
- 1学习腾讯的NLP文本分类_nlp的roi
- 2【LeetCode之MySQL】175. Combine Two Tables_mysql 175. combine two tables
- 3JMeter 接口自动化测试的最佳实践
- 4Python酷库之旅-比翼双飞情侣库(04)
- 5二、Crazepony1无人机源码分析-(5)50Hz循环_无人机源代码
- 6android的危险权限(dangerous)授权_android 危险权限
- 7智能算法挑战赛小学组全年级——模拟考试_全国青少年信息素养大赛智能算法应用挑战赛初赛试题
- 8如何开发一个车牌识别,车牌识别系统,车辆识别系统毕业设计毕设作品_车牌识别系统开发
- 9搭建Hadoop报错汇总(那些曾经踩过的坑)_hdfs namenode -format bash: hdfs: command not foun
- 10Image recognition&NLP_图像分割置信度
代码世界中的Lambda
赞
踩
“ λ ”像一个双手插兜儿,独自行走的人,有“失意、无奈、孤独”的感觉。λ 读作Lambda,是物理上的波长符号,放射学的衰变常数,线性代数中的特征值……在程序和代码的世界里,它代表了函数表达式,系统架构,以及云计算架构。
代码中的Lambda
Lambda表达式基于数学中的λ演算得名,可以看作是匿名函数,可以代替表达式,函数,闭包等,也支持类型推论,可以远离匿名内部类。
为什么使用Lambda呢?
1)代码更紧凑
2)拥有函数式编程中修改方法的能力
3)有利于多核计算
Lambda的目的是让程序员能够对程序行为进行抽象,把代码行为看作数据。
Java
Java 8的一个大亮点是引入Lambda表达式,在编写Lambda表达式时,也会随之被编译成一个函数式接口。
一个典型的例子是文件类型过滤 :
File dir = new File("/an/dir/");
FileFilter directoryFilter = new FileFilter() {
public boolean accept(File file) {
return file.isDirectory();
}
};- 1
- 2
- 3
- 4
- 5
- 6
用lambda 重写后:
File dir = new File("/an/dir/");
File[] dirs = dir.listFiles((File f) -> f.isDirectory());
- 1
- 2
- 3
- 4
Lambda 表达式本身没有类型,因为常规类型系统没有“Lambda 表达式”这一内部概念。
Python
与其它语言不同,Python的Lambda表达式的函数体只能有唯一的一条语句,也就是返回值表达式语句。Python编程语言使用lambda来创建匿名函数。
一个典型的例子是求一个列表中所有元素的平方。
一般写法
def sq(x):
return x * x
map(sq, [y for y in range(108)])- 1
- 2
- 3
- 4
- 5
使用Lambda 的写法
map( lambda x: x*x, [y for y in range(108)] )
- 1
- 2
在spark 中,用python 操作RDD时,Lambda 更是随处可见。
out_rdd = in_rdd.filter( # filter the empty record
lambda x:x[1] is not None and x[1] != {}
