
- 1thingsboard源码编译常见问题_thingsboard 编译完成后,还是提示很多类找不到
- 2element-ui tree树形控件 自定义节点内容_element tree 自定义节点
- 3关于Python3.7.1无法导入Numpy的问题的解决_python3.7和numpy不兼容
- 4 Vue面试中,经常会被问到的面试题/Vue知识点整理
- 5Java毕业设计基于Springboot+vue的房产销售系统_spring+vue做的房产系统
- 6OpenCV实践之路——人脸识别之二模型训练_opencv多次训练一个人脸文件
- 7计算机毕业设计springboot再生资源回收(废品回收)管理系统a5rit9【附源码+数据库+部署+LW】_废品回收网系统的背景
- 8vue中fetch封装_fetch vue封装
- 9网络安全面试题大全(整理版)500+ 面试题附答案详解,最全面详细,看完稳了
- 10【ML】现实生活中的十大机器学习示例(让世界变得更美好)_机器学习的例子
javaEE005.03 HTTP通信协议和报文、STS中tomcat目录分析、响应码 200、404、500、302_sts报错500
赞
踩
系列文章目录
前言
接上一篇文章
这篇文章主要讲HTTP协议
HTTP协议是一种协议,一种规则
那什么又是报文呢?
客户端与服务端通信传输的内容我们就称之为报文
但是报文分为两种
请求报文和响应报文
发送给服务器的报文称为请求报文
反之服务器发送给客户端的称为响应报文
一、tomcat目录分析
我们已经知道了,STS里面的Tomcat 目录 并不是我们本地的Tomcat(Tomcat服务器绿色安装包的软件运行目录)
而是缓存目录
但是它却依赖于本地的Tomcat



在启动的同时直接访问helloworld页面





我们发现它会把src中的东西,放在classes文件夹 里面,而我们的代码,无非也就是页面和class代码
本地的Tomcat 可以清理一些没用的文件以提高效率(因为STS依赖于本地,本地的越冗余,STS服务器也就越慢)

缓存里面的Tomcat目录里面需要注意的是

二、HTTP协议
1、简介:简介一般就是 什么ss HTTP
超文本传输协议
HTTP 超文本传输协议 (HTTP-Hypertext transfer protocol),是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。它是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
客户端与服务端通信时传输的内容我们称之为报文。
HTTP就是一个通信规则,这个规则规定了客户端发送给服务器的报文格式,也规定了服务器发送给客户端的报文格式。实际我们要学习的就是这两种报文。客户端发送给服务器的称为”请求报文“,服务器发送给客户端的称为”响应报文“。
2.发展历程
超文本传输协议的前身是世外桃源(Xanadu)项目,超文本的概念是泰德˙纳尔森(Ted Nelson)在1960年代提出的。进入哈佛大学后,纳尔森一直致力于超文本协议和该项目的研究,但他从未公开发表过资料。1989年,蒂姆˙伯纳斯˙李(Tim Berners Lee)在CERN(欧洲原子核研究委员会 = European Organization for Nuclear Research)担任软件咨询师的时候,开发了一套程序,奠定了万维网(WWW = World Wide Web)的基础。1990年12月,超文本在CERN首次上线。1991年夏天,继Telnet等协议之后,超文本转移协议成为互联网诸多协议的一分子。
当时,Telnet协议解决了一台计算机和另外一台计算机之间一对一的控制型通信的要求。邮件协议解决了一个发件人向少量人员发送信息的通信要求。文件传输协议解决一台计算机从另外一台计算机批量获取文件的通信要求,但是它不具备一边获取文件一边显示文件或对文件进行某种处理的功能。新闻传输协议解决了一对多新闻广播的通信要求。而超文本要解决的通信要求是:在一台计算机上获取并显示存放在多台计算机里的文本、数据、图片和其他类型的文件;它包含两大部分:超文本转移协议和超文本标记语言(HTML)。HTTP、HTML以及浏览器的诞生给互联网的普及带来了飞跃。
3.HTTP协议的会话方式(跟我们打电话差不多)
浏览器与服务器之间的通信过程要经历四个步骤

浏览器与WEB服务器的连接过程是短暂的,每次连接只处理一个请求和响应。对每一个页面的访问,
浏览器与WEB服务器都要建立一次单独的连接。
浏览器到WEB服务器之间的所有通讯都是完全独立分开的请求和响应对。
4、HTTP1.0和HTTP1.1的区别
在HTTP1.0版本中,浏览器请求一个带有图片的网页,会由于下载图片而与服务器之间开启一个新的连接;但在HTTP1.1版本中,允许浏览器在拿到当前请求对应的全部资源后再断开连接,提高了效率。

