
- 1和区块链Say Hi(1)--- 故事的起源之中本聪的比特币白皮书
- 2Ubuntu20.04 用 `hwclock` 或 `timedatectl` 设置RTC硬件时钟为本地时区_timedatectl设置rtc时间
- 3VMware创建新的虚拟机并使用U盘安装Windows10操作系统_vmware虚拟机怎么用u盘装系统
- 4elasticsearc使用指南之ES管道聚合(Pipeline Aggregation)_es pipeline 聚合
- 5【理论】:OSPF中邻居、邻接关系详解_ospf邻居和邻接关系
- 6webbrowser 打开支付宝网页提示无权打开_支付宝无限实名技术
- 7万字长文详解Typora+Github/Gitee+PicGo图床工具配置教程 | 保姆级教程_typora+github
- 8前端 JS 经典:变量交换_js [a,b] = [b,a]
- 9python的os库是第三方库吗_python第三方库系列之九--os库
- 10SSLError(MaxRetryError(‘HTTPSConnectionPool(host=\‘mirrors.tuna.tsinghua.edu.cn\ ‘, port=443)解决方案_conda sslerror(maxretr
大数据毕设分享 基于python的答题卡识别评分系统_python 识别答题卡客观题
赞
踩
0 简介
今天学长向大家分享一个毕业设计项目
毕业设计 基于python的答题卡识别评分系统
项目运行效果:
毕业设计 基于opencv的答题卡识别
项目获取:
https://gitee.com/sinonfin/algorithm-sharing
课题简介
今天我们来介绍一个与机器视觉相关的毕业设计
基于机器视觉的答题卡识别系统
多说一句, 现在越来越多的学校以及导师选题偏向于算法类, 这几年往往做web系统的同学很难通过答辩, 仔细一想这也在情理之中, 毕业设计是大学四年技术水平的体现, 只做出个XXX管理系统未免太寒酸, 而且web系统选题每年都是那几个老师看着也吐了, 不卡学生才怪
所以同学们, 毕设选题要慎重, 最好先找已经毕业了的学长学姐们了解一下, 至少弄清自己做的系统会被老师问到什么问题, 不然只会为自己的毕业挖坑而已
什么是机器视觉
答题卡识别使用的是机器视觉识别算法, 那什么是机器视觉算法呢?
机器视觉,并不是视觉,他不具有人类的视觉理解能力,说穿了他只是图像处理技术的工程应用,都是由工程师开发的算法来完成任务,并且是特定的算法完成特定的任务,互相之间没有通用性。
废话不多说, 学长到大家看看, 这项技术实现的效果如何.
实现步骤
答题卡识别步骤:
- Step #1: 检测到图片中的答题卡
- Step #2: 应用透视变换来提取图中的答题卡(以自上向下的鸟瞰视图)
- Step #3: 从透视变换后的答题卡中提取 the set of 气泡/圆点 (答案选项)
- Step #4: 将题目/气泡排序成行
- Step #5: 判断每行中被标记/涂的答案
- Step #6: 在我们的答案字典中查找正确的答案来判断答题是否正确
- Step #7: 为其它题目重复上述操作
首先,打开摄像头扫描答题卡

对摄像头获取到的答题卡图片进行二值化腐蚀膨胀边缘检测

轮廓计算,进行顶点对齐,得到下图

对图像进行倾斜变换和仿射变换,得到下图

开始对图像进行二值化,边缘检测等操作,最终得到结果




详细设计
图片读取
主要采用了python+opencv
因为要做后续分割,所以肯定要用到边缘检测,所以先灰度化再二值化
#读取图片 img=cv2.imread('images/5.png') #转换为灰度图 gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #高斯滤波 blurred=cv2.GaussianBlur(gray,(3,3),0) #增强亮度 blurred=imgBrightness(blurred,1.5,3) #自适应二值化 blurred=cv2.adaptiveThreshold(blurred,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,51,2) ''' adaptiveThreshold函数:第一个参数src指原图像,原图像应该是灰度图。 第二个参数x指当像素值高于(有时是小于)阈值时应该被赋予的新的像素值 第三个参数adaptive_method 指: CV_ADAPTIVE_THRESH_MEAN_C 或 CV_ADAPTIVE_THRESH_GAUSSIAN_C 第四个参数threshold_type 指取阈值类型:必须是下者之一 • CV_THRESH_BINARY, • CV_THRESH_BINARY_INV 第五个参数 block_size 指用来计算阈值的象素邻域大小: 3, 5, 7, ... 第六个参数param1 指与方法有关的参数。对方法CV_ADAPTIVE_THRESH_MEAN_C 和 CV_ADAPTIVE_THRESH_GAUSSIAN_C, 它是一个从均值或加权均值提取的常数, 尽管它可以是负数。 ''' blurred=cv2.copyMakeBorder(blurred,5,5,5,5,cv2.BORDER_CONSTANT,value=(255,255,255))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
处理结果如下
canny边缘检测
根据轮廓大小,将要处理的几部分分割出来
如果提取效果不好,可能是因为拍摄光线原因,导致图片亮度不好,增强一下亮度,二值化后的图片效果会好一点,这样canny边缘检测结果也会好一点
#增强亮度
def imgBrightness(img1, c, b):
rows, cols= img1.shape
blank = np.zeros([rows, cols], img1.dtype)
rst = cv2.addWeighted(img1, c, blank, 1-c, b)
return rst
- 1
- 2
- 3
- 4
- 5
- 6
#canny边缘检测 edged = cv2.Canny(blurred,0,255) cnts,hierarchy=cv2.findContours(edged,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) docCnt = [] count=0 #确保至少有一个轮廓被找到 if len(cnts)>0: #将轮廓按照大小排序 cnts=sorted(cnts,key=cv2.contourArea,reverse=True) #对排序后的轮廓进行循环处理 for c in cnts: #获取近似的轮廓 peri = cv2.arcLength(c,True) approx = cv2.approxPolyDP(c,0.02*peri,True) #如果近似轮廓有四个顶点,那么就认为找到了答题卡 if len(approx) == 4: docCnt.append(approx) count+=1 if count==3: break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
处理结果如下:

四点变换 划出区域
直接用imutils包中的four_point_transform将需要的区域提取出来
彩色图便于展示
灰度图用来处理
#四点变换,划出选择题区域
paper = four_point_transform(img,np.array(docCnt[0]).reshape(4,2))
warped = four_point_transform(gray,np.array(docCnt[0]).reshape(4,2))
#四点变换,划出准考证区域
ID_Area = four_point_transform(img,np.array(docCnt[1]).reshape(4,2))
ID_Area_warped = four_point_transform(gray,np.array(docCnt[1]).reshape(4,2))
#四点变换,划出科目区域
Subject_Area = four_point_transform(img,np.array(docCnt[2]).reshape(4,2))
Subject_Area_warped = four_point_transform(gray,np.array(docCnt[2]).reshape(4,2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
处理结果如下:

处理选择题区域
提取选项轮廓
''' 处理选择题区域统计答题结果 ''' thresh = cv2.threshold(warped,0,255,cv2.THRESH_BINARY_INV|cv2.THRESH_OTSU)[1] thresh = cv2.resize(thresh,(2400,2800),cv2.INTER_LANCZOS4) paper = cv2.resize(paper,(2400,2800),cv2.INTER_LANCZOS4) warped = cv2.resize(warped,(2400,2800),cv2.INTER_LANCZOS4) cnts,hierarchy = cv2.findContours(thresh.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) questionCnts=[] answers=[] #对每一个轮廓进行循环处理 for c in cnts: #计算轮廓的边界框,然后利用边界框数据计算宽高比 (x,y,w,h) = cv2.boundingRect(c) ar = w/float(h) #判断轮廓是否是答题框 if w>=40 and h>=15 and ar>=1 and ar<=1.8: M = cv2.moments(c) cX = int(M["m10"]/M["m00"]) cY = int(M["m01"]/M["m00"]) questionCnts.append(c) answers.append((cX,cY)) cv2.circle(paper,(cX,cY),7,(255,255,255),-1) ID_Answer=judge_point(answers,mode="point") cv2.drawContours(paper,questionCnts,-1,(255,0,0),3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
处理结果如下:

判断选项
def judgeX(x,mode):
if mode=="point":
if x<600:
return int(x/100)+1
elif x>600 and x<1250:
return int((x-650)/100)+6
elif x>1250 and x<1900:
return int((x-1250)/100)+11
elif x>1900:
return int((x-1900)/100)+16
elif mode=="ID":
return int((x-110)/260)+1
elif mode=="subject":
if x<1500:
return False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
def judge(x,y,mode): if judgeY(y,mode)!=False and judgeX(x,mode)!=False: if mode=="point": return (int(y/560)*20+judgeX(x,mode),judgeY(y,mode)) elif mode=="ID": return (judgeX(x,mode),judgeY(y,mode)) elif mode=="subject": return judgeY(y,mode) else: return 0 def judge_point(answers,mode): IDAnswer=[] for answer in answers: if(judge(answer[0],answer[1],mode)!=0): IDAnswer.append(judge(answer[0],answer[1],mode)) else: continue IDAnswer.sort() return IDAnswer def judge_ID(IDs,mode): student_ID=[] for ID in IDs: if(judge(ID[0],ID[1],mode)!=False): student_ID.append(judge(ID[0],ID[1],mode)) else: continue student_ID.sort() return student_ID def judge_Subject(subject,mode): return judge(subject[0][0],subject[0][1],mode)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
读取正确结果
''' 读取结果 ''' df = pd.read_excel("answer.xlsx") index_list = df[["题号"]].values.tolist() true_answer_list = df[["答案"]].values.tolist() index=[] true_answer=[] score=0 #去括号 for i in range(len(index_list)): index.append(index_list[i][0]) for i in range(len(true_answer_list)): true_answer.append(true_answer_list[i][0]) answer_index=[] answer_option=[] for answer in ID_Answer: answer_index.append(answer[0]) answer_option.append(answer[1]) for i in range(len(index)): if answer_option[i]==true_answer[i]: score+=1 if i+1==len(answer_option): break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
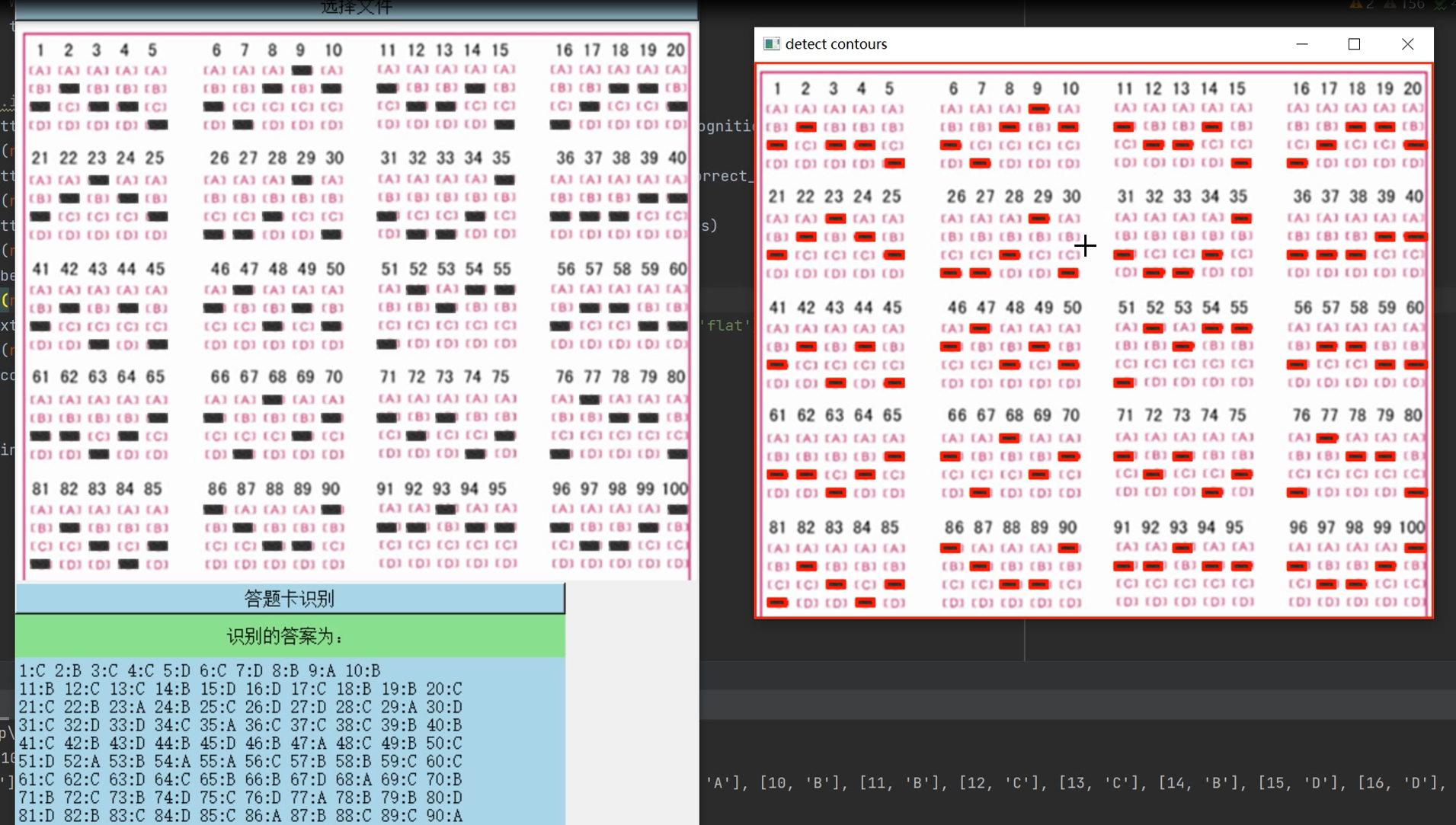
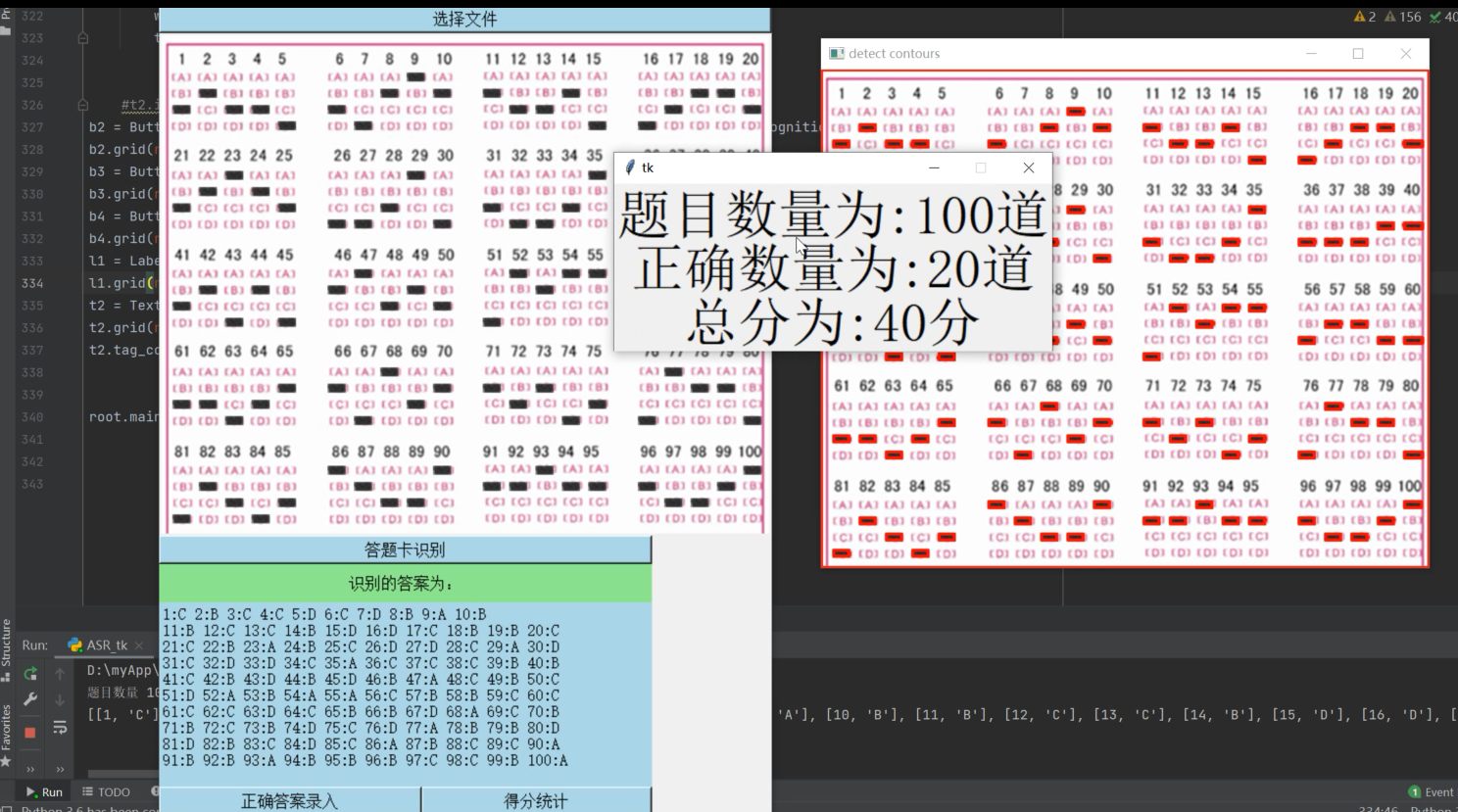
最后
实现效果:
毕业设计 基于opencv的答题卡识别
项目获取:

