
- 1JDK8新特性 - Lambda表达式_jdk8有lamda表达式吗
- 2阿里云服务器搭建hadoop集群后无法访问9870,8088web端口解决方案_阿里云服务器登不上hadoop的8970
- 3gitlab 克隆远程仓库 分支方法_gitlab克隆分支
- 4Docker高级篇之Docker-compose容器编排
- 5探秘AI测试助手:Test-Agent,智能化测试的新纪元
- 6使用window自带的ssh连接linux服务器_window用ssh连接linux
- 7万字总结!5大AI应用场景+17个细分方向+40多个案例精选_ai常见办公场景
- 8顺序输出片内RAM的数据_2分钟时ram的输出数据
- 9深入理解与解决Git中的“fatal: refusing to merge unrelated hi_git refusing to merge
- 10二、Neo4j的使用(知识图谱构建射雕人物关系)_neo4j的使用(知识图谱构建射雕)
堆排序的比较次数_堆排序过程、时间复杂度分析及改进
赞
踩
前言
前面介绍过四种排序方法,其中快速排序和归并排序的平均时间复杂度都是
一、堆排序过程
堆排序有两种形式,一种是大顶堆,一种是小顶堆。顾名思义,大顶堆的父结点总大于子结点,小顶堆父结点总小于子结点。

建立这个堆的过程有两种方法,分别是筛选法和插入法。
1. 建堆过程分析
① 筛选法
- 过程
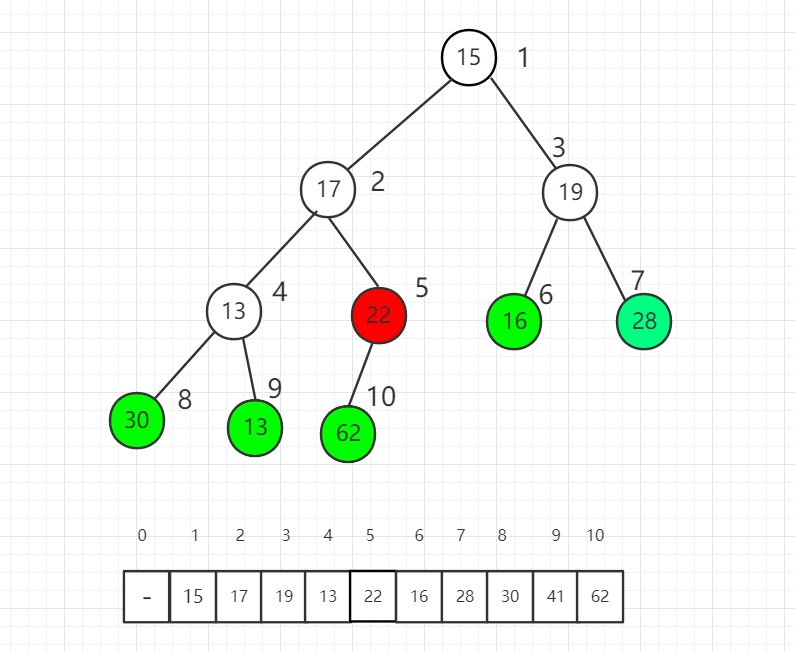
假设当前有一个数字序列为
| 25 | 56 | 49 | 78 | 11 | 65 | 41 | 36 |
|---|
先对这个序列建立完全二叉树。
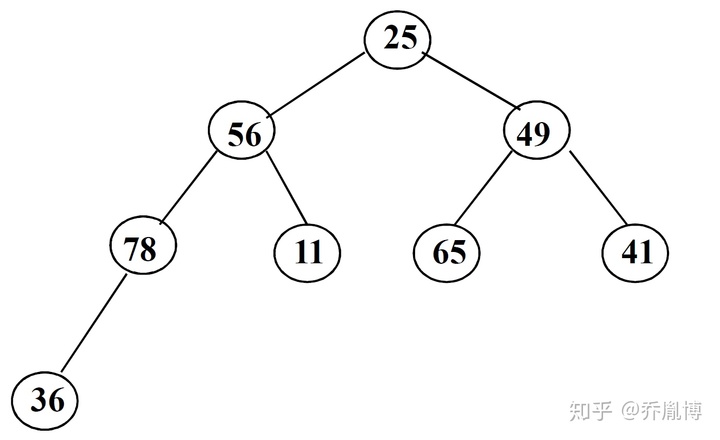
随后从这n个元素的n/2位置开始,进行堆调整,每次调整把两个子结点中最大的而且大于父结点的节点数字与父结点交换,直到调整到根节点为止。
最后我们会得到最终的调整结果。
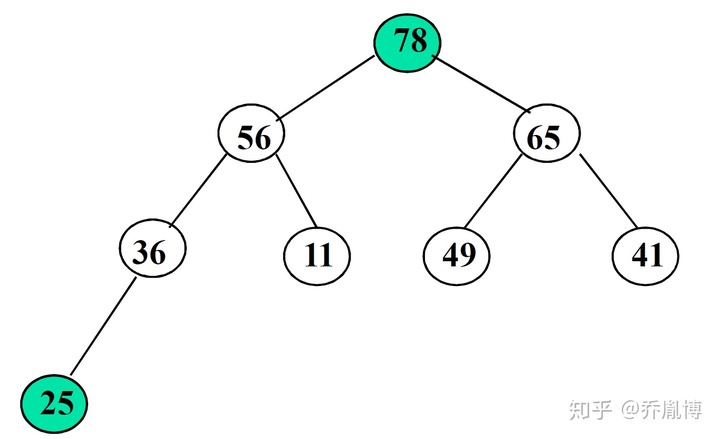
下面给出一个动画演示筛选法建堆的过程以及后续堆排序的过程。

- public class Heapsort {
-
- private void headAdjust(int[] array, int start, int stop){
- int j = 0;
- array[0] = array[start];
- for (j = 2*start;j<=stop;j=j*2){
- if(j<stop && array[j]<array[j+1])j++;
- if(array[0]>=array[j])break;
- array[start] = array[j];
- start = j;
- }
- array[start] = array[0];
- }
- private void headsort(int[] array){
- int i,j,k;
- //筛选法建堆
- for (i = array.length/2;i>0;i--){
- headAdjust(array,i,array.length-1);
- }
- //堆排序过程
- for(j = array.length-1;j>1;j--){
- array[0] = array[j];
- array[j] = array[1];
- array[1] = array[0];
- headAdjust(array,1,j-1);
- }
- headAdjust(array,i,array.length-1);
- }
-
-
- public static void main(String[] args) {
- int[] array = new int[]{0,25,56,49,78,11,65,41,36};//0位置作为哨兵项
- Heapsort headsort = new Heapsort();
- headsort.headsort(array);
- for(int item: array){
- System.out.print(item+" ");
- }
- }
- }

- 时间复杂度分析
经过上面的分析我们可以观察得出如下几点规律:
堆的高度为k,最多有个结点。
调整k-1层的数据结点,最多下调一层,以此类推。
每下调一层,需要进行两次元素比较,一次是孩子之间比较,选出最大值,然后用这个最大值和父结点比较,决定是否交换父结点。
