
- 1基于SpringBoot+Vue的房屋租赁系统(源码+文档+部署+讲解)_基于springboot+vue的租房管理系统的系统整体需求概述
- 2css 动画 (transition animation)_css动画
- 3Git — 版本管理_on branch master changes not staged for commit: (u
- 4yolov8 如何将分割的mask掩模,显示读取出来 ,Masks类型 转换为 ndarray_yolo掩膜
- 5Android Camera相机开发示例、Android 开发板 USB摄像头采集、定期拍照、定时拍照,安卓调用摄像头拍照、Android摄像头预览、监控,USB摄像头开发、摄像头监控代码_安卓调用usb摄像头
- 6GraphPad Prism 9.3 win/mac 安装教程及获取
- 7华为Mate怎么解账号锁被机主锁定激活锁ID账户锁定强制解除教程_华为手机激活账号解锁
- 8AI赋能,轻松出爆文!AI新闻创作新时代,你准备好了吗?
- 9mysql关于utf8_unicode_ci与utf8mb4_unicode_ci的区别_utf8mb4_general_ci和utf8字符长度
- 10uniapp获取手机通知权限_uniapp获取通知权限
详解fork函数_windows fork
赞
踩
一、fork函数的功能
一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
通俗点说:fork()函数通过系统调用创建一个与原来进程几乎一样的进程,这个新进程叫做子进程,而原来的进程叫做父进程,父子进程一起向下执行代码。
****注意:调用fork函数之前,仅由原进程(也就是之后的父进程调用),调用fork之后,后面的代码由两个进程一起执行。
fork函数有两个返回值:
在父进程中,fork返回子进程的ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值;
***注意:
在fork函数执行结束后,如果创建新进程成功,那么将出现两个进程,一个是父进程,一个是子进程。在子进程中,fork函数返回0,在父进程中,返回创建子进程的ID,也就是说,我们可以通过fork的返回值来判断当前进程是父进程还是子进程
fork的特性:一次调用,两次返回
---------------------------------------------------------------------------------------------------------------------------------
代码实现:
- int main()
- {
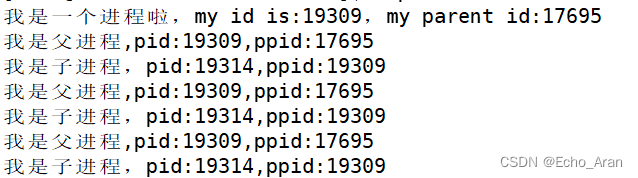
- printf("我是一个进程啦,my id is:%d,my parent id:%d\n",getpid(),getppid());
- sleep(2);
-
-
- pid_t id =fork();
- if(id ==0 ){
- while(1){
- printf("我是子进程,pid:%d,ppid:%d\n",getpid(),getppid());
- sleep(1);
- }
- }else if(id>0){
- while(1){
- printf("我是父进程,pid:%d,ppid:%d\n",getpid(),getppid());
- sleep(1);
- }
- }else{
-
- }
-
- return 0;
- }

代码执行的结果 :
二、深度剖析fork函数
对于fork函数和上述代码的运行结果,我们可能会有以下疑问:
1.fork函数的返回值为什么要给子进程返回0,给父进程返回子进程的pid?
2.一个函数是如何做到返回两次的?如何理解?
3.一个变量为什么会有不同的内容,怎么理解?
4.子进程创建后,父进程和子进程谁先执行?