如果结合我们现实生活中的场景大概就是:
问完所有问题再挂,而不是,问一个就挂掉,然后又打
三、报文
IE8以下的IE浏览器没有提供监听HTTP的功能,IE8以下以及以上版本有,而谷歌浏览器也是完全自带监听功能的

5.HttpWatch
由于IE8以下的IE浏览器没有提供监听HTTP的功能,所以如果要使用IE8以下的浏览器查看HTTP请求的内容需要安装一个工具HttpWatch。
HttpWatch的使用非常简单,直接安装,然后一直下一步,直到安装完成
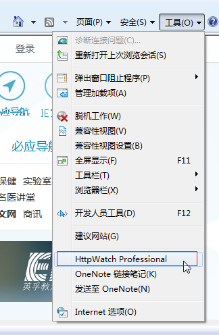
安装完成后,打开IE浏览器,工具下拉列表可以看到HttpWatch Professional选项
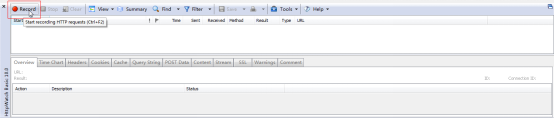
打开后点击Record按钮开始监听Http请求。
6.报文
默认请求都是get请求,比如什么超链接之类的,没有明示 都是 get请求

所以请求不同,报文也不同
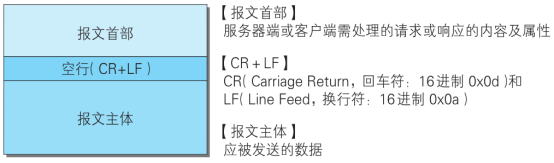
请求报文格式:

注意,get请求是没有请求体的,post请求才有这也就是为什么get请求的数据在url中,而post请求
的数据不会在url中显示的原因


GET /Hello/index.jsp HTTP/1.1:GET请求,请求服务器路径为Hello/index.jsp,协议为1.1;
Host:localhost:请求的主机名为localhost;
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0…:与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这都是通过获取User-Agent头信息而来的;
Accept: /:告诉服务器,当前客户端可以接收的文档类型, /,就表示什么都可以接收;
Accept-Language: zh-CN:当前客户端支持的语言,可以在浏览器的工具选项中找到语言相关信息;
Accept-Encoding: gzip, deflate:支持的压缩格式。数据在网络上传递时,可能服务器会把数据压缩后再发送;
Connection: keep-alive:客户端支持的链接方式,保持一段时间链接,默认为3000ms;
Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98:因为不是第一次访问这个地址,所以会在请求中把上一次服务器响应中发送过来的Cookie在请求中一并发送过去。


POST请有请求体,而GET请求没有请求体。
Referer: http://localhost:8080/hello/index.jsp:求请求来自哪个页面,例如你在百度上点击链接到了这里,那么Referer:http://www.baidu.com;如果你是在浏览器的地址栏中直接输入的地址,那么就没有Referer这个请求头了;
Content-Type: application/x-www-form-urlencoded:表单的数据类型,说明会使用url格式编码数据;url编码的数据都是以“%”为前缀,后面跟随两位的16进制,例如“传智”这两个字使用UTF-8的url编码用为“%E4%BC%A0%E6%99%BA”;
Content-Length:13:请求体的长度,这里表示13个字节。
keyword=hello:请求体内容!hello是在表单中输入的数据,keyword是表单字段的名字。

HTTP/1.1 200 OK:响应协议为HTTP1.1,状态码为200,表示请求成功;
Server: Apache-Coyote/1.1:服务器的版本信息;
Content-Type: text/html;charset=UTF-8:响应体使用的编码为UTF-8;
Content-Length: 274:响应体为274字节;
Date: Tue, 07 Apr 2015 10:08:26 GMT:响应的时间,这可能会有8小时的时区差;
响应码
响应码对浏览器来说很重要,它告诉浏览器响应的结果;
200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
(404其实一般就是错了,要么是你这个页面在服务器中没有,
第二种情况就是页面有但是找不到,可能你少些了一个字母或者其它的原因写错了)
500:请求资源找到了,但服务器内部出现了错误;
(500换句话说就是代码写错了)
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
操作实战环境





总结
1、

2、默认请求都是get请求

3、报文