输入n个元素建堆,需要最多的比较次数为:
令
接着由我们第一条规律得到
因此,筛选法建堆最坏情况的时间复杂度为
② 插入法
- 过程
插入法建堆过程和筛选法不太一样,下面先了解一下插入法建堆过程。
插入法是从无到有开始建堆,不同于筛选法基于完全二叉树调整建堆。插入法在插入一个新元素是,只和父结点比较,无需和兄弟结点比较,如果大于父结点则上调一层,比较一次。
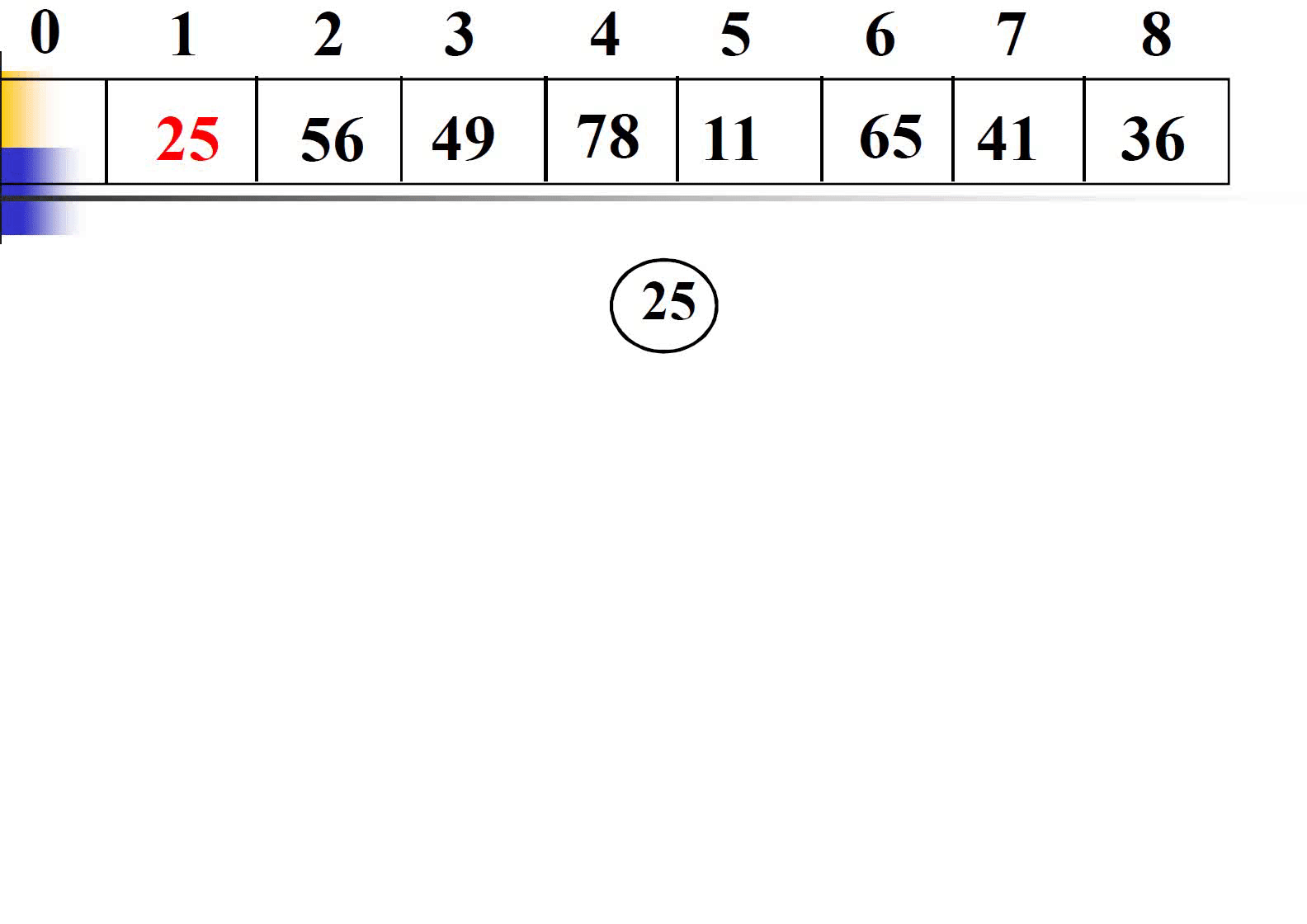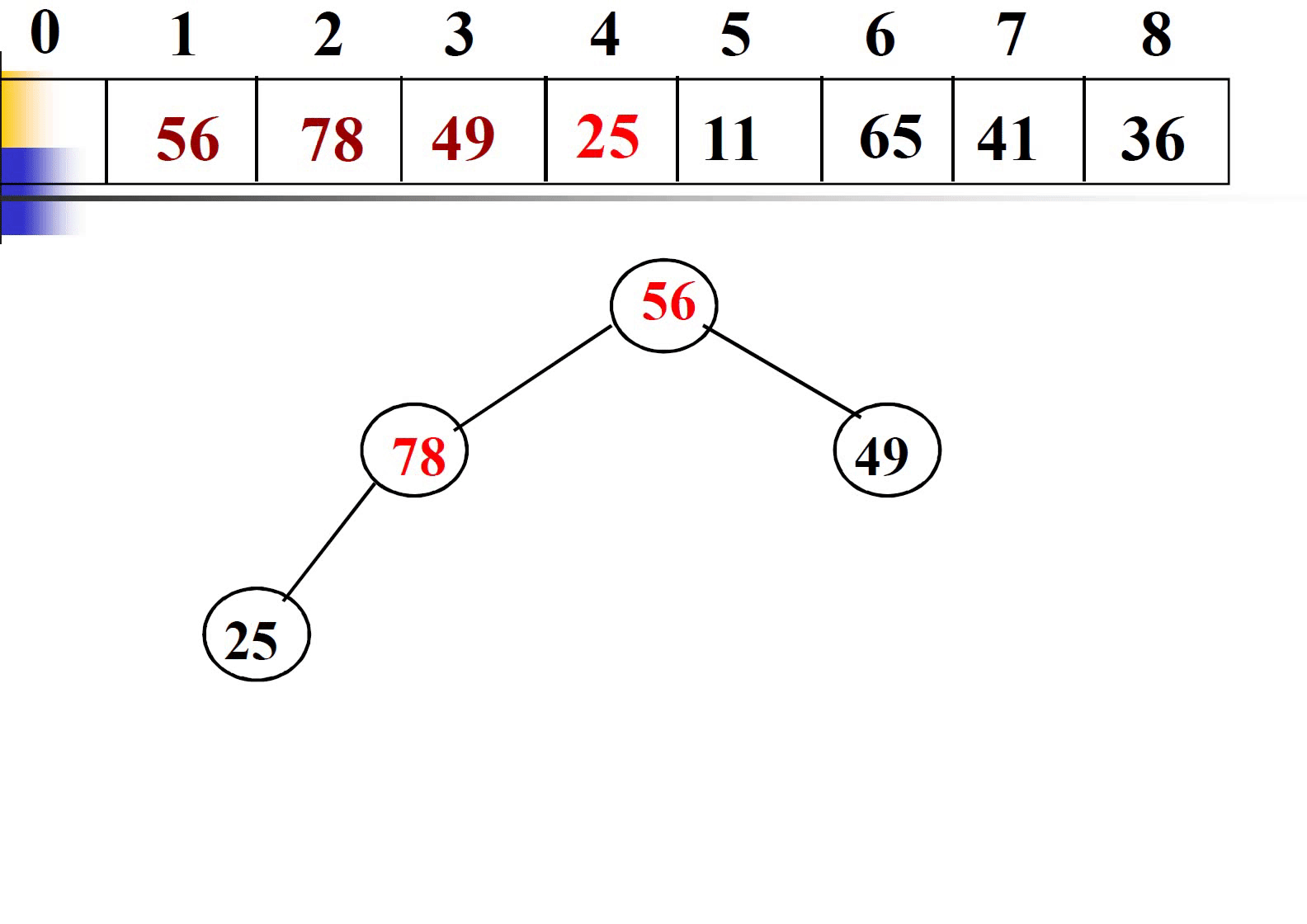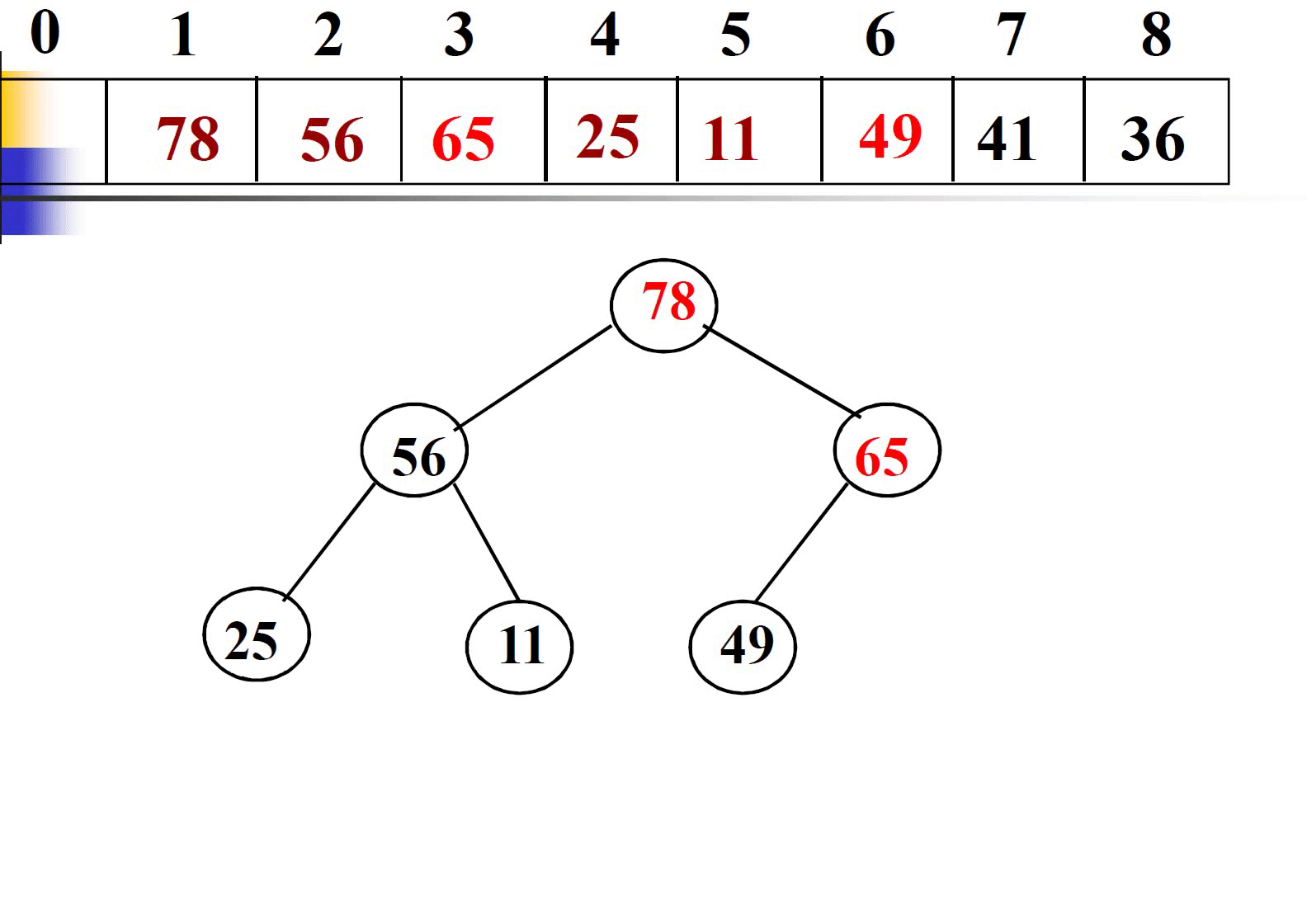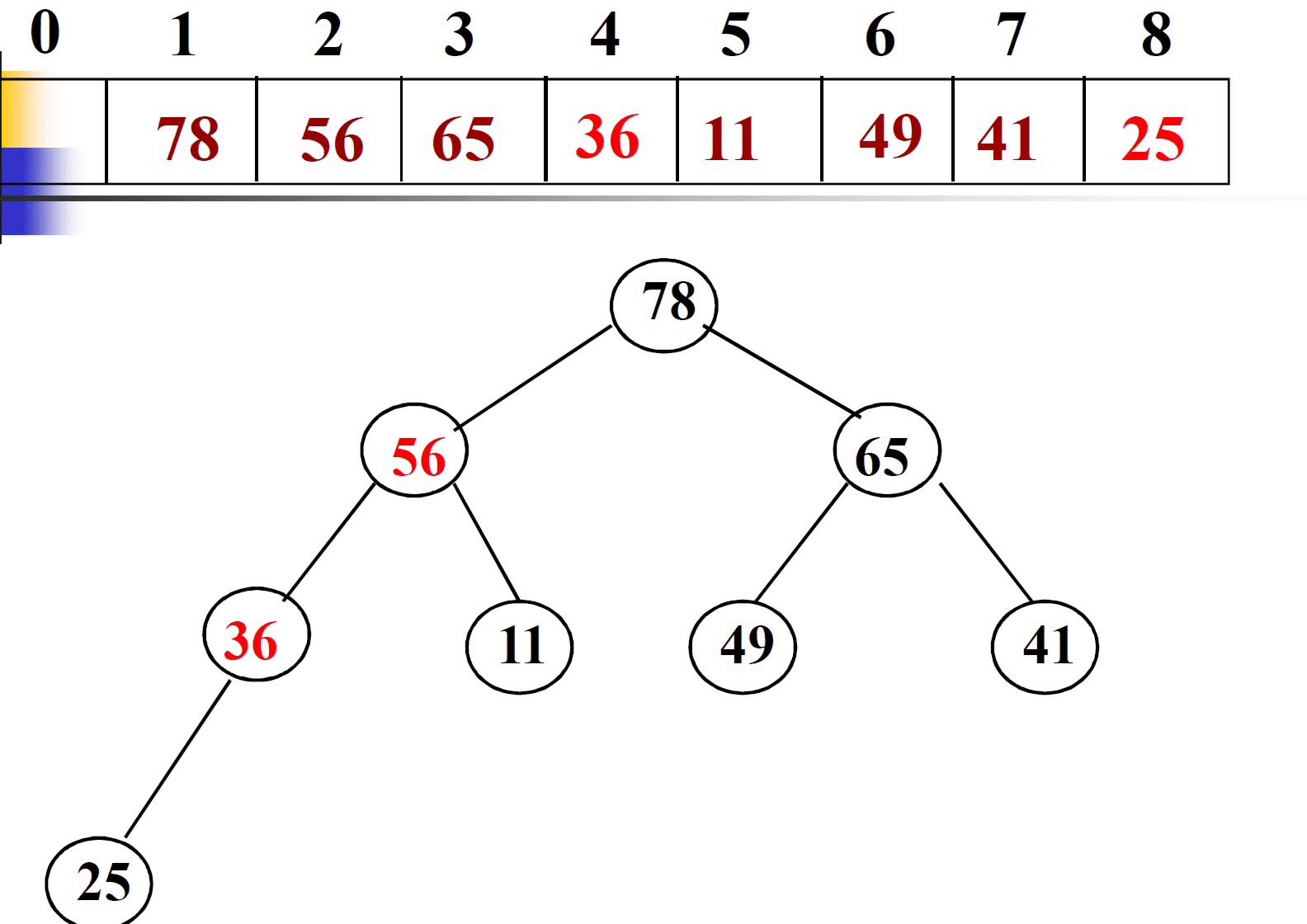
这里不再给出插入法建堆过程的代码。我们直接进行时间复杂度的分析。
时间复杂度分析
类似于筛选法,我们分析最坏情况时间复杂度。有下面几个事实
插入一个新元素,只与父结点比较一次,比较一次,最多上调一层,最多上调当前层减一。
二叉树第i层有个结点,每个结点最多上调i-1层。
