
- 1变配电站配电监控解决方案--变电站综合自动化系统
- 2CAS基本原理和应用_cas 应用管理
- 3企业数字化转型到底是什么?_数智化转型五部曲
- 4JAVA权重算法(如Dubbo的负载均衡权重)_java权重分配算法
- 5Android 滑动菜单(DrawerLayout + NavigationView )_android滑动菜单
- 6PSQL容器带脚本初始化_postgresql基于容器创建表的初始化脚本
- 7eclipse无法启动提示 java.lang.NoClassDefFoundError: org/w3c/dom/stylesheets/StyleSheet问题
- 8VSCode SSH免密登录失败原因 原因分析及解决_vscode设置密钥登陆没有效果
- 9【摘要】抽取式摘要:TextRank和BertSum。
- 10通过包名,直接精确启动一个三方Activity_通过包名启动应用startactivity
阿里巴巴创研究计划AIR2018正式发布 邀全球学者共创未来
赞
踩
主要发现
相对于2016年的报告,2018年《Top 20 Python AI and Machine Learning projects on Github》报告主要有如下几个变化:
从贡献者(Contributors)的基数看,Tensorflow已上升至排名第一;Scikit-learn下降至第二,但其贡献者基数仍很大。
从贡献者数量的增长率看,增长最快的项目分别为:TensorFlow(169%)、Deap(86%)、Chainer(83%)、Gensim(81%)、Neon(66%)、Nilearn(50%)
2018年的新项目:Keras(贡献者数:629)和PyTorch(贡献者数:399)。
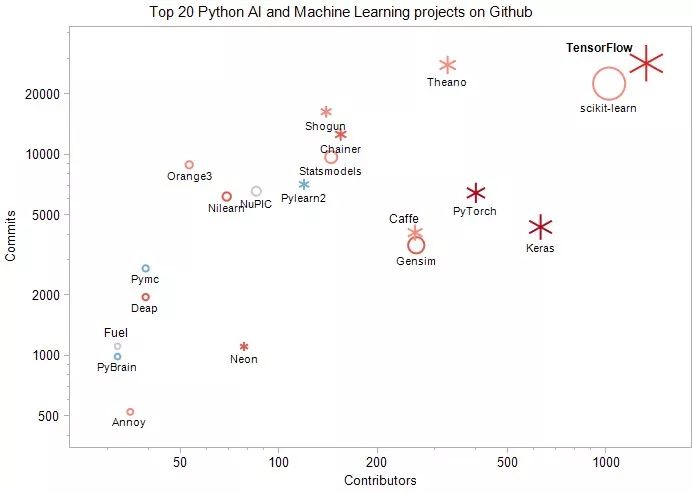
图中,点的【大小】代表的是贡献者数量的绝对值;【颜色】代表的是贡献者数量的变化:红色越高,蓝色越低;【形状】代表的是项目类型:雪花为深度学习项目。
TensorFlow:最初由Google Brain Team研发,旨在促进机器学习方面的科学研究,并使研究原型转换为生产系统变得快速简单。Contributors: 1324 (增长168% ), Commits: 28476, Stars: 92359. Github URL: Tensorflow
Scikit-learn:建立在NumPy,SciPy和matplotlib等的Python机器学习包。Contributors: 1019 (增长39% ), Commits: 22575, Github URL: Scikit-learn
Keras:可以运行在TensorFlow,CNTK或Theano上的一种高层神经网络API。Contributors: 629 (new), Commits: 4371, Github URL: Keras.
PyTorch:支持GPU加速的张量和动态神经网络。Contributors: 399 (new), Commits: 6458, Github URL: pytorch.
Theano:支持以较高的效率定义,优化和评估涉及多维数组的数学表达式。Contributors: 327 (24% up), Commits: 27931, Github URL: Theano
Gensim :一种支持可扩展的统计语义,分析用于语义结构的文本文档,检索语义相似的文档等功能的Python库。Contributors: 262 (81% up), Commits: 3549, Github URL: Gensim
Caffe:由伯克利视觉和学习中心(BVLC)和社区贡献者开发的深度学习框架 Contributors: 260 (21% up), Commits: 4099, Github URL: Caffe
Chainer:一种独立的深度学习框架,以较为灵活,直观和高性能的方式实现了多种深度学习模型,其中包括最新的模型,如递归神经网络和变分自动编码器。Contributors: 154 (84% up), Commits: 12613, Github URL: Chainer
Statsmodels:实现统计学基本功能的模块,Contributors: 144 (33% up), Commits: 9729, Github URL: Statsmodels
Shogun:一种机器学习工具箱,以统一与高效的方式实现了机器学习方法,方便集成多种数据表示、算法类型和通用工具。Contributors: 139 (32% up), Commits: 16362, Github URL: Shogun
Pylearn2:一种是一个机器学习库,其大部分功能都建立在Theano之上,支持使用数学表达式编写Pylearn2插件(新模型,算法等)。Contributors: 119 (3.5% up), Commits: 7119, Github URL: Pylearn2
NuPIC:基于一种叫做分层时间存储器(Hierarchical Temporal Memory,HTM)的新大脑皮层理论的探索型项目,目前仍在不断探索和扩展之中。Contributors: 85 (12% up), Commits: 6588, Github URL: NuPIC
Neon:Nervana提供的基于Python的深度学习库,其易用性和性能均为较高。Contributors: 78 (66% up), Commits: 1112, Github URL: Neon
Nilearn :一种用于在NeuroImaging数据上进行统计学习的Python模块,它利用scikit-learn Python工具箱进行多变量统计,并提供预测建模,分类,解码或连接分析等应用。 Contributors: 69 (50% up), Commits: 6198, Github URL: Nilearn
Orange3:一种新手和专家均可以使用的机器学习和数据可视化工具箱,支持交互式数据分析。Contributors: 53 (33% up), Commits: 8915, Github URL: Orange3
Pymc: 一种实现贝叶斯统计模型和拟合算法的Python模块,包括马尔可夫链蒙特卡罗。Contributors: 39 (5.4% up), Commits: 2721, Github URL: Pymc
Deap:一种用于快速原型设计和测试思想的新型演化计算框架。它试图使算法明确,数据结构透明,与多处理和SCOOP等并行机制较好地集成。 Contributors: 39 (86% up), Commits: 1960, Github URL: Deap
Annoy(Approximate Nearest Neighbors Oh Yeah):一种用于搜索接近给定查询点的空间点。 它还可以创建映射到内存的大型只读基于文件的数据结构,以便多个进程可以共享相同的数据。 Contributors: 35 (46% up), Commits: 527, Github URL: Annoy
PyBrain:一种模块化的机器学习库,使用简单,支持用户测试和分析自己的算法。 Contributors: 32 (3% up), Commits: 992, Github URL: PyBrain
Fuel:一种数据管道式框架,不仅提供机器学习算法,而且还提供所需数据,将由Blocks和Pylearn2神经网络库使用。 Contributors: 32 (10% up), Commits: 1116, Github URL: Fuel
【特别声明】本文原作者为KDnuggets的Ilan Reinstein ,来源https://www.kdnuggets.com/2018/02/top-20-python-ai-machine-learning-open-source-projects.html 。由朝乐门翻译和编辑。
本文转自:数据科学DataScience 已获授权;
END
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读:
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:

