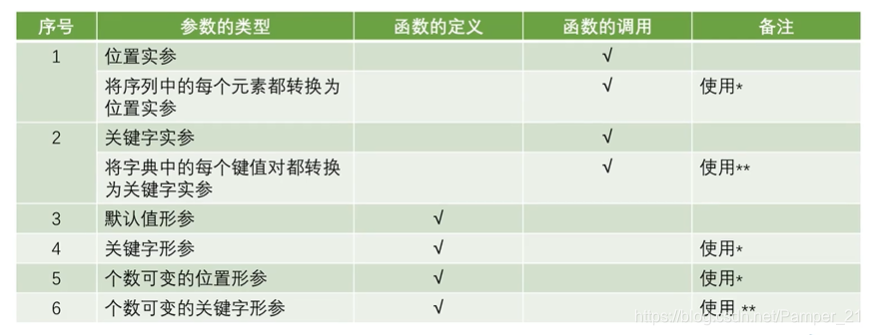
def fun(a,b,*,c,d)#从*之后的参数,在函数调用时,只能采用关键字参数传递
- 1
变量的作用域
程序代码能访问该变量的区域
根据变量的有效范围可分为:
1、局部变量:在函数内定义并使用的变量,只在函数内部有效,局部变量使用global声明,这个变量就会变成全局变量
2、全局变量:函数体外定义的变量,可作用于函数内外
递归函数
递归函数:如果在一个函数的函数体内调用了该函数本身,这个函数就称为递归函数
组成部分:递归调用与递归终止条件
调用过程:每递归调用一次函数,都会在栈内存分配一个栈帧,每执行完一次函数,都会释放相应的空间
优缺点:占用内存多,效率低下;思路和代码简单
雯波纳契数列
def fun(n):
if n==1:
return 1
elif n==2
return 1
else:
return fun(n-1)+fun(n-2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Bug
bug的由来
bug的常见类型
1、粗心导致的语法错误:SyntaxError
漏了末尾的冒号
缩进错误
把英文符号写成中文符号
字符串拼接时,将字符串和数字拼在一起
没有定义变量
比较运算符与赋值运算符混用
2、知识点不熟练导致的错误
(1)索引越界问题IndexError
(2)append()方法的使用不熟练
3、思路不清
(1)使用print()函数
(2)使用#暂时注释部分代码
4、被动掉坑:程序代码逻辑没有错,只是因为用户错误操作或者一些“例外情况”而导致的程序崩溃
Python提供了异常处理机制,可以在异常出现时及时捕获,然后内部“消化”,让程序继续执行
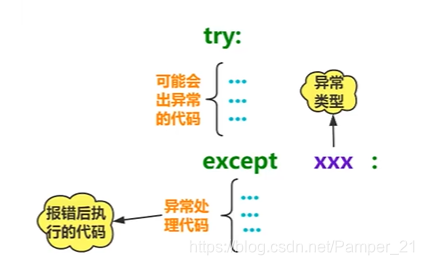
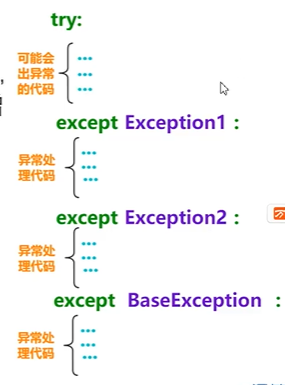
多个except结构
捕获异常的顺序按照先子类后父类的顺序,为了避免遗漏可能出现的异常,可以在最后增加BaseException
try…except…else结构
如果try块中没有抛出异常,则执行else块,如果try中抛出异常,except块
try…except…else…finally结构
finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源

Python中常见的异常类型
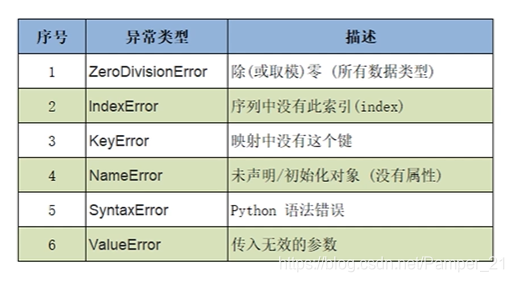
traceback模块
使用traceback模块打印异常信息
import traceback
try:
print(1.-------------)
num=10/0
except:
traceback.print_exc()
- 1
- 2
- 3
- 4
- 5
- 6
PyCharm开发环境调试
断点
程序运行到此处,暂时挂起,停止执行。此时可以详细观察程序的运行情况,方便做出进一步判断
进入调试视图
方式:
(1)单价工具栏上的按钮
(2)右键单击编辑区:点击:debug‘模块名’
(3)快捷键:shift+F9
面向对象编程
类与对象
类
类是过个类似事物组成的群体的统称。能够帮助我们快速理解和判断事物的性质
数据类型
不同的数据类型属于不同的类;使用内置函数查看数据类型
对象
Python中一切皆对象
类的创建
类名单词的首字母大写,其余小写
类之外定义的叫函数,类之内定义的叫方法
class 类名:
类属性
实例方法#有self
静态方法#用@staticmethod定义,不允许有self
类方法#用@classmethod定义,有cls
def __init__(self,变量):
self.变量=value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对象的创建