上述问题都需要我们深度剖析一下fork函数究竟干了什么
2.1 fork函数究竟干了什么
准备知识:
linux对进程的管理原理:先描述再组织
linux中对OS对进程的管理是通过进程控制块(PCB)实现的。
具体请看这一篇文章:http://t.csdn.cn/ZZD8B
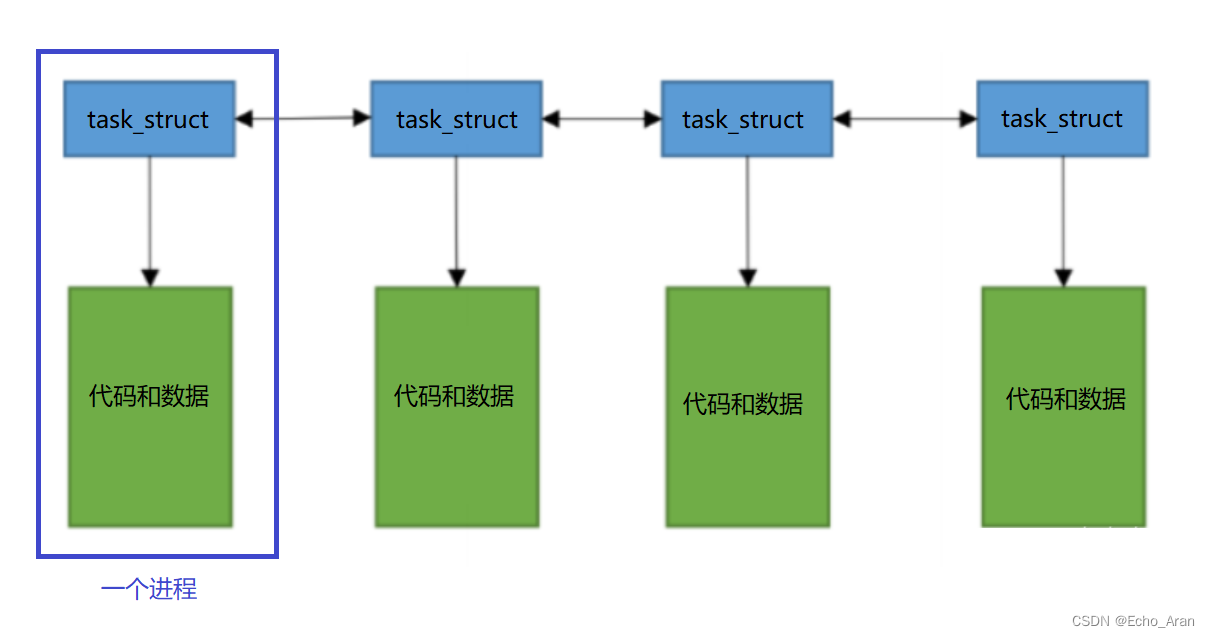
进程=内部数据结构+代码和数据
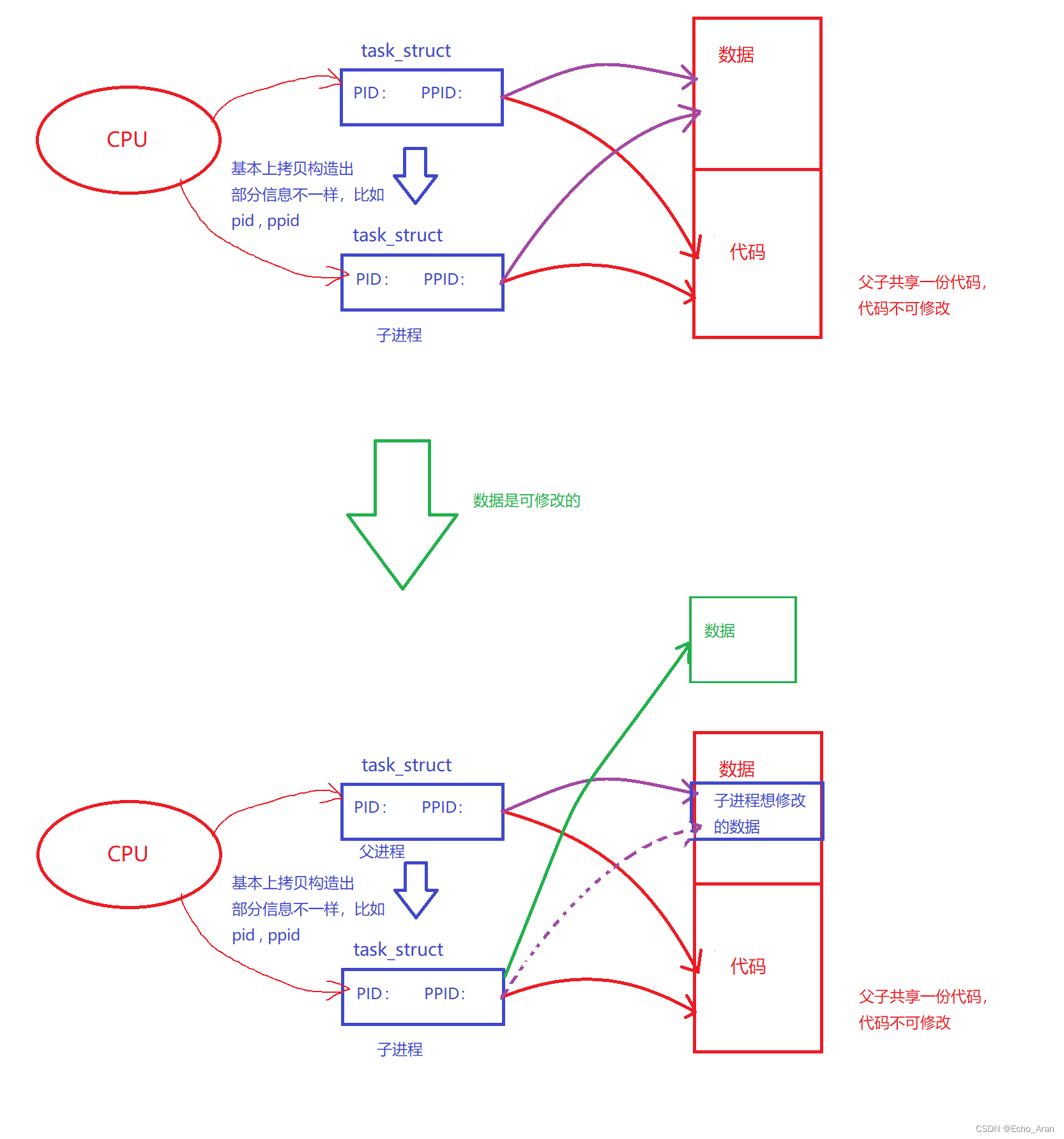
fork函数先几乎复制一份父进程的task_struct,并指向同一块内存空间,创建一个了与原来进程几乎完全一致的子进程。
因为代码是不可以修改的,而数据是可以修改的,所以一般父子进程不享用同一块数据
当子进程想修改父进程中的数据时,系统会单独分配一块空间存储子进程的数据。
**但如果子进程不修改父进程的数据,就不用拷贝父进程的数据并开空间,这种方法叫做写时拷贝。
2.2 fork函数的返回值为什么要给子进程返回0,给父进程返回子进程的pid?
因为调用fork函数之后的代码父子共享,返回不同的返回值,是为了区分不同的执行流,执行不同的代码块。
就像上述代码,父子进程执行的printf函数就不一样。
2.3 一个函数是如何做到返回两次的?如何理解?
因为创建了两个进程,每个进程都返回了一次。
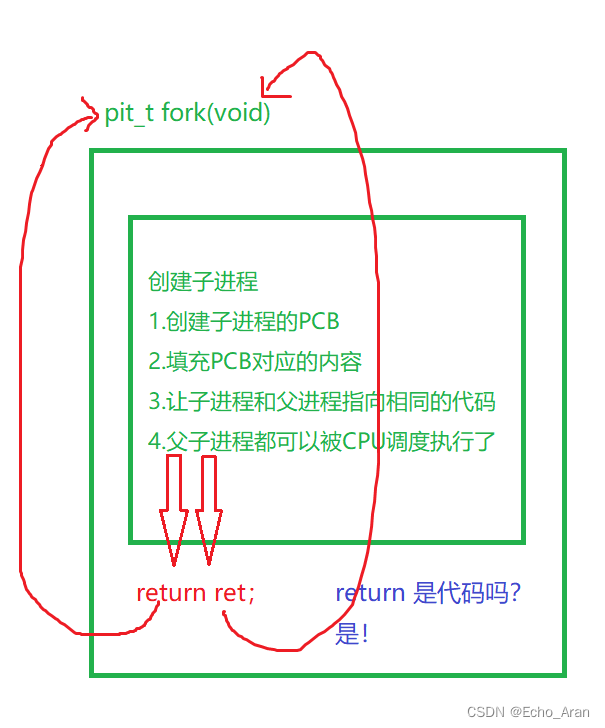
2.4 一个变量为什么会有不同的内容,怎么理解?
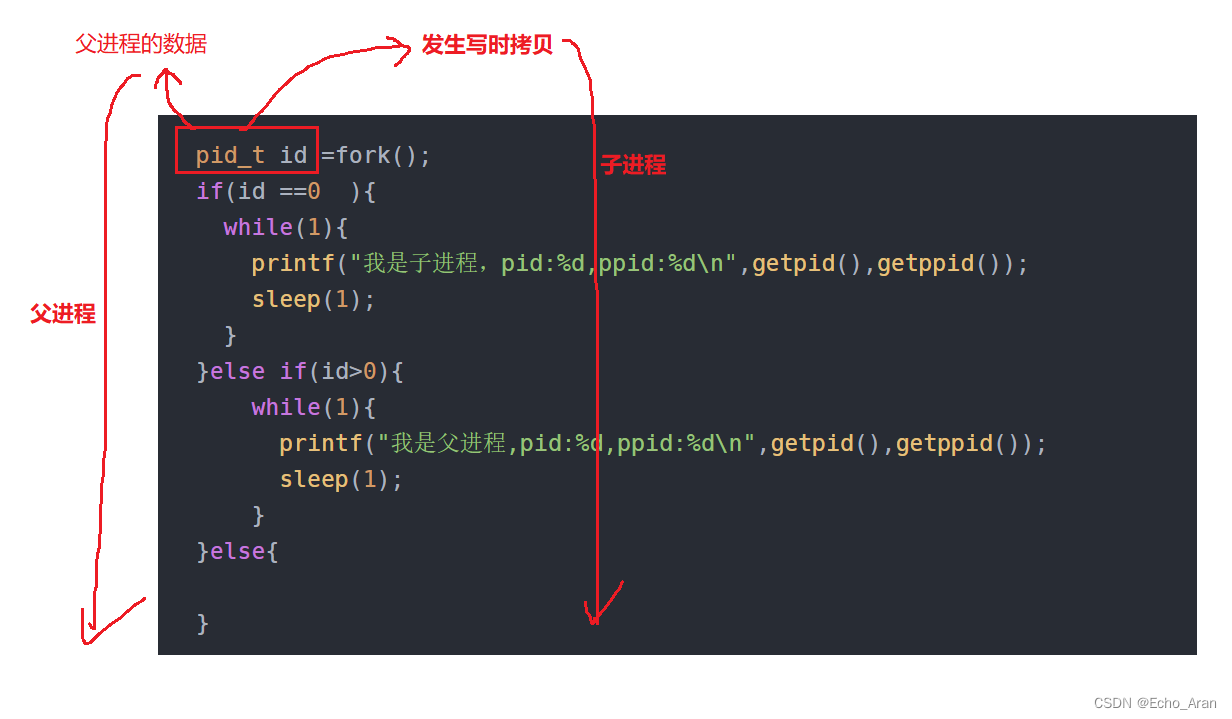
2.5 子进程创建后,父进程和子进程谁先执行?
由调度器决定
此外,在打印父子进程中认识到了 \n 的一个新作用,详情请看这一篇文章http://t.csdn.cn/HlzU9