则输入n个元素建堆需要的最多比较次数为
可以看出插入法建堆的过程时间复杂度为
我们通常不适用插入法建堆,而通常使用筛选法建堆,因为筛选法时间复杂度O(n),而插入法时间复杂度为O(nlogn)。
2. 堆调整过程分析
- 堆调整过程
堆调整的过程如上面的堆排序整体过程所示的那样,这里不在赘述,下面默认大家都已经完全理解了堆排序的过程。我们对堆调整过程进行一下时间复杂度分析。
- 堆调整时间复杂度分析
堆排序调整过程,每个元素都要遍历一次,因此每个元素都有被上调的概率,我们假设每个元素都下调其原所在层数,则有如下公式
我们可知堆排序筛选法建堆和堆调整过程结合到一起,时间复杂度是O(n)+O(nlogn),进一步堆排序时间复杂度为O(nlogn)量级。
二、堆排序的改进
显然堆排序的调整过程是存在问题的,还是存在可以继续优化的空间。
我们观察到,堆调整过程每个元素上调都进行了两次比较操作,我们考虑能否精简这两次比较,使其小于2,最理想能达到1。
下面介绍两种堆排序的加速方式:
第一种堆排序加速方式:
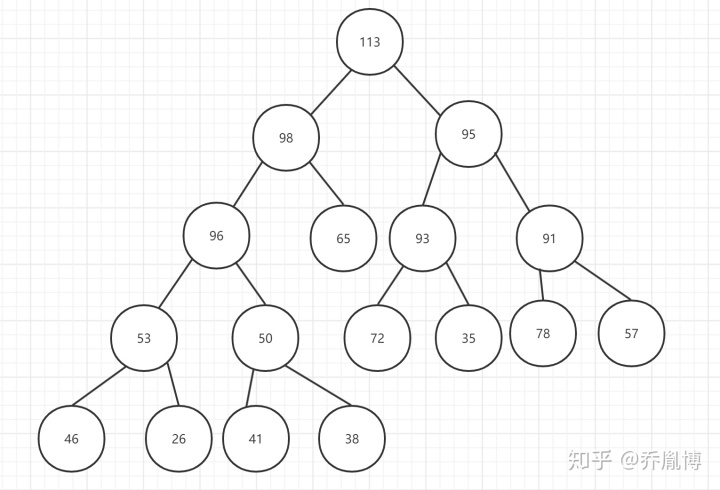
上面的大顶堆,我们首先将38与113交换,然后并不将38做调整,反而我们将根节点的孩子节点中较大的那个调整到父结点,最后我们会得到如下的大顶堆。
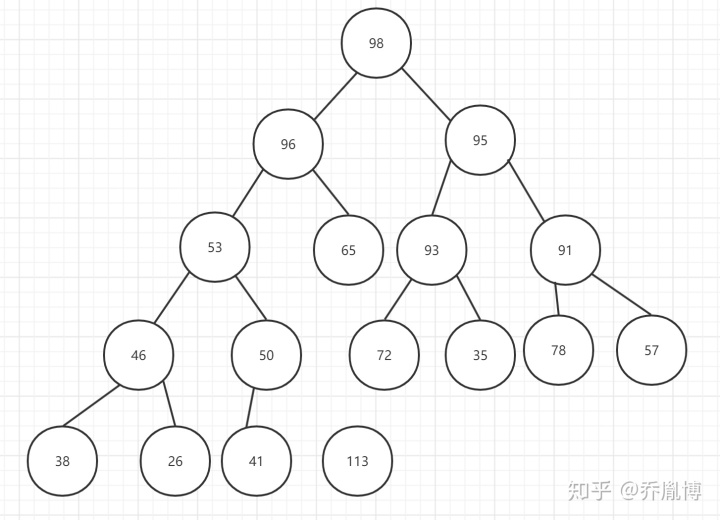
这整个过程,每次元素的调整只进行了一次元素比较。
接下来,我们进行一遍向上调整,38不断和父结点比较,如果发生交换继续与交换后的父结点比较。
通常,向上比较的次数不会超过下沉操作的比较次数,正常情况下向上调整的次数不多。整个算法整体堆调整过程的时间复杂度,可能只有一点几倍的nlogn,优于2nlogn的时间复杂度。
第二种堆排序加速过程:
第一种堆排序过程仍然存在可以优化的空间。我们关注于第一步元素下沉的过程,如果我们能够在合适的位置停止下沉,则不需要进行向上调整,会进一步减少比较次数。
一般我们会在下沉一半时,判断是否需要继续下沉。
总结
以上就是堆排序相关的过程,时间复杂度分析和改进。堆排序从时间复杂度上来说,不失为一种优秀的排序算法。最坏时间复杂度是nlogn量级的。