对象的创建称为类的实例化
实例名=类名()
- 1
对象名.方法名()
类名.方法名(类的对象)
- 1
- 2
类属性、类方法、静态方法
类属性:类中方法外的变量称为类属性,被该类的所有对象共享
类方法:使用@classmethod修饰的方法,使用类名直接方法的方法
静态方法:使用@staticmethod修饰的方法,使用类名直接方法的方法
动态绑定属性和方法
Python是动态语言,在创建对象之后,可以动态的绑定属性和方法
class Student(): def __init__(self,name,age): self.name=name self.age=age def eat(self): print(self.name+'在吃饭') def show(): print('展示...') stu2=Student('李四',20) stu1=Student('张三',19) print(stu1.name,stu1.age) print(stu2.name,stu2.age) stu1.sex='男'#动态绑定属性 print(stu1.name,stu1.age,stu1.sex) print(stu2.name,stu2.age,stu2.sex)#报错,stu2没有性别属性 stu1.eat() stu2.eat() stu1.show=show#动态绑定方法 stu1.show() stu2.show()#报错,stu2没有show方法

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
面向对象的三大特征
封装:提供程序的安全性
继承:提高代码的复用性
多态:提高程序的可扩展性和可维护性
封装及其实现
将数据(属性)和行为(方法)包装到类对象中。在方法内部对属性进行操作,在类对象的外部调用方法。
在Python内没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被方法,前边使用两个‘_’
== 在类外部可以通过__类名__属性名进行私有对象的访问==
class Student:
def __init__(self,name,age):
self.name=name
self.__age=age
def show(self):
print(self.name,self.__age)
stu=Student("张三",19)
stu.show()
print(stu.name)
print(stu.__age)#报错
print(dir(stu))
print(stu._Student__age)#在类外部可以通过_类名__属性名进行私有对象的访问
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
继承及其实现
class 子类类名(父类1,父类2……):
pass
- 1
- 2
如果一个类没有继承任何类,则默认继承object
Python支持多继承
定义子类时,必须在其构造函数中调用父类的构造函数
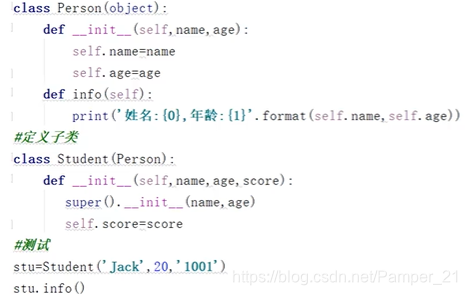
方法重写
如果子类对继承自父类的某个属性或方法不满意,可以在子类中对其进行重新编写
子类重写后的方法可以通过super().xxx()调用父类中被重写的方法
object类
object类是所有类的父类,因此所有类都有object类的属性和方法
内置函数dir()可以查看指定对象所有属性
object有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象信息,所以我们经常对__str__()进行重写
多态及其实现
多态就是“具有多种形态”,指的是:即便不知道一个变量所引用的对象到底是什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型,动态决定调用哪个对象中的方法
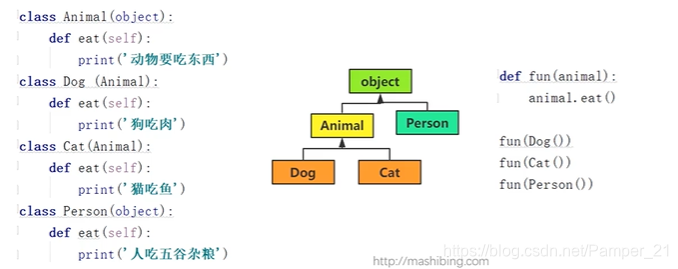
静态语言与动态语言
关于多态的区别:
静态语言实现多态的三个必要条件:
继承
方法重写
父类引用指向子类对象
动态语言的多态崇尚“鸭子类型”,当看到一只鸟走起来像鸭子、游泳起来像鸭子、收起来也像鸭子,那么这只鸟就可以被称为鸭子。在鸭子类型中,不需要关心对象是什么类型,到底是不是鸭子,只关心对象的行为
特殊属性和特殊方法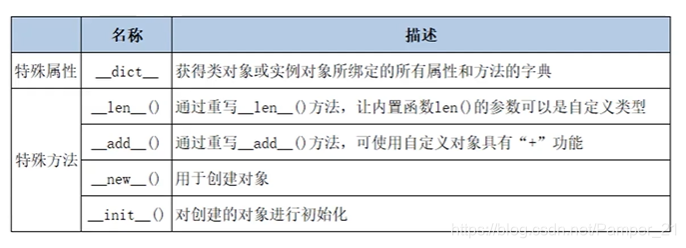
| 名称 | 描述 |
|---|---|
| class | 输出对象所属的类 |
| bases | 输出父类的元组 |
| base | — |
| mro | 输出类的层次结构 |
| subclasses() | 输出子类的列表 |
class Person(object):
def __init__(self,name,age):
print('__init__被调用了',self的id值为:{0}.format(id(self)))
self.name=name
self.age=age
def __new__(cls,*args,**kwargs):
print('__new__被调用执行了,cls的id值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为:{0}'.format(id(obj)))
return obj
print('object这个类对象的id为:{0}'.format(id(object)))
print('Person这个类对象的id为:{0}'.format(id(Person)))
p1=Person('张三',20)
print('p1这个Person类的实例对象的id:{0}'.format(id(p1)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
类的浅拷贝与深拷贝
变量的赋值:只是形成两个变量,实际上还是指向同一个对象
浅拷贝:Python拷贝一般是浅拷贝,使用copy模块的copy函数,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
深拷贝:使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
模块
什么叫模块
一个模块中可以包含N多个函数
在Python中一个扩展名为.py的文件就是一个模块
使用模块的好处:方便其他程序和脚本的导入并使用;避免函数名和变量名冲突;提高代码的可维护性和可重用性
模块的导入
创建模块:新建一个.py文件,名称尽量不要与Python自带的标准模块名称相同
导入模块:
import 模块名称[as 别名]
from 模块名称 import 函数/变量/类
- 1
- 2
以主程序形式运行
在每个模块的定义中都包括一个记录模块名称的变量__name__,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其他程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name__变量的值为__main__
if __name__='__main__':
pass
- 1
- 2
包
Python中的包
包是一个分层次的目录结构,他将一组功能相近的模块组织在一个目录下
作用:代码规范;避免模块名称冲突
包与目录的区别:包含__init__.py文件的目录称为包;目录里通常不包含__init__.py文件
包的导入
import 包名.模块名
- 1
使用import方式进行导入时,只能跟包名或模块名
使用form…import方式进行导入时,可以导入包/模块/函数/变量等
Python中常用的内置模块
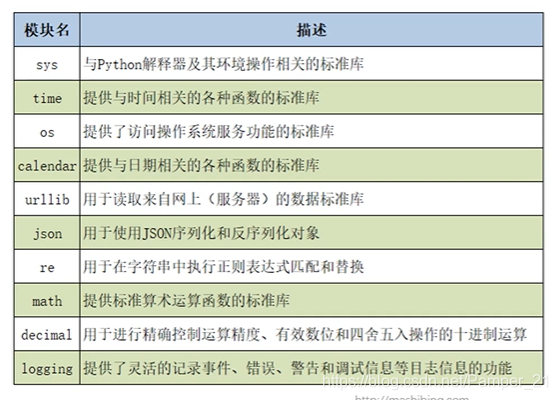
第三方模块的安装及使用
pip install 模块名#安装
import 模块名#使用
- 1
- 2
import schedule
import time
def job():
print('哈哈-----')
schedule.every(3).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
文件
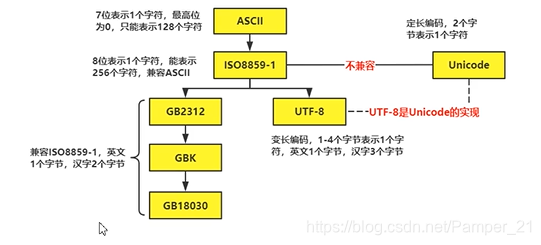
编码格式介绍
常见的字符编码格式
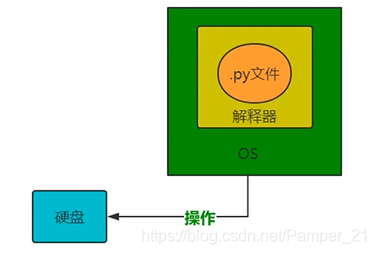
Python的解释器使用的是Unicode(内存)
.py文件在磁盘上使用UTF-8存储(外存)
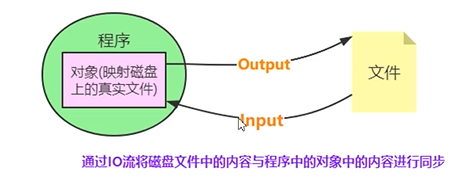
文件的读写原理
文件的读写俗称“IO操作”
文件读写操作流程:
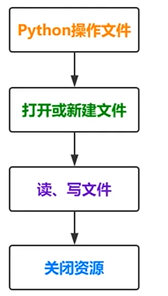
操作原理:
文件的读写操作
内置函数open()创建文件对象
file=open(filename [,mode,encoding])
- 1

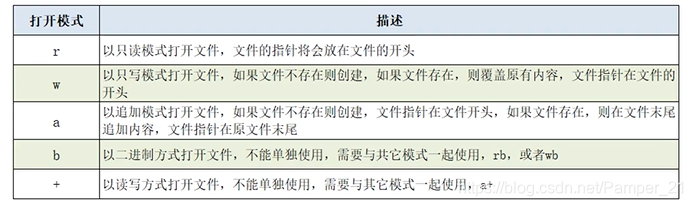
常用的文件打开模式
文件的类型
按文件中数据的组织形式,文件分为以下两大类:
1、文本文件:存储的是普通“字符”文本,默认为unicode字符集,可以使用记事本程序打开
2、二进制文件:把数据内容用“字节”进行存储,无法用记事本打开,必须使用专用的软件打开
文件对象的常用方法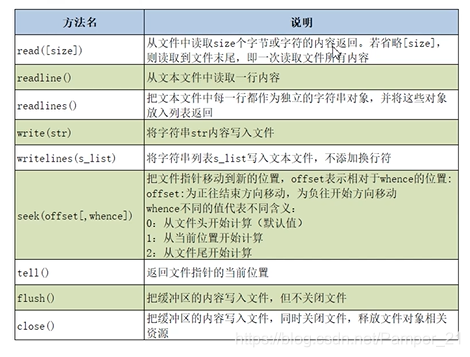
with语句(上下文管理器)
with语句可以自动管理上下文资源,不论什么原因跳出with块,都能确保文件正确的关闭,以此来达到释放资源的目的
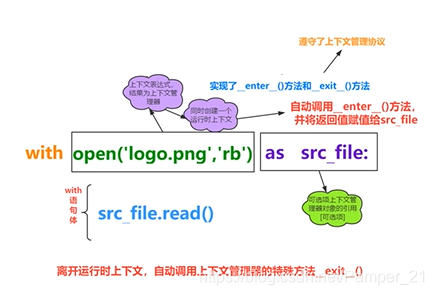
类实现了特殊方法__enter__(),exit()称为该类对象遵守了上下文管理器协议
该类对象的示例对象,称为上下文管理器
目录操作
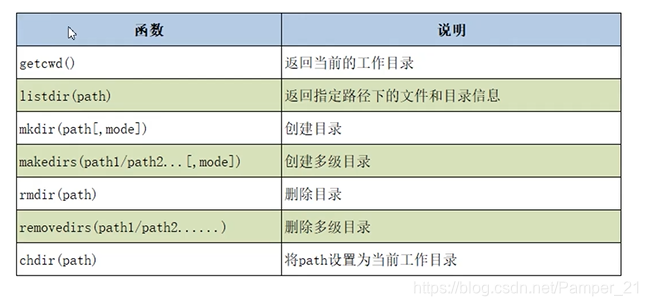
OS模块的常用函数
OS模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样
OS模块与os.path模块用于对目录或文件进行操作
import os
os.system('notepad.exe')#打开记事本
os.system('calc.exe')#打开计算器
- 1
- 2
- 3
os模块操作目录相关函数
import os
path=os.getcwd()
lst_files=os.walk(path)
for dirpath,dirname,filename in lst_files:
'''print(dirpath)
print(dirname)
print(filename)
print('----------------')
'''
for dir in dirname:
print(os.path.join(dirpath,dir))
print('-----------------------')
for file in filename:
print(os.path.join(dirpath,file))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
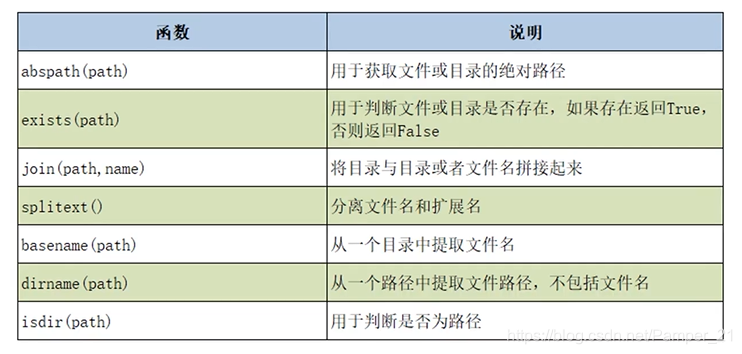
os.path模块操作目录相关函数
本文章内容为观看哔哩哔哩视频所记笔记:https://www.bilibili.com/video/BV1wD4y1o7AS

