
- 1c++逆序输出正整数_c++给出一个正整数 nn,你需要将 nn 进行倒序输出。 注意:请使用递归完成。
- 2MongoDB 存储引擎:WiredTiger和In-Memory
- 3sql报错:sql injection violation, syntax error_sql injection violation, syntax error: error. pos
- 4EasyExcel工具类封装, 做到一个函数完成简单的读取和导出
- 5web搭建服务器端+创建web后端项目详细步骤_web系统部署详解
- 6Unity 中有关iOS Player 设置属性大全_unity ios高性能模式关闭
- 7C++链表的实现(链表反转、合并)_c++ 判断链表中间节点
- 8Android文本输入框EditText方法说明和属性
- 9Spring Boot(三十七):Spring Boot 使用spring-boot-configuration-processor获取配置文件_springboot configuration processor与 spring版本
- 10云原生之使用Docker部署homarr个人导航页
Python 线程,进程,多线程,多进程以及并行执行for循环笔记_pythonfor循环嵌入多进程
赞
踩
Python 线程,进程,多线程,多进程以及并行执行for循环
一、Python 线程,进程,多线程,多进程简要介绍
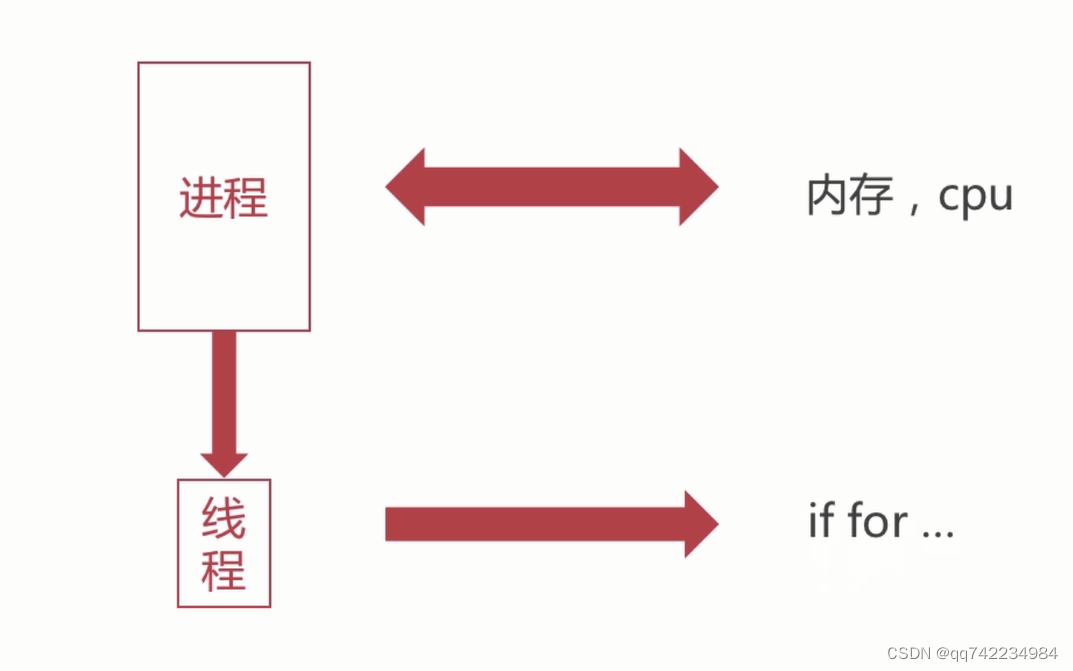
在 Python 中,我们可以使用多线程和多进程来实现并发执行的程序以提高效率。下面是对于 Python 中线程、进程、多线程和多进程的简要说明:
- 线程(Thread):线程是进程内部的执行路径,用于执行程序的一部分。Python 提供了 threading 模块来创建和管理线程。
- 进程(Process):进程是程序的执行实例,具有独立的资源和控制流程。可以使用 multiprocessing 模块在 Python 中创建和管理进程。
- 多线程(Multithreading):多线程是在单个进程内创建多个线程来同时执行任务的方式。多个线程共享进程的资源,但需要注意线程间的同步和资源竞争问题。
- 多进程(Multiprocessing):多进程是通过创建多个独立的进程来实现并发执行的方式。每个进程有自己独立的资源和控制流程,可以利用多核处理器并行执行任务。
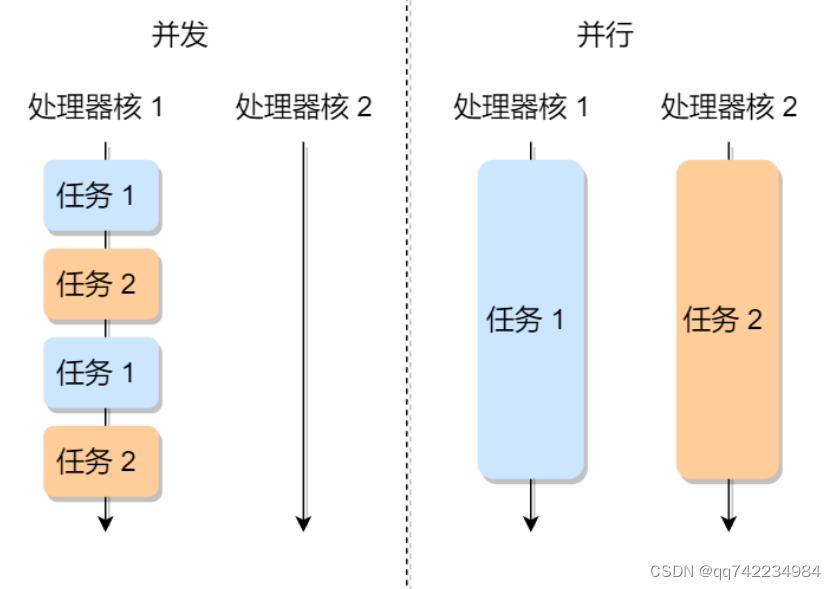
使用多线程和多进程的选择取决于具体的场景和需求。多线程适合于 I/O 密集型任务,如网络请求、文件读写等,可以提高并发性和响应性。多进程适用于 CPU 密集型任务,如大量计算、图像处理等,可以利用多核处理器加速运算。
需要注意的是,在 Python 中全局解释器锁(Global Interpreter Lock,GIL)的限制下,多线程并不能实现真正的并行执行,而是通过在不同线程之间切换来达到并发效果。如果需要真正的并行执行,可以使用多进程来充分利用多核处理器。
要在 Python 中使用多线程和多进程,可以使用 threading 和 multiprocessing 模块,它们提供了相应的类和函数来创建和管理线程和进程,以及处理线程间的同步和通信。
GIL的作用:单一CPU工作,线程安全
二、Multiprocessing
Python 的 multiprocessing 模块提供了用于并行执行任务的多进程功能。它允许在 Python 中创建和管理多个独立的进程,每个进程有自己独立的资源和控制流程,可以同时执行任务以提高程序的性能和效率。
下面是对 multiprocessing 模块的详细说明:
- 进程创建:multiprocessing 模块提供了 Process 类,可以使用它来创建进程。通过创建 Process 类的实例,可以指定要执行的函数或方法,并传递参数给它们。然后调用进程的 start() 方法来启动进程的执行。
| 函数名 | 功能 | 参数 | 返回值 |
|---|---|---|---|
| Process | 创建一个进程 | target,args(元组) | 进程对象 |
| start | 执行进程 | 无 | 无 |
| join | 阻塞程序 | 无 | 无 |
| kill | 杀死进程 | 无 | 无 |
| is_alive | 进程是否存活 | 无 | bool |
-
进程间通信:由于每个进程拥有独立的地址空间,进程间的数据共享需要使用特定的进程间通信(IPC)机制。multiprocessing 模块提供了多种 IPC 的方式,如队列(Queue)、管道(Pipe)、共享内存(Value、Array)等,在不同进程之间安全地传递数据。
-
进程池:通过使用 multiprocessing 模块的 Pool 类,可以创建进程池,实现对任务的批量处理。进程池中的多个进程可以并行执行任务,从而提高效率。
| 函数名 | 功能 | 参数 | 返回值 |
|---|---|---|---|
| Pool | 进程池创建 | Processcount | 进程池对象 |
| apply_async | 任务加入进程池(异步) | func,args | 无 |
| join | 等待进程池任务结束 | 无 | 无 |
| close | 关闭进程池 | 无 | 无 |
- 锁和同步:多个进程同时访问共享资源时,可能会导致资源竞争和数据不一致的问题。为了避免这些问题,multiprocessing 模块提供了锁(Lock)、信号量(Semaphore)、条件变量(Condition)、事件(Event)等同步原语,用于实现进程间的同步和通信。
from multiprocessing import Process,Lock
manage = Manager()
lock = manage.Lock()
- 1
- 2
- 3
| 函数名 | 功能 | 参数 | 返回值 |
|---|---|---|---|
| acquire | 上锁 | 无 | 无 |
| release | 开锁 | (解锁) | 无 |
- 异常处理:在多进程执行时,各个进程都是相互独立运行的,因此可能会出现进程抛出异常的情况。multiprocessing 模块提供了异常处理机制,可以捕获和处理子进程抛出的异常。
总体而言,multiprocessing 模块提供了一种简单且方便的方式来实现多进程并行处理。它适用于处理 CPU 密集型任务、利用多核处理器的计算、并行执行独立的子任务等场景,可以充分发挥多核处理器的能力,提高程序的性能和效率。
import multiprocessing as mul
def f(x):
return x ** 2
if __name__ == '__main__':
pool = mul.Pool(5)
rel = pool.map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(rel)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
pool.close()和pool.join()是用于管理multiprocessing模块中进程池的两个方法。
pool.close()方法用于关闭进程池,表示不再接受新的任务。之后如果尝试提交新的任务,将会引发错误。pool.join()方法用于等待所有提交的任务执行完毕,即所有任务都被处理完成后再继续执行后续代码。这个方法会阻塞当前线程,直到所有任务都完成。
通常的使用方式是:先调用pool.close()方法告诉进程池不再接受新任务,然后调用pool.join()方法等待所有任务执行完毕。这样可以确保在主进程退出前,子进程都被正确地清理和终止。
进程示例
# coding:utf-8
"""主进程与子进程互不影响"""
import time
import os
import multiprocessing
def work_a():
for i in range(10):
print(i, 'a', os.getpid())
time.sleep(1)
def work_b():
for i in range(10):
print(i, 'b', os.getpid())
time.sleep(1)
if __name__ == '__main__':
start = time.time() # 主进程1
a_p = multiprocessing.Process(target=work_a) # 子进程1
# a_p.start() # 子进程1执行
# a_p.join()
b_p = multiprocessing.Process(target=work_b) # 子进程2
# b_p.start() # 子进程2执行
for p in (a_p, b_p):
p.start()
for p in (a_p, b_p):