).map(
lambda x:utils.parse_data(x[1],es_relations)
).filter( # filter the empty record
lambda x:x is not None
).filter( # filter the record
lambda x:x[u'timestamp']>time_start)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
大数据架构中的Lambda
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
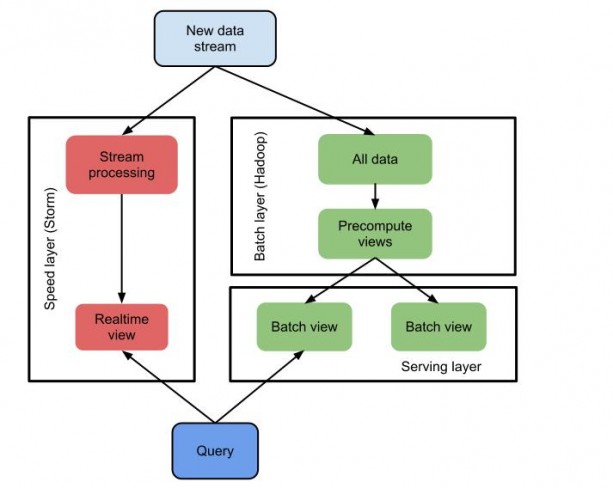
Batch Layer进行预运算的作用实际上就是将大数据变小,从而有效地利用资源,改善实时查询的性能。主要功能是:
- 存储Master Dataset,这是一个不变的持续增长的数据集
- 针对这个Master Dataset进行预运算
Serving Layer就要负责对batch view进行操作,从而为最终的实时查询提供支撑。主要作用是:
- 对batch view的随机访问
- 更新batch view
speed layer与batch layer非常相似,它们之间最大的区别是前者只处理最近的数据,后者则要处理所有的数据。另一个区别是为了满足最小的延迟,speed layer并不会在同一时间读取所有的新数据,在接收到新数据时,更新realtime view,而不会像batch layer那样重新运算整个view。speed layer是一种增量的计算,而非重新运算(recomputation)。Speed Layer的作用包括:
- 对更新到serving layer带来的高延迟的一种补充
- 快速、增量的算法
- 最终Batch Layer会覆盖speed layer
大数据系统一般具有如下属性:
* 健壮性和容错性(Robustness和Fault Tolerance)
* 低延迟的读与更新(Low Latency reads and updates)
* 可伸缩性(Scalability)
* 通用性(Generalization)
* 可扩展性(Extensibility)
* 内置查询(Ad hoc queries)
* 维护最小(Minimal maintenance)
* 可调试性(Debuggability)
个人觉得,有了spark streaming 之后,spark 本身就是一种Lambda架构。
云计算中的Lambda
云计算中的Lambda,是指serverless architecture,无需配置或管理服务器即可运行代码。借助 Lambda,几乎可以为任何类型的应用程序或后端服务运行代码,而且全部无需管理。
以AWS 为例,云计算中的Lambda 示意流程如下:
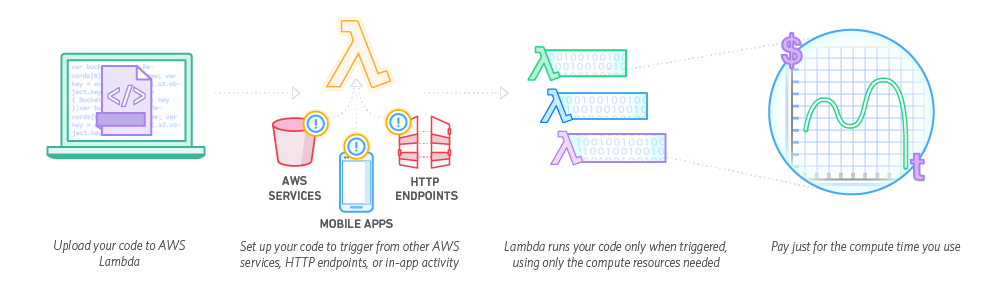
只需上传代码,Lambda 会处理运行和扩展高可用性代码所需的一切工作。还可以将代码设置为自动从其他服务触发,或者直接从任何 Web 或移动应用程序调用。
ETL 是数据挖掘与数据分析中的必备环节,可以方便的通过AWS的Lambda实现,示例如下:
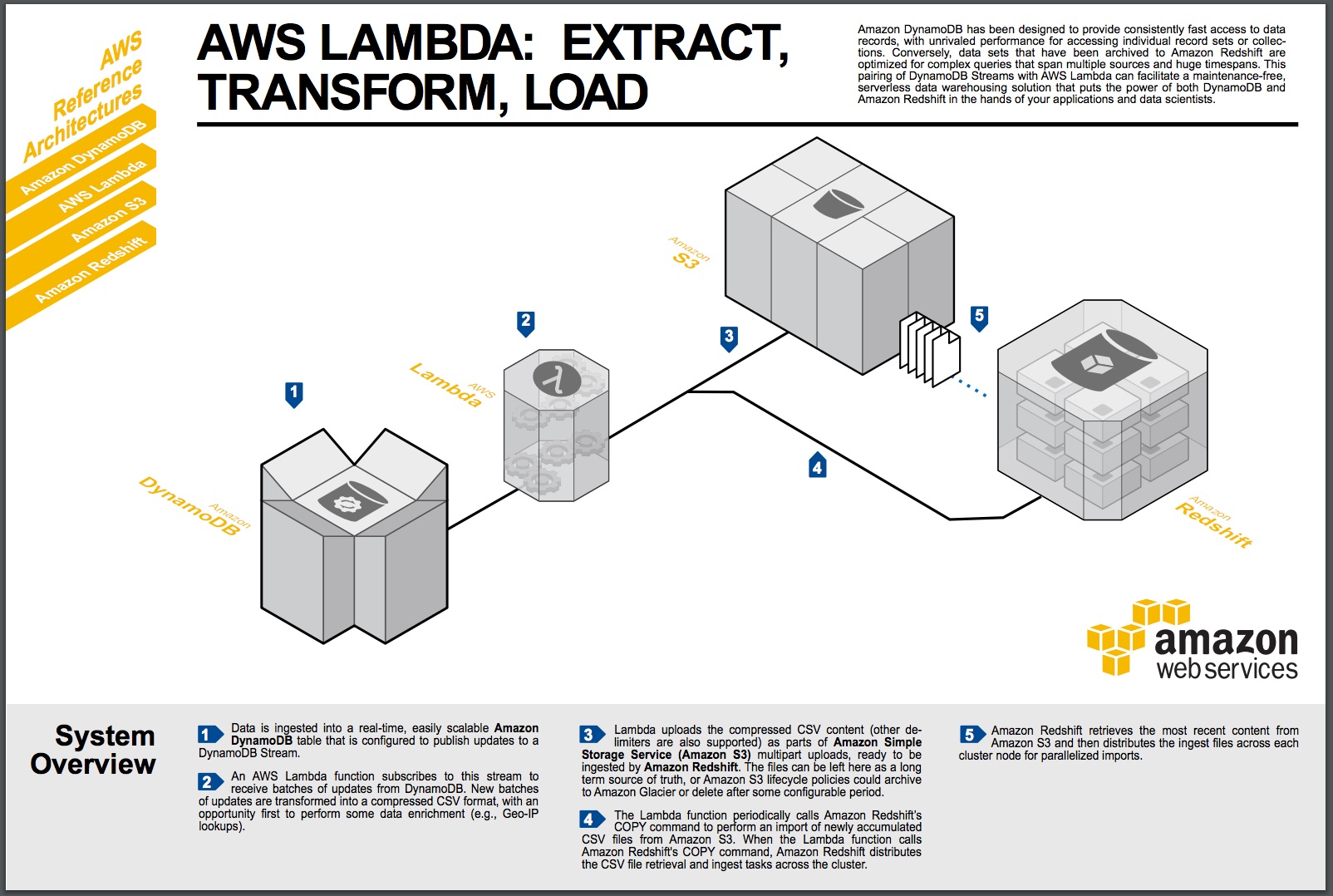
其实,在spark 上实现Lambda 云服务也不是太费力的事。
总之,了解越多,越会喜欢上它,神奇而有趣的Lambda。


