
- 1Qt|Linux工作笔记-第二种方式读取Linux中top命令(直接读取,非重定向)_8622qt top
- 2win10中如何让python服务开机自启动_win10 python服务开机重启
- 3THE、QS等四大世界大学排名对比 计算机专业究竟哪家强?_佐治亚理工和苏黎世联邦理工比较
- 4大数据开发之离线数仓项目(用户行为采集平台)(可面试使用)
- 5使用translateZ(0)提升性能的原理是什么?
- 6运行时的用法积累_[self willchangevalueforkey:@"mj_header"]; // kvo
- 7Docker 容器编排之 --- docker-compose 详解_docker-compose.yml 用#号注释吗
- 8Object.assign 用法总结_object.assign拷贝数组
- 9开源与闭源:大模型时代的技术交融与商业平衡_大模型开源与闭源并存
- 10Spring3新特性:Graalvm打包Springboot+Mybatis;Graalvm打包成Docker
72.全卷积神经网络(FCN)及代码实现_fcn和cnn的网络结构代码
赞
踩
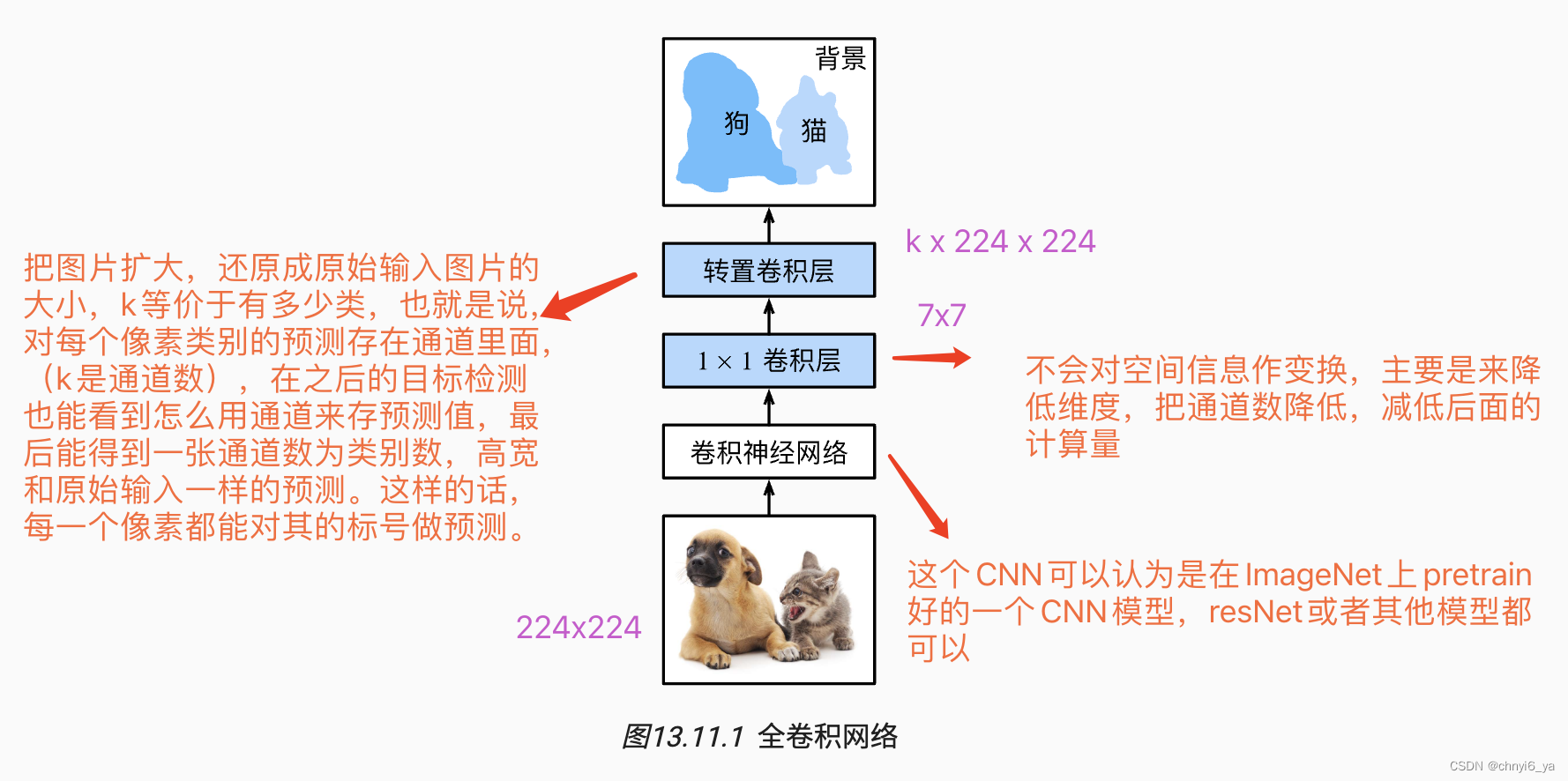
语义分割是对图像中的每个像素分类。 全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换 。 与我们之前在图像分类或目标检测部分介绍的卷积神经网络不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过在 转置卷积(transposed convolution)实现的。 因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。
- FCN是用深度神经网络来做语义分割的奠基性工作
- 它用转置卷积层替换CNN最后的全连接层,从而可以实现每个像素的预测
1. 构造模型
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
- 1
- 2
- 3
- 4
- 5
- 6
全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1×1 卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。 因此,模型输出与输入图像的高和宽相同,且最终输出通道包含了该空间位置像素的类别预测。
下面,使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征,并将该网络记为pretrained_net。 ResNet-18模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
pretrained_net = torchvision.models.resnet18(pretrained=True)
# 列出最后3层
list(pretrained_net.children())[-3:]
- 1
- 2
- 3
运行结果:
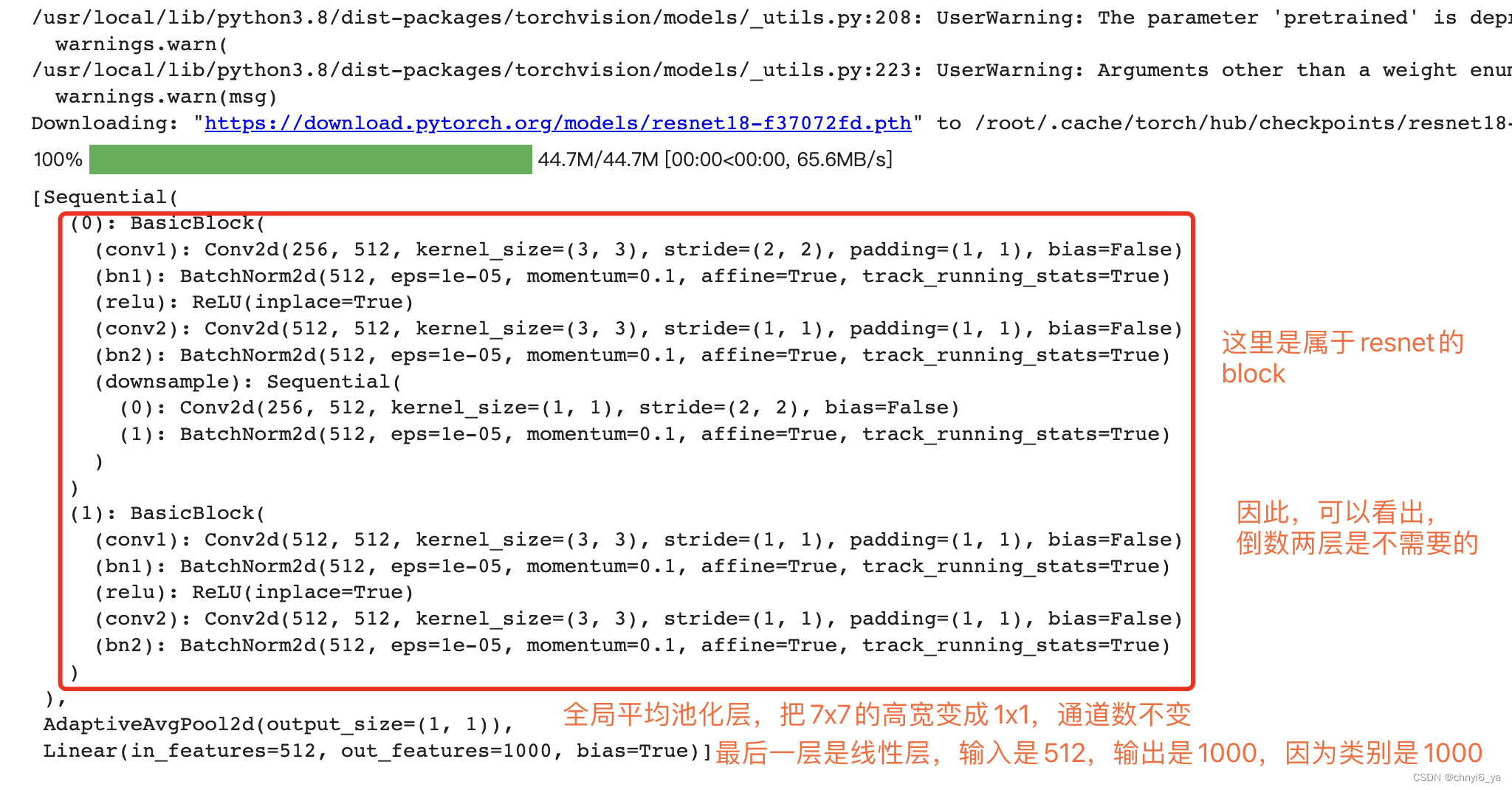
接下来,我们创建一个全卷积网络net。 它复制了ResNet-18中大部分的预训练层,除了最后的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
- 1
给定高度为320和宽度为480的输入,net的前向传播将输入的高和宽减小至原来的 1/32 ,即10和15,通道数从3变成512.
# 在语义分割中,输入图片是320 x 480的图片,因为是像素级别的,所以图片相对来说比较大
# 和ImageNet是不同的,在ImageNet中是224 x 224
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
- 1
- 2
- 3
- 4
运行结果:

ps:卷积神经网络最好的地方就是:不管输入图片的高宽如何都能进行计算,不像全连接,全连接一旦定了,输入的大小是不能变的,卷积没关系,因为要进行学习的权重kernel(卷积核)和输入大小无关,是和卷积层的定义是相关的
接下来使用 1×1 卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。最后需要(将特征图的高度和宽度增加32倍),从而将其变回输入图像的高和宽。
回想一下 卷积层输出形状的计算方法: 由于 (320−64+16×2+32)/32=10 且 (480−64+16×2+32)/32=15 ,我们构造一个步幅为 32 的转置卷积层,并将卷积核的高和宽设为 64 ,填充为 16 。 我们可以看到如果步幅为
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