p.join()
for p in (a_p, b_p):
print(p.is_alive())
print('时间消耗是:', time.time() - start) # 主进程代码2
print('parent pid is %s' % os.getpid()) # 主进程代码3行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
进程池示例
# coding:utf-8
import os
import time
import multiprocessing
def work(count, lock):
lock.acquire()
print(count, os.getpid())
time.sleep(5)
lock.release()
return 'result is %s, pid is %s' % (count, os.getpid())
if __name__ == '__main__':
pool = multiprocessing.Pool(5)
manger = multiprocessing.Manager()
lock = manger.Lock()
results = []
for i in range(20):
result = pool.apply_async(func=work, args=(i, lock))
# results.append(result)
# for res in results:
# print(res.get())
pool.close()
pool.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
问题1.使用multiprocessing.Pool并行处理任务时,需要添加锁吗
在使用multiprocessing.Pool并行处理任务时,通常情况下不需要手动添加锁。
multiprocessing.Pool内部会自动处理进程间的并发访问问题,确保任务的并行执行不会导致数据竞争或冲突。
Pool会将任务分配给不同的进程,并确保每个进程独立地执行任务。每个进程都有自己的内存空间和执行环境,因此它们之间不会共享变量。
然而,如果你在任务内部使用了共享的可变数据结构(例如列表、字典)或共享的资源(例如文件、网络资源),那么你可能需要考虑使用进程锁(multiprocessing.Lock)或其他同步机制来保证数据访问的一致性和完整性。
在这种情况下,你可以在任务函数中使用锁来保护共享资源的读写操作,以避免数据竞争问题。如果你的任务没有使用共享的可变数据结构或资源,则通常情况下无需手动添加锁。
需要注意的是,进程锁的使用可能会对并行性能产生一定的影响,尤其是在高度竞争的情况下。因此,在使用锁时,需要权衡并行性能和数据一致性之间的需求。
问题2.multiprocessing.map用于for循环加速时,怎么加锁
import multiprocessing
def process_item(args):
print(multiprocessing.current_process().pid)
item, lock = args
# 加锁
with lock:
print(item)
# 处理共享资源
# ...
def main():
# 创建一个进程池
pool = multiprocessing.Pool()
# 创建一个Manager对象
manager = multiprocessing.Manager()
# 创建一个可在多个进程之间共享的锁对象
lock = manager.Lock()
# 要处理的数据
data = [1, 2, 3, 4, 5, 6]
# 使用map进行并行处理
pool.map(process_item, [(item, lock) for item in data])
# 关闭进程池
pool.close()
pool.join()
if __name__ == '__main__':
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
注意,加锁可能会导致性能下降,因为多个进程需要等待锁的释放才能继续执行。因此,在使用multiprocessing.map时,应该根据具体情况权衡使用锁的必要性和性能影响。
问题3.在使用Python的multiprocessing模块的map函数时必须在__main__中吗,为什么?
在使用Python的multiprocessing模块的map函数时,通常需要将其放在__main__函数或脚本的顶层代码中。这是因为multiprocessing模块在Windows和Unix-like系统上使用不同的方法来实现多进程,并且需要在__main__函数或脚本的顶层代码中启动新的进程。
具体原因是,在Unix-like系统中,multiprocessing模块会使用fork系统调用来创建子进程,它会复制当前进程的所有代码和状态。因此,当map函数在__main__函数或脚本的顶层代码中被调用时,map函数所依赖的代码也会被复制到新的子进程中。
而在Windows系统中,由于没有fork系统调用,multiprocessing模块会通过spawn方法来创建新的进程。在这种情况下,Python解释器会将整个脚本重新执行一次,并从__main__函数开始执行。因此,如果map函数不在__main__函数或脚本的顶层代码中调用,新的进程将无法找到所需的代码。
综上所述,为了确保在不同操作系统上multiprocessing.map的正确运行,它通常需要在__main__函数或脚本的顶层代码中被调用。
问题4.Python函数并行的基本实现方式
import multiprocessing
def func1():
print("Function 1")
def func2():
print("Function 2")
if __name__ == "__main__":
# 创建两个进程
process1 = multiprocessing.Process(target=func1)
process2 = multiprocessing.Process(target=func2)
# 启动进程
process1.start()
process2.start()
# 等待进程结束
process1.join()
process2.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、Multithreading
| Thread | 创建线程 | Thread(target,args) |
|---|---|---|
| 方法名 | 说明 | 用法 |
| start | 启动线程 | start() |
| join | 阻塞直到线程执行结束 | join(timeout=None) |
| getName | 获取线程的名字 | getName() |
| setName | 设置线程的名字 | setName(name) |
| is_alive | 判读线程是否存活 | is_alive() |
| setDaemon | 守护线程 | setDaemon(True) |
问题1.python for循环可以用多线程吗
在Python中,简单的for循环无法直接并发执行多线程。这是因为Python解释器的全局解释器锁(Global Interpreter Lock,GIL)限制了在解释器级别同时运行多个线程执行字节码的能力。
GIL是一种机制,确保在CPython解释器中同一时刻只有一个线程在执行Python字节码。这意味着即使在多线程环境下,同一进程中的多个线程也无法同时利用多个CPU核心。
然而,值得注意的是,尽管for循环本身不能直接并发执行多线程,但是可以使用其他模块(如threading模块)来在循环内部创建和管理多个线程,以实现并发执行的效果。
以下是一个示例代码,展示了如何在for循环中使用threading模块创建多个线程并发执行任务:
import threading
def process_function(value):
# 执行任务的代码
print(f"Processing value {value}")
if __name__ == "__main__":
values = [1, 2, 3, 4, 5]
threads = []
for value in values:
thread = threading.Thread(target=process_function, args=(value,))
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
print("All threads completed")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
在上述示例中,我们使用threading.Thread来创建多个线程,并将每个线程的目标函数设置为process_function。在循环结束后,我们启动每个线程,并使用join方法等待所有线程完成。
需要注意的是,由于GIL的存在,在多线程情况下,并不会提高CPU密集型任务的执行速度,因为同一时刻只有一个线程能够执行Python字节码。而对于I/O密集型任务,多线程可以在等待I/O的时候切换到其他线程,提高效率。
如果你希望充分利用多核/多CPU,实现并行处理,可以考虑使用multiprocessing模块来创建多个进程执行任务。
四、concurrent.futures
concurrent.futures 是 Python 标准库中用于并发编程的模块。它提供了一种高级的接口,使得在编写并发代码时更加简单和直观。concurrent.futures 模块基于线程池和进程池的概念,允许在多个线程或进程中并发执行任务,并提供了一些方便的方法来管理并发任务的执行和获取结果。
下面是对 concurrent.futures 模块的一些关键概念和用法的详细说明:
-
Executor接口:concurrent.futures模块提供了Executor接口作为执行并发任务的抽象。它定义了一些常用的方法,如submit()、map()和shutdown()。submit(fn, *args, **kwargs):将函数fn以及其参数args和关键字参数kwargs提交给执行器,返回一个Future对象,代表函数的异步执行。map(fn, *iterables, timeout=None):将函数fn应用于iterables中的每个元素,并返回一个可迭代的Future对象,每个Future对象代表一个函数的异步执行。shutdown(wait=True):关闭执行器,等待所有任务完成。如果wait参数为True(默认),则会阻塞直到所有任务完成。
-
Future对象:Future对象代表一个异步操作的结果。通过submit()或map()方法返回的Future对象可以用于获取任务的结果和管理任务的状态。result(timeout=None):等待并返回任务的结果。如果timeout参数指定了超时时间,超过该时间仍未完成则抛出TimeoutError异常。add_done_callback(fn):添加一个回调函数,在任务完成时被调用。cancelled():返回任务是否被取消。running():返回任务是否正在运行。done():返回任务是否已经完成。
-
并发任务的执行方式:
- 线程池执行器:
concurrent.futures.ThreadPoolExecutor类提供了线程池的实现,使用线程来执行并发任务。 - 进程池执行器:
concurrent.futures.ProcessPoolExecutor类提供了进程池的实现,使用多个进程来执行并发任务。
- 线程池执行器:
下面是一个简单示例,演示了如何使用 concurrent.futures 模块创建线程池执行器并异步执行任务:
import concurrent.futures
def task(name):
print(f"Task {name} started")
result = name.upper()
print(f"Task {name} completed")
return result
if __name__ == '__main__':
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(task, i) for i in range(5)]
for future in concurrent.futures.as_completed(futures):
result = future.result()
print(f"Result: {result}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在上述示例中,我们定义了一个简单的任务函数 task(),它接受一个名称作为输入,并将其转换为大写。然后,我们使用 ThreadPoolExecutor 创建了一个线程池执行器,并使用 submit() 方法提交了五个任务。通过 as_completed() 函数,我们可以按照任务完成的顺序获取结果,并打印出每个任务的结果。
这只是 concurrent.futures 模块的基本用法介绍,它还提供了其他功能,如超时处理、并发映射、异常处理等。
五、joblib
joblib 是一个用于高效地并行运行 Python 函数的库,特别适用于科学计算和机器学习任务。它提供了一种简单的方式来并行执行函数,自动处理函数的序列化和反序列化,并提供了内存缓存功能,以减少重复计算的开销。
下面是对 joblib 库的一些关键概念和用法的详细说明:
- 并行执行函数:
joblib提供了Parallel类,用于并行执行函数。它可以通过多线程或多进程的方式实现并行计算。
from joblib import Parallel, delayed
# 定义需要并行执行的函数
def my_function(x):
return x ** 2
# 并行执行函数
results = Parallel(n_jobs=2)(delayed(my_function)(i) for i in range(10))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在上述示例中,我们定义了一个简单的函数 my_function(),它接受一个参数并返回参数的平方。通过 Parallel 类,我们可以并行地执行 my_function() 函数,并得到一个包含计算结果的列表。
- 内存缓存:
joblib提供了Memory类,用于在函数执行期间缓存中间结果,以减少重复计算的开销。
from joblib import Memory
# 创建内存缓存对象
mem = Memory("cachedir")
# 定义需要缓存的函数
@mem.cache
def my_function(x):
return x ** 2
# 调用函数
result = my_function(5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在上述示例中,我们使用 Memory 类创建了一个内存缓存对象,指定缓存目录为 “cachedir”。通过装饰器 @mem.cache,我们将 my_function() 函数包装成一个带有缓存功能的函数。在函数被调用时,如果输入参数已经被缓存,那么将直接返回缓存的结果,避免重复计算。
- 其他功能:
joblib还提供了其他一些功能,如延迟计算、并行循环、内存映射等。你可以根据具体需求进一步探索和了解这些功能。
joblib 库的优势在于它的简单易用性和高效性,特别适用于科学计算和机器学习中的大规模计算任务。它可以帮助提高代码的执行速度,并提供了一些方便的功能来处理函数的并行执行和结果的缓存,从而提升工作效率。
参考:https://docs.python.org/zh-cn/3/library/multiprocessing.html

